GAN在蛋白质设计上的应用(三)
思考了一下,目前题目大概有了个眉目「基于GAN的蛋白质二级结构的生成及其应用」
具体的计划的话,我自己的想法是能够弄一个能根据人们的想法去生成具有特定性质的蛋白质二级结构序列,最好能为合成生物学这方面近一点微薄之力就是最好不过了,看了几个这方面的访谈,感觉还挺有意思的。
既然要按人们的要求去生成新的蛋白质,那么就需要Conditional GAN了。
1.Conditional GAN
Generator和Discriminator与普通的GAN都有些许差别:
Generator需要一个输入,这个输入表示我们指定的要求,要求生成的目标需要满足一些Condition;
Discriminator不只是要辨别生成的目标是否足够清晰准确,还需要判断Generator生成的target与Condition是否相匹配,如果target不够准确或者与Condition不匹配,Discriminator都会打一个低分.
对比GAN的训练,Conditional GAN因为多了一种需要打低分的情况,所以需要在Loss Function中多一项:
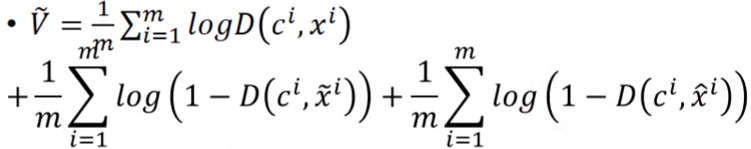
一共有三项,第一项是positive example,每一个真实数据xi都对应一个与它match的条件ci,第二项表示一个condition配上generator生成的模糊结果,第三项是condition与generator生成的清晰准确的目标完全不匹配。
而对于Discriminator的打分,也有一种模式是把后两项的情况分开传达给Generator,以便Generator能够及时得知到底是因为生成的target过于模糊还是因为target与condition不匹配:

有时候,可能在训练时不会对所有的feature都设置一个参数,这样子参数过多,训练可能会很慢,或者生成的结果不够清晰准确,于是就可以只对其中一部分设置参数,这种叫做batch GAN,其中的batch size是作为了训练时的一个参数;
还有一种做法是stack GAN,将整个过程分为两个stage,第一个stage生成较为小规模的结果,然后将这个结果作为stage2的input,再生成正常规模的结果,两个stage都具有一个Generator和一个Discriminator。
2.seq2seq GAN(seq-GAN)
(1)Policy Gradient(Reinforcement Learning)
强化学习中的feedback,使用了Policy Gradient,将这个概念与GAN相结合,例如存在一个机器人,输入一个condition,这个机器人会对这个condition做出一个response,可以将这个机器人看作seq-GAN中的Generator,然后存在一个Discriminator,以这个机器人的输入(condition)和输出(response)作为输入,评价这次response的好坏并对机器人给予一个Reward,这时,这个机器人(Generator)的首要目标就是最大化这个Reward,这就是seq-GAN的基本工作原理。
Policy Gradient的工作过程如下图所示,输入一个c(condition),通过由参数θ控制的Generator,生成一个x(response),
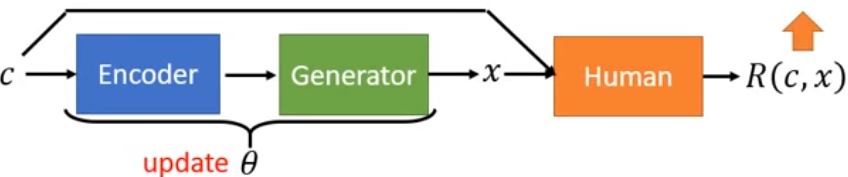
将c和x作为Human(Discriminator)的输入,然后由Discriminator给出一个Reward--R(c,x),Generator的目标就是![]() 。
。![]() 是Reward的期望值,我们已知condition的分布和Generator生成的Response的分布,所以可以写出
是Reward的期望值,我们已知condition的分布和Generator生成的Response的分布,所以可以写出![]() 的函数:
的函数:
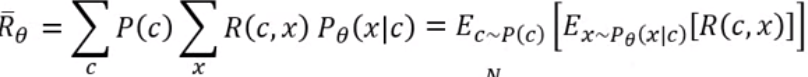
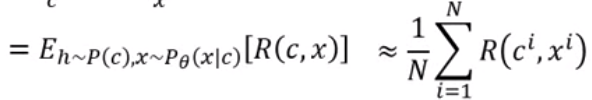
最后的结果是通过从Reward的分布中sample出N个样本所进行计算的Reward的期望,因为是sample的,所以结果中的θ不见了,θ其实是藏在了sample的过程中,当θ不同时,Reward的分布也会不同,所以sample的结果也会发生改变。
所以为了能够对Policy Gradient也能进行关于参数θ的Gradient Descent,在第一步就进行梯度计算:
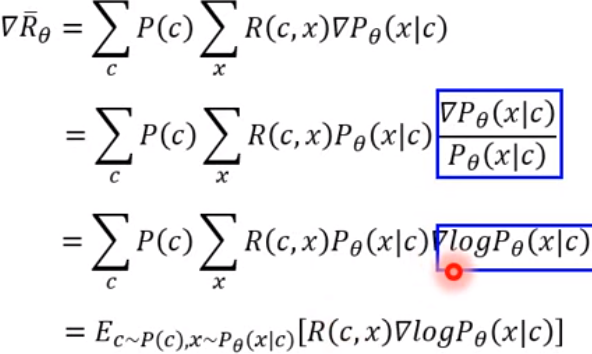
与之前的sample出N个样本计算的期望进行对比,我们可以求出基于Reward的期望的关于θ的梯度:
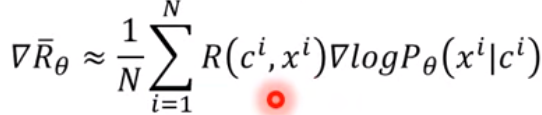
于是我们可以看到强化学习的过程,机器人与人类进行博弈,针对一个c,机器人给出response x,然后由人去评判这个结果的好坏并给出打分(Reward),经过N次取样后我们可以算出Reward的期望的Gradient,然后调整参数θ并进入下一轮调整。
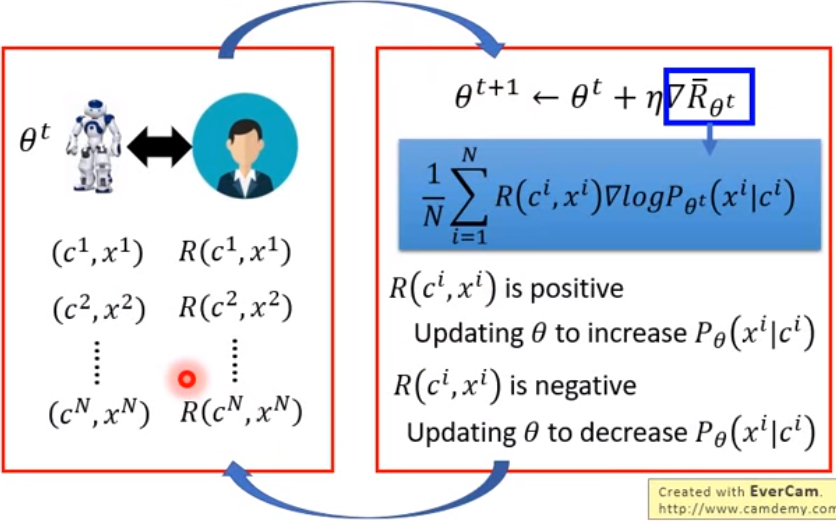
但是观察这个训练过程,我们会发现其实这是难以实现的,因为由Human来充当Discriminator其实是不现实的,我们无法通过人力去给机器进行上万次的打分,无法实现这个训练过程,于是就需要引入GAN的思想了。
(2)seq-GAN
seq-GAN中使用机器充当Discriminator,这个Discriminator能够和Generator完成上万次打分,从而让Generator能够生成足够逼近真实序列的样本分布。
训练过程如下图所示:
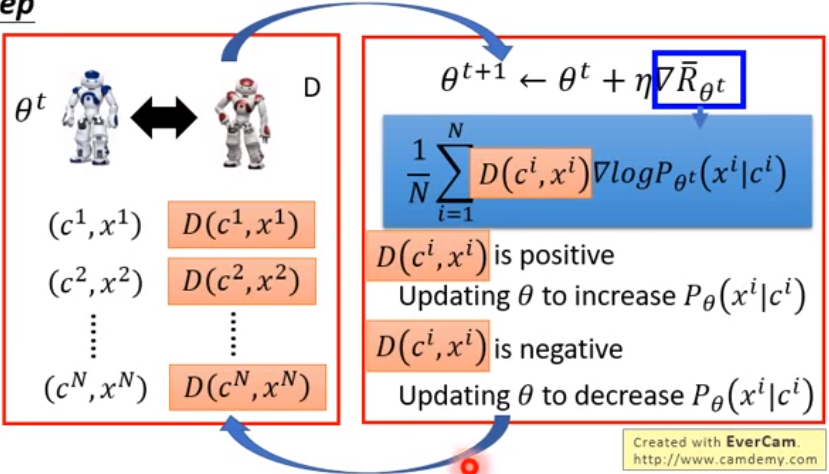
由Discriminator去给每一次迭代进行打分,然后经过N次后得到一个关于参数θ的Reward的分布,通过这个分布的梯度去优化θ使得Reward最大。
这里的Discriminator是要通过真实的数据进行训练好的,训练好Discriminator后,因为Reward发生了改变,所以再使用这个Discriminator去训练Generator,然后再去训练Discriminator,之后再训练Generator,这样反复来回训练,使得Generator最终能够生成与真实序列的分布相同的序列分布。

seq-GAN的主要架构大概就是这样,但其实还有一些问题需要说一下。
(3)seq-GAN的收敛
我们都知道seq-GAN生成的是一个序列,对比conditional GAN,conditional GAN中当output不清晰或者output与input不匹配时,discriminator都会给generator打一个低分,这里也一样,既然生成的是一个序列,我们最明确的目标是能够得知对于Generator生成的当前序列,Discriminator为什么要给它打一个低分,换句话说,我们希望得知这一个序列中到底是那些element使得这次生成的序列与真实序列不符。比对生物信息中,假如我们希望Generator能够生成具有指定特性的protein的amino acid sequence,在训练中我们希望得知到底是哪些位置的amino acid是不应该出现的,sequence中哪些位置的amino acid是应该出现的。
例如:我们想要一个能够与人对话的chatbot,input是“What is your name?”,对于“I don't know”这个回答Discriminator给了一个很低的Reward,如果按表达式的话,对于这个输入,应当减少‘I’在第一个位置出现的概率,减少在这种情况下出现“I don't”的概率,减少这种情况下在出现“I don't”的情况下再出现‘know’的概率。

然而真实的情况是,在第一个位置出现‘I’的正确回答有很多,而真正造成这个sequence是negative的原因是出现“I don't”和在出现“I don't”的情况下再出现‘know’,
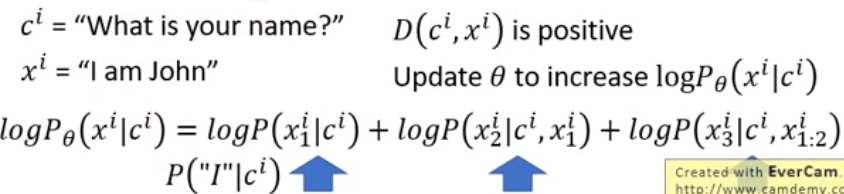
所以为了让Generator能够更快的收敛,我们希望Generator能够得知这个事实,如图所示:
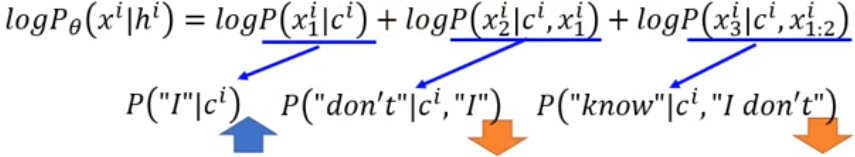
针对这个问题的解决方法有一些,主要方法比如说Monte-Carlo Search Tree等等,有时间研究的话,也会学习一下,对研究应该是很有帮助的。
3.基于seq-GAN生成蛋白质的二级结构序列
看了一篇关于蛋白质二级结构序列的生成的论文(其实主要是没有找到很多这方面的论文),他也是用了seq-GAN,并且结合了Monte-Carlo Method,但是他是直接使用二级结构进行网络的训练,于是生成的就直接是蛋白质二级结构的序列,但我总感觉这样有点脱离amino acid sequence直接生成序列的感觉,于是我觉得最好是使用一级结构进行网络的训练,最后能够生成可靠性足够高的amino acid sequence之后再去预测二级结构,因为现在蛋白质二级结构的预测准确度也是非常高了,所以通过生成的氨基酸序列预测这个生成的新蛋白质的二级结构准确性理论上来说应该也会比较高才对。
(1)Generator input/output
关于Generator的输入输出,我初步构想是希望能够提取出一些能够明确将蛋白质进行分类的一些特征,通过这些特征去定位到某一些蛋白质的集合,将这些特征作为Generator的输入,希望Generator也能够生成一些属于这个集合的新蛋白质的氨基酸序列。
Generator的输出就是新生成的蛋白质的氨基酸序列。
(2)Discriminator input/output
Discriminator的input是蛋白质的一级结构和这个蛋白质的特征向量(包含了对这个蛋白质所在集合的所有特征的描述)。
Discriminator的output是对这个序列的评分,通过Monte-Carlo Method希望能够对每一个从第一个氨基酸开始的子氨基酸序列的打分,以便seq-GAN能够更有效的收敛。
(3)Reward Expectation(期望生成什么样的序列)
参照别的大佬做的ProteinGAN所得到的结果,我希望生成的氨基酸序列能够与所在蛋白质集合的其他蛋白质有完全相同的子氨基酸序列,这样可以认为新生成的蛋白质有几率与其他蛋白质有相同的特征。
(4)进一步的准确性判断
套用现在已经具有较高准确率的蛋白质二级结构预测model,能够得到生成的蛋白质的二级结构序列,将这个二级结构序列与集合中其他蛋白质进行对比,希望能发现一些有趣的规律。
上一篇:GAN在蛋白质设计上的应用(二)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号