【论文笔记】Federated Learning in Mobile Edge Networks: A Comprehensive Survey(综述)
Federated Learning in Mobile Edge Networks: A Comprehensive Survey
| Authors | Wei Yang Bryan Lim、Nguyen Cong Luong、Dinh Thai Hoang、Yutao Jiao、Ying-Chang Liang、Qiang Yang、Dusit Niyato、Chunyan Miao |
|---|---|
| Keywords | Federated learning; mobile edge networks; resource allocation; communication cost; data privacy; data security |
| Abstract | 由于其允许ML模型的协作训练和允许移动网络优化的DL,FL可以作为移动边缘网络中的使能技术进行服务。然而,在大规模和异构的移动边缘网络中,有着各种局限的异构设备参与其中,这带来了FL实现过程中通信代价、资源分配、隐私与安全的挑战。本文介绍了FL背景与基础,重点阐述了上述挑战并回顾了现存解决方案,接着,提出了移动边缘网络优化中FL的应用,最后,讨论了FL重要挑战与未来研究方向。 |
| Publication | COMMUNICATIONS SURVEYS & TUTORIALS 2020 |
| DOI | 10.1109/COMST.2020.2986024 |
1 INTRODUCTION
传统的云集中式方法(cloud-centric approach)将数据收集到云上集中处理,由于以下原因已经无法持续下去了:
- 隐私敏感性提升。
- 云集中式方法涉及高传播延迟,导致了一些需要做实时决策的应用不可接受的延迟。
- 数据传输到云计算来处理加重了主干网络的负担,尤其是在涉及非结构化数据的任务中。
如今数据主要分布在云外,移动边缘计算(Mobile Edge Computing,MEC)被提出,终端设备与边缘服务器计算与存储能力被用于将模型训练逼近数据产生的地方。终端边缘云计算网络由以下部分组成:
- 终端设备
- 边缘结点
- 云服务器
对于传统的MEC方法中的模型训练,一种协作范式被提出:训练数据首先被发送到边缘服务器训练DNN的浅层,然后更多计算敏感型任务被offload到云(如下图所示)。然而,这会导致通信代价并且尤其不适合需要持续训练的应用,另外边缘服务器上的数据处理仍然涉及用户隐私数据的传输。
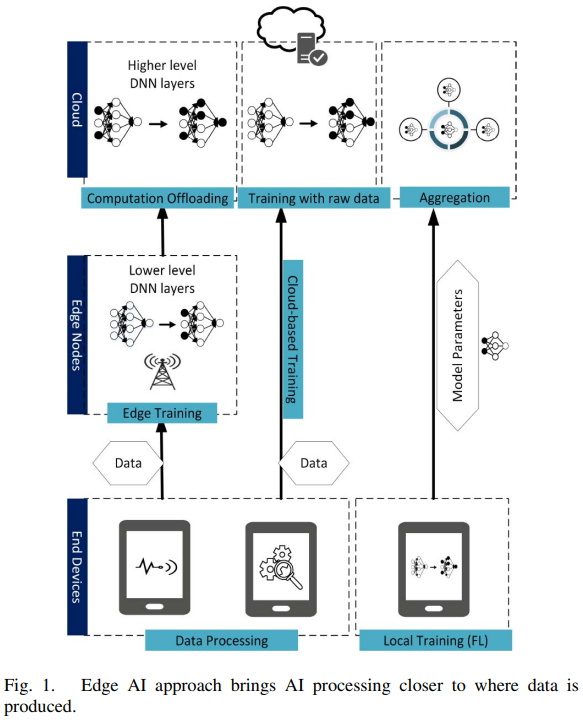
为了保证数据的训练保持在个人设备上,促进分布式设备上复杂模型的协作机器学习,一种叫作FL的分散式ML方法被提出。与传统云集中式(cloud-centric)训练方法相比,FL有以下特点:
- 网络带宽的高效利用:更少的信息上传到云,只需要上传更新参数而非原始数据。
- 隐私保护:基于FL参与者与服务器是非恶意的假设,它加强了用户隐私、降低了窃听的概率。有了强化的隐私保护,用户会更愿意参与到协作训练中。
- 低延迟:采用FL,ML模型可以被持续训练和更新。同时,在MEC范式中,实时决策可以在边缘结点或终端设备本地做出,这样比在云端做出决策然后传输给终端延迟要小很多。
除了作为移动边缘网络上ML模型训练的使能技术,FL也已经被应用为移动边缘网络优化的使能技术。考虑到日益复杂的移动边缘网络的计算和存储限制,基于静态模型的传统网络优化方法在建模动态网络时表现相对较差,例如,针对优化资源分配的基于数据驱动的DL方法日益流行。
然而,在FL大规模应用前有许多挑战:
- 由于高维度的模型更新与参与方受限的通信带宽,通信代价仍然是一个问题。
- 在数据质量、算力、参与训练的意愿上参与设备的异构性,这些方面需要从资源管理方面上做很好地管理。
- 对于恶意参与方或服务器,FL不能保证隐私,所以隐私与安全问题仍然需要考虑。
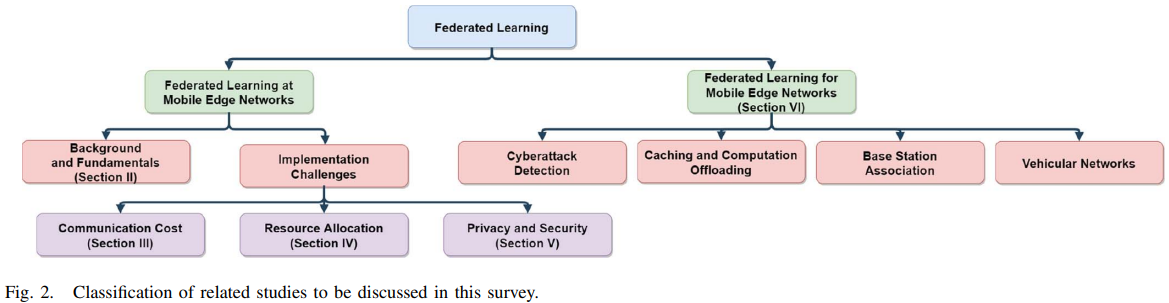
现有关于FL的研究工作没有考虑FL在移动边缘网络环境下的应用,而关于MEC的研究没有考虑FL实现的挑战或是FL应用于移动边缘网络优化的潜能。这驱使我们做一个有以下贡献的综合研究:
- 阐述FL重要性,然后提供FL简练教程和开源框架,为未来FL研究及应用铺平道路。
- 讨论了FL相比于集中式ML的特点及由此带来的实现挑战,针对每一个挑战讨论了现存方案。
- 讨论了FL作为移动边缘网络优化的使能技术,具体而言,讨论了当下的和潜在的FL在边缘计算中作为隐私保护方法的应用。
- 讨论了FL挑战及未来研究方向。
2 FL背景及基础
在传统的DNN训练中,基于云的方法是将数据集中到云端做训练,随着终端传感器与算力的不断提升,将智能从云带到边缘(例如在MEC范式中)成为一种自然的趋势,另外,在不断增长的隐私担忧之中,FL的概念被提出。
FL训练流程可以概括为两步:
- 终端设备上的本地模型训练。
- FL服务器上更新参数的全局聚合。
A 深度学习
传统的ML需要人工提取原始数据的特征,需要该领域的专家来做,并且每遇到一个新问题需要重新定制特征的提取。然而,DNN可以自动从原始数据中提取特征,有大量数据的情况下DNN优于传统ML。
DNN权重更新采用随机梯度下降法(Stochastic Gradient Descent,SGD):
注意,\((1)\)所示的SGD公式是mini-batch GD,\((2)\)由\(B\) batches的梯度矩阵的平均梯度矩阵得到,每个batch是包含\(m\)个样本的随机子集。
mini-batch GD相比于full-batch GD更受欢迎,full-batch GD即一次性将整个训练集作为一个batch计算偏导,导致缓慢的训练与批量记忆。
训练多epochs以最小化损失,每个epoch代表遍历一次整个训练集,包含若干batch。
B 联邦学习
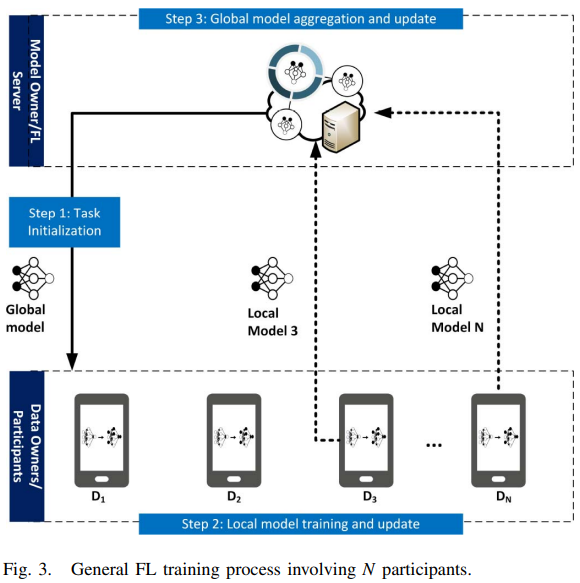
典型的FL系统架构与训练流程如下图所示,默认假设数据拥有者是诚信的(即他们使用真实的私人数据做训练并提交正确的本地模型到FL服务器),当然,这个假设有时不切实际,后面会讨论一些解决方案。
-
任务初始化:服务器决定训练任务,即目标应用以及相应的数据需求。服务器也要具体化全局模型的超参数与训练过程(例如学习率)。然后服务器广播初始化的全局模型\(w^0_G\)与任务到被选取的参与方。
-
本地模型训练与更新:基于全局模型\(w^t_G\)(\(t\)代表当前迭代序号),每个参与方\(i\)分别使用自己的本地数据与设备来更新本地模型参数\(w^t_i\)。更新后的本地模型再上传到服务器。
-
全局模型聚合与更新:服务器聚合来自各参与方的本地模型,然后将更新后的全局模型参数\(w^{t+1}_G\)发回到参与方。
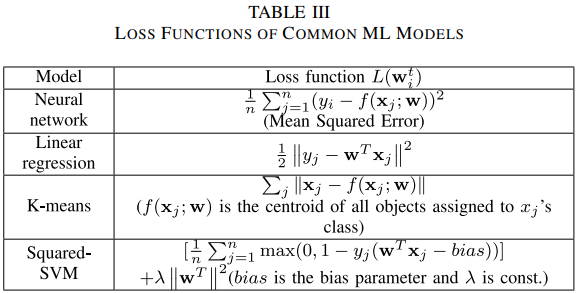
全局模型损失函数为\(L\left(\mathbf{w}_{G}^{t}\right)=\frac{1}{N} \sum_{i=1}^{N} L\left(\mathbf{w}_{i}^{t}\right)\)。
重复步骤2-3直到全局损失函数收敛或达到一个令人满意的训练准确度。
注意,FL训练过程可被用于不同的采用SGD的ML模型(如SVM、NN、LR)。
一个直观而经典的叫作FedAvg的聚合算法伪代码如下:
C FL的统计学挑战
传统的分布式ML中,中心服务器可以接触到整个训练集。服务器可以将数据集分割成一个个遵从相似分布的子集,将子集发送到参与方做分布式训练。
FL环境下,参与方拥有的数据是Non-IID的,尽管Non-IID下FedAvg可以达到令人满意的效果,但是[65]却发现了特例。
FL参与方收集的数据是不平衡的,导致模型准确度恶化。Astraea框架被提出,一开始FL参与方发送数据分布到服务器,参与方在训练之前做再均衡(对小数据的类别做数据增强)。
- 从多任务学习中借鉴概念,相比于传统的损失函数(表III),损失函数改为任务之间关系的建模。然后MOCHA算法[72]被提出以解决最小化问题,并且可以自适应设备的资源限制,但是MOCHA不能用在非凸DL模型上。
- 相似的,从多任务学习中借鉴概念以解决FL的统计学异构问题,FEDPER方法被提出,FL参与方共享用FedAvg训练的基础层,然后每个参与方用自己的本地数据分别训练个性化层。
除了数据异构,分布式学习算法的收敛也是一个担忧,有以下改善方案。
- [75]提出FedProx。
- [76]提出LoAdaBoost FedAvg。
D FL协议与框架
为了解决拓展性,一种FL协议[77]被提出,该协议解决了关于不稳定设备连接与通信安全等问题。该FL协议(下图所示)由三个阶段组成:
- 选择:FL服务器选择一部分已连接的设备参加训练轮。选择的标准依照服务器的需求,例如训练效率。
- 配置:服务器根据聚合机制进行配置,例如简单或安全的聚合。然后服务器发送训练方案和全局模型给各个参与方。
- 报告:服务器从参与方收到更新,之后,进行模型聚合。
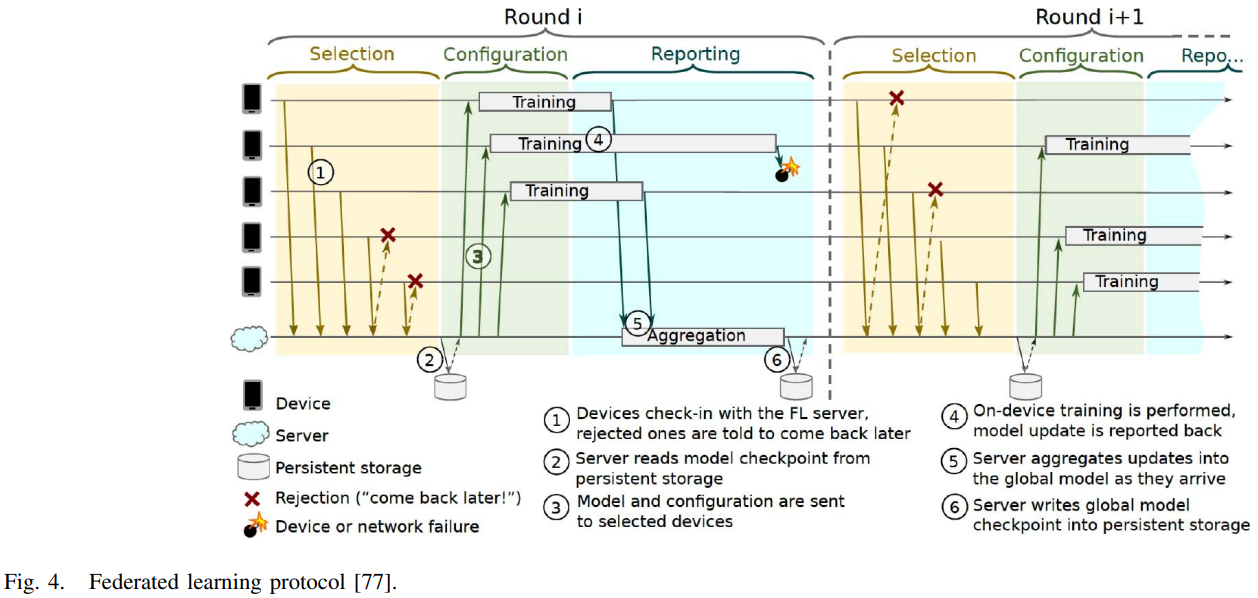
步速控制(Pace Steering)也是需要的,它可以自适应地为参与方管理优化时间窗口以重连到FL服务器。例如,当FL总量很小,pace steering用来确保有足够数量的参与设备与服务器同时相连;相反,当总量很大时,pace steering随机选取设备参与训练,防止过多设备接入一点。
除了通信效率,通信安全是另一个亟待解决的问题,其主要有两个方面:
- 安全聚合(Secure Aggregation):为了保护本地更新免受追踪和利用以推理出FL参与方的身份,为本地模型聚合部署一个信任的第三方服务器。秘密的分享机制也被用于经过身份验证过后的加密的本地更新的传输。
- 差分隐私(Differential Privacy):与安全聚合类似,差分隐私保护FL服务器以免识别出本地更新的拥有者。不同之处在于,为了达到隐私保护的目标,FL中的DP在原始本地更新中加入了一个确切等级的噪声,同时为模型质量提供理论保证。
开源框架:
- TensorFlow Federated(TFF)
- PySyft
- LEAF
- FATE
E FL特点与问题
相比于其他分布式ML方法,FL有以下特点:
- 缓慢且不稳定的通信:传统的分布式训练放在数据中心,通信环境可以假设完美(信息传输率很高且不丢包),然而这些假设不适用于异构设备参与训练的FL环境。例如,互联网上传的速度要比下载的速度慢很多、一些无线通信信道不稳定的参与方可能因此断网掉队。
- 异构设备:FL涉及到各种资源限制的异构设备。例如,设备算力不同、参与训练的意愿不同。
- 隐私与安全担忧:之前假设参与方于服务器是信任的,但是现实中可能有恶意者从参数中推理出敏感信息,这无疑否定了FL的“隐私保护”特性。
3 通信代价
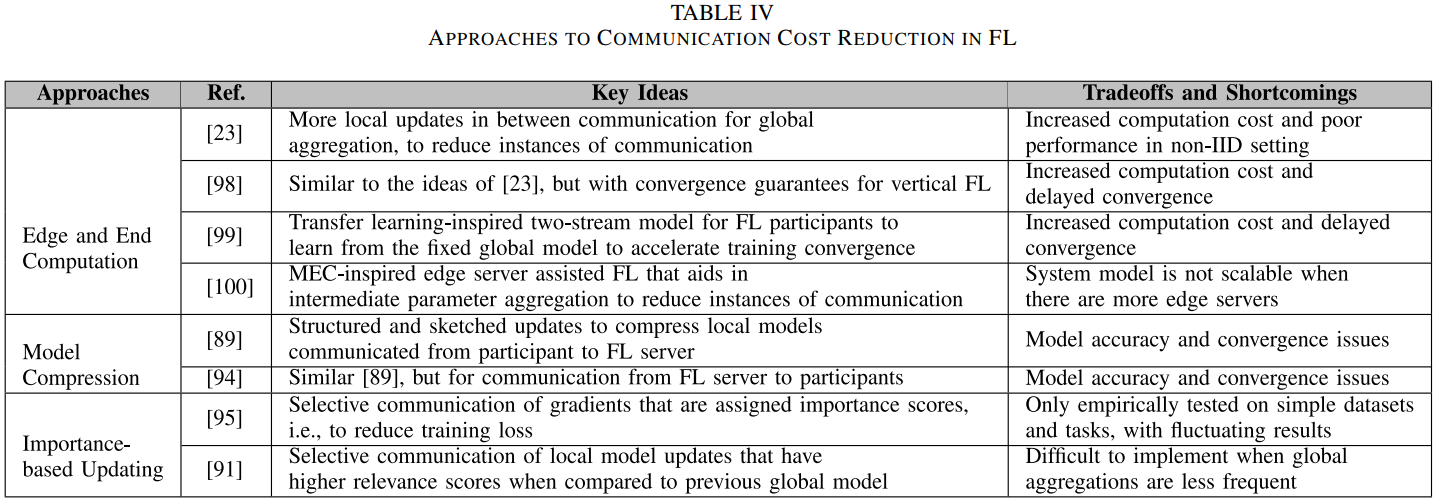
对于一些复杂的模型,更新参数数量可达几百万,加之不可靠的网络条件与网络连接速度的不对称,导致模型更新的延迟训练瓶颈。降低通信代价考虑了以下方法:
- 边缘与终端计算:FL环境下,通信代价往往主导了计算代价。因为设备上的训练集相对较小但是参与方处理器越来越快,另一方面,参与方可能只愿意在连接WIFI的时候参与训练。更多的计算可以放在边缘结点或终端设备上做,另外,确保更快收敛的算法会减少通信轮。
- 模型解压:这是通常用于分布式学习的技术。模型或梯度压缩涉及更新的通信,该更新被转换成更紧凑,例如通过稀疏化、量化或二次采样,而非传输整个更新。然而,自从压缩可能带来噪声,目标是保持训练模型质量的同时缩小更新规模。
- 基于重要性的更新:在每轮通信中,只有重要或相关的更新被传输。事实上,除了节省通信成本,省略一些更新甚至会提升模型表现。
A 边缘与终端计算
为了减少通信轮数量,可以把更多计算放到参与方终端上。
-
[23]中的作者考虑了两种增加参与设备计算量的方法:(1)增加并行性,即选择更多参与者参与每轮训练;(2)增加每个参与者的计算量,即每个参与者在通信之前执行更多的局部更新,以进行全局聚合。对FederatedSGD(FedSGD)算法和提出的FedAvg算法进行了比较。对于FedSGD算法,所有参与者都参与其中,每个训练轮只通过一次,其中batch大小包含参与者的整个数据集,这类似于集中式DL框架中的full-batch训练。模拟结果表明,一旦达到一定的阈值,提高并行性并不会显著降低通信成本,因此,更多的重点是增加每个参与者的计算量,同时保持选取的参与方的比例不变。此外,FedAvg最终会提高精度,因为模型平均会产生类似于退出[97]的正则化效果,从而防止过度拟合。
-
作为扩展,作者在[98]中还验证了与[23]中类似的概念。在纵向FL中,协作模型训练是在具有不同数据特征的同一组参与者中进行的。提出了联邦随机块坐标下降(Federated Stochastic Block Coordinate Descent,FedBCD)算法,其中每个参与设备在进行全局聚合通信之前首先执行多个局部更新。此外,收敛保证还提供了每个通信间隔的本地更新数量的近似校准。
降低通信成本也可以通过改进训练算法以提高收敛速度的方式。
- 通过上述的[76]的LoAdaBoost FedAvg。
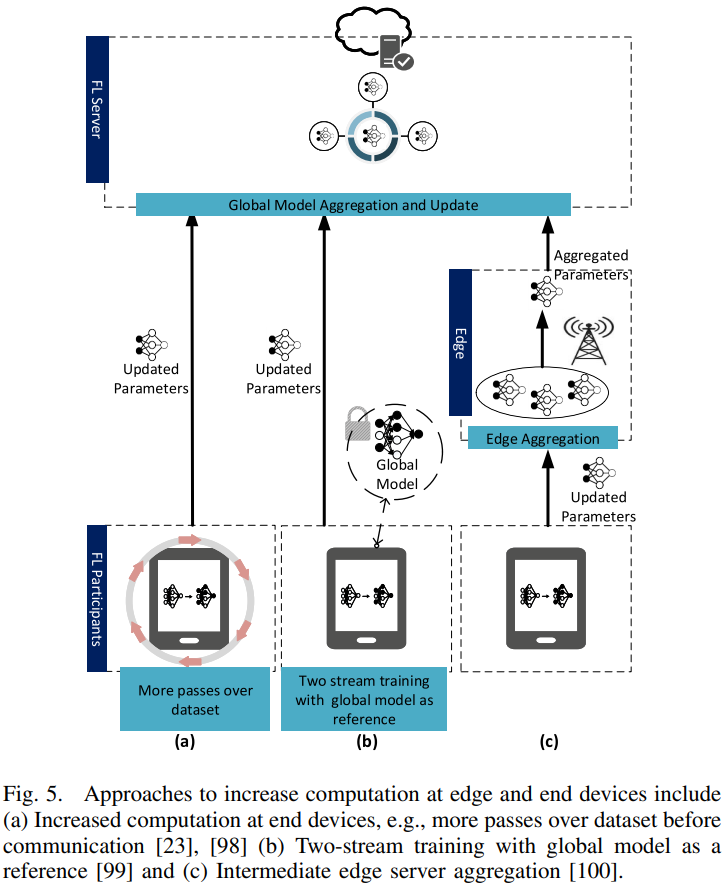
- 类似地,[99]还建议通过采用迁移学习和领域自适应[101]中常用的双流模型(下图(b))来增加每个参与设备的计算量。在每轮训练中,参与者都会收到全局模型,并在训练过程中将其固定为参考。在训练期间,学员不仅从本地数据中学习,还可以参考固定的全局模型从其他学员中学习,这是通过将最大平均偏差(MMD)纳入损失函数来实现的,参与者可以从全局模型中提取更多的广义特征,从而加快训练过程的收敛,减少交流次数。然而,在收敛速度提高的同时,对于上述方法,终端设备必须消耗更多的计算资源。特别是考虑到参与移动设备的电量限制,这就需要进行资源分配优化。
尽管上述研究考虑增加参与设备上的计算量,但[100]中的作者提出了一种受边缘计算启发的范例,其中,考虑到参与者到边缘服务器的传播延迟小于参与者云通信的传播延迟(下图(c)),邻近的边缘服务器可以充当中间参数聚合器。提出了一种分层FL(HierFAVG)算法,边缘服务器每更新几次本地参与者,就聚合收集的本地模型。在预定义数量的边缘服务器聚合之后,边缘服务器与云通信以进行全局模型聚合。因此,参与者和云之间的通信仅在多次本地更新间隔后发生一次。相比之下,对于[23]中提出的FedAvg算法,由于不涉及中间边缘服务器聚合,因此全局聚合发生得更频繁。在给定Non-IID用户数据的情况下,作者进一步证明了HierFAVG对凸和非凸目标函数的收敛性。仿真结果表明,与FedAvg算法相比,对于两个全局聚合之间相同数量的局部更新,在每个全局聚合之前进行更多的中间边缘聚合可以减少通信开销。这个结果适用于IID和Non-IID数据,这意味着可以在FedAvg之上实现边缘服务器上的中间聚合,以降低通信成本。然而,当应用于Non-IID数据时,模拟结果表明,HierFAVG在某些情况下无法收敛到所需的精度水平(90%),例如,当边缘云散度较大或涉及多个边缘服务器时。因此,需要进行进一步的研究,以更好地理解调整局部和边缘聚集间隔之间的权衡,从而确保HierFAVG算法的参数可以进行最佳校准,以适应其他环境。尽管如此,对于在移动边缘网络上实现FL,HierFAVG是一种很有前途的方法,因为它利用了中间边缘服务器的邻近性来降低通信成本,并可能减轻远程云的负担。
B 模型压缩
为了降低通信代价,[89]中的作者提出了结构化和草图更新,以减少参与者在每轮沟通中向FL服务器发送的模型更新的大小。
- 结构化更新(Structured updates)约束参与者更新使其拥有预先指定的结构,即低秩和随机掩码。对于低秩结构,每个更新都被强制为一个低秩矩阵,表示为两个矩阵的乘积。在这里,一个矩阵是随机生成的,在每一轮通信中保持不变,而另一个是优化的,因此,只需将优化后的矩阵发送到服务器。对于随机掩码结构,每个参与者更新被限制为一个稀疏矩阵,遵循在每一轮中独立生成的预定义随机稀疏模式,因此,只需要将非零条目发送到服务器。
- 草图更新(Sketched updates)指的是在与服务器通信之前以压缩形式对更新进行编码的方法,服务器随后在聚合之前对更新进行解码。草图更新的一个例子是子抽样方法,在这种方法中,每个参与者只传递更新矩阵的一个随机子集。然后,服务器对二次抽样更新进行平均,以得出真实平均值的无偏估计。另一个例子是概率量化方法[103],其中更新矩阵针对每个标量进行矢量化和量化。为了减少量化误差,在量化之前应用沃尔什-阿达玛矩阵和二进制对角矩阵[104]的乘积,即结构化随机旋转。
在CIFAR-10图片分类任务数据集上的模拟显示,对于结构化更新随机掩码表现更好,随机掩码准确度也比草图更新高,毕竟后者在训练过程中会抛弃一些信息。然而,三种草图工具(二次采样、量化、旋转)相结合可以达到更高压缩率和更快收敛,尽管准确率上有牺牲。另外,每轮参与训练的参与方越多草图更新准确率越高。
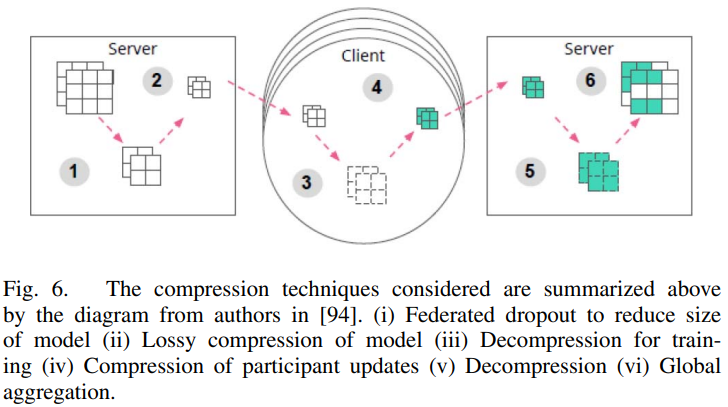
- [94]拓展了[89]的研究,提出有损压缩与联邦dropout以减少server-to-participant通信代价(如下图所示)。
除了二次采样和量化方法外,还考虑了联邦dropout方法,移除每个全连接层上固定数量的激活函数,以导出较小的子模型。然后将子模型发送给参与者进行训练。然后,可以将更新后的子模型映射回全局模型,以导出一个完整的DNN模型,并在随后的聚合过程中更新所有权重。这种方法降低了server-to-participant的通信成本,也降低了participant-to-server更新的规模。此外,由于需要更新的参数较少,因此减少了局部计算。
上述两项研究提出了有用的模型压缩方法,可以降低server-to-participant和participant-to-server的通信成本。通信成本的降低伴随着模型准确性的牺牲,因此,将压缩精度的权衡形式化是很有用的,尤其是因为对于不同的任务,或者当涉及不同数量的FL参与者时,这种权衡是不同的。
C 基于重要性的更新
-
基于DNN模型绝大部分参数是稀疏分布的且接近于0的观测,[95]提出了边缘随机梯度下降(edge Stochastic Gradient Descent,eSGD),只选取一小部分重要梯度用于与FL服务器通信更新。但是与标准SGD相比还是有正确率损失,并且基于超参数的使用模型正确率与收敛速度非常不稳定。
-
[91]提出通信缓解学习(Communication-Mitigated Federated Learning,CMFL),只上传相关本地模型更新以减少通信代价,同时保证全局收敛,节省了通信轮,甚至还略微提升了准确度(因为丢弃不相关更新一定程度上清除了伤害训练的离群点)。
D 总结与经验教训
本部分主要回顾了减轻通信代价的三个主要途径(文献如下表所示),经验教训有:
- 在实现大规模FL之前,通信代价是一个重要问题。
- 要管理好“降低通信代价”与其他损失之间的权衡。
- 目前对这种权衡的研究通常主要是经验性质的,随着更有效的优化方法在理论上的形式化和经验测试,FL最终可以变得更具可扩展性。
- FL的研究还可以从MEC范式中的应用和方法中获得启发,对于未来的工作,可以通过多任务学习的启发来应对Non-IID这一统计挑战。此外,可以探索更有效和创新的系统模型,以便FL网络可以利用更接近数据源的大量计算和存储资源来促进高效的FL。
- 对于我们在本节中讨论的研究,通常不考虑移动设备之间的异构性,例如计算能力。对于处理能力较弱的设备,上述的方法(例如增加边缘设备上的计算量)可能也不可行,并可能导致掉队效应。因此,我们将在下一节进一步探讨资源分配问题。
4 资源分配
参与FL的设备是异构的:不同的数据集质量、算力、电量状态、参与训练的意愿。在设备异构与资源限制下,资源分配必须被优化以最大化训练效率。具体而言,下面几个问题需要被考虑:
- 参与方选择:通常参与方是随机选取的,FL训练进展被最慢的参与方给限制了。
- 联合广播与计算资源管理:即使移动设备算力迅速提升,许多设备仍面临广播资源的缺乏。
- 自适应聚合:传统聚合方法是同步方式,每隔固定时间间隔聚合一次。全局聚合频率的自适应校准会提高训练效率。
- 激励机制:在FL实践过程中,因为模型训练消耗资源,没有补偿参与方可能不情愿参与训练。另外,FL服务器与参与方存在信息不对称,参与方对自己的可用计算资源及数据质量有更好了解,因此激励机制必须精心设计,既能激励参与,又能减少信息不对称的潜在不利影响。
A 参与方选择
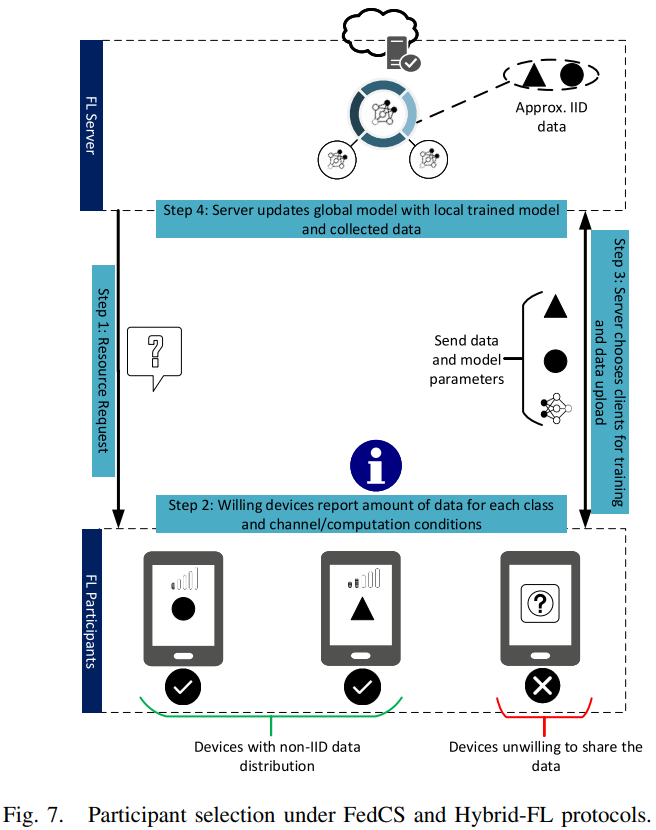
- [78]提出一个新的FL协议叫作FedCS(如下图所示),该系统模型是一个MEC框架,MEC的运营商是在蜂窝网络中协调训练的FL服务器,蜂窝网络由有着异构资源的参与方移动设备组成。FL服务器首先执行资源请求步骤,以从随机选择的参与者收集诸如无线信道状态和计算能力之类的信息。MEC运营商根据这些信息,为后续的全局聚合阶段选择在预先指定的截止时间内完成训练的最大可能参与者人数。通过在每一轮中选择尽可能多的参与者,可以保持训练的准确性和效率。
- 虽然FedCS解决了FL参与者之间的资源异构性问题,但[118]中的作者将FedCS协议扩展为处理参与者之间数据分布差异的混合FL协议(Hybrid-FL)。FL的参与者数据集可能是Non-IID的,因为它反映了每个用户的特定特征。正如我们在第2-C节中所讨论的,Non-IID数据集可能会显著降低FedAvg算法的性能[65]。解决数据集Non-IID性质的一项拟议措施是向参与者分发公开可用的数据,从而减少他们的设备数据集与人口距离之间的EMD。然而,这样的数据集可能并不总是存在,出于安全原因,参与者可能不会下载它们。因此,另一种解决方案是使用有限数量的隐私敏感参与者的输入构建一个近似IID的数据集[118]。在Hybrid-FL中,在资源请求步骤(图7)期间,MEC操作员询问随机参与者是否允许上传其数据。在参与者选择阶段,除了根据计算能力选择参与者外,还以使其上传的数据可以在服务器中形成近似IID的数据集选择参与者,即每个类中收集的数据量具有相近的值(图7)。此后,服务器在收集的IID数据集上训练模型,并将该模型与参与者训练的全局模型合并。模拟结果表明,即使只有1%的参与者共享他们的数据,与前面提到的FedCS基准相比,Non-IID数据的分类精度也可以显著提高,因为FedCS基准根本不上传数据。然而,推荐的协议可能会侵犯用户的隐私和安全,尤其是在FL服务器恶意的情况下。如果参与者是恶意的,则可以在上传之前篡改数据。此外,提议的措施可能成本高昂,尤其是在视频和图像的情况下。因此,当参与者可以免费使用其他志愿者的工作时,他们不太可能自愿上传数据。为了可行性,需要一个精心设计的激励和声誉机制,以确保只有值得信赖的参与者才能上传他们的数据。
- 一般来说,FL在其上实现的移动边缘网络环境是动态的、不确定的,具有可变约束,例如无线网络和电量条件。为此,可以使用深度Q学习(Deep Q-Learning,DQL)优化模型训练的资源分配,如[119]所述。系统模型包括参与者,即移动设备,它们协作训练FL服务器所需的DNN模型。移动设备受到能源、CPU和无线带宽的限制。因此,服务器需要确定移动设备用于训练的适当数据量、能量和CPU资源,以最小化能量消耗和训练时间。移动设备的状态包括移动设备的数量、从服务器获取的能量。奖励定义为累积数据、能量消耗和训练延迟的函数。然后采用双深度Q网络(DDQN)[120]来解决服务器的问题。仿真结果表明,与贪婪算法相比,该方案能降低约31%的能量消耗,与随机方案相比,训练延迟降低了55%。
- 作为对[119]的拓展,[121]提出了一种采用DRL的资源分配方法。在没有移动网络的先验知识的情况下,FL服务器能够优化参与者之间的资源分配(如信道选择与设备电脑消耗)。
上述的资源分配方法关注改善FL训练效率,然而,这可能导致一些FL参与者由于资源限制在聚合阶段掉队。如果每次训练轮都选取高算力设备参与设备,那么FL模型就会被该设备的数据分布给过度代表了,因此,[117, 124]将公平性作为FL的一个附加目标,公平性在[124]中被定义为FL模型表现的变化幅度,如果测试正确率变化幅度大,表示缺乏公平性。
-
[124]提出q-Fair FL(q-FFL)算法,对FedAvg中的目标函数重新加权,将损失函数中更高的权重分配到有更高损失的设备中。修改后的目标函数如下:
\[\min _{w} F_{q}(w)=\sum_{k=1}^{m} \frac{p_{k}}{q+1} F_{k}^{q+1}(w) \]其中,\(F_k\)指标准的损失函数(表3),\(q\)指公平性的校准,即\(q=0\)返回传统FL目标函数,\(p_k\)指参与方\(k\)本地样本数量与总训练样本的数量的比例。实际上,这就是Agnostic FL(AFL)[117]的泛化。
-
[125]提出一种基于神经网络的方法预估FL训练过程中掉队的参与方的本地模型。
B 联合广播与计算资源管理
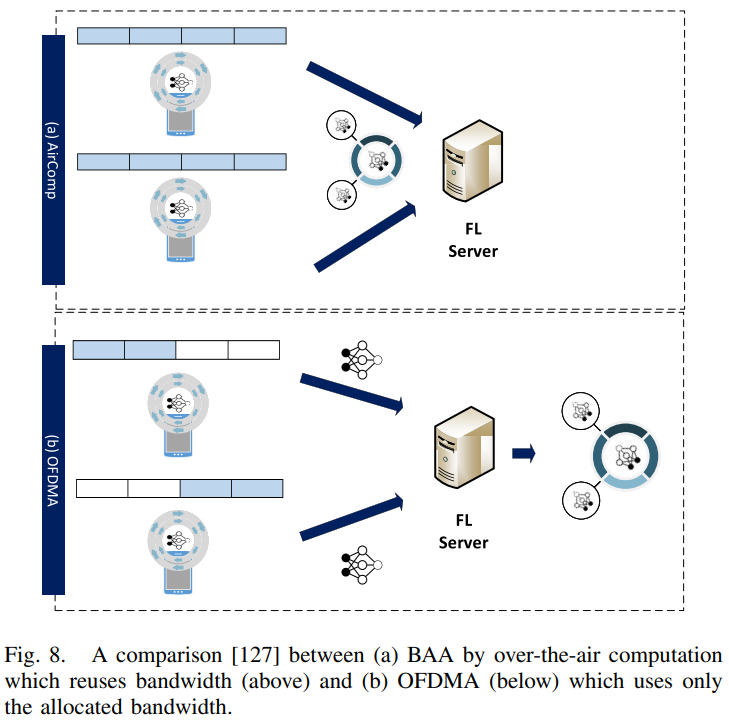
虽然之前大多数FL研究假设正交接入方案,如正交频分多址(OFDMA)[126],但[127]中的作者提出了一种多接入宽带模拟聚合(BAA)设计,以减少FL中的通信延迟。而不是在服务器的全局聚合期间单独执行通信和计算,BAA方案基于over-the-air计算[128]的概念,通过利用多址信道的信号叠加特性来集成计算和通信。所提出的BAA方案允许重用整个带宽(图8(a)),而OFDMA将带宽分配正交化(图8(b))。因此,对于正交接入方案,通信延迟与参与者数量成正比增加,而对于多接入方案,延迟与参与者数量无关。在BAA传输期间,信噪比(SNR)的瓶颈是传播距离最长的参与设备,因为距离较近的设备必须降低其传输功率,以便与距离较远的设备进行振幅对齐。为了提高信噪比,必须放弃传播距离较长的参与者。然而,这会导致模型参数的截断。因此,为了管理SNR截断权衡,考虑了三种调度方案,即i)Cell-interior调度:不调度超过距离阈值的参与者;ii)All-inclusive调度:考虑所有参与者;以及iii)Alternating调度:边缘服务器在上述两种方案之间交替。仿真结果表明,所提出的BAA方案可以实现与OFDMA方案相似的测试精度,同时将延迟从10倍减少到1000倍。作为三种调度方案的比较,对于参与者位置快速变化的高移动性网络,小区内部方案在测试精度方面优于全包方案。对于低移动性网络,交替调度方案优于小区内部调度。
- 作为扩展,[129]介绍了误差累积和梯度稀疏化,以及over-the-air计算。为了提高模型精度,首先将未传递的梯度向量存储在误差累积向量中。在下一轮中,使用误差向量校正局部梯度估计。此外,当存在带宽限制时,参与设备可以应用梯度稀疏化,以仅保留具有最高量级的元素进行传输。未传输的元素随后被添加到误差累积向量上,以便在下一轮中进行梯度估计校正。
- 与[129]类似,[130]中的作者提出了一种通过over-the-air计算将计算和通信集成起来的方法。然而,可以观察到,由于信号失真,over-the-air计算过程中产生的聚合误差可能会导致模型精度下降[131]。因此,提出了一种参与者选择算法,其中选择用于训练的设备数量最大化,以提高统计学习性能[23],同时将信号失真保持在阈值以下。由于均方误差约束的非凸性和优化问题的难处理性,提出了一种差分凸函数(DC)算法[132]来解决最大化问题。仿真结果表明,该算法具有良好的可扩展性,并能获得接近最优的性能,可与全局优化相媲美。全局优化由于其指数时间复杂度而不具有可扩展性。与其他最先进的方法(如半定松弛技术[133])相比,该算法可以选择更多的参与者,从而获得更高的精度。
C 自适应聚合
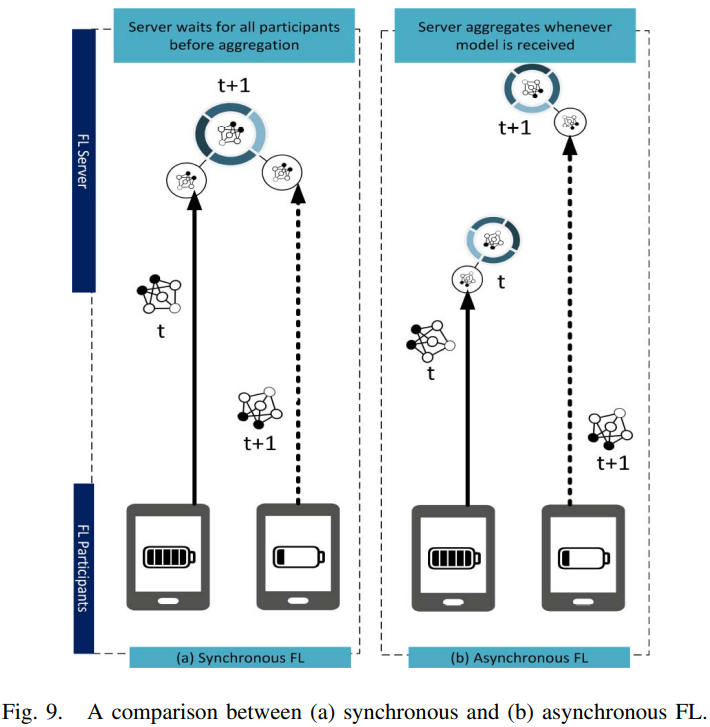
FedAvg算法聚合是同步方式的(如下图所示),很容易受掉队者的影响,另外,模型不考虑可以中途加入的参与者。对于异步FL,服务器任何时候收到本地模型都进行更新,这种方式是鲁棒的,但是当数据是Non-IID和不平衡的时候,模型收敛会延迟。
- 作为改善,[134]提出FedAsync算法,每个新接收的本地更新根据staleness被自适应地加权,staleness被定义为接收的更新所属epoch与iteration之间的差异。该算法虽然保证了非凸问题的收敛,但依然存在问题。
实际上,异步FL可靠性的不确定性使得同步FL至今还是应用更广泛。
对于现存的大多数FedAvg算法实现来说,全局聚合阶段发生在固定数量的训练轮之后。
- 为了更好地管理动态资源约束,[63]提出了一种自适应全局聚合方案,该方案改变了全局聚合频率,以确保理想的模型性能,同时确保在FL训练过程中有效利用可用资源,例如电量。
D 激励机制
-
[135]提出了一个服务定价方案,参与者作为模型所有者的训练服务提供者。此外,为了克服模型更新传输中的能量效率低下问题,提出了一种支持模型更新传输和交易的协作中继网络。参与者和模型所有者之间的互动被建模为Stackelberg博弈[136],其中模型所有者是买方,参与者是卖方。仿真结果表明,该机制可以保证Stackelberg均衡的唯一性,例如,包含有价值信息的模型更新在Stackelberg均衡中定价较高。此外,模型更新可以协同传输,从而减少通信中的拥塞,提高能源效率。然而,模拟环境只涉及相对较少的移动设备。
-
与[135]类似,[137]将参与者和模型所有者之间的交互建模为Stackelberg博弈,这非常适合表示FL中涉及的FL server-participant交互。
-
与上述解决Stackelberg公式不同,[138]提出了基于DRL的方法。在DRL公式中,FL服务器充当代理,根据边缘节点的参与程度和payment历史决定payment,目标是最小化激励费用。然后,边缘节点根据payment策略确定最优参与等级。这种基于学习的激励机制使FL服务器能够根据其观察到的状态导出最优策略,而不需要任何先验信息。
-
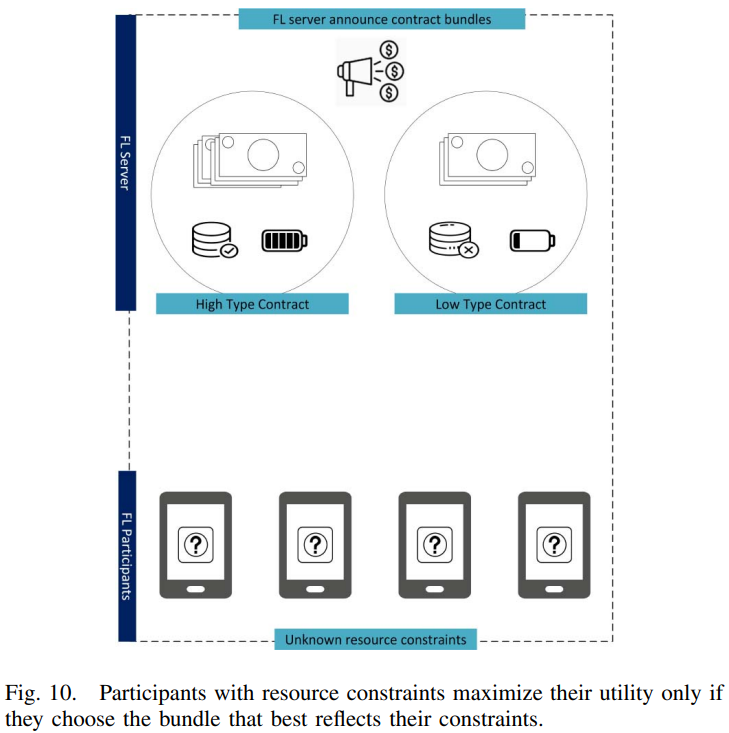
与[135, 137–139]相比,[140]中的作者提出了一种激励设计,使用契约理论[141]的方法吸引参与者提供高质量的FL数据。特别是,设计良好的契约可以通过自我揭示机制减少信息不对称,参与者只选择为其类型专门设计的契约。对于可行性,每个合同必须满足个人理性(Individual Rationality,IR)和激励相容性(Incentive Compatibility,IC)约束。对于IR,当参与者参与联邦时,每个参与者都被保证具有正效用。对于IC,每个效用最大化的参与者只选择为其类型设计的契约。模型所有者的目标是在IR和IC约束下实现自身利润最大化。如下图所示,所导出的最优契约是自我揭示的,因此具有较高数据质量的每个高类型参与者仅选择为其类型设计的契约,而具有较低数据质量的每个低类型参与者没有模仿高类型参与者的动机。仿真结果表明,所有类型的参与者只有在选择与其类型匹配的契约时才能实现最大效用。此外,与Stackelberg博弈方法相比,合同方法在模型所有者的利润方面具有更好的性能。这是因为在契约理论方法下,模型所有者可以从参与者那里获取更多利润,而在斯塔克伯格博弈方法下,参与者可以优化他们各自的效用。事实上,FL服务器和参与者之间的信息不对称使契约理论成为FL机制设计的强大而有效的工具。作为扩展,作者在[142]中介绍了一种多维契约,其中每个FL参与者确定其愿意为模型训练贡献的最佳计算能力和图像质量,以换取每次迭代中的合同奖励。
E 总结与经验教训
- 在异构移动网络中,资源分配的考虑对于确保高效FL很重要。
- 资源分配中存在着不同权衡需要考虑。
- 在Non-IID环境中的对非凸损失函数的收敛保证需要被考虑。
- 由于数据隐私担忧,FL服务器不能检查数据质量。现存研究[60, 135, 140]通常假设一个联邦享有垄断,特别的,每个系统模型被假设为只由多种与一个FL服务器协作的个人参与方所组成,这种环境下会有例外:(1)参与方之间的竞争导致参与方不愿参与训练;(2)服务器之间的竞争。未来工作可以结合考虑Stackelberg博弈与合同理论。
5 隐私与安全问题
保护参与方的隐私是FL的主要目标之一,基于FL参与方或服务器是“诚实的好人”的假设下,FL更新只传参的机制可以保护隐私,但是当参与方或服务器是恶意时,FL隐私与安全担忧不断提升。
- 隐私:即使FL在协作训练时不需要交换数据,恶意参与方仍然可以基于其他参与方共享的模型推理出敏感信息。因此,本部分讨论关于FL中共享模型的隐私问题及解决方案。
- 安全:在FL训练过程中会遭受各种攻击。本部分讨论FL新型攻击的更多细节及解决方案。
A 隐私问题
1)ML中的信息挖掘攻击——概览
- [147]表明存在从已训练好的模型中提取信息的可能性。
- [148]发展出了一种模型入侵(model-invasion)算法,该算法能高效从基于决策树或人脸识别的模型挖掘信息。
- [149]表明对于敌手来说,通过查询预测模型推理出受害者的信息甚至是可能的。
- 一些工作已经证明基于DNN模型在对抗模型提取攻击方面的脆弱性[150-152]。
2)针对FL参与方的基于差分隐私的保护方案
-
[20]引入了一种技术,叫作差分隐私随机梯度下降(differentially private stochastic gradient descent),可以在DL中高效实现。
-
[154]发展了一种可以达到更好隐私保护的方案,在这种方法中,作者提出了在向服务器发送经过训练的参数之前处理数据的两个主要步骤。特别是,对于每轮学习,聚合服务器首先选择随机数目的参与者来训练全局模型。然后,如果选择一名参与者在一轮学习中训练全局模型,该参与者将采用[20]中提出的方法,即在将训练参数发送给服务器之前,使用高斯分布向训练模型添加噪声。这样,恶意参与者就无法使用共享全局模型的参数推断其他参与者的信息,因为它没有关于谁参加了每轮训练的信息。
3)协作训练方案
尽管DP方案可以保护诚信参与方的隐私信息,但是这只在服务器是诚信的时起效。如果服务器是恶意的,将会导致更严重的隐私威胁。
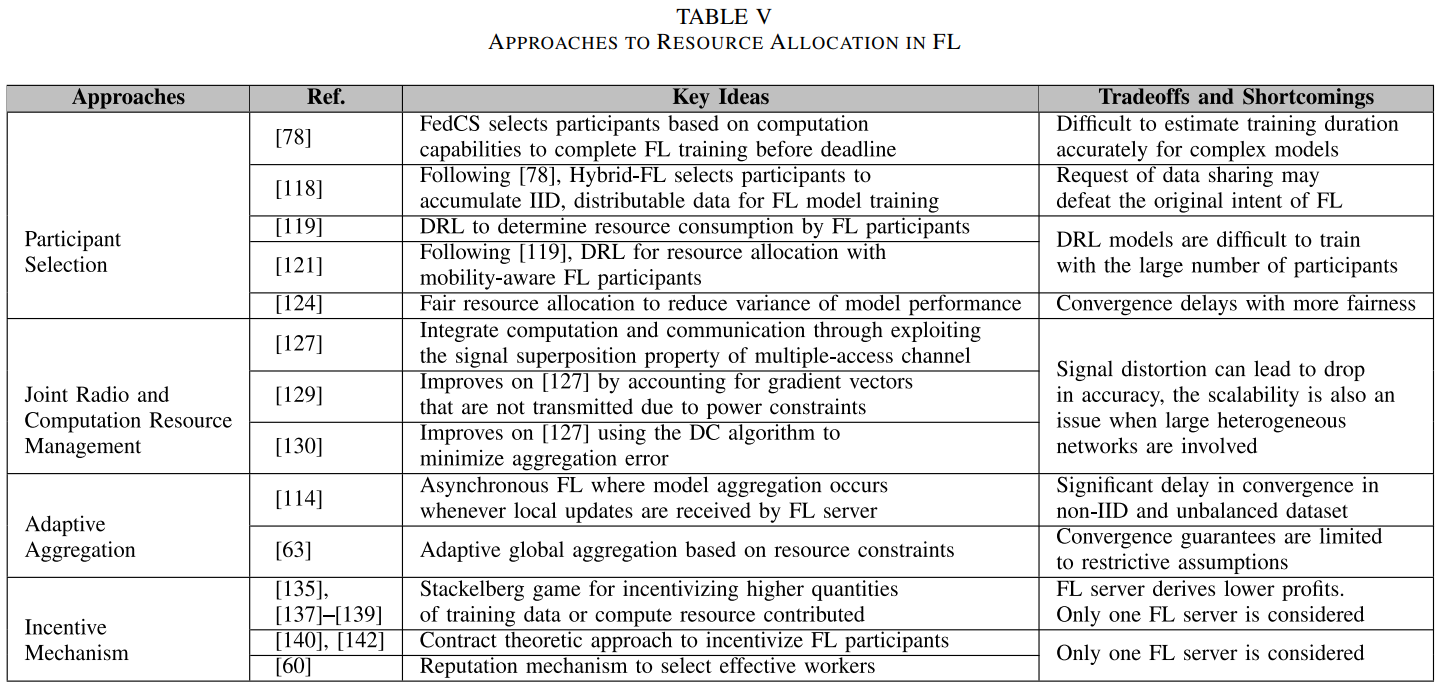
- [155]引入一种协作DL框架,使多参与方学习全局模型而无需上传它们显式的训练模型到服务器。如下图所示,每个参与方明智地从全局模型中选择要上传的梯度数量和要更新的参数数量,这样一来,恶意参与方就不能从共享模型中推理出明确信息。有趣的是,即使参与方不分享全部参数,不更新来自共享模型的全部参数,正确率依然接近服务器拥有全部数据做训练的情况。
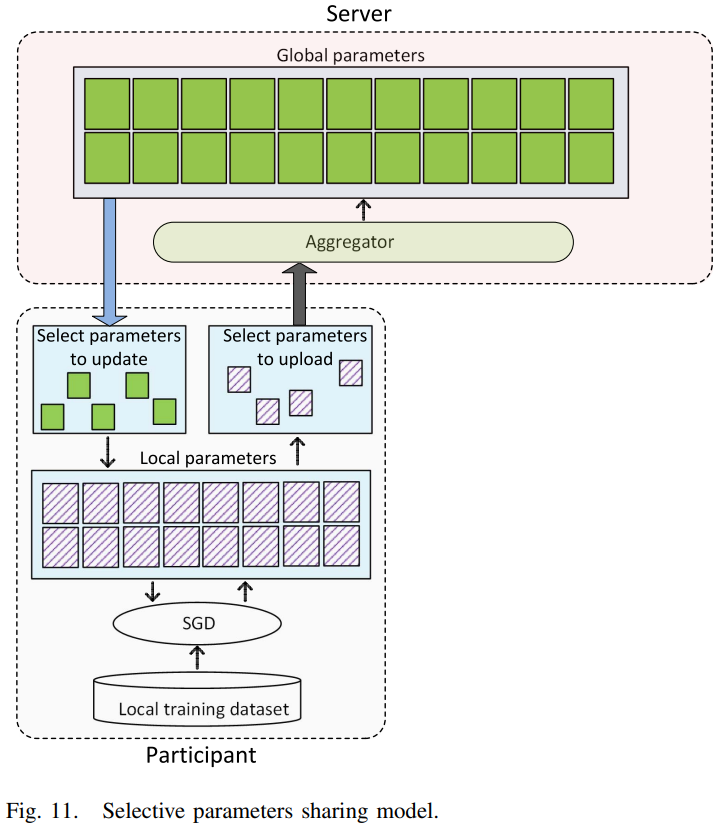
即使选择性地参数共享与DP方案可以一定程度上抑制信息挖掘攻击,但是[157]表明这些方案容易受一种叫作电量攻击(powerful attack)的新型攻击的影响(如下图所示),该攻击基于GANs。
- 为了应对GAN攻击,[159]引入了一种带有极端增强算法的采用秘密共享方案的方法。
- 不同于上述工作,[160]引入了一种协作训练模型,所有参与方合作训练一个联邦GANs模型。
4)基于加密的方案
加密是一种保护隐私的有效途径。
- [161]中,同态加密技术被引入对参与方的已训练的参数进行加密,然后将加密后的参数发送给服务器。该方法在保护好奇服务器敏感信息上很有效。
- [79]提出了相似的概念,采用秘密共享机制。
[161, 79]需要多轮通信,并且不能排除服务器与参与方之间的冲突。
- [162]提出一种混合方案,将额外的同态加密与DP融合起来,很好地解决了上述问题。
B 安全问题
1)数据投毒攻击(Data Poisoning Attacks)
FL环境下,对于服务器来说检查参与方真实的训练数据是一件棘手的事情。因此,一个恶意的参与方可以通过制造脏标签(dirty-label)数据向全局模型投毒,其可以对DL处理过程造成很大分类错误。
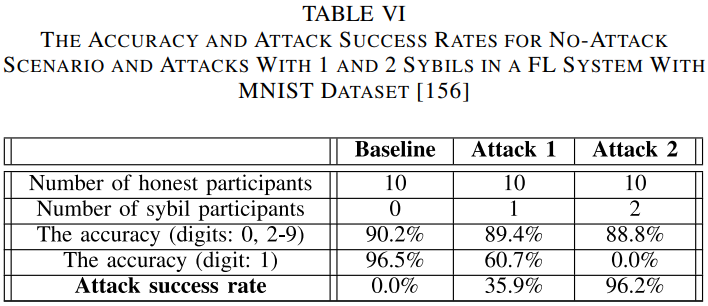
- 调查了基于sybil的数据投毒攻击对FL系统的影响。尤其是对于sybil攻击,恶意参与者试图通过创建多个恶意参与者来提高数据中毒在训练全局模型中的有效性。如下表所示,只有两个恶意参与者,攻击成功率可以达到96.2%。为了缓解sybil攻击,作者随后提出了一种防御策略,即FoolsGold,其关键思想是,诚实的参与者可以根据其更新的梯度与sybil参与者区分开来。
2)模型投毒攻击(Model Poisoning Attacks)
与数据投毒攻击的旨在生成假数据对全局模型造成不良影响不同,模型投毒攻击企图直接投毒即将用作聚合的全局模型。
[166, 167]表明,模型投毒攻击比数据投毒攻击更加有效,特别是在多参与方的大规模FL中。(原因是对于数据投毒攻击,一个恶意的参与方的更新会基于其数据集和FL参与方数量来缩放)
-
[166]提出了一些防止模型中毒攻击的解决方案。首先,基于参与者共享的更新模型,服务器可以检查共享模型是否有助于提高全局模型的性能。如果不是,该参与者将被标记为潜在的攻击者,在观察该参与者更新的模型几轮后,服务器可以确定这是否是恶意参与者。第二种解决方案基于参与者共享的更新模型之间的比较。特别是,如果某个参与者的更新模型与其他人的模型差异太大,则该参与者可能是恶意的。然后,服务器将继续观察该参与者的更新,然后才能确定这是否是恶意用户。然而,模型中毒攻击极难预防,因为在数百万参与者的训练中,很难评估每个参与者的改善情况。因此,需要进一步研究更有效的解决方案。
-
在[167]中,作者介绍了一种更有效的模型中毒攻击,该攻击被证明在一轮学习中就可以100%准确地完成攻击者的任务。特别是,恶意参与者可以共享其中毒模型,该模型不仅是为其故意目的而训练的,而且还包含后门功能。在本文中,作者考虑使用语义后门函数注入全局模型。原因是,即使不需要修改恶意参与者的输入数据,该函数也可以使全局模型错误分类。例如,图像分类后门功能可以将攻击者选择的标签注入具有某些特定特征的所有图像,例如,所有带有黑色条纹的狗都可能被错误分类为猫。仿真结果表明,该攻击的性能明显优于传统的FL数据中毒攻击。例如,在一个总共有80000名参与者的单词预测任务中,仅牺牲其中八人就足以实现50%的后门准确率,而执行数据中毒攻击需要400名恶意参与者。
3)搭便车攻击(Free-Riding Attacks)
当参与方想要从全局模型中获益而不想为学习过程做贡献,便采用搭便车攻击。恶意参与方(即搭便车的人)可以伪装有着小样本参与训练或者可以选择其数据集一小部分参与训练,这样一来,诚信的参与者需要在FL训练过程中贡献更多资源。
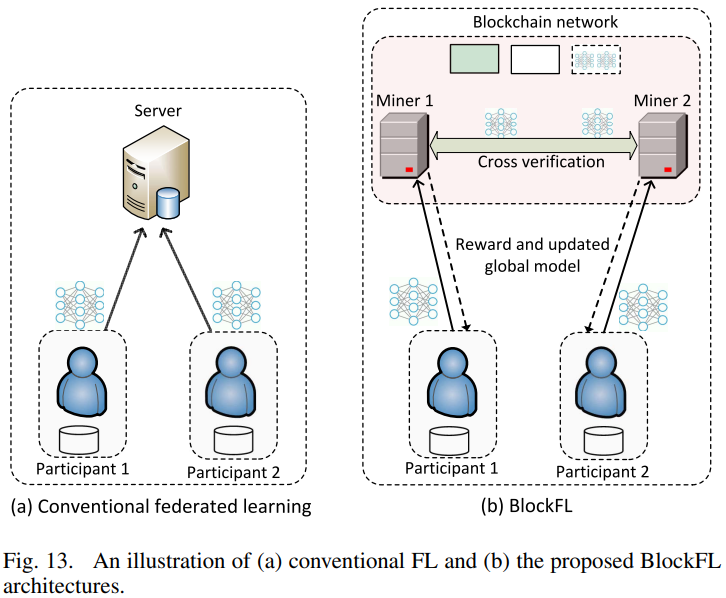
- [168]介绍了一种基于区块链的FL架构,称为BlockFL,在该架构中,参与者的本地学习模型更新通过利用区块链技术进行交换和验证。特别是,每个参与者训练并将训练过的全局模型发送给区块链网络中与其关联的矿工,然后获得与训练过的数据样本数量成比例的奖励,如下图所示。这样,这个框架不仅可以防止参与者搭便车,还可以激励所有参与者为学习过程做出贡献。
- [169]中还引入了一个类似的基于区块链的模型,为FL参与者提供数据保密性、计算可审计性和激励。然而,区块链技术的使用意味着实施和维护矿商运营区块链网络会产生大量成本。此外,区块链网络中使用的共识协议,例如工作证明(PoW),可能会导致信息交换的长时间延迟,因此它们可能不适合在FL模型上实施。
C 总结与经验教训
一般认为,FL是一种有效的隐私保护学习解决方案,可供参与者进行协作模型训练。然而,在本节中,我们已经展示了恶意参与者可以利用该进程并访问其他参与者的敏感信息。此外,我们还表明,通过使用FL中的共享模型,攻击者可以进行攻击,这不仅可以破坏整个学习系统,还可以篡改训练后的模型以达到其恶意目的。此外,还回顾了处理这些问题的解决方案,这对于指导FL系统管理员设计和实施适当的对策尤为重要。下表总结了攻击的关键信息及其相应的对策。
6 针对移动边缘计算的FL应用
本部分考虑FL在边缘计算中四个方面的应用:
- 网络攻击检测(Cyberattack Detection):无处不在的IoT设备与日益复杂的网络攻击预示着改善现存网络攻击检测工具的需要。
- 边缘缓存与计算卸载(Edge Caching and Computation Offloading):考虑到边缘服务器的计算和存储容量限制,终端设备的一些计算密集型任务必须卸载到远程云服务器进行计算。此外,通常请求的文件或服务应该放在边缘服务器上,以便更快地检索,也就是说,当用户想要访问这些文件或服务时,不必与远程云通信。因此,可以通过FL协作学习和优化最佳缓存和计算卸载方案。
- 基站联合(Base Station Association):在密集网络中,优化基站关联以限制用户面临的干扰非常重要。然而,利用用户数据的传统基于学习的方法通常假定这些数据是集中可用的。考虑到用户隐私限制,可以采用基于FL的方法。
- 车辆网络(Vehicular Networks):车联网(IoV)[171]的特点是智能车辆具有数据收集、计算和通信功能,用于相关功能,例如导航和交通管理。然而,这些丰富的知识在本质上又是隐私和敏感的,因为它可以揭示驾驶员的位置和个人信息。在本节中,我们将讨论基于FL的方法在IoV网络边缘的电动汽车充电站的交通队列长度预测和能源需求中的使用。
A 网络攻击检测
网络攻击检测是及时预防和减轻移动边缘网络攻击严重后果的最重要步骤之一。在检测网络攻击的各种方法中,DL被认为是以高精度检测各种攻击的最有效工具。
- [181]指出,DL在检测三个数据集上的入侵时,能够以非常高的准确度超过所有传统的ML技术,即KDDcup 1999、NSL-KDD[182]和UNSW-NB15[183]。然而,基于DL的解决方案的检测精度在很大程度上取决于可用的数据集。具体来说,DL算法只有在提供足够的数据进行训练时才能优于其他ML技术。然而,这些数据在本质上可能是敏感的。因此,一些基于FL的移动边缘网络攻击检测模型最近被引入来解决这个问题。
- [172]为授权的边缘网络提出了一个网络攻击检测模型。在该模型中,每个边缘节点作为一个参与者,拥有一组用于入侵检测的数据。为了提高检测攻击的准确性,每个参与者在训练完全局模型后,都会将训练好的模型发送到FL服务器。服务器将聚合来自参与者的所有参数,并将更新的全局模型发送回所有参与者,如下图所示。这样,每个边缘节点都可以从其他边缘节点学习,而无需共享其真实数据。因此,该方法不仅可以提高检测攻击的准确性,而且可以增强边缘节点入侵数据的隐私性,降低整个网络的流量负载。
- [173]中也提出了类似的想法,其中物联网网关作为FL参与者运行,物联网安全服务提供商作为服务器节点聚合参与者共享的经过训练的模型。[173]以经验证明,通过使用FL,系统可以在大约257毫秒的时间内成功检测到95.6%的攻击,而不会在实际智能家居部署环境中进行评估时发出任何虚假警报。
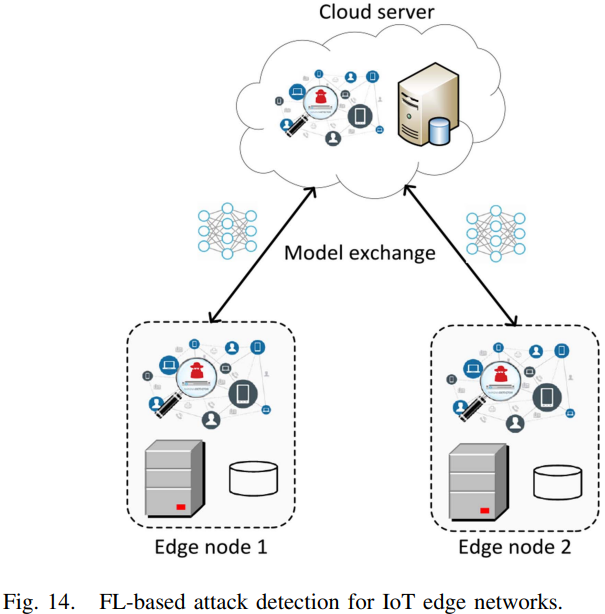
在[172, 173]中,都基于参与方(边缘结点与IoT网关)是诚信的,并且它们都愿意为模型参数更新做贡献。然而,如果参与方是恶意的,它们可以使整个入侵检测被破坏。
- 因此,[174]提出在管理被参与方共享的数据上采用区块链技术。
B 边缘缓存与计算卸载
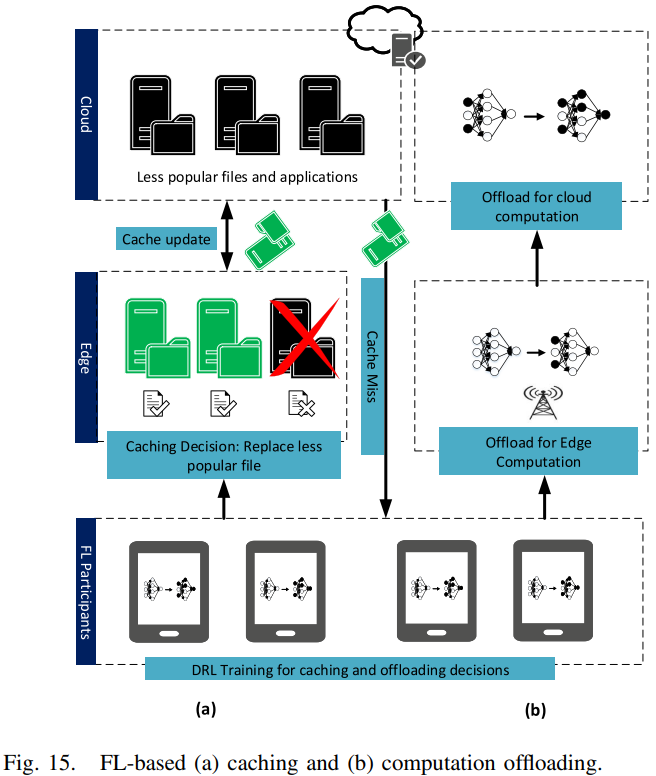
- 为了考虑MEC系统中的动态和时变条件,[32]建议使用DRL和FL来优化MEC系统中的缓存和计算卸载决策。MEC系统由基站覆盖的一组用户设备(User Equipments,UE)组成。对于缓存,DRL代理决定是否缓存下载的文件,以及在缓存发生时替换哪个本地文件。对于计算卸载,UE可以选择通过无线信道将计算任务卸载到边缘节点,或者在本地执行任务,该缓存和卸载决策过程如Fig.15所示。MEC系统的状态包括无线网络状况、UE能耗和任务队列状态,而奖励函数定义为UE的体验质量(Quality of Experience,QoE)。考虑到MEC环境中的大状态空间和大动作空间,采用了DDQN方法。为了保护用户的隐私,提出了一种FL方法,在这种方法中,可以在UEs上保留数据的情况下进行训练。此外,现有的FL算法,例如FedAvg,也可以确保训练对UE的不平衡和Non-IID数据具有鲁棒性。仿真结果表明,与集中式DDQN方法相比,采用FL的DDQN方法在UE间实现了相似的平均效用,同时消耗了更少的通信资源并保护了用户隐私。然而,模拟仅在10个UE的情况下执行。如果将实现扩展到针对更多的异构UE,则训练过程中可能会有显著的延迟,尤其是因为DRL模型的训练是计算密集型的。作为扩展,迁移学习[184]可用于提高训练效率,即训练不是从头开始的。
-
与[32]类似,[175]建议使用DRL优化物联网系统中的计算卸载决策。系统模型由物联网设备和边缘节点组成。物联网设备可以从边缘节点获取能量单元[185],以存储在能量队列中。此外,物联网设备还维护本地任务队列,其中包含未处理和未成功处理的任务。这些任务可以本地处理,也可以以先进先出(FIFO)的顺序卸载到边缘节点进行处理[14]。在DRL问题公式中,网络状态被定义为能量队列长度、任务执行延迟、来自边缘节点关联的任务切换延迟以及物联网设备和边缘节点之间的信道增益的函数。任务可能无法执行,例如,当没有足够的能量单元或通信带宽用于计算卸载时。考虑的效用是任务执行延迟、任务队列延迟、失败任务数和执行失败惩罚的函数。DRL代理决定将计算卸载到边缘节点,或者在本地执行计算。为了确保用户的隐私,对代理进行了训练,用户无需将自己的数据上传到中央服务器。在每轮训练中,随机选择一组物联网设备,从边缘网络下载DRL代理的模型参数。然后使用模型参数自身的数据(例如,能源水平、信道增益和本地传感数据)更新模型参数。然后,DRL代理的更新参数被发送到边缘节点进行模型聚合。仿真结果表明,基于FL的方法可以达到与集中式DRL方法相同的总效用水平。这对不同的任务生成概率是鲁棒的。此外,当任务生成概率更高时,即物联网设备中有更多的计算任务,基于FL的方案可以实现比集中式DRL方案更少的丢弃任务数和更短的排队延迟。然而,模拟仅涉及由相对多的边缘节点提供服务的15台物联网设备。为了更好地反映较少边缘节点必须覆盖多个物联网设备的实际情况,可以对优化边缘物联网协作进行进一步研究。例如,在计算卸载期间,有限的通信带宽可能会导致显著的任务切换延迟。此外,随着物联网设备的增多,DRL训练需要更长的时间才能收敛,尤其是因为这些设备具有异构计算能力。
-
[176]建议使用基于FL的堆叠式自动编码器学习模型,即基于FL的主动式内容缓存方案(FPCC),来预测优化缓存的内容受欢迎程度,同时保护用户隐私,而不是使用DRL方法。在系统模型中,每个用户都配备了一个移动设备,该设备连接到覆盖其地理位置的基站。使用堆叠式自动编码器学习模型,学习用户信息的潜在表示,例如位置和文件评级,例如内容请求历史。然后,获得用户与其历史上请求的文件之间的相似性矩阵,其中矩阵的每个元素表示用户与文件之间的距离。基于该相似矩阵,确定每个用户的K个最近邻居,并计算用户的历史观察列表和邻居之间的相似性。然后使用聚合方法预测最常用的缓存文件,即所有用户中相似度最高的文件。缓存文件是用户中最常用的文件,也是最频繁检索的文件,因此不需要每次都从源服务器重新下载。为了保护用户的隐私,FL被用来学习堆叠自动编码器的参数,而用户不必向FL服务器透露其个人信息或其内容请求历史。在每轮训练中,用户首先从FL服务器下载一个全局模型。然后,使用本地数据对模型进行训练和更新。更新后的模型随后上传到FL服务器,并使用FedAvg算法进行聚合。仿真结果表明,与其他缓存方法(如Thompson采样方法[186])相比,建议的FPCC方案可以实现最高的缓存效率,即缓存文件与用户请求匹配的比率。此外,用户的隐私也得到了保护。
-
[177]介绍了一种隐私感知服务放置方案,以在边缘服务器上部署用户首选的服务,同时考虑到边缘云中的资源限制。该系统模型由一个服务于各种移动设备的移动边缘云组成。用户偏好模型首先基于诸如服务请求次数等信息以及其他用户上下文信息(例如年龄和位置)来构建。然而,由于这可能涉及敏感的个人信息,因此提出了一种基于FL的方法来训练偏好模型,同时将用户的数据保存在个人设备上。然后,提出了一个优化问题,目标是在存储容量、计算能力、上行链路和下载带宽的约束下,根据用户偏好最大化边缘所需的服务数量。然后使用贪婪算法求解优化问题,即添加对目标函数改善最大的服务,直到满足资源约束。仿真结果表明,该方案在边缘云上处理的请求数量方面优于流行的服务放置方案,即只将最流行的服务放置在边缘云上,因为该方案在最大化服务数量时也考虑了上述资源约束。
C 基站联合
- [178]提出了一种基于FL的深度回声状态网络(Echo State Networks,ESNs)方法,以最大限度地减少虚拟现实(Virtual Reality,VR)应用程序用户的在场中断(Breaks In Presence,BIPs)[187]。BIP事件可能是信息传输延迟的结果,当用户的身体运动阻碍无线链路时,可能会导致信息传输延迟。BIP会让用户意识到自己身处虚拟环境,从而降低体验质量。因此,用户关联策略的设计必须使BIP最小化。系统模型由覆盖一组虚拟现实用户的基站组成。基站接收来自每个相关用户的上传跟踪信息,例如物理位置和方向,而用户下载VR视频以供在VR应用程序中使用。对于数据传输,VR用户必须与其中一个基站关联。因此,提出了一个最小化问题,其中BIP相对于虚拟现实用户的预期位置和方向最小化。为了得到用户位置和方向的预测,基站必须依赖用户的历史信息。然而,存储在每个基站的历史信息仅收集来自每个用户的部分数据,即,一个用户连接到多个基站,其数据分布在这些基站上。因此,实现了基于FL的方法,其中每个基站首先使用其部分数据训练本地模型。然后,对局部模型进行聚合,形成一个能够泛化的全局模型,即全面预测用户的移动性和方向。仿真结果表明,与[188]中提出的集中式ESN算法相比,联邦ESN算法可以实现用户体验到的较低BIP,因为集中式方法仅对来自单一基站的不完整数据进行部分预测,而联邦ESN方法可以基于从更完整的数据协同学习的模型进行预测。
随着物联网设备的普及,传统的基于云的方法可能不再足以满足密集蜂窝网络的需求。随着计算和存储移动到网络边缘,用户与基站的关联对于促进最终用户之间高效的ML模型训练变得越来越重要。
- 为此,[31]考虑用协作学习方法解决密集无线网络中的细胞关联问题。在系统模型中,基站覆盖LTE蜂窝系统中的一组用户。在蜂窝系统中,用户可能面临与其邻居相似的信道条件,因此可以从已经与基站相关联的邻居那里学习。因此,小区关联问题被描述为具有模仿的平均场博弈(Mean-Field Game,MFG)[189],其中每个用户最大化自己的吞吐量,同时最小化模仿成本。MFG进一步简化为单用户马尔可夫决策过程,然后通过神经Q-learning算法求解。在大多数其他提出的小区关联解决方案中,假设基站和用户都知道所有信息。然而,考虑到隐私问题,信息共享的假设可能并不实际。因此,可以考虑一种协作学习方法,其中在学习过程中仅交换学习算法的结果,而使用数据保存在每个用户自己的设备中。仿真结果表明,与非模仿用户相比,模仿用户可以在更短的训练时间内获得更高的效用。
D 车辆网络
车辆网络中的超可靠低延迟通信(Ultra reliable low latency communication,URLLC)是开发智能交通系统的必要先决条件。然而,现有的无线电资源管理技术并没有考虑到罕见的事件,例如在尾部分布的大队列长度。
- 为了模拟此类低概率事件的发生,[179]提出了极值理论(extreme value theory,EVT)[190]的使用。该方法需要足够的队列状态信息样本(queue state information,QSI)和车辆之间的数据交换。因此,提出了一种FL方法,其中车辆用户(vehicular users,VUE)使用本地保存的数据训练学习模型,并仅将其更新的模型参数上传到路边单元(roadside units,RSU)。然后,RSU计算出模型参数的平均值,并将更新后的全局模型返回给VUE。在同步方法中,所有VUE都会在预先指定的时间间隔结束时上传其模型。然而,多辆车同时上传可能会导致通信延迟。与异步方法不同,每个VUE仅在收集预定义数量的QSI样本后评估并上传其模型参数。当收到本地更新时,也会更新全局模型,从而减少通信延迟。为了进一步减少开销,还利用了功率分配的李雅普诺夫(Lyapunov)优化[191]。仿真结果表明,在该框架下,经历大排队长度的车辆数量减少,而FL可以确保相对于集中方法的最小数据交换。
除QSI外,车辆网络中的车辆还暴露于大量有用的捕获图像中,这些图像可用于建立更好的推理模型,例如用于交通优化。然而,这些图像本质上是敏感的,因为它们可以泄露车辆客户的位置信息。因此,FL方法可用于促进协作ML,同时确保隐私保护。然而,由于运动模糊,车辆拍摄的图像质量往往会有所不同。此外,异构性的另一个来源是车辆计算能力的差异。
-
考虑到所涉及的信息不对称,[142]提出了一种多维契约设计,其中FL服务器设计包含不同级别的数据质量、计算资源和契约报酬的契约包。然后,车辆客户根据其隐藏类型选择效用最大化的合同包。与[140]中的结果类似,模拟结果表明,与线性定价或Stackelberg博弈方法相比,FL服务器在提出的契约理论方法下获得了最大的效用。
-
[180]提出了一种联邦能源需求学习(federated energy demand learning,FEDL)方法来管理电动汽车(electric vehicles,EV)充电站(charging stations,CSs)中的能源。当大量电动汽车聚集在CS时,这可能会导致能量传输阻塞。为了解决这一问题,电力由电网供应,并提前预留,以满足电动汽车[192]的实时需求,而不是仅在收到充电请求时才从电网发出CSs能量请求。因此,需要使用历史充电数据预测电动汽车网络的能源需求。然而,这些数据通常单独存储在EV使用的每个CS中,本质上是私有的。因此,采用FEDL方法,每个CS在其自己的数据集上训练需求预测模型,然后仅向充电站提供商(charging station provider,CSP)发送梯度信息。然后,将来自CS的梯度信息进行聚合,以进行全局模型训练。为了进一步提高模型精度,根据CSs的物理位置,使用约束K-均值算法[193]对其进行聚类。基于聚类的FEDL降低了有偏预测的成本[194]。仿真结果表明,聚类FEDL模型的均方根误差低于传统的ML算法,例如多层感知器回归器[195]。然而,用户数据的隐私仍然不受这种方法的保护,因为用户数据存储在每个CS中。作为扩展,用户数据可以单独存储在每个电动汽车中,模型训练可以在电动汽车中进行,而不是在CSs中进行。这可以考虑更多用户功能,以提高EDL的准确性,例如用户消费习惯。
7 挑战与未来研究方向
- 掉队的参与方:新的FL算法需要对网络中的设备掉队具有鲁棒性,并预测只有少数参与者保持连接以参与训练回合的场景。一个可能的解决方案是,FL模型所有者提供免费的专用/特殊连接,例如蜂窝连接,以激励参与者避免掉队。
- 隐私担忧:在实现FL系统时隐私保证与系统表现之间的权衡需要被很好平衡。
- 无标签数据:现实中网络上生成的数据可能是无标签的或错误标签的。一种可能的解决方案是,通过相互学习“标记数据”,使移动设备能够构建其标记数据。新兴研究也考虑了半监督学习激励技术的使用[198]。
- 移动设备上的干扰:设备可能在地理上互相离得很近,这会在更新模型到服务器时导致一些干扰问题。因此,信道分配策略可能需要与资源分配方法相结合,以解决干扰问题。虽然[127, 129, 130]中的研究考虑了多址方案和over-the-air计算,但这些方法是否具有可扩展性,即是否能够支持多个参与者的大型联邦,还有待观察。为此,可以考虑使用基于数据驱动学习的解决方案,例如联邦DRL,对边缘网络的动态环境进行建模,并做出优化决策。
- 通信安全:第5-B节研究的隐私和安全威胁主要围绕数据相关的危害,例如数据和模型中毒。由于无线媒体的暴露性质,FL也容易受到通信安全问题的影响,如分布式拒绝服务(DoS)[199]和干扰攻击[200]。特别是,对于干扰攻击,攻击者可以发射高功率的射频干扰信号,以中断或干扰移动设备与服务器之间的通信。这种攻击可能会导致模型上传/下载错误,从而降低FL系统的性能,即准确性。可以采用抗干扰方案[201]来解决该问题,例如跳频,例如,在不同的频率上发送模型更新的多个副本。
- 异步FL:由于收敛保证,同步FL仍然是最常用的方法[77]。鉴于异步FL的许多优点,应该探索新的异步算法。特别是对于未来提出的算法,需要考虑非凸损失函数在Non-IID环境下的收敛保证。需要考虑的一种方法是,根据[108]的研究,可能包括后备工作者。
- 与其他分布式学习方法的比较:随着对数据隐私的日益严格审查,人们越来越多地致力于开发新的保护隐私的分布式学习算法。一项研究提出了分割学习[202],它还支持协作式ML,而无需与外部服务器交换原始数据。[203]对分割学习和FL的通信效率进行了实证比较。仿真结果表明,当涉及的模型规模较大时,或者当涉及的参与者较多时,分割学习表现良好,因为参与者不必将权重传输到聚合服务器。然而,FL更容易实现,因为参与者和FL服务器运行相同的全局模型,即FL服务器只负责聚合,因此FL可以与作为主节点的参与者之一一起工作。因此,可以将更多的研究工作用于指导系统管理员做出明智的决定,以确定哪种场景需要使用这两种学习方法。
- 学习收敛上的进一步研究:FL的基本考虑之一是算法的收敛性。FL找到权重以最小化全局模型聚合。这实际上是一个分布式优化问题,并且并不总是保证收敛。对凸和非凸损失函数基于梯度下降的FL算法的收敛范围进行理论分析和评价是一个重要的研究方向。虽然现有研究已经涵盖了这一主题,但许多保证仅限于限制,例如损失函数的凸性。
- 量化统计异构工具的使用:为了提高FL算法的收敛性,需要对数据的统计异构性进行量化。最近的工作,例如[204],已经开发了通过度量(如局部差异)来量化统计异构性的工具。然而,在训练开始之前,这些指标无法通过联邦网络轻松计算。这些指标的重要性推动了未来的发展方向,例如开发高效的算法,以快速确定联邦网络中的异构程度。
- 减轻通信的联合算法:目前,如第三节所述,FL中有三种常用的减少交流的技术。研究如何将这些技术相互结合以进一步提高性能是很重要的。此外,需要进一步评估组合技术的准确性和通信开销之间的权衡。
- 合作移动群ML:在现有的方法中,移动设备需要直接与服务器通信,这可能会增加能耗。事实上,附近的移动设备可以分组在一个集群中,服务器和移动设备之间的模型下载/上传可以通过充当中继节点的“集群头”来实现[205]。然后,移动设备和集群头之间的模型交换可以通过设备到设备(D2D)连接完成。这种模式可以显著提高能源效率。因此,可以为簇头设计有效的协调方案,以进一步提高FL系统的能效。
- FL应用:鉴于保障数据隐私的优势,FL在许多应用中扮演着越来越重要的角色,例如医疗、金融和交通系统。对于未来关于FL应用的研究,除了需要考虑调查中的上述问题,即通信成本、资源分配、隐私和安全,还需要考虑与FL将被采用的系统模型相关的具体问题。例如,对于延迟关键型应用,将更多地强调训练效率,而不是能源消耗。
8 总结
本文介绍了FL教程和一篇关于FL实施问题的综合调查。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号