
08 学生课程分数的Spark SQL分析
一.读学生课程分数文件chapter4-data01.txt,创建DataFrame。
1.用DataFrame的操作或SQL语句完成以下数据分析要求:

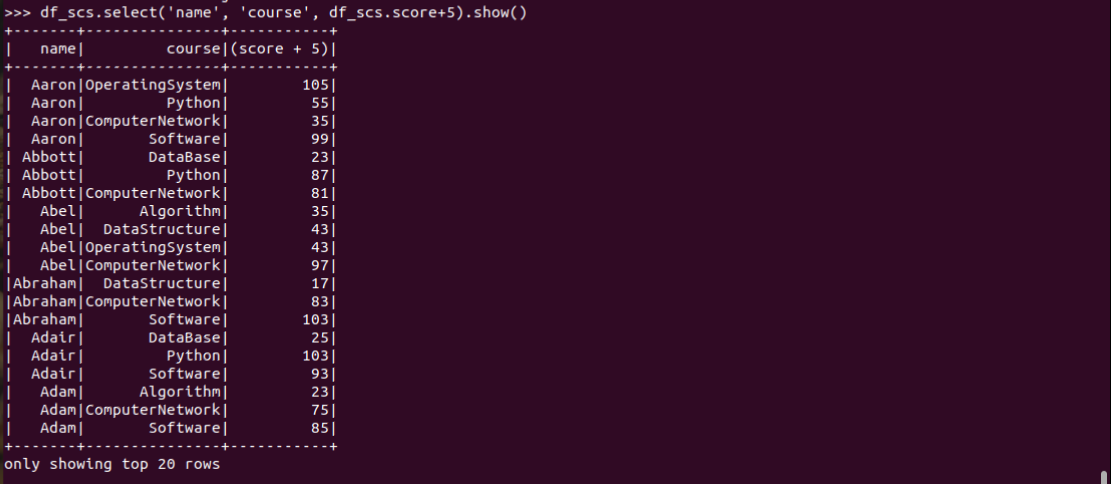
2.每个分数+5分。
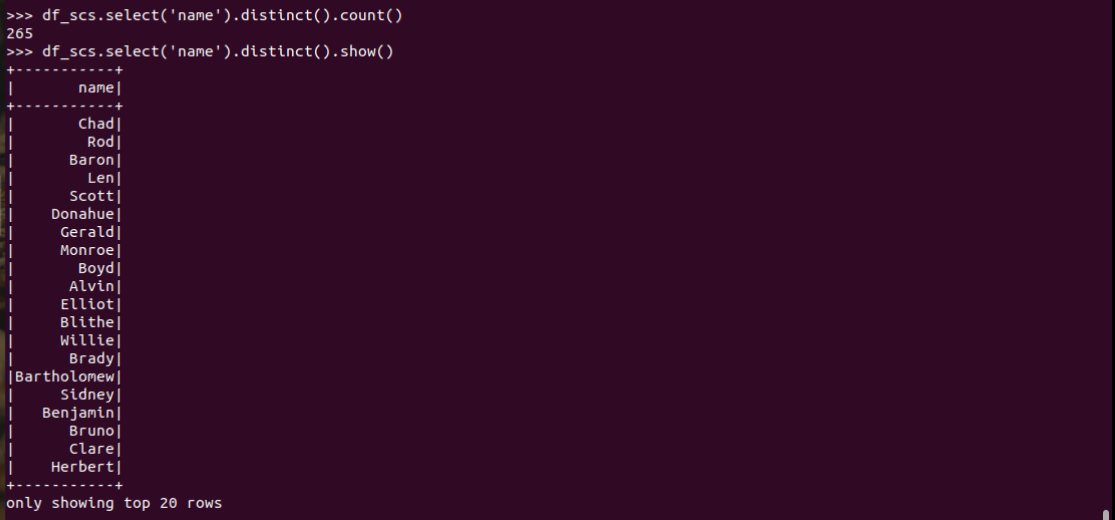
3.总共有多少学生?
4.开设了多少门课程?

5.每个学生选修了多少门课?

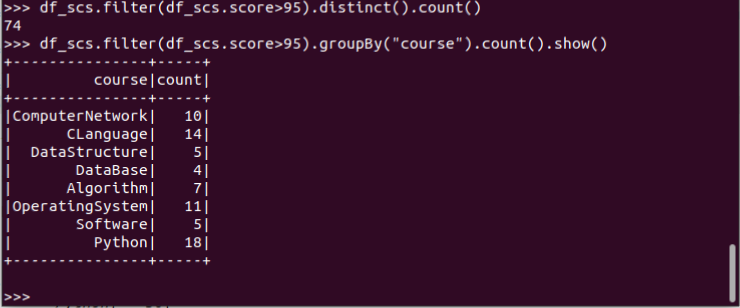
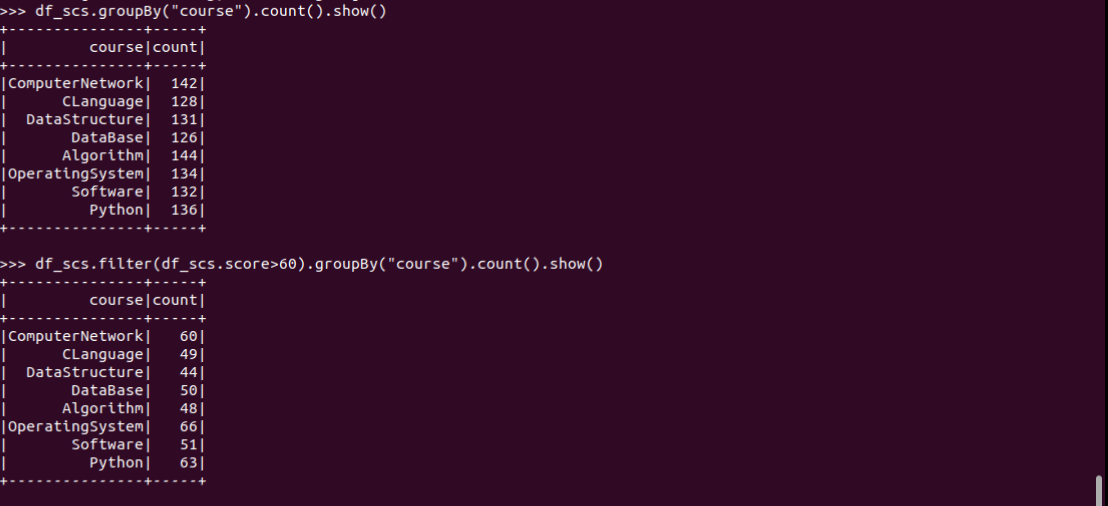
6.每门课程有多少个学生选?

7.每门课程大于95分的学生人数?
8.Tom选修了几门课?每门课多少分?

9.Tom的成绩按分数大小排序。

10.Tom的平均分。

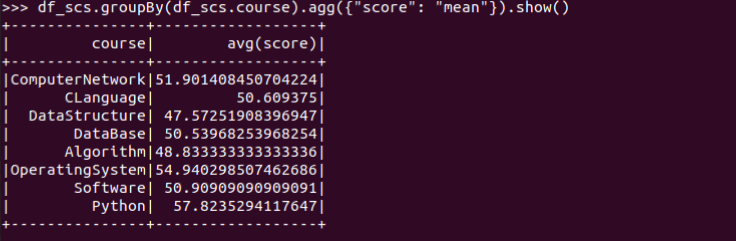
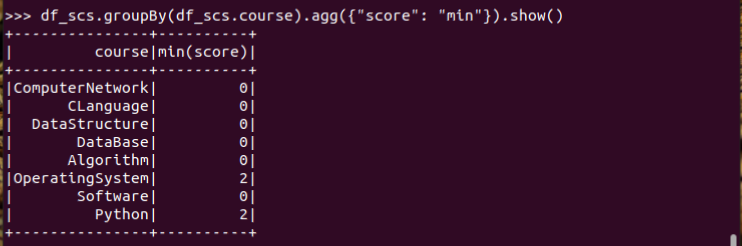
11.求每门课的平均分,最高分,最低分。

12.求每门课的选修人数及平均分,精确到2位小数。

13.每门课的不及格人数,通过率
先把60分以上的人数和总人数按照课程排序输出,然后就没有没有然后了,这个我是真不会\0皿0/。。。。
二.用SQL语句完成以上数据分析要求
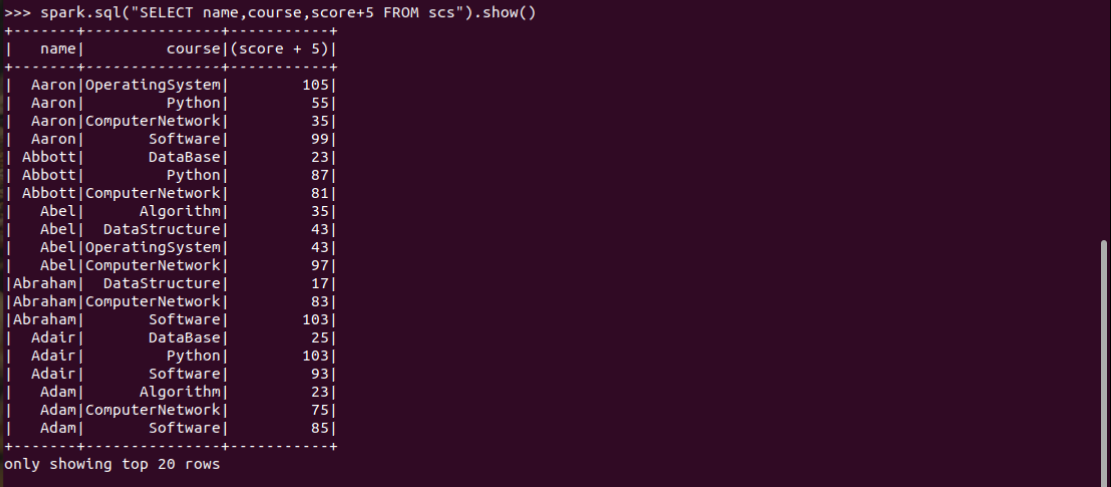
1.每个分数+5分
spark.sql("SELECT name,course,score+5 FROM scs").show()
2.总共有多少学生?
spark.sql("SELECT count(name) FROM scs").show()

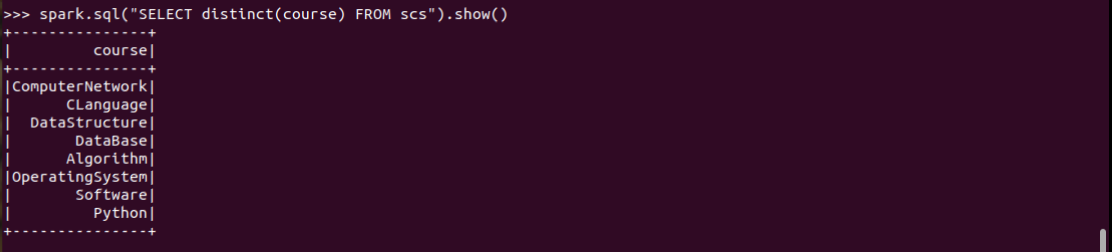
3.总共开设了哪些课程?
spark.sql("SELECT distinct(course) FROM scs").show()
4.每个学生选修了多少门课?
spark.sql("SELECT name,count(course) FROM scs group by name").show()

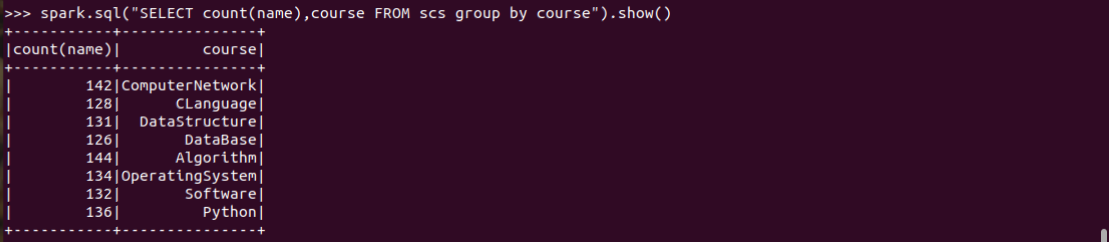
5.每门课程有多少个学生选?
spark.sql("SELECT count(name),course FROM scs group by course").show()
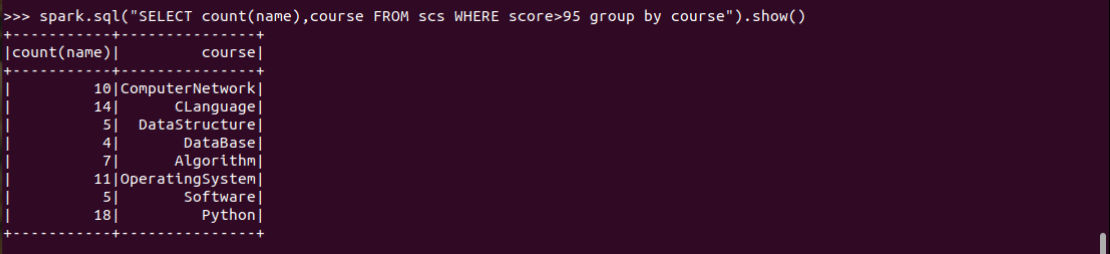
6.每门课程大于95分的学生人数?
spark.sql("SELECT count(name),course FROM scs WHERE score>95 group by course").show()
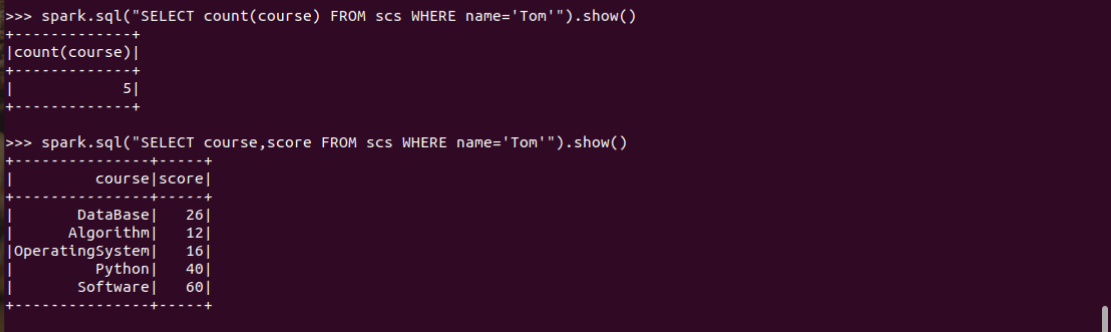
7.Tom选修了几门课?每门课多少分?
Tom选修了几门课?每门课多少分?
Tom的成绩按分数大小排序。
Tom的平均分。
spark.sql("SELECT count(course) FROM scs WHERE name='Tom'").show()
spark.sql("SELECT course,score FROM scs WHERE name='Tom'").show()
spark.sql("SELECT course,score FROM scs WHERE name='Tom' ORDER by score desc").show()
spark.sql("SELECT avg(score) FROM scs WHERE name='Tom'").show()


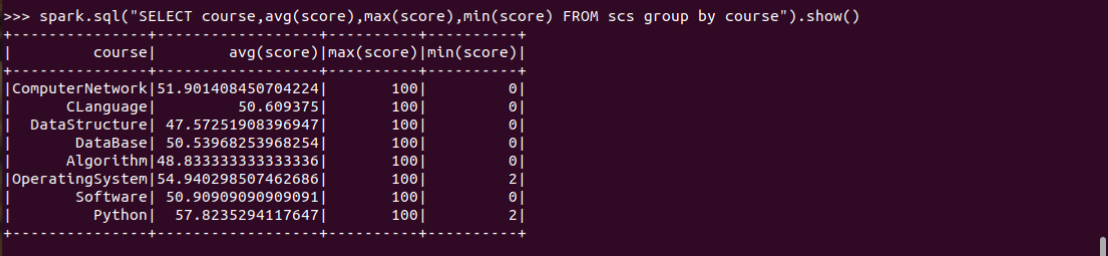
10.求每门课的平均分,最高分,最低分。
spark.sql("SELECT course,avg(score),max(score),min(score) FROM scs group by course").show()
11.求每门课的选修人数及平均分,精确到2位小数。
spark.sql("SELECT course,count(course),round(avg(score),2) FROM scs group by course").show()
12.每门课的不及格人数,通过率
spark.sql("SELECT course, count(name) as n, avg(score) as avg FROM scs group by course").createOrReplaceTempView("a")
spark.sql("SELECT course, count(score) as notPass FROM scs WHERE score<60 group by course").createOrReplaceTempView("b")
spark.sql("SELECT * FROM a left join b on a.course=b.course").show()
spark.sql("SELECT a.course, round(a.avg, 2), b.notPass, round((a.n-b.notPass)/a.n, 2) as passRat FROM a left join b on a.course=b.course").show()

三、对比分别用RDD操作实现、用DataFrame操作实现和用SQL语句实现的异同。(比较两个以上问题)
1.求每门课的选修人数及平均分,精确到2位小数。map(),round()
rdd操作

DataFrame操作
SQL语句
spark.sql("SELECT course,count(course),round(avg(score),2) FROM scs group by course").show()
2.总共有多少学生?map(), distinct(), count()
rdd操作

DataFrame操作
SQL语句
总结:
一、RDD
RDD的优点:
1.相比于传统的MapReduce框架,Spark在RDD中内置很多函数操作,group,map,filter等,方便处理结构化或非结构化数据。
2.面向对象编程,直接存储的java对象,类型转化也安全
RDD的缺点:
1.由于它基本和hadoop一样万能的,因此没有针对特殊场景的优化,比如对于结构化数据处理相对于sql来比非常麻烦
2.默认采用的是java序列号方式,序列化结果比较大,而且数据存储在java堆内存中,导致gc比较频繁
二、DataFrame
DataFrame的优点:
1.结构化数据处理非常方便,支持Avro, CSV, elastic search, and Cassandra等kv数据,也支持HIVE tables, MySQL等传统数据表
2.有针对性的优化,如采用Kryo序列化,由于数据结构元信息spark已经保存,序列化时不需要带上元信息,大大的减少了序列化大小,而且数据保存在堆外内存中,减少了gc次数,所以运行更快。
3.hive兼容,支持hql、udf等
DataFrame的缺点:
1.编译时不能类型转化安全检查,运行时才能确定是否有问题
2.对于对象支持不友好,rdd内部数据直接以java对象存储,dataframe内存存储的是row对象而不能是自定义对象
三、Sql语句
Spark SQL是spark套件中一个模板,它将数据的计算任务通过SQL的形式转换成了RDD的计算,类似于Hive通过SQL的形式将数据的计算任务转换成了MapReduce。
Spark SQL的特点:
1、和Spark Core的无缝集成,可以在写整个RDD应用的时候,配置Spark SQL来完成逻辑实现。
2、统一的数据访问方式,Spark SQL提供标准化的SQL查询。
3、Hive的继承,Spark SQL通过内嵌的hive或者连接外部已经部署好的hive案例,实现了对hive语法的继承和操作。
4、标准化的连接方式,Spark SQL可以通过启动thrift Server来支持JDBC、ODBC的访问,将自己作为一个BI Server使用
参考文章:https://blog.csdn.net/weixin_39793644/article/details/79050762
https://www.jianshu.com/p/832964384253

 浙公网安备 33010602011771号
浙公网安备 33010602011771号