激活函数:
激活函数(Activation functions)对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到我们的网络中。在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数。引入激活函数是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。
激活函数的作用:
如果不用激活函数(其实相当于激活函数是f(x) = x),在这种情况下你每一层节点的输入都是上层输出的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了,那么网络的逼近能力就相当有限。正因为上面的原因,我们决定引入非线性函数作为激活函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
常用的激活函数:

sigmoid激活函数:

特点:将输入压缩到[0,1]之间,类似于神经元的饱和放电率
存在的问题:
1.饱和神经元导致梯度消失
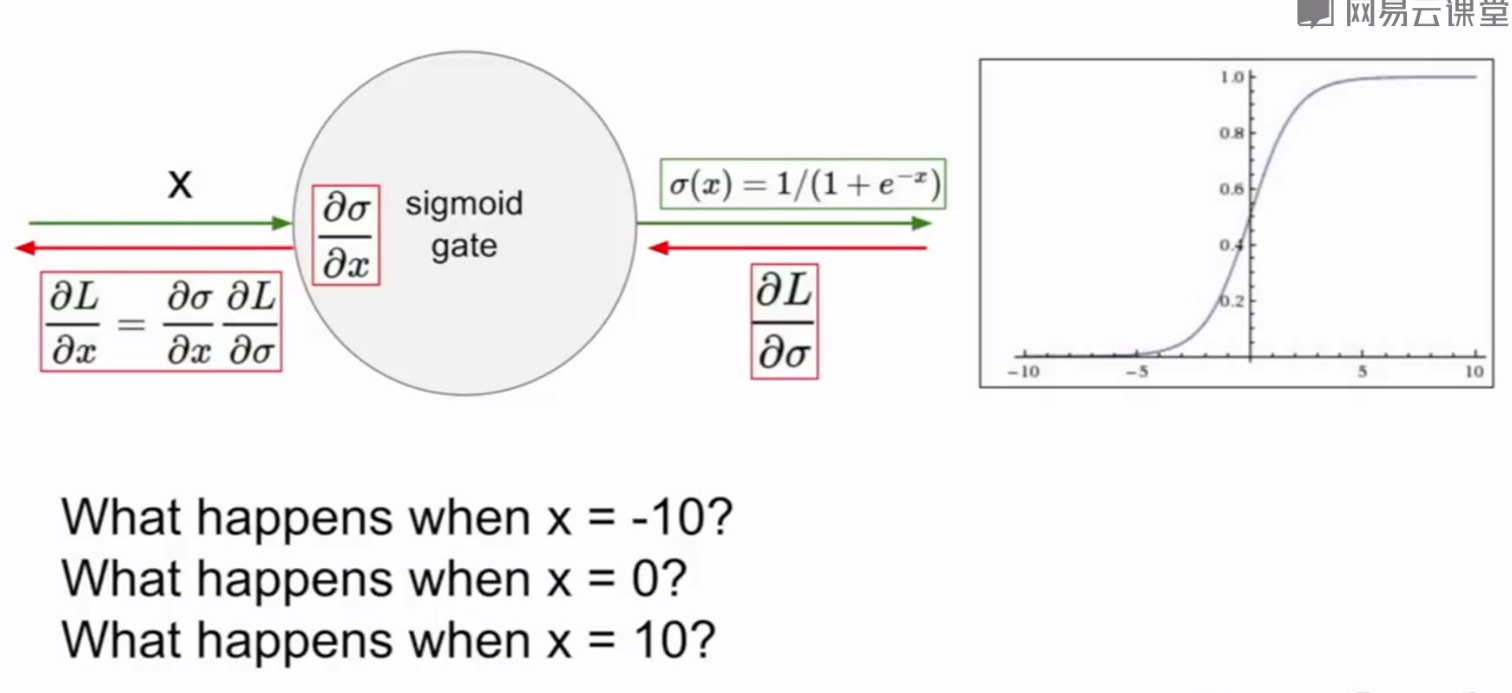
当x=-10或10时,梯度趋于0,反向传播会导致上层梯度也趋于0,从而导致梯度消失,无法得到梯度流的正确反馈
2.sigmoid的输出是一个非0为中心的函数

当神经元的输入总为正时,它会导致局部梯度(df/dw=x)也总为正,相当于把上游的梯度符号也传了回来,意味着所有关于w的梯度会总是朝着一个方向移动,对梯度更新来说非常的低效。只有在均值为0的数据,w的梯度更新会向上图中红色箭头的方向进行梯度下降,而蓝色的方向是理想的方向。
3.exp()的计算代价很高
tanh激活函数:

特点:与sigmoid激活函数类似,将输入压缩到[-1,1]之间
存在问题:与sigmoid的问题一类似,在输入非常大或者非常小时存在梯度消失的问题
ReLU激活函数:

特点:输入小于0时输出为0,输入大于0时输出等于输入
优势:
1.输入在(0,+∞)时不会饱和,不会产生梯度消失
2.计算成本低,效率高,比sigmoid和tanh速度大约快6倍
3.与生物学上更像神经元
缺点:
1.不是以0为中心,与sigmoid的问题2类似
2.输入为负时,梯度为0
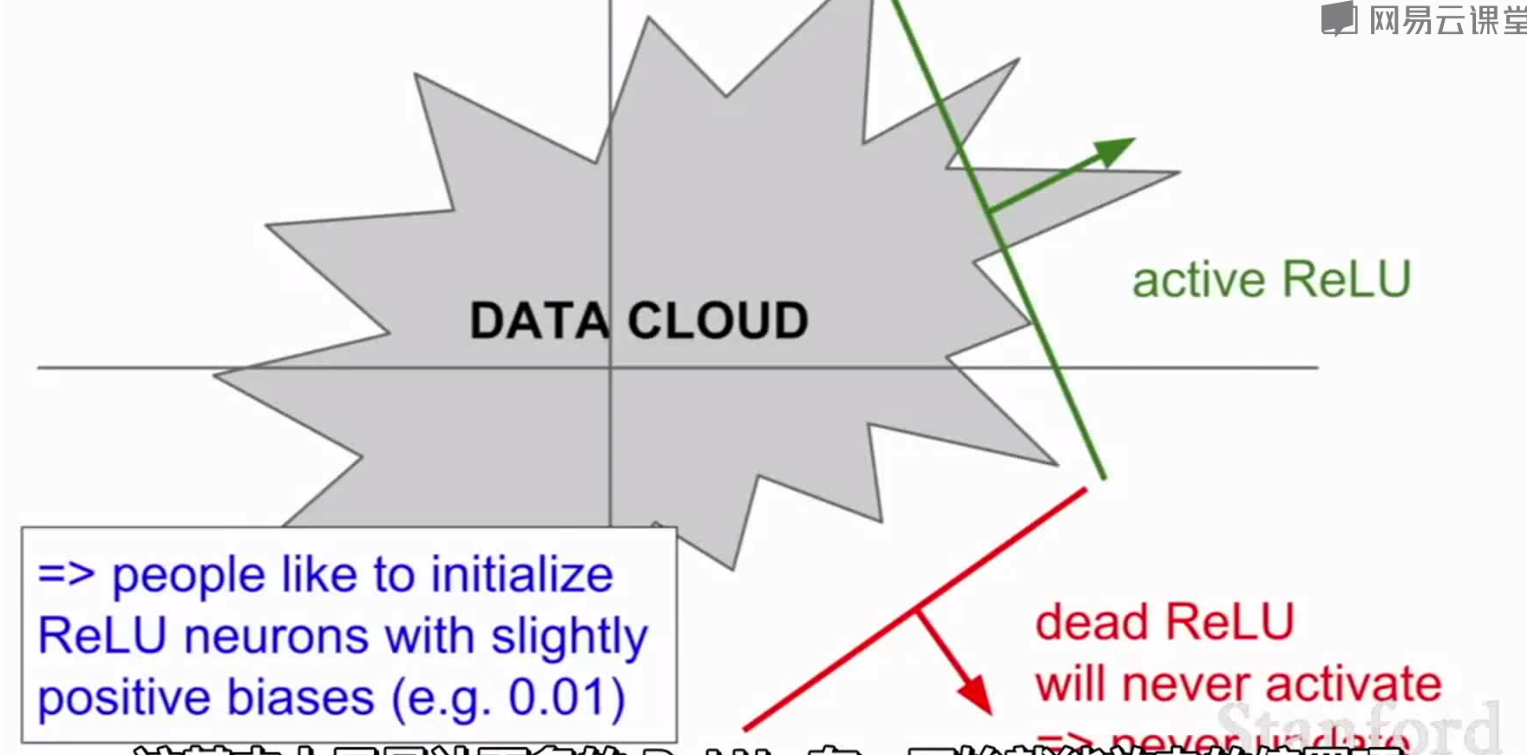
当权重初始化不好和数据波动很大时,ReLU有很大可能不被激活和更新。可以选择很小的正偏置(如0.01,一般还是0)来作为初始化值。
Leaky ReLU 和PReLU激活函数:

Leaky ReLU:与ReLU类似,在(-∞,0)为0.01x,不会像ReLU一样在(-∞,0)上不被激活和更新(dead)
PReLU(参数整流器):以参数α为负区间的斜率,不用定义或硬编码,把它当作反向传播和学习的参数
ELU激活函数(指数线性单元):

优点:
1.具有所有ReLU的优点
2.接近0的均值输出
3.在负区间没有斜率,有观点称这种负饱和机制可以让模型具有更好的抗噪音能力和鲁棒性
缺点:
1.需要exp(),计算成本
Maxout“Neuron”

特点:没有基本的点积形式,非线性
优势:
1.囊括和泛化了ReLU和LeakyReLU
2.另一种线性机制,不会饱和也不会dead
缺点:参数翻倍
总结:

1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号