Oracle、Mysql REGEXP_LIKE正则表达式用法
1.情景展示
oracle和mysql关于正则表达式和对应的函数都一样。
正则表达式符号介绍:
'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。
'.' 匹配除换行符之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
\num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
字符簇:
[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。各种操作符的运算优先级:
\转义符
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
|
*/
2.REGEXP_LIKE()
与LIKE的功能相似,区别在于:可以使用正则表达式;
基本用法:
-- 查询THEMECODE字段值包含36的记录
select * from meta_theme where regexp_like(THEMECODE,'36');相当于:
select * from meta_theme where THEMECODE like '%36%';
只包含数字0-9或小数点
regexp_like(str,'^[0-9\.]+$')只包含纯数字的四种实现方式
regexp_like(str,'^[0-9]+[0-9]$');
regexp_like(str,'^[0-9]+$');
regexp_like(str,'^[[:digit:]]+$');
not regexp_like(str,'[^0-9]');'+' 匹配前面的子表达式一次或多次;
^表示排除。
不是纯数字0-9的两种实现方式
regexp_like(str,'[^0-9]'); -- ^表示排除
not regexp_like(str,'^[[:digit:]]+$');只包含0-9和-字符的两种实现方式
regexp_like(str,'[0-9-]');
regexp_like(str,'^[0-9]|[-]$');'|' 指明两项之间的一个选择,相当于or。
只包含0-9,-字符, 或者空格的五种实现方式
regexp_like(str,'^[0-9]|[-]$') or regexp_like(str,'^[ ]$');
regexp_like(str,'^[0-9]|[-]$|^[ ]$');
regexp_like(str,'(^[0-9]|[-]$)|(^[ ]$)');
regexp_like(str,'^[0-9]|[-]|[ ]$');
regexp_like(str,'[0-9- ]');
3.REGEXP_INSTR()
与INSTR()的功能相似,区别在于:可以使用正则表达式;
4.REGEXP_SUBSTR()
与SUBSTR()的功能相似,区别在于:可以使用正则表达式;
将字符串按照匹配模式拆分成N组数据,可选择返回哪一组数据。
function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
__srcstr :需要进行正则处理的字符串
__pattern :进行匹配的正则表达式
__position :起始位置,从第几个字符开始正则表达式匹配(默认为1)
__occurrence :标识第几个匹配组,默认为1
__modifier :模式('i'不区分大小写进行检索;'c'区分大小写进行检索。默认为'c'。)
5.REGEXP_REPLACE()
与REPLACE()的功能相似,区别在于:可以使用正则表达式;
可以利用正则表达式,替换或者提取字段内容。
-- 替换
select regexp_replace('hjbfgcoqwue8723r8fhescb938r','[^0-9]','-');
-- 提取
select regexp_replace('hjbfgcoqwue8723r8fhescb938r','[^0-9]','') from dual;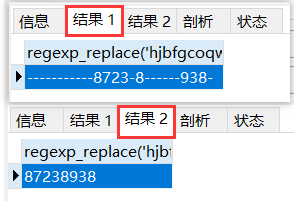
6.常用正则表达式
匹配数字
^[1-9]\d*$ -- 匹配正整数
^-[1-9]\d*$ -- 匹配负整数
^-?[1-9]\d*$ -- 匹配整数
^[1-9]\d*|0$ -- 匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ -- 匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ -- 匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ -- 匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ -- 匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ -- 匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ -- 匹配非正浮点数(负浮点数 + 0)匹配字符
^[A-Za-z]+$ -- 匹配由26个英文字母组成的字符串
^[A-Z]+$ -- 匹配由26个英文字母的大写组成的字符串
^[a-z]+$ -- 匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ -- 匹配由数字和26个英文字母组成的字符串
^\w+$ -- 匹配由数字、26个英文字母或者下划线组成的字符串十六进制值:/^#?([a-f0-9]{6}|[a-f0-9]{3})$/
电子邮箱:/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
URL:/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
IP 地址:/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
HTML 标签:/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/
Unicode编码中的汉字范围:/^[u4e00-u9fa5],{0,}$/
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
匹配空白行的正则表达式:\n\s*\r
匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? />
说明:上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^\s*|\s*$
说明:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
说明:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
说明:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
说明:腾讯QQ号从10000开始
匹配中国大陆邮政编码:[1-9]\d{5}(?!\d)
说明:中国大陆邮政编码为6位数字
匹配身份证:\d{15}|\d{18}
匹配ip地址:\d+\.\d+\.\d+\.\d+
2021年12月28日14:24:18
以英文字符结尾:'^.*[A-Za-z]$'
UPDATE meta_theme SET THEMETYPE=2 WHERE regexp_like(THEMENAME, '^.*[A-Za-z]$');
NOT REGEXP_LIKE(字段名称,正则表达式)
UPDATE meta_theme SET THEMETYPE=1 WHERE not regexp_like(THEMENAME, '^.*[A-Za-z]$');
表行数总计:
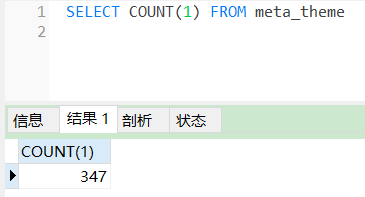
上面两条数据之和与该值相等,所以说,正则表达式的like是没有问题的。
只保留字符串当中的中文:[\u4e00-\u9fa5]
通过regexp_replace()来实现。

去除字符串当中的中文:[^\u4e00-\u9fa5]

\u表示按unicode匹配某些规则;
汉字的表示范围:\u4e00-\u9fa5
数字表示范围:\u0030-\u0039
英文表示范围:\u0041-\u005A,\u0061-\u007A
示例1:筛选字段值以英文结尾的数据,并将数据当中的中文进行剔除。

示例2:筛选字段值以_开头的数据,并去掉该字符。

本文来自博客园,作者:Marydon,转载请注明原文链接:https://www.cnblogs.com/Marydon20170307/p/15614776.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号