第四模块
第四功能模块的简要设计
@Luxiaoye支持原创
永不言弃的黄金精神

作业链接:https://edu.cnblogs.com/campus/fzu/2019FZUSEZ/homework/9819
此次团队编程中,我主要编写第四模块
基本要求
-m 指定需统计的词组长度
-n 指定需要输出的词频排行的前n项4、统计文件中各词组(单词)的出现次数,最终只按照字典序输出频率最高的n个,n由输入参数指定。
- 该功能不影响单词总数统计
- 同一词组(单词)不区分大小写;例如,file、File和FILE是同一个单词
- 频率相同的单词,优先输出字典序靠前的单词,例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式。
在经过队友把文本内容处理之后,会变成如下格式。
格式:去掉不是规定单词的单词,单词之间只用空格隔开,可以多个空格,单词的字母数大于等于4。
样例
标准样例
文件输入
Monday Tuesday Wednesday Thursday
Friday
文件输出
<monday tuesday wednesday>: 1
<tuesday wednesday thursday>: 1
自定义样例
文件输入
Iiii loove china china love iiii
dsaaa bdsadsb AAAa aaaa aaaa aaaa aaaa AAAA
Posoa jihoasj akkkp jihoasj akkkp
文件输出
<aaaa aaaa aaaa>: 4
<akkkp jihoasj akkkp>: 1
<bdsadsb aaaa aaaa>: 1
<china china love>: 1
<china love iiii>: 1
<dsaaa bdsadsb aaaa>: 1
<iiii loove china>: 1
<jihoasj akkkp jihoasj>: 1
<loove china china>: 1
<posoa jihoasj akkkp>: 1
需要实现的功能
-
打开文件流
-
单行读入
-
以r'(+?)个空格分割,就是多个空格分割。
-
处理分割后的数据分组
-
统计词组 频
-
根据传参 m 和 n来输出规定格式数据
-
写规定格式数据流到文件
大致思路流程图
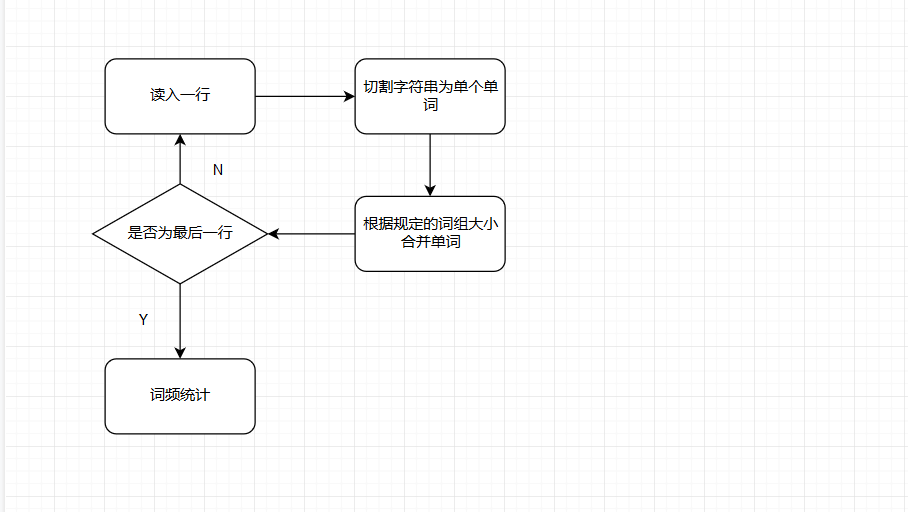
文本词组频统计算法简要介绍
切割聚合算法
对字符串切割并根据规定长度聚合词组函数算法,注释有算法介绍
//对字符串切割并根据规定长度聚合词组
vector<string> split(const string& str,const string& delim){
vector<string> res;
vector<string> result;
res.clear();
result.clear();
string ss;
//以delim切割字符串到string向量res里面
if("" == str) return res;
char* strs = new char[str.length() + 1];
strcpy(strs,str.c_str());
char* d = new char[delim.length() + 1];
strcpy(d,delim.c_str());
char* p = strtok(strs,d);
while(p){
string s = p;
res.push_back(s);
p = strtok(NULL,d);
}
if(res.size() >= m){//如果这一行的单词个数小于规定的词组长度,则不予加入词频的统计范围
//从此行第0个单词开始到 单词数-m 个单词
for(int kk = 0; kk <= res.size()-m; ++kk){
ss="";
//从第kk个单词开始,后数m个,将这些单词以规定格式聚合
for(int i = kk; i < kk + m -1; i++){
ss.append(res[i]) ;
ss.append(" ");
}
//最后一个单词后不聚合空格
ss.append(res[kk+m-1]);
//将聚合后的放入向量result中
result.push_back(ss);
}
}
return result;
}
我重载了sort算法用于词频排序,因为map本身就是按字典序排列所以我只需要按词频排序
bool cmp(const pair<string, int>& a, const pair<string, int>& b) {
return a.second > b.second;
}
统计词组的词频算法
string line; //保存读入的每一行
map<string,int> mp;
while(getline(f,line))//读入一行会自动把\n换行符去掉
{
//转小写
transform(line.begin(),line.end(),line.begin(),::tolower);
//空格分割后在all_str中保存单词
vector<string> all_str = split(line," ");
for(int i = 0; i < all_str.size(); ++i){
flag = 0;//定义flag标志此次词组是否出现
/*
flag==0未出现 map中插入词组及次数1
flag==1出现过 map.second的次数++
*/
for(map<string,int>::iterator j = mp.begin(); j != mp.end(); ++j){
pair<string,int> it = *j;
if(all_str[i] == it.first){
it.second++;
mp.erase(all_str[i]);
mp.insert(it);
flag = 1;
}
}
//若flag为0
if(!flag){
pair<string,int> p_tmp(all_str[i], 1);
mp.insert(p_tmp);
}
}
}
//将统计完成的词组及词频map插入到总的vec中排序
vector< pair<string, int> > vec(mp.begin(), mp.end());
sort(vec.begin(), vec.end(), cmp);
输入到文件流函数
//定义changdu为要输出的所有的词组的长度
/*
若未指定m,则changdu取10与所有词组总长度的最小值
若指定m,则changdu取m与所有词组总长度的最小值
*/
outfile.open(argv[outputpos],ios::app);
if (m != 0) {
if (vec.size() <= n)
changdu = vec.size();
else changdu = n;
for (int i = 0; i < changdu; ++i) {
outfile << "<" << vec[i].first << ">: " << vec[i].second << endl;
cout <<"<" << vec[i].first << ">: " << vec[i].second << endl;
}
} else {
if (vec.size() <= 10)
changdu = vec.size();
else changdu = 10;
for (int i = 0; i < changdu; ++i) {
outfile << "<" << vec[i].first << ">: " << vec[i].second << endl;
cout << "<" << vec[i].first << ">: " << vec[i].second << endl;
}
}
outfile.close();
编码体会
更进一步掌握了vector和map的用法及结合使用
程序截图
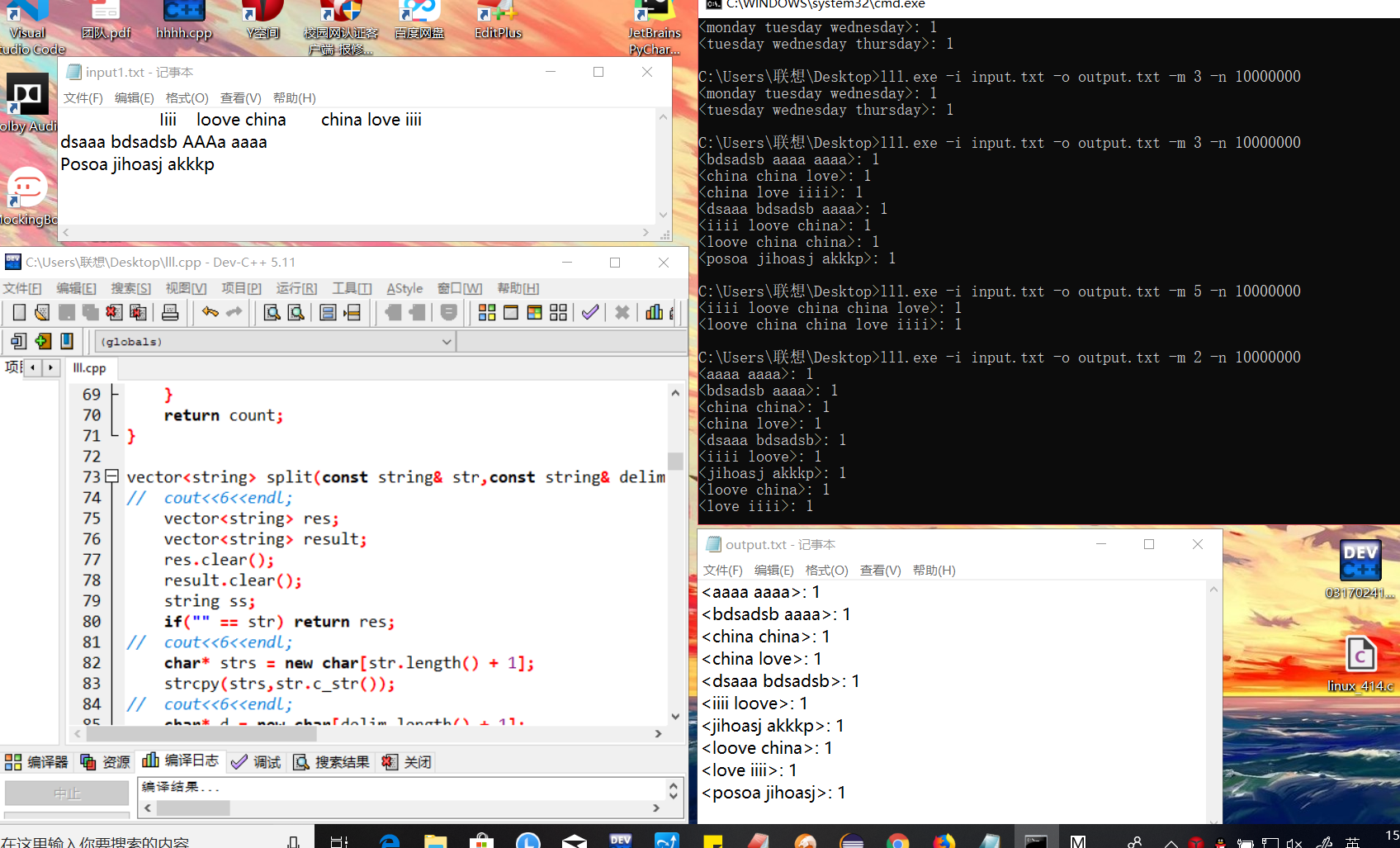
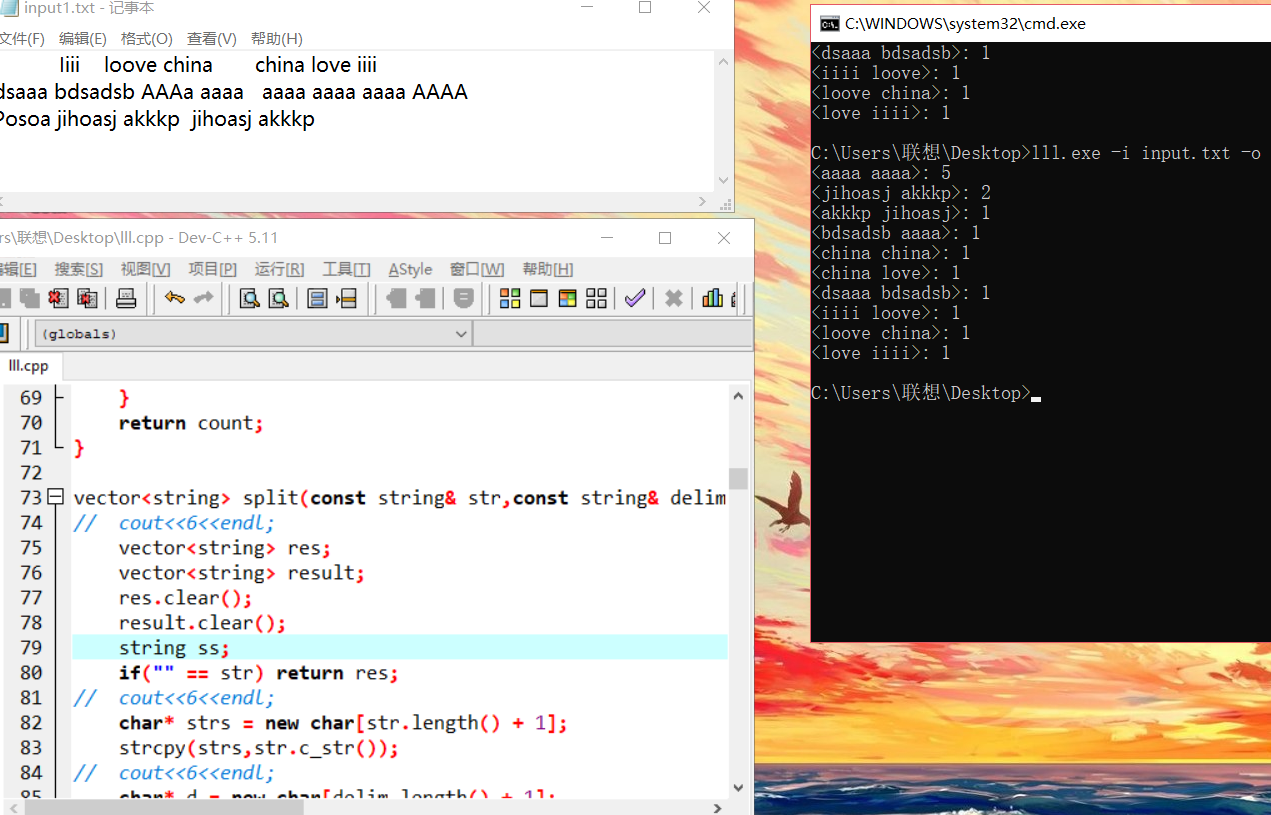
posted on 2019-10-20 18:46 Martrix-revolution 阅读(282) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号