计算系统中的互联
Survey of Inter-connects in computer system
姚伟峰
http://www.cnblogs.com/Matrix_Yao/
https://github.com/yao-matrix
计算机系统处理数据就像是碾谷机碾谷子,能碾多少谷子取决于两个方面:一是机器每单位时间能碾多少谷子;二是传送带每单位时间能运多少谷子。如果瓶颈在前者,我们叫“compute boundary”,如果是后者,我们叫“communication boundary”。目前, 一个典型的IA CPU的系统如下图:
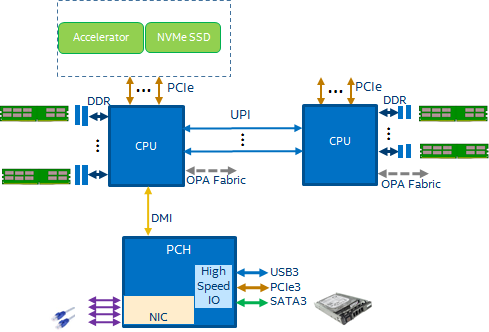
在计算机系统中, interconnect连接着运算设备,内存设备与IO设备,承担着传送带的职责。因此,它的带宽和延时决定了communication的效率,本文主要讨论带宽。
首先亮出带宽(Bandwidth, BW)计算公式,它的单位为GB/s(Giga Bytes per seconds),如下:
Computation Engine Interconnects
本部分讨论计算设备间的互连设备(interconnect)及其带宽参数的计算。
QPI/UPI
QPI(QuickPath Interconnect)和UPI(UltraPath Interconnect)是Intel为支持multi-socket而设计的socket间interconnect,其最大的特点是unified memory space和cache coherency。

例
Skylake spec 中UPI说明如下:

一般的dual-socket方案,两个socket是通过两个UPI lane连接的,每个lane的有效带宽为16 bit,所以:
, 即41.6 GB/s.
需要注意的是QPI/UPI是全双工的,且10.4GT/s包含了双工的带宽,所以严格来说单方向的带宽为20.8 GB/s.
PCIe
PCIe(Peripheral Component Interconnect express) spec如下。

PCIe 3
例
Skylake spec 中PCIe说明如下:

对一个典型的16 lane的PCIe 3设备而言, 每条lane的有效带宽为128/130 bit,所以其带宽为:
,即15.8 GB/s.
在这里, PCIe的bus width是1 bit, 编码效率是128b/130b.
P.S.
Rule-of-Thumb
PCIe 3.0 一条lane大约为1GB/s
PCIe 4
PCIe 4的GT/s是PCIe 3的一倍。也就是说一个16 lane的PCIe 4设备带宽约为48 GB/s。
Memory Interconnects
本部分讨论计算设备与内存间带宽参数的计算。
DDR
最常见的内存设备就是DDR了。
例
Skylake spec 中memory 说明如下:
这里DPC = DIMMs Per Channel.
首先DDR 4每channel 的有效带宽 是 64 bits (72 for ECC memory),从spec可以看出支持6 channel,频率为2666MT/s。因此:
所以单socket的, 即 127 GB/s.
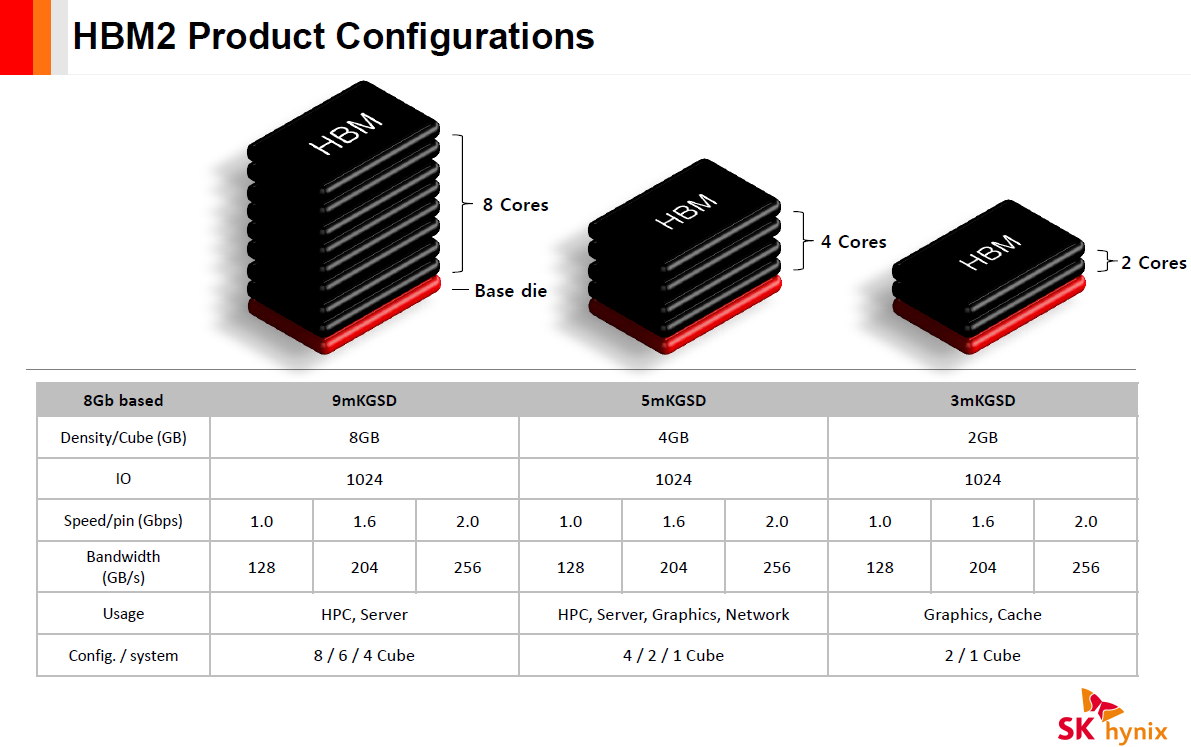
HBM
HBM(High Bandwidth Memory)顾名思义是高带宽内存,它是一个通过3D堆叠技术把若干个DRAM(die)堆叠起来形成的memory.
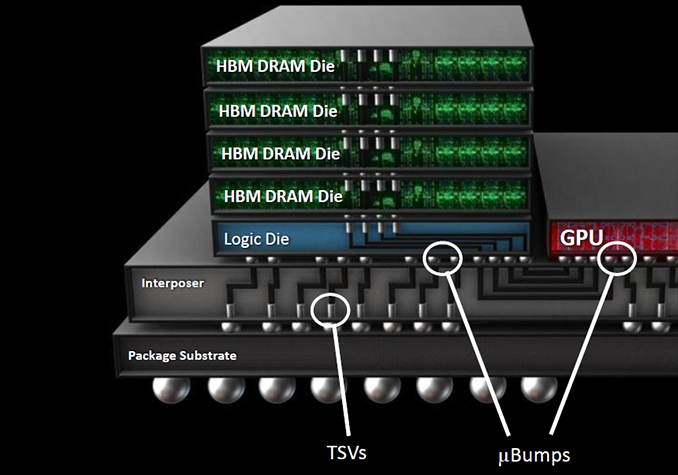
每个die有两个128-bit的channel(即 ![]() bytes), 目前正在使用的HBM2的transfer rate最高能到2 GT/s, 因此带宽计算可以如下:
bytes), 目前正在使用的HBM2的transfer rate最高能到2 GT/s, 因此带宽计算可以如下:
IO Interconnects
目前IO的带宽与memory相比差距还是比较大的。所以谈到分布式系统的时候,很多时候大家都说“IO is important”,甚至有人说“network is critical”。因为IO的带宽与memory差距相当大,而在当前10 Gbps为部署主流的状况下,network IO的差距尤甚。
Storage
Storage和Network是计算型workload中最常用的两种IO设备。Storage设备就是各种各样的盘,目前主流的是SSD(Solid State drive)和HDD(Hard Disk Drive),他们带宽不同,但都是块设备(block device)。块设备与内存设备不同之处为:
- 内存读写的单位是byte,但盘读写的单位是block。因此计算盘的的带宽一般为:
其中IOPS 为 Input/Output Operations Per Second。

- 顺序读写和随机读写的带宽是不一样的。一个直觉的解释就是:对HDD而言顺序读写减少了磁针的寻道开销,所以提高了读写带宽。 但对SSD而言,因为不再有寻道和旋转延时,理论上顺序读写和随机读写的带宽是一样的。另外在SSD中,不同的block size的IOPS是不一样的,这是由SSD内部的scatter机制决定的。
所以,IOPS尤其是SSD的IOPS是个挺复杂的东西,受很多东西影响,我们一般通过测试而不是解读spec来获得其性能。在Linux中,一般通过fio测试我们关心的配置下的IOPS,然后用上述公式折算出带宽。 从上限估算的角度,我们可以从它们使用的接口来给出一个上限。对SSD盘来说,目前主要有两种:SATA和PCIe NVMe。SATA-2的带宽为3 Gbps也就是375 MB/S,SATA-3的带宽为6 Gbps也就是750 MB/s(除去校验码,实际只有600 MB/s),PCIe 3 x4的接口带宽为4 GB/s。从这里可以看出,即使不管介质、控制器和协议的限制,单从接口的限制上来看,Storage离内存还是差得远的。
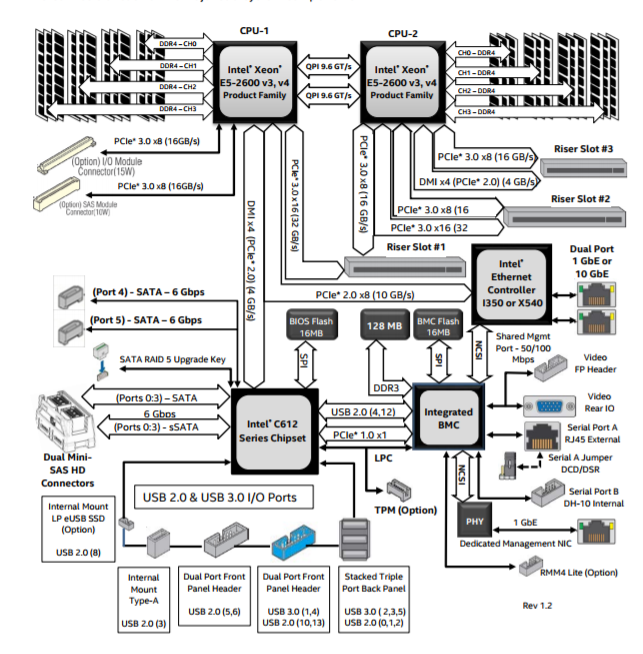
需要注意的是,SATA接口之间是相互独立的,也就是理论上来讲,如果我插N块盘,且能把文件均匀地scatter到各个盘中,理论上总的IO带宽会变成N倍的。但是,有一个限制,就是因为SATA接口是接在PCH(Platform Controller Hub)的,然后PCH通过一个PCIe或者DMI(Direct Media Interface)与CPU连接,所以总带宽上限受这个DMI或PCIe的带宽限制。在下面这个板子design中,总带宽限制是4 GB/s。
Network
目前比较的网络有10 Gbps, 25 Gbps, 40 Gbps,后面演进有50 Gbps, 100 Gbps。就算到了100 Gbps,它的上限还是12.5 GB/s,离memory还是有较大距离的。
趋势
随着各种各样的workload往云端迁徙,云端承载越来越多的各种各种的workloads,从web server到数据库到AI, 因此云端会逐渐成为一个需求hub。这使得“把所有的工作converge到CPU”方案变得越来越局促和不符合发展趋势,“以CPU为中心”的系统设计也越来越不合时宜。“异构计算”时代已经到来,这不仅仅是因为目前的workload的多样性发展趋势,也是cloud provider作为workload hub的话语权越来越大的必然结果。AI只是踢开这个大门的第一个闯入者,我相信后续这样的usage scenarios会越来越多。我们在见证一个交替的时代,一个生态从“hardware define application”转型到“application define hardware”的时代,何其幸哉。
那么哪些系统设计方案会成为“明日之星”,我觉得以内存为中心 (memory-centric)的方案会是其中之一。我们已经看到很多这一方向上的探索,如CCIX,Gen-Z,OpenCAPI甚至NVLink。虽然它们有着不同的设计和实现方法,但是它们有一个共同的愿景就是:系统设计思路应该开始从CPU monolithic转移到engine democrtization,它的两个显著特点是:
- 各个计算引擎与内存的距离相似,即不会出现所有engine都必须经过CPU来access memory的情况。
- 统一编址(Unified Memory)。
References
[1] PCIe wiki
[2] Converting GT/s to Gbps
[3] DDR SDRAM
[4] Everything You Need To Know About QPI
[5] Performance Characteristics of Common Transports and Buses
[6] Intel Server Board S2600WT Design Spec


 浙公网安备 33010602011771号
浙公网安备 33010602011771号