数学建模结课题目
题目
这学期选修了数学建模,期末考查题挺有意思的。

思路
数据预处理(指标设置)
处理方式:我设置了两个指标,一个考勤率,一个作业完成度。
考勤率:
缺勤:0分
早退:1分(未上满90分钟)
完成:2分
缺勤率=(各课程考勤总分数/2*7)*100%
完成度:
未提交:0分
D:1分
C:2分
B:3分:
A:4分
A+:5分
其他:3分
得到作业的总分数
然后,判断是否迟交(在下一次上课前必须提交,即时间差是否大于14)
如果迟交:则分数-1,其他0分,得到最终作业分数。
完成度=最终作业总分/35*100%
综合评价
可以参考之前写的两篇博客:
https://www.cnblogs.com/Mayfly-nymph/p/13096966.html
https://www.cnblogs.com/Mayfly-nymph/p/13096812.html
代码与结果
预处理代码
import pandas as pd import numpy as np df = pd.read_excel("C:\\Users\\10245\\Desktop\\data.xlsx") a = [] tmp = df.iloc[:,1:8] for i in range(7): a.append(list(tmp.iloc[:,i])) for i in range(len(a)): for j in range(len(a[0])): if(type(a[i][j]) != int): a[i][j] = 0 if(a[i][j] < 90): a[i][j] = 1 if(a[i][j] >= 90): a[i][j] = 2 data0 = np.sum([x for x in a], axis=0) idata = [round((x / 14)*100,2) for x in data0] tmp1 = df.iloc[:,8::2] b = [] for i in range(7): b.append(list(tmp1.iloc[:,i])) for i in range(len(b)): for j in range(len(b[0])): if(b[i][j] == '未提交'): b[i][j] = 0 elif(b[i][j] == 'D'): b[i][j] = 1 elif(b[i][j] == 'C'): b[i][j] = 2 elif(b[i][j] == 'B'): b[i][j] = 3 elif(b[i][j] == 'A'): b[i][j] = 4 elif(b[i][j] == 'A+'): b[i][j] = 5 else: b[i][j] = 3 tmp2 = df.iloc[:,9::2] c = [] for i in range(7): c.append(list(tmp2.iloc[:,i])) limit_time = [[3,4],[3,18],[4,1],[4,15],[4,29],[5,13],[5,20]] month_day = [31,28,31,30,31,30,31,31,30,31,30,31,0] d = [] for i in range(len(b)): for j in range(len(b[0])): index = limit_time[i][0] if c[i][j].month - limit_time[i][0] > 0 else -1 days = month_day[index] + (c[i][j].day - limit_time[i][1]) if(days <= 14): d.append(0) elif(days > 14): d.append(-1) else: d.append(0) e = [] for i in range(7): e.append(list(np.array(b[i]) - np.array(d[i]))) data1 = np.sum([x for x in e], axis=0) jdata = [round((x / 35)*100,2) for x in data1] # data = [idata,jdata] # s= list(df.iloc[:,0]) # s1 = '\n'.join(s) # with open(r'C:\Users\10245\Desktop\results.xls','w') as f: # f.write(s1) # with open(r'C:\Users\10245\Desktop\results.xls','a') as f: # f.write('\t') # for i in range(len(data)): # for j in range(len(data[i])): # f.write(str(data[i][j])) # f.write('\n') # f.write('\n')
熵权法和优劣解距离法代码
%% 数据读取
clear,clc
load data.mat
%%
[n,m] = size(datas_matrix);
%% 矩阵标准化
% datas_S_matrix = datas_matrix ./ repmat(sum(datas_matrix.*datas_matrix) .^ 0.5, n, 1)
for i = 1:m
tmp = datas_matrix(:,i)
datas_S_matrix(:,i) = (tmp - min(tmp))/(max(tmp) - min(tmp));
end
%%
model = ["编号1", "编号2", "编号3", "编号4", "编号5", "编号6", "编号7", "编号8", "编号9", "编号10", "编号11", "编号12", "编号13", "编号14", "编号15", "编号16", "编号17", "编号18", "编号19", "编号20", "编号21", "编号22", "编号23", "编号24", "编号25", "编号26", "编号27", "编号28", "编号29", "编号30", "编号31", "编号32", "编号33", "编号34", "编号35", "编号36", "编号37", "编号38", "编号39", "编号40", "编号41", "编号42", "编号43", "编号44", "编号45", "编号46", "编号47", "编号48", "编号49", "编号50", "编号51", "编号52", "编号53", "编号54", "编号55", "编号56", "编号57", "编号58", "编号59", "编号60", "编号61", "编号62", "编号63", "编号64", "编号65", "编号66", "编号67", "编号68", "编号69", "编号70", "编号71", "编号72", "编号73", "编号74", "编号75", "编号76", "编号77", "编号78", "编号79", "编号80", "编号81", "编号82", "编号83", "编号84", "编号85", "编号86", "编号87", "编号88", "编号89", "编号90", "编号91", "编号92", "编号93", "编号94", "编号95", "编号96", "编号97", "编号98", "编号99", "编号100", "编号101", "编号102", "编号103", "编号104", "编号105", "编号106", "编号107", "编号108", "编号109", "编号110", "编号111", "编号112"];
%% 熵权法
p = datas_S_matrix./sum(datas_S_matrix);
k = 1/log(n);
r = zeros(n,m);
for i = 1:n
for j = 1:m
if p(i,j) == 0
r(i,j) = 0;
else
r(i,j) = log(p(i,j));
end
end
end
e = -k*sum(p.*r,1);
d = ones(1,m)-e
weight = d./sum(d)
score = sum(weight.*datas_S_matrix,2);
results1 = 0 + (100-0)/(max(score)-min(score)).*(score - min(score));
[sorted_score,index] = sort(results1 ,'descend');
a = [sorted_score,index]
rivers1 = [];
for i = 1:n
rivers1 = [rivers1;model(index(i))];
end
s = [rivers1,sorted_score]
%% 优劣解距离法
t = ones(1,m) ./ m ;
max_dis = sum([(datas_S_matrix - repmat(max(datas_S_matrix),n,1)) .^ 2 ] .* repmat(t,n,1) ,2) .^ 0.5;
min_dis = sum([(datas_S_matrix - repmat(min(datas_S_matrix),n,1)) .^ 2 ] .* repmat(t,n,1) ,2) .^ 0.5;
S = min_dis ./ (max_dis+min_dis);
% results = S / sum(S);
results2 = 0 + (100-0)/(max(S)-min(S)).*(S - min(S));
[sorted_results,index] = sort(results2 ,'descend');
rivers2=[];
for i = 1:n
rivers2 = [rivers2;model(index(i))];
end
R = [rivers2,sorted_results];
%% 绘图
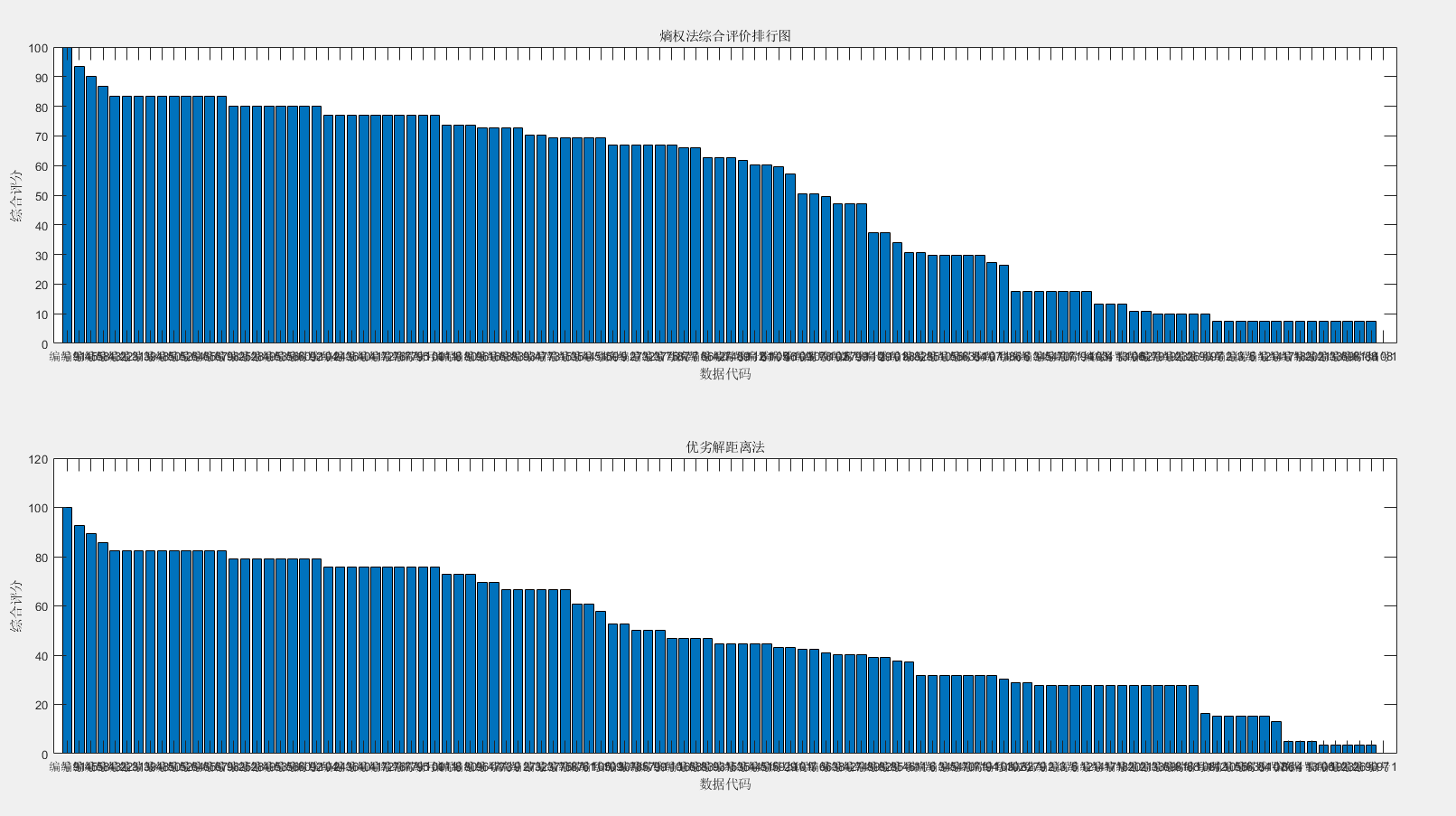
subplot(2,1,1)
bar(sorted_score);
title('熵权法综合评价排行图')
set(gca,'XTick',1:112)
set(gca, 'xticklabel',{rivers1{1:112}});
xlabel('数据代码');
ylabel('综合评分')
subplot(2,1,2)
bar(sorted_results);
title('优劣解距离法')
set(gca,'XTick',1:112)
set(gca, 'xticklabel',{rivers2{1:112}});
%% 保存到文件
% xlswrite('output.xls',s,'Sheet1');
% xlswrite('output.xls',R,'Sheet2');
结果
附件
https://wwa.lanzous.com/iuYt2ejrzbg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号