scrapy tutorial
scrapy tutorial
scrapy的整体架构
-
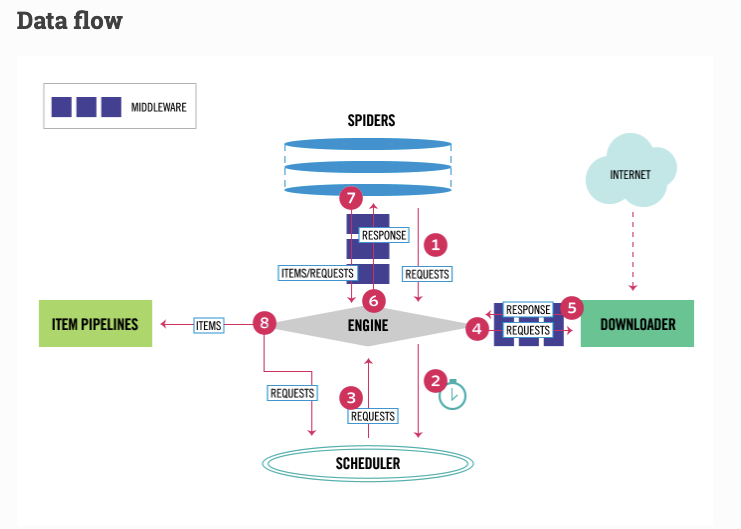
The data flow in Scrapy is controlled by the execution engine, and goes like this:
-
The Engine gets the initial Requests to crawl from the Spider.
-
The Engine schedules the Requests in the Scheduler and asks for the next Requests to crawl.
-
The Scheduler returns the next Requests to the Engine.
-
The Engine sends the Requests to the Downloader, passing through the Downloader Middlewares (see process_request()).
-
Once the page finishes downloading the Downloader generates a Response (with that page) and sends it to the Engine, passing through the Downloader Middlewares (see process_response()).
-
The Engine receives the Response from the Downloader and sends it to the Spider for processing, passing through the Spider Middleware (see process_spider_input()).
-
The Spider processes the Response and returns scraped items and new Requests (to follow) to the Engine, passing through the Spider Middleware (see process_spider_output()).
-
The Engine sends processed items to Item Pipelines, then send processed Requests to the Scheduler and asks for possible next Requests to crawl.
-
The process repeats (from step 1) until there are no more requests from the Scheduler.
使用Xpath而不是用CSS
Xpath 比CSS 更大、更强
官方提醒
While perhaps not as popular as CSS selectors, XPath expressions offer more power because besides navigating the structure, it can also look at the content. Using XPath, you’re able to select things like: select the link that contains the text “Next Page”. This makes XPath very fitting to the task of scraping, and we encourage you to learn XPath even if you already know how to construct CSS selectors, it will make scraping much easier.
Xpath的学习
scrapy doc
XPath 1.0 Tutorial
this tutorial to learn “how to think in XPath”.
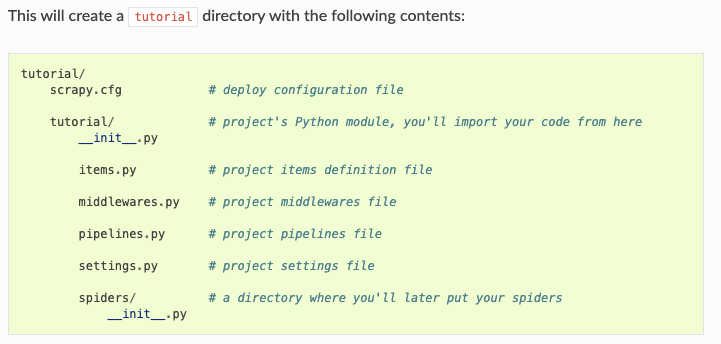
创建一个爬虫项目
scrapy startproject tutorial
保存爬取的数据
scrapy crawl quotes -O quotes.json
大O 表示会重写文件
小o表示追加内容到文件
item pipeline
在小项目中不需要写item pipeline 但是如果对item进行复杂的处理 就需要写
换句话说,如果要处理item,可以在item pipeline中写代码进行控制处理
In small projects (like the one in this tutorial), that should be enough. However, if you want to perform more complex things with the scraped items, you can write an Item Pipeline. A placeholder file for Item Pipelines has been set up for you when the project is created, in tutorial/pipelines.py. Though you don’t need to implement any item pipelines if you just want to store the scraped items.
shell
scrapy shell 'http://quotes.toscrape.com'
爬取下一页
方法一 使用 urljoin
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get() # 提取下一页的链接
if next_page is not None:
# print("before urljoin:",next_page) # /page/2/
next_page = response.urljoin(next_page) # amazing!!!
# print("after urljoin:",next_page) # http://quotes.toscrape.com/page/2/
yield scrapy.Request(next_page, callback=self.parse)
使用response.follow
使用相对地址即可访问 也是强👍🏻
Unlike scrapy.Request, response.follow supports relative URLs directly - no need to call urljoin.
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
print(next_page)
yield response.follow(next_page, callback=self.parse)
To create multiple requests from an iterable, you can use response.follow_all instead:
anchors = response.css('ul.pager a')
yield from response.follow_all(anchors, callback=self.parse)
# shortening
# yield from response.follow_all(css='ul.pager a', callback=self.parse)
多重解析 多个页面
import scrapy
class AuthorSpider(scrapy.Spider):
name = 'author'
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
# current page contains author_page_links and
# author_page_links = response.css('.author + a')
author_page_links = response.xpath('//div[@class="quote"]//span//a//@href') # scrapy.selector.unified.SelectorList
yield from response.follow_all(author_page_links, self.parse_author)
# pagination_links = response.css('li.next a')
pagination_links = response.xpath('//ul[@class="pager"]//a//@href')
yield from response.follow_all(pagination_links, self.parse)
def parse_author(self, response):
def extract_with_css(query):
return response.css(query).get(default='').strip()
name = extract_with_css('h3.author-title::text')
print(name)
yield {
'name': extract_with_css('h3.author-title::text'),
'birthdate': extract_with_css('.author-born-date::text'),
'bio': extract_with_css('.author-description::text'),
}
scrapy还为我们做了一件事,自动过滤已经爬取的页面
Another interesting thing this spider demonstrates is that, even if there are many quotes from the same author, we don’t need to worry about visiting the same author page multiple times. By default, Scrapy filters out duplicated requests to URLs already visited, avoiding the problem of hitting servers too much because of a programming mistake. This can be configured by the setting DUPEFILTER_CLASS.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号