业务领域建模Domain Modeling
关于领域模型
一 领域模型的定义
领域模型是对领域内的概念类或现实世界中对象的可视化表示。领域模型也成为概念模型、领域对象模型和分析对象模型。领域建模可以降低软件和现实世界之间的差异,用真实的业务概念划分职责,目的是实现一个可以高效低成本维护的可持续发展的软件系统。从领域模型推导到系统实现是一套引导思考的方式,也是一套科学的开发流程。其核心目的在于提供了系统设计的“指导方针”。领域模型必须站在用户需求和业务发展的角度上,既可以用来同客户沟通验证需求,又可以避免模型因实现的考量而带偏(实现成本、遗留系统)。
二 领域模型的特点
1、领域模型是业务概念的可视化描述,是需求分析的产物;
2、领域模型用于指导程序设计,但领域模型与实现方式无关,领域建模时不应该考虑如何实现;
3、领域模型需要同项目所有成员(客户、项目经理、开发、测试…)达成共识。
三 领域建模的重要性
首先,建模的重要性在所有工程实践中都已经得到了广泛的认同。建模是一种抽象和分解的方法,它可以将复杂的问题拆解成一个个抽象,代表了特定的一块密集而内聚的信息。从上世纪80年代开始,人们对于面向对象建模产生了许多思考和方法,其中最流行的就是面向对象分析与设计。面向对象分析,强调的是在问题域发现并描述概念,解决的问题是做正确的事情。面向对象设计,强调的是定义软件对象,解决的问题是正确的做事情。领域模型就是面向对象分析的主要产物,它表达了对现实问题的描述和抽象。大多数人可能可能会有质疑:不做分析和设计,我也可以直接去做代码实现(甚至使用面向过程的编程语言),一样可以完成软件的功能需求,何必花心思去做建模呢?但实际上,这样做会有以下弊端:首先,如果不做设计直接实现,俗称走一步看一步。很大可能在开发过程中发现思维局限,开发进度推倒重来。其次,如果不做分析直接设计,看起来没什么问题。遗憾的是,通过这种方式构造的代码,并没有和现实世界连接起来,当我们的软件和需求稍加修改,这份代码就可能变得异常混乱和难以维护。而通过领域建模的,自上而下的设计,可以保证代码实现的层次结构和模块划分是科学的、稳定的。
基于工程实践的业务建模
我的工程实践是《正负新闻分类》,下面是以我的工程实践为例来进行业务建模。
一 收集应用领域信息
文本情感分析:又称意见挖掘、倾向性分析等。简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。互联网(如博客和论坛以及社会服务网络如大众点评)上产生了大量的用户参与的、对于诸如人物、事件、产品等有价值的评论信息。这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等。基于此,潜在的用户就可以通过浏览这些主观色彩的评论来了解大众舆论对于某一事件或产品的看法。我的工程实践主要针对的是关于企业新闻,收集企业新闻之后,分析新闻是正面还是负面,从而了解互联网关于企业的消息情况。
二 头脑风暴
深度学习:深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
神经网络:人工神经网络也简称为神经网络或称作连接模型,它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
自然语言处理:自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
文本情感分析:又称意见挖掘、倾向性分析等。简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。互联网(如博客和论坛以及社会服务网络如大众点评)上产生了大量的用户参与的、对于诸如人物、事件、产品等有价值的评论信息。这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等。基于此,潜在的用户就可以通过浏览这些主观色彩的评论来了解大众舆论对于某一事件或产品的看法。
三 对领域概念进行分类(关联、继承、聚合)
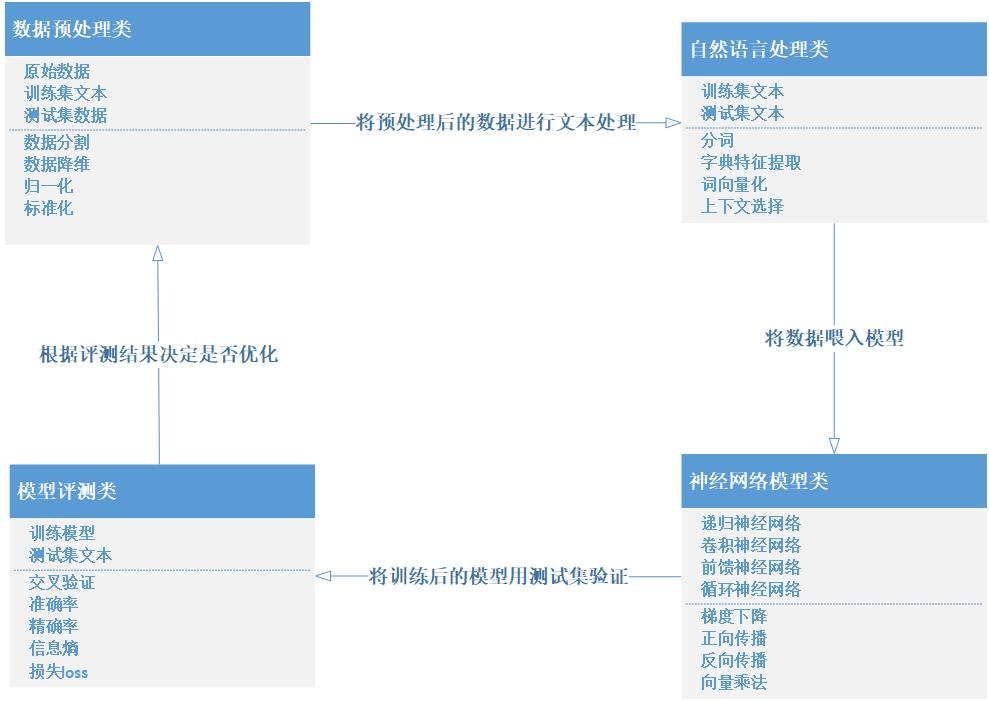
数据预处理类
属性:原始数据、训练集文本、测试集数据
方法:数据分割、数据降维、归一化、标准化
神经网络模型类
属性:前馈神经网络、循环神经网络、递归神经网络、卷积神经网络、模块化神经网络
方法:梯度下降、正向传播、反向传播、向量乘法
自然语言处理类
属性:训练集文本、测试集文本
方法:分词、字典特征提取、词向量化、上下文选择
模型评测类:
属性:训练模型、测试集文本
方法:交叉验证、准确率计算、精确度计算、信息熵、损失loss计算
四 使用UML类图记录结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号