广告图片分析——labelImg+Tensorflow object detection API+tensorboard可视化
背景
在外实习的时候接到了公司给的毕业设计题目,其中数据由我们组老大帮忙爬取并存入数据库中,我负责做聚类算法分析。
花了24h将所有图片下载完成后,我提取其中200份(现阶段先运行一遍后可能会增加一些)并使用labellmg为图片打上标签,作为训练集。
前置需求
1、首先安装配置好TensorFlow
2、TensorFlow模型源码
git地址: https://github.com/tensorflow/models
通过pip安装pillow,jupyter,matplotlib,lxml 如下:
pip install pillow
3、安装tensorboard:
注意 因为tensorboard所需要的pycocotools不支持Windows所以不能直接pip安装,不过git上的大牛提供了windows版本。安装命令如下:
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
这里有可能报错:
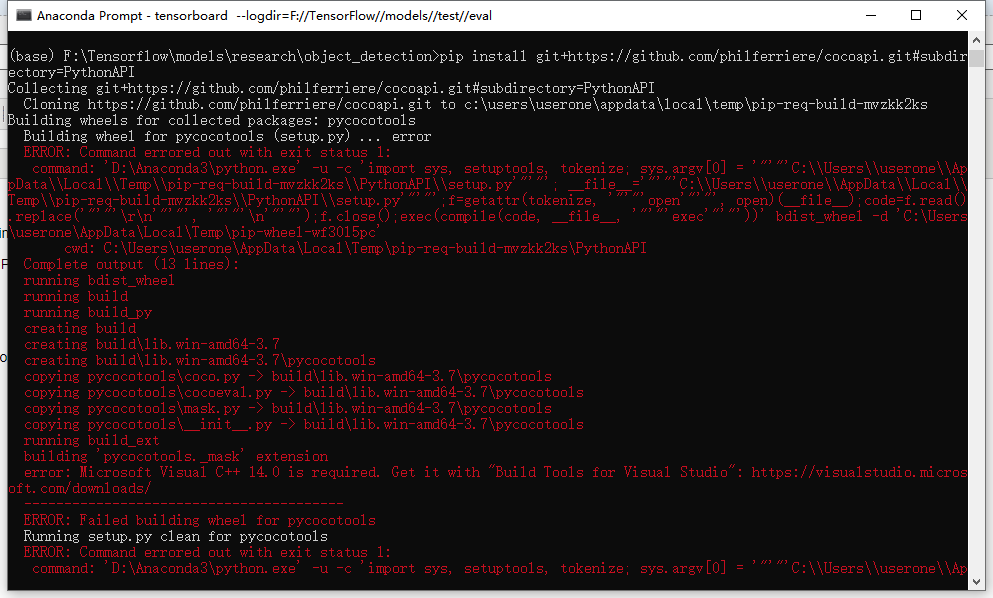
我的解决方法:
直接下载https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
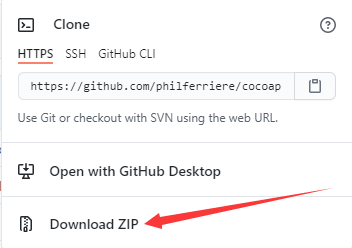
然后解压到本地F:\coco\cocoapi-master
用notebook++打开 修改F:\coco\cocoapi-master\PythonAPI\setup.py为如下
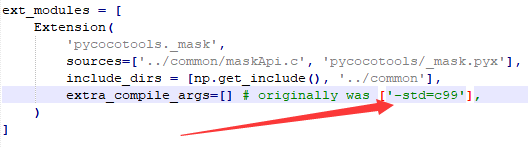
然后再anaconda Promat中 cd到这个目录,并执行
python setup.py install
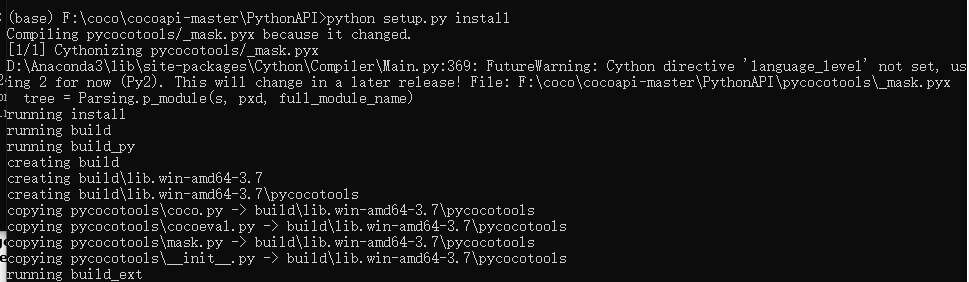
这样 pycocotools就安装完成了。
4、编译Protobuf,生产py文件
需要先安装Google的protobuf,下载protoc-3.4.0-win32.zip
打开cmd窗口,cd到models/research/目录下(老版本没有research目录),执行如下:
protoc object_detection/protos/*.proto --python_out=.
然后在F:\Tensorflow\models\research\object_detection\protos中会生成一大堆python文件 如下图所示:
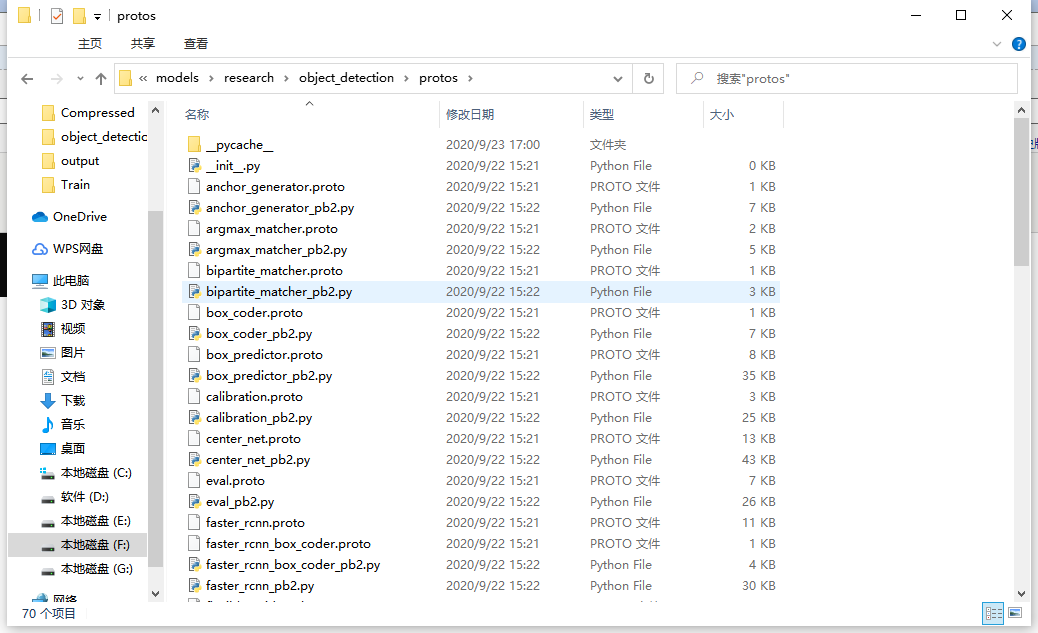
最后测试一下:
python object_detection/builders/model_builder_test.py
注意:如果出现No module named 'object_detection' 这是因为没有将工作目录添加到环境变量中
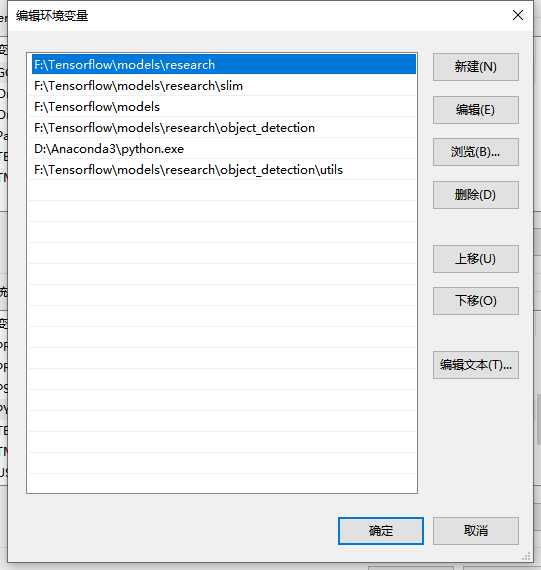
添加完成后就OK了。
开始训练自己的数据集
1.标注自己的样本图片
这里我们会使用到labelImg这个工具:
LabelImg是一个图形图像注释工具。
它用python编写的,用QT作为图形界面。
注释被按照ImageNet所使用的PASCAL VOC格式存成XML文件。
git地址:https://github.com/tzutalin/labelImg
样例:
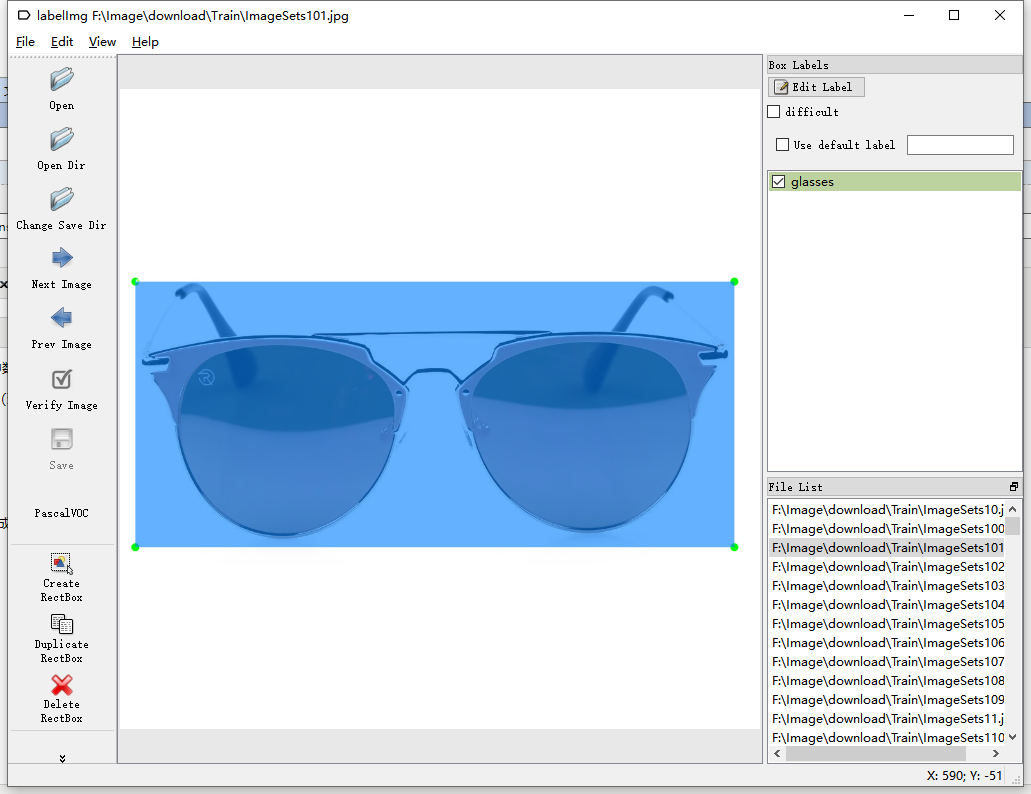
其标注后的xml文件内容
-<annotation> <folder>Train</folder> <filename>ImageSets101.jpg</filename> <path>F:\Image\download\Train\ImageSets101.jpg</path> -<source> <database>Unknown</database> </source> -<size> <width>1000</width> <height>1000</height> <depth>3</depth> </size> <segmented>0</segmented> -<object> <name>glasses</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> -<bndbox> <xmin>24</xmin> <ymin>301</ymin> <xmax>960</xmax> <ymax>716</ymax> </bndbox> </object> </annotation>
2.标注完成后,需要将xml转为csv文件,使用xml_to_csv.py,生成eval.csv验证集和train.csv训练集
代码如下:
import os import glob import pandas as pd import xml.etree.ElementTree as ET def xml_to_csv(path): xml_list = [] # 读取注释文件 for xml_file in glob.glob(path + '/*.xml'): tree = ET.parse(xml_file) root = tree.getroot() for member in root.findall('object'): value = (root.find('filename').text, int(root.find('size')[0].text), int(root.find('size')[1].text), member[0].text, int(member[4][0].text), int(member[4][1].text), int(member[4][2].text), int(member[4][3].text) ) xml_list.append(value) column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax'] # 将所有数据分为样本集和验证集,一般按照3:1的比例 train_list = xml_list[0: int(len(xml_list) * 0.67)] eval_list = xml_list[int(len(xml_list) * 0.67) + 1: ] # 保存为CSV格式 train_df = pd.DataFrame(train_list, columns=column_name) eval_df = pd.DataFrame(eval_list, columns=column_name) train_df.to_csv('F:/Image/download/Train/train.csv', index=None) eval_df.to_csv('F:/Image/download/Train/eval.csv', index=None) def main(): path = 'F:/Image/download/Train' xml_to_csv(path) print('Successfully converted xml to csv.') main()
3.生成TFrecord文件
Created on Tue Jan 16 01:04:55 2018 @author: Xiang Guo 由CSV文件生成TFRecord文件 """ """ Usage: # From tensorflow/models/ # Create train data: python generate_tfrecord.py --csv_input=data/tv_vehicle_labels.csv --output_path=train.record # Create test data: python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record """ import os import io import pandas as pd import tensorflow.compat.v1 as tf from PIL import Image from object_detection.utils import dataset_util from collections import namedtuple, OrderedDict import sys sys.path.append("F:/models/research") sys.path.append("F:/models/research/object_detection/utils") os.environ['PYTHONPATH'] += 'F:/Tensorflow/models/research/:F:/Tensorflow/models/research/slim/' os.chdir('F:/Tensorflow/models/research/object_detection') flags = tf.app.flags flags.DEFINE_string('csv_input', '', 'Path to the CSV input') flags.DEFINE_string('output_path', '', 'Path to output TFRecord') FLAGS = flags.FLAGS # TO-DO replace this with label map #注意将对应的label改成自己的类别!!!!!!!!!!
#需要打开F:\Image\Labellmg\data\predefined_classes.txt文件,将打上的标签一一对应
def class_text_to_int(row_label): if row_label == 'clothes': return 1 elif row_label == 'pants': return 2 elif row_label == 'roads': return 3 elif row_label == 'sports': return 4 elif row_label == 'accessories': return 5 elif row_label == 'man': return 6 elif row_label == 'shoes': return 7 elif row_label == 'drink': return 8 elif row_label == 'poster': return 9 elif row_label == 'baby': return 10 elif row_label == 'bag': return 11 elif row_label == 'text': return 12 elif row_label == 'cosmetic': return 13 elif row_label == 'furniture': return 14 elif row_label == 'light': return 15 elif row_label == 'plants': return 16 elif row_label == 'book': return 17 elif row_label == 'hat': return 18 elif row_label == 'glasses': return 19 elif row_label == 'food': return 20 elif row_label == 'tools': return 21 elif row_label == 'hands and feet': return 22 elif row_label == 'toy': return 23 elif row_label == 'sock': return 24 elif row_label == 'house': return 25 elif row_label == 'door': return 26 elif row_label == 'dog': return 27 elif row_label == 'painting': return 28 elif row_label == 'woman': return 29 elif row_label == 'health': return 30 elif row_label == 'computer': return 31 elif row_label == 'phone': return 32 elif row_label == 'watch': return 33 elif row_label == 'car': return 34 else: None def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): #with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: print(os.path.join(path, '{}'.format(group.filename))) with open(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() print(encoded_jpg) encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf-8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), #'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def main(csv_input, output_path, imgPath): #print(output_path) writer = tf.python_io.TFRecordWriter(output_path) #print(writer) path = imgPath #print(path) examples = pd.read_csv(csv_input) # print(examples) grouped = split(examples, 'filename') # print(grouped) for group in grouped: tf_example = create_tf_example(group, path) writer.write(tf_example.SerializeToString()) writer.close() print('Successfully created the TFRecords: {}'.format(output_path)) if __name__ == '__main__': imgPath = 'F:/Image/download/Train' # 生成train.record文件 output_path = 'F:/Image/output/record/train.record' csv_input = 'F:/Image/download/Train/train.csv' main(csv_input, output_path, imgPath) # 生成验证文件 eval.record output_path = 'F:/Image/output/record/eval.record' csv_input = 'F:/Image/download/Train/eval.csv' main(csv_input, output_path, imgPath)
在这一步中,我遇到了很多问题,比如csv文件对应的路径错误,以及csv文件中后缀名重复导致的编码错误。总的来说就是要细心细心再细心!
开始训练
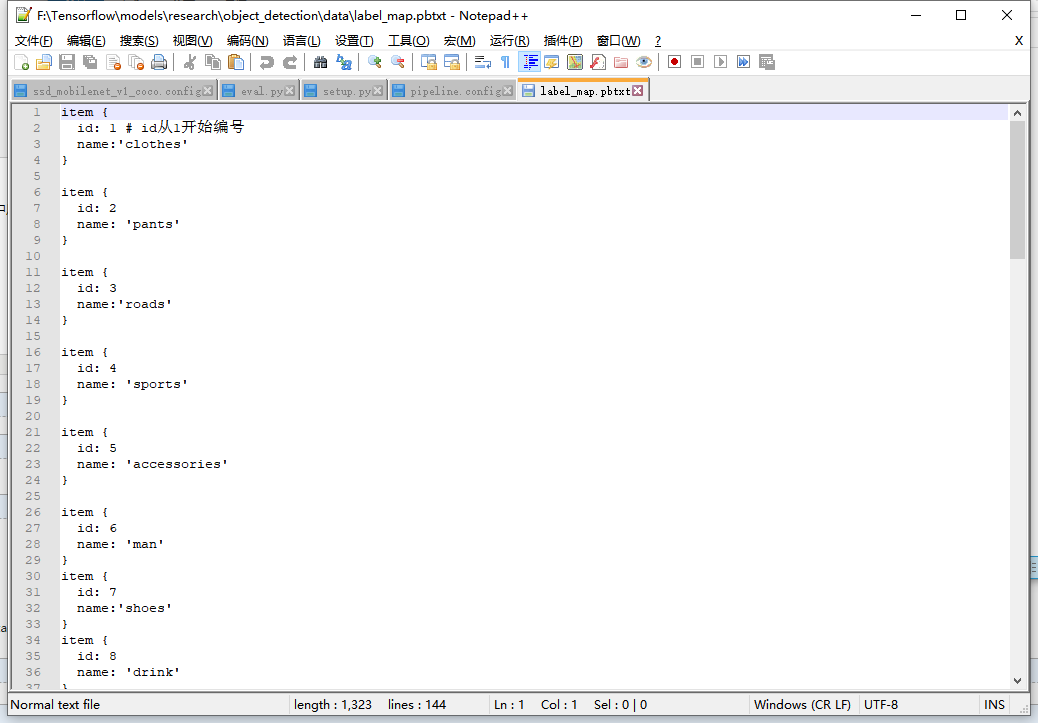
1.编写label_map.pbtxt文件
2.配置需要模型的conifg文件。
这里我使用了ssd_mobilenet_v1_coco,所以修改其config
注意 接下来的操作很关键:
#====================================== model { ssd { #首先修改num_classes,将数量改为你需要判断的类型 num_classes: 34 box_coder { faster_rcnn_box_coder { y_scale: 10.0 x_scale: 10.0 height_scale: 5.0 width_scale: 5.0 } } #====================================== #其次,因为我们是重新训练模型,所以这里注释掉模型检测点,并将from_detection_checkpoint该为false #fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/model.ckpt" from_detection_checkpoint: false num_steps: 200000 # 训练次数可以改小,因为我就是在跑的时候写下的这篇博客:)。 #====================================== #最后修改train和eval的路径,以及eval_config中的num_examples个数。 train_input_reader: { tf_record_input_reader { #第一处修改 input_path: "F:/Image/output/record/train.record" } label_map_path: #第二处修改 "F:/Tensorflow/models/research/object_detection/data/label_map.pbtxt" } eval_config: { #第三处修改 num_examples: 47 # Note: The below line limits the evaluation process to 10 evaluations. # Remove the below line to evaluate indefinitely. max_evals: 10 } eval_input_reader: { tf_record_input_reader { #第四处修改 input_path: "F:/Image/output/record/eval.record" } label_map_path: #第五处修改 "F:/Tensorflow/models/research/object_detection/data/label_map.pbtxt" shuffle: false num_readers: 1 }
3.开始训练
使用代码如下,根据工作目录修改train.py文件的定位
python legacy/train.py --logtostderr --train_dir=F:/TensorFlow/models/test/training/ --pipeline_config_path=F:/Tensorflow/models/research/models/ssd_mobilenet_v1_coco.config
接下来就是等啊等……我在写这篇博客时,才刚跑完五分之一。
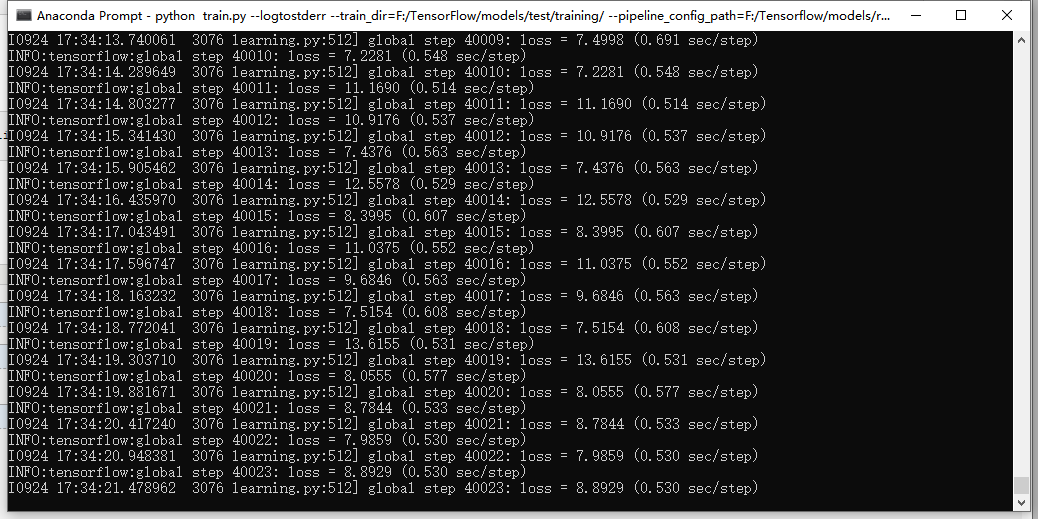
可选:Tensorboard的使用
之前我们已经安装好了pycocotools以及tensorboard,但是tensorboard不能独立使用,这时候我们就要从F:\Tensorflow\models\research\object_detection\legacy中找到eval.py文件。
使用方法与train.py类似。
python F:\Tensorflow\models\research\object_detection\eval.py --logtostderr --eval_dir=F:/TensorFlow/models/test/eval/ --pipeline_config_path=F:/Tensorflow/models/research/models/ssd_mobilenet_v1_coco.config --checkpoint_dir=F:/TensorFlow/models/test/training/
这里如果出现错误,比如在image文件读到10时出现错误:
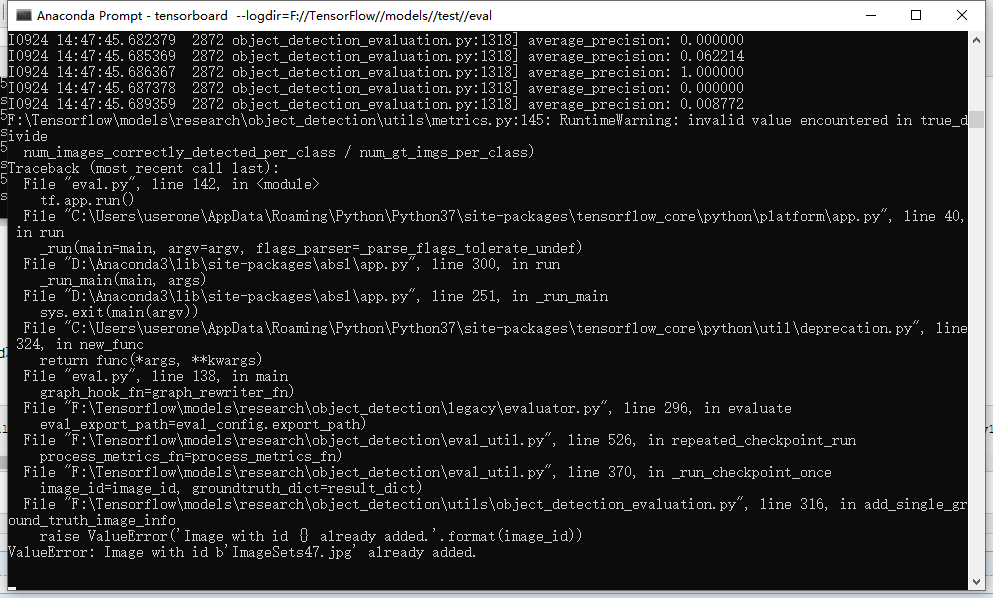
如果有这样的报错,需要再修改config文件中eval_config下的num_examples,修改到可以运行为止。
eval.py的原理说不太清,但是可以看成是train的一种验证方法。
先运行train.py,再运行eval.py,然后运行
tensorboard --logdir=F://TensorFlow//models//test//eval
在浏览器中打开http://localhost:6006/即可。
要注意的是,在tensorboard中不是立马就会有结果,而是训练保存一个checkpoint,tensorboard读取一个模型,更新一次参数,所以相当于有几个checkpoint,在曲线中就会有几个点,需要耐心等待,不要着急。
运行tensorboard成功后可以见到下图:
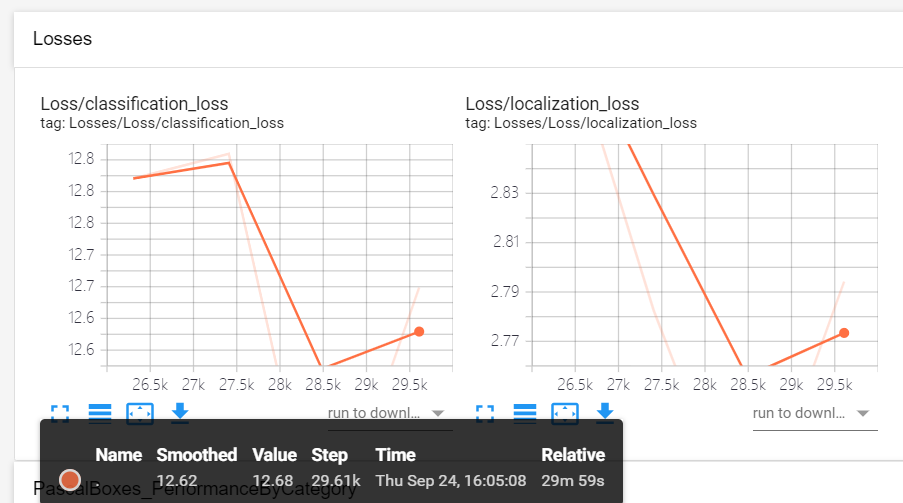
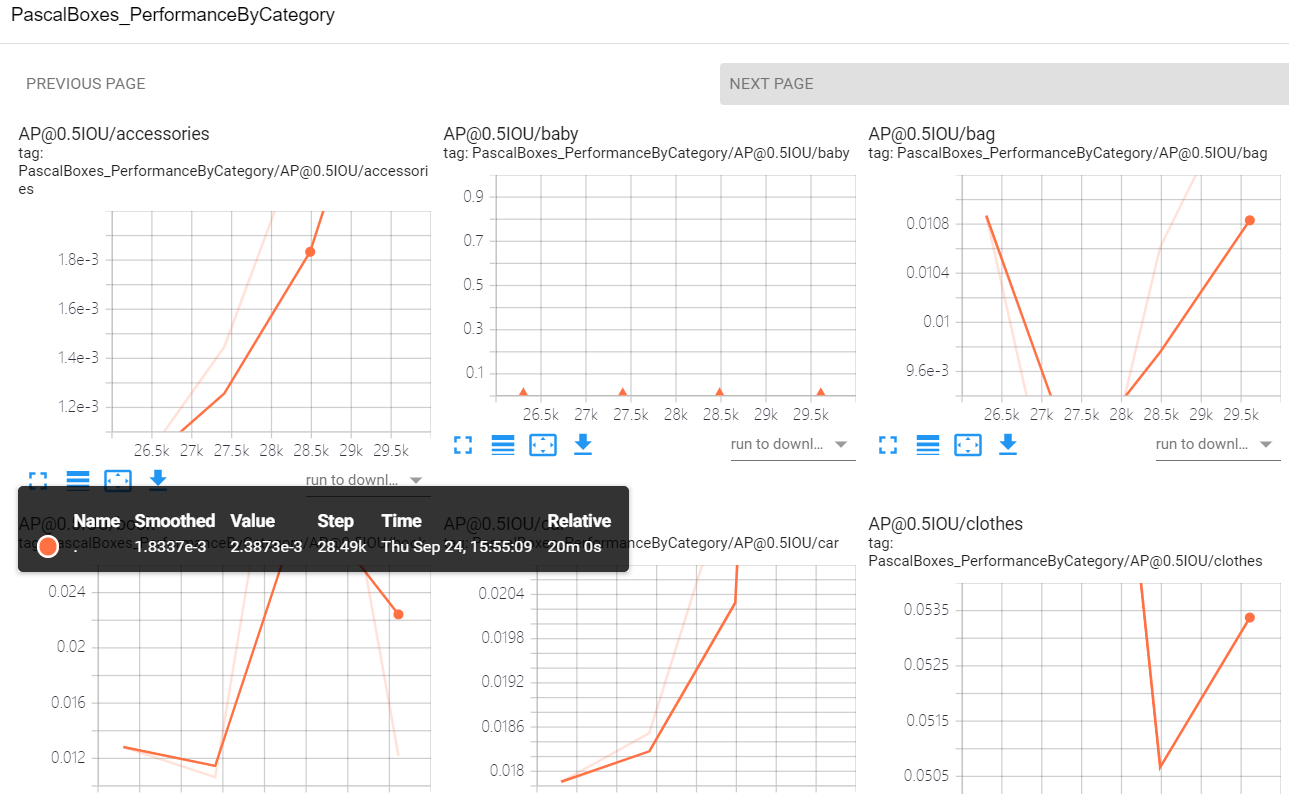
Loss/RPNLoss/localization_loss/mul_1: Localization Loss or the Loss of the Bounding Box regressor for the RPN
Loss/RPNLoss/objectness_loss/mul_1: Loss of the Classifier that classifies if a bounding box is an object of interest or background
The losses for the Final Classifier:
Loss/BoxClassifierLoss/classification_loss/mul_1: Loss for the classification of detected objects into various classes: Cat, Dog, Airplane etc
Loss/BoxClassifierLoss/localization_loss/mul_1: Localization Loss or the Loss of the Bounding Box regressor
感慨一下,做了这么多东西花费了我将近一星期的时间,很多问题的解决方法其实很简单,但是因为经验和细心都有欠缺 所以多花了一些时间。不过大多数的坑跨过就真的跨过了,希望等跑完这20w后能更顺利点的把剩下的图片分析完毕吧。
感谢github和csdn上的各位前辈。其中大部分文献和代码来自:https://blog.csdn.net/RobinTomps/article/details/78115628。谢谢各位花费时间看我完成的一个小玩意,希望大家能一起进步嗷。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号