梯度消失与梯度爆炸
梯度消失与梯度爆炸
梯度及其更新
深层次的神经网络要比浅层次的神经网络有更好的处理数据的效果,目前优化神经网络的方法都是基于反向传播的思想,即根据损失函数计算的误差通过梯度反向传播的方式,来对更深的层次进行更新优化.
所以,我们可以把一个神经网络看作是一个复合的多元的非线性函数.而我们最终的目的是要对这个函数很好的进行从输入层到输出层的映射.
我们优化的过程实际上就是寻找合适的权值,使得我们定义的损失函数的值最小.
不得不祭出这张神图了!
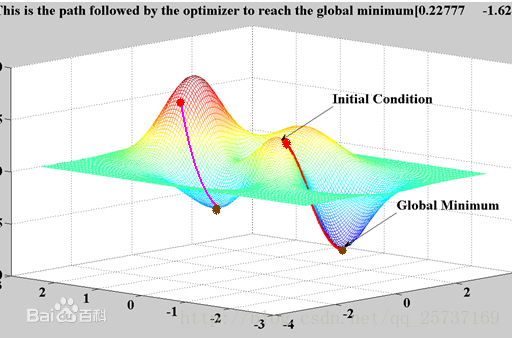
对于这样的数据处理,我们可以使用梯度下降的方法来进行梯度更新.
而梯度消失和爆炸,就出现在更新梯度的过程中.
梯度消失与梯度爆炸
梯度消失:靠近输出层的权值更新相对正常,但是靠近输入层的权值更新会变得很慢,导致靠近输入层的隐藏层权值几乎不变,仍接近于初始化的权值。这就导致1层相当于只是一个映射层,对所有的输入做了一个函数映射,这时此深度神经网络的学习就等价于只有后几层的隐藏层网络在学习.
梯度爆炸:的情况是:当初始的权值过大,靠近输入层的 hidden layer 1 的权值变化比靠近输出层的权值变化更快,就会引起梯度爆炸的问题.
产生原因:
采用了不合适的激活/损失函数并且初始化权值太大,或者是在深层网络中.
梯度消失
深度角度
还用这张图:
也就是说,对激活函数求导,如果这个部分大于1的话就会发生梯度爆炸,反之会发生梯度消失,
激活函数角度
使用了不合适的激活函数,使得其导数小于1
如何解决
预训练+微调
思想:每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,作为预训练,然后使用一个贪心的思想,局部最优推导到全局最优,作为微调
梯度正切-正则
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内.这可以防止梯度爆炸.
正则化是通过对网络权重做正则限制过拟合,正则函数:
\(Loss=(y-W^Tx^2)^2+\alpha ||W||^2\)
其中\(\alpha\)是指正则项系数,因此,如果发生梯度爆炸,权值的范数就会变的非常大,通过正则化项,可以部分限制梯度爆炸的发生.
使用优化后的激活函数
学完了
Batchnorm
在处理的过程中人为的在ReLU激活层的前面插入,然后将其映射为一个矩阵,进行标准化:
1.Standardization:对m个x进行Standardization,得到x的分布x^
2.Scale and shift:对x的分布x^进行scale和shift,缩放平移得到新的矩阵和方差
映射公式:
\(x_i^b\leftarrow \gamma \times\frac{x_i^b-u_i}{\sigma_i}+\beta\)
也就是:
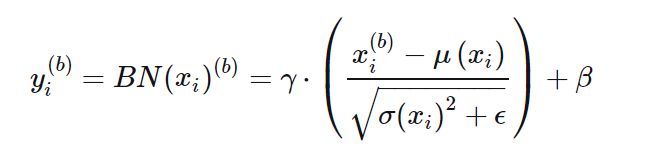
可见,无论\(x_i\)原本的均值和方差是多少,通过BatchNorm后其均值和方差分别变为待学习的β和γ.
过程:
1.计算更新均值
2.计算更新方差
3.使用均值和方差是某个元素标准化
反向传播
就是求其梯度的过程(可微的),抓住一个关键点,然后求得几个变量之间的偏导数,然后发掘关系.
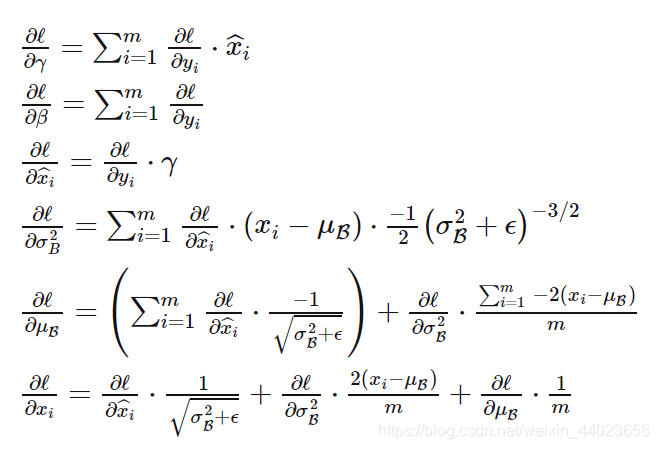
对于每个激活函数的意义
Sigmoid函数
使得输入在每个sigmoid函数的敏感区域内,使得其对不同样本的输出保持一种区分的状态,不至于使得全为0或者1,并且使得在反向传播过程中,梯度的衰减被减缓了
对于ReLU函数
防止梯度的爆炸或者衰减,并且依据梯度将部分样本放置0以下或者0的上面,使得过滤效果加强.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号