
20162309《程序设计与设计结构》第十一周学习总结
学号 20162309《程序设计与数据结构》第11周学习总结
教材学习内容总结
关于哈希函数的基本概念:
Hash,一般翻译做"散列",也有直接音译为"哈希"的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
哈希算法的主要算法用途:
HASH主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码里,叫做HASH值. 也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关。
1.文件效验
2.数字签名
Hash函数的构造:
直接定址法
例如:有一个从1到100岁的人口数字统计表,其中,年龄作为关键字,哈希函数取关键字自身。
折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法。
除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。
H(key)=key MOD p (p<=m)
随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即
H(key)=random(key),其中random为随机函数。通常用于关键字长度不等时采用此法。
若已知哈希函数及冲突处理方法,哈希表的建立步骤如下:
Step1. 取出一个数据元素的关键字key,计算其在哈希表中的存储地址D=H(key)。若存储地址为D的存储空间还没有被占用,则将该数据元素存入;否则发生冲突,执行Step2。
Step2. 根据规定的冲突处理方法,计算关键字为key的数据元素之下一个存储地址。若该存储地址的存储空间没有被占用,则存入;否则继续执行Step2,直到找出一个存储空间没有被占用的存储地址为止。
散列(Hashing)通过散列函数将要检索的项与索引(散列,散列值)关联起来,生成一种便于搜索的数据结构(散列表)。
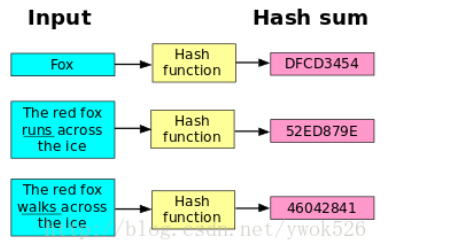
简单的说,hash函数就是把任意长的输入字符串变化成固定长的输出字符串的一种函数。输出字符串的长度称为hash函数的位数。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来,比如我们自定义密码的存储。
哈希函数的映射:
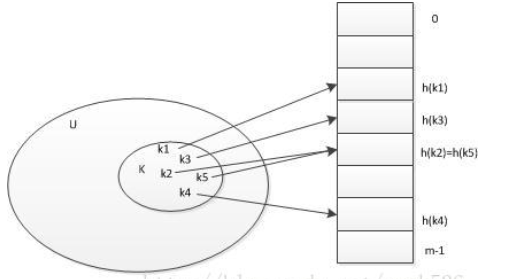
哈希函数的性质:
同一函数的Hash值不相同,那么其原始输入也不相同,上图中k1,k3和k4。(确定性)
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是不相同的,这种情况称为“哈希碰撞”。(不确定性)
构造Hash列表:
利用探测法构造散列表,举例:
已知一组关键字为(26,36,41,38,44,15,68,12,06,51),用除余法构造散列函数,用线性探查法解决冲突构造这组关键字的散列表。
这里关键字个数n=10,不妨取m=13,此时α≈0.77,散列表为T[0..12],散列函数为:h(key)=key%13。
由除余法的散列函数计算出的上述关键字序列的散列地址为
(0,10,2,12,5,2,3,12,6,12)。
步骤:
1、前5个关键字插入时,其相应的地址均为开放地址,故将它们直接插入T[0],T[10),T[2],T[12]和T[5]中。
2、当插入第6个关键字15时,其散列地址2(即h(15)=15%13=2)已被关键字41(15和41互为同义词)占用。故探查h1=(2+1)%13=3,此地址开放,所以将15放入T[3]中。当插入第7个关键字68时,其散列地址3已被非同义词15先占用,故将其插入到T[4]中。
3、当插入第8个关键字12时,散列地址12已被同义词38占用,故探查hl=(12+1)%13=0,而T[0]亦被26占用,再探查h2=(12+2)%13=1,此地址开放,可将12插入其中。
4、类似地,第9个关键字06直接插入T[6]中;而最后一个关键字51插人时,因探查的地址12,0,1,…,6均非空,故51插入T[7]中。
关于Hash表的冲突问题:
几种常见的处理方法:
(1)开放地址法
(2)拉链法
(3)再哈希法
(4)建立公共溢出区
教材学习中的问题和解决过程
-
问题1:关于开放地址法的实际使用方法
-
问题1解决方案:
![]()
-
问题2:什么是拉链法?如何通过代码来实现?
-
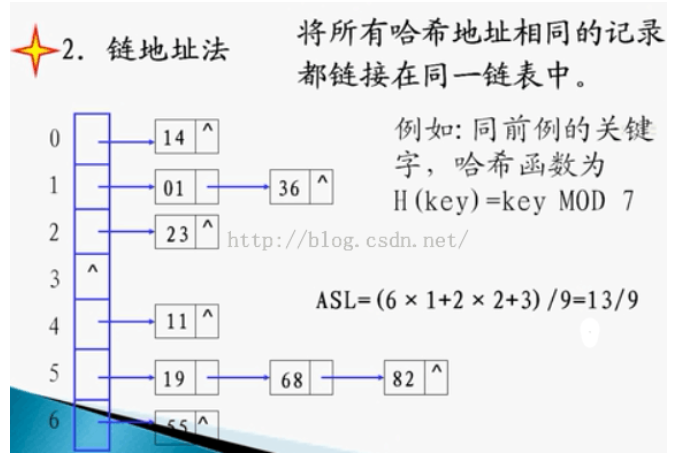
问题2解决方案:拉链法又叫链地址法,适合处理冲突比较严重的情况。基本思想是把所有关键字为同义词的记录存储在同一个线性链表中。插入操作需要把Key的值转为整形后Mod P,这样就知道该元素会放到哪个链表里面,在执行Insert时,逐个比较链表中的元素,看看是否已经存在该Key,没有则将他放到链表的最后。
代码实现:
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
![]()

static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
代码调试中的问题和解决过程
- 问题1:Java Collection API中的Hash 实现
- 问题1解决方案:
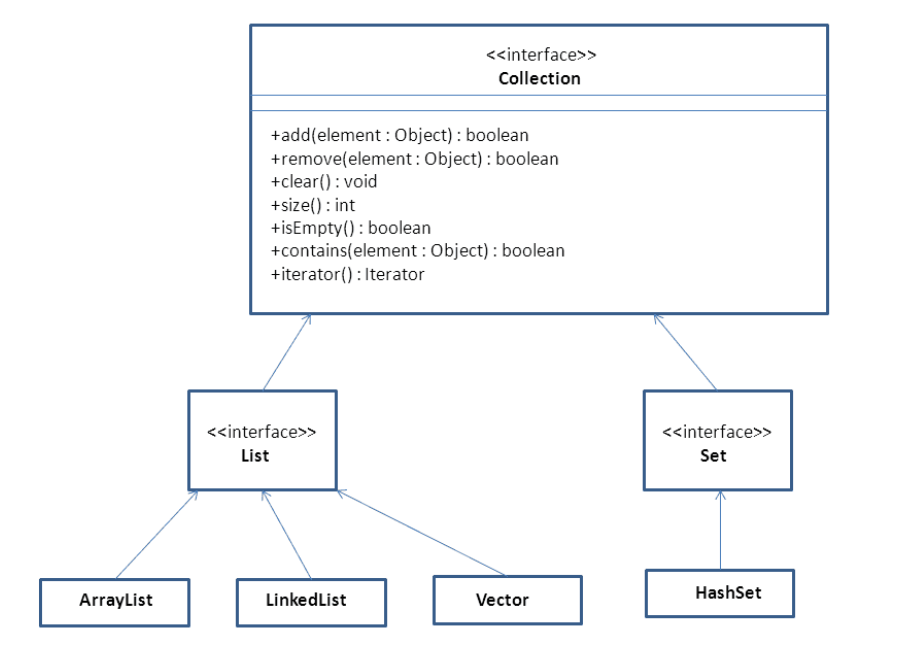
首先是用uml类图来表示关系:
![]()
Set 接口的重用实现类有HashSet(哈希集)。
Set 和 HashSet
Set 表示一个数学的集。和 List 不同, Set 不允许重复的内容。假设两个元素, e1 和 e2,如果 e1.equals(e2)的话,它们是不能在 Set中同时存在的。如果试图添加一个重复的元素, Set 的 add 方法会返回 false。例如,如下的代码会打印出“ addition failed”。
代码实现:
Set set = new HashSet();
set.add("Hello");
if (set.add("Hello")) {
System.out.println("addition successful");
} else {
System.out.println("addition failed");
}
代码托管
https://gitee.com/xingtianyue/events
(statistics.sh脚本的运行结果截图)
结对及互评
本周和20162313苑洪铭同学学习了关于图的总结部分知识,主要包括了几种构成最小生成树的方法。
本周结对学习情况
- 结对同学学号1
- 结对照片
- 结对学习内容
- 哈希表达
- 图结构
- ...
其他(感悟、思考等,可选)
关于哈希方法:
为什么要学习哈希方法?通过机器学习机制将数据映射成简洁的二进制串的形式, 同时使得哈希码尽可能地保持原空间中的近邻关系, 即保相似性。这是相对比较关键的一点。关于哈希方法的分类:1、第一种的代表是局部敏感哈希,这种方法主要是人工设计或者随机生成哈希函数,是一种数据独立的方法; 2、第二种是哈希学习的方法,希望从数据中自动学习出哈希函数,是一种数据依赖的方法;也是现在主流的方法; 显然第二种具有数据依赖性,是一种更有适应性的方法。
xxx
xxx
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 |
-
计划学习时间:18小时
-
实际学习时间:18小时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号