《机器学习》第二次作业——第四章学习记录和心得
《机器学习》第四章学习记录和心得
Bienvenu à nouveau !
思维导图
Chapter 4
4.1、 线性判据基本概念
- 生成模型:给定训练样本 {𝒙𝑛},直接在输入空间内学习其概率密度函数𝑝(𝒙)。
- 在贝叶斯决策分类中,生成模型通常用于估计每个类别的观测似然概率𝑝(𝒙|𝐶𝑖),再结合先验概率得到联合概率𝑝(𝒙,𝐶𝑖)=𝑝(𝒙|𝐶𝑖)𝑝(𝐶𝑖)。然后,对所有类别进行积分,得到边缘概率密度函数𝑝 (𝒙) = Σ𝑖 𝑝(𝒙,𝐶𝑖)。最后,得到后验概率𝑝(𝐶𝑖|𝒙)。
- 优势:可以根据𝑝(𝒙)采样新的样本数据,可以检测出较低概率的数据,实现离群点检测;劣势:如果是高维的𝒙,需要大量训练样本才能准确的估计𝑝(𝒙);否则,会出现维度灾难问题。
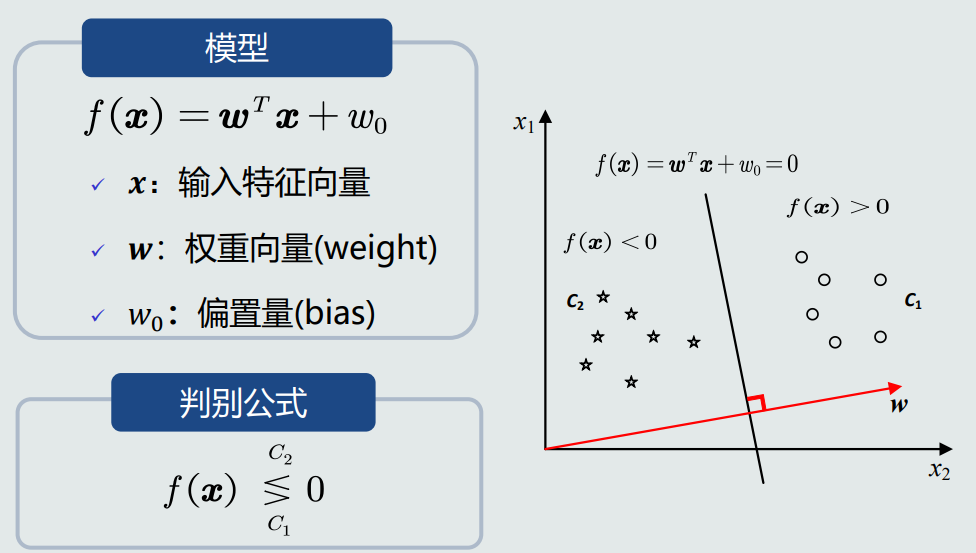
- 线性判据定义:判别模型𝑓(𝒙)是线性函数,则𝑓(𝒙)为线性判据。优势在于计算量少,在学习和分类过程中,线性判据方法都比基于学习概率分布的方法计算量少,适用于训练样本较少的情况。
- 线性判据数学表达:
![]()
4.2、 线性判据学习概述
- 监督式学习(训练)过程:基于训练样本{𝒙1, 𝒙2, … , 𝒙𝑁}及其标签{𝑡1, 𝑡2, … , 𝑡𝑁} ,设计目标函数,学习𝐰和𝑤0。
- 识别过程:将待识别样本𝒙带入训练好的判据方程。
- 常见目标函数:
![]()

4.3、 并行感知机算法
- 预处理过程:
![]()
- 梯度下降法:
![]()
- 算法流程:
![]()



4.4、 串行感知机算法
- 串行感知机:训练样本是一个一个串行给出的。
- 目标函数:
![]()
- 算法流程:
![]()
- 收敛性:如果训练样本是线性可分的,感知机(并行和串行)算法理论上收敛于一个解。
- 步长决定收敛的速度、以及是否收敛到局部或者全局最优点。
- 如果目标函数J(a)满足L-Lipschitz条件(对于任意a,存在一个常数L,使得|J(a)|<L成立),则步长𝜂 = 1/ 2𝐿 可确保收敛到局部最优点。
- 如果目标函数J(a)是凸函数,局部最优点就是全局最优点。
- 加入约束:
![]()



4.5、 Fisher线性判据
![]()
- Fisher判据基本原理:
- 找到一个最合适的投影轴,使两类样本在该轴上投影的重叠部分最少,从而使分类效果达到最佳。
- 最佳标准之一:投影后,使得不同类别样本分布的类间差异尽可能大,同时使得各自类内样本分布的离散程度尽可能小。
- 决策边界:
![]()
- 算法流程:
![]()



4.6、 支持向量机基本概念
- 支持向量机设计思想:给定一组训练样本,使得两个类中与决策边界最近的训练样本到决策边界之间的间隔最大。
- 间隔的定义:在两个类的训练样本中,分别找到与决策边界最近的两个训练样本,记作𝒙+和𝒙− 。𝒙+和𝒙−到决策边界的垂直距离叫作间隔,记作𝑑+和𝑑− 。
- 支持向量的概念:
![]()
- 目标函数:
![]()


4.7、 拉格朗日乘数法
- KKT条件:
![]()

4.8、 拉格朗日对偶问题
- 主问题:
![]()
- 主问题难以求解或者是NP难问题。
- 主问题最优值的下界
![]()
- 对偶问题:
![]()
- 由于目标函数𝐿𝐷是凹函数,约束条件是凸函数,所以对偶问题是凸优化问题。
- 对偶法的优势:
- 无论主问题的凸性如何,对偶问题始终是一个凸优化问题。
- 凸优化的性质:局部极值点就是全局极值点。
- 所以,对偶问题的极值是唯一的全局极值点。
- 因此,对于难以求解的主问题(例如,非凸问题或者NP难问题),可以通过求解其对偶问题,得到原问题的一个下界估计。



4.9、 支持向量机学习算法
-
参数最优解:
![]()
-
决策过程:
![]()


4.10、 软间隔支持向量机
- 软间隔概述:
![]()
- 设计思想:引入松弛变量
- 参数最优解:
![]()
- 决策过程:
![]()



4.11、 线性判据多类分类
- 实现非线性分类的途径
- 一个模型:能刻画非线性的决策边界。
- 多个模型:多个模型(线性/非线性)组合成非线性决策边界。组合方式:并行组合、串行组合。
- 对于线性判据:通过多个线性模型组合的途径实现多类分类。
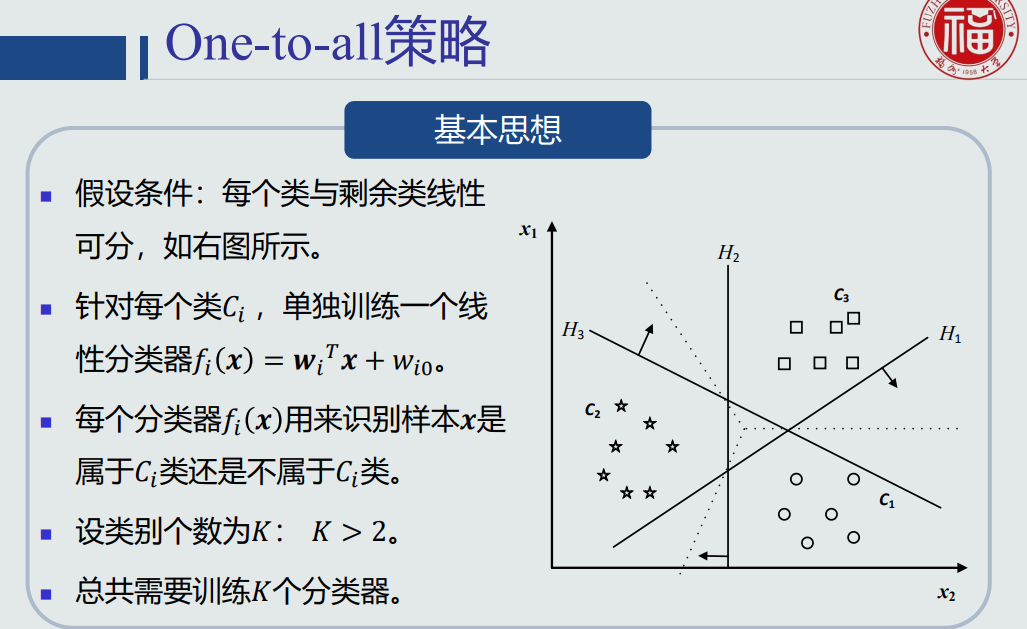
- one-to-all策略:
![]()
- one-to-all问题:每个分类器正负类样本个数不均衡。
- 线性机:
![]()
- 线性机问题:
- 可能出现最大的𝑓𝑖(𝒙) ≤ 0,即测试样本𝒙出现在拒绝区域。
- 如果严格按照线性判据的定义,拒绝区域其实是线性机(基于one-to-all策略)无法正确判断的区域。
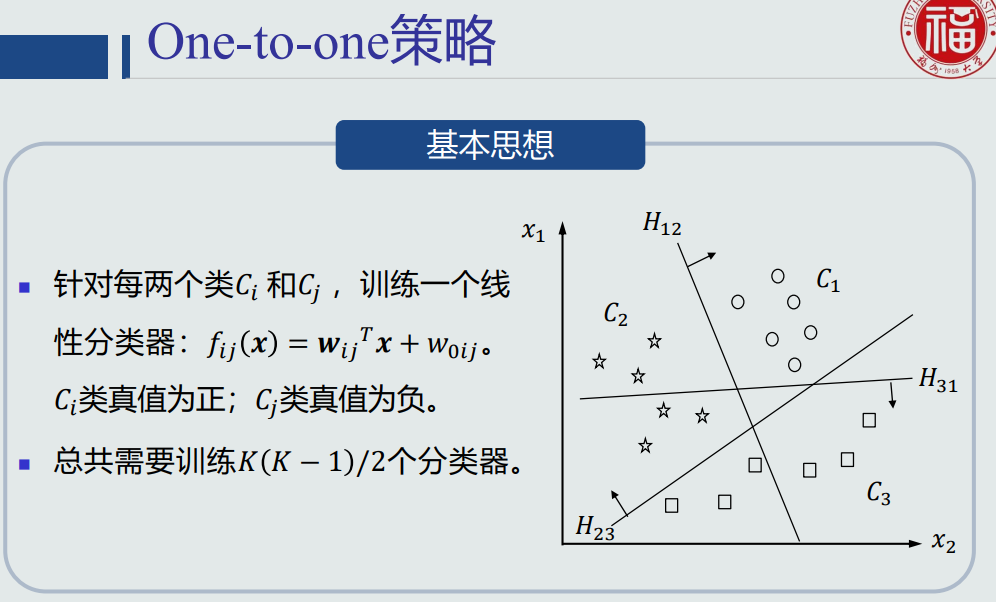
- one-to-one策略:
![]()
- one-to-one问题:会出现拒绝选项( reject case ),即样本不属于任何类的情况。
- 使用线性判据进行多类分类,本质上是利用多个线性模型组合而成一个非线性分类器。因此,决策边界不再是由单个超平面决定,而是由多个超平面组合共同切割特征空间。

4.12、 线性回归
- 线性回归模型表达:
![]()
![]()
- 最小二乘法:
![]()
- 最小二乘法适用于Tall数据。



4.13、 逻辑回归的概念
- 后验概率对数比率 = 线性判据输出。
- Logit变换:
![]()
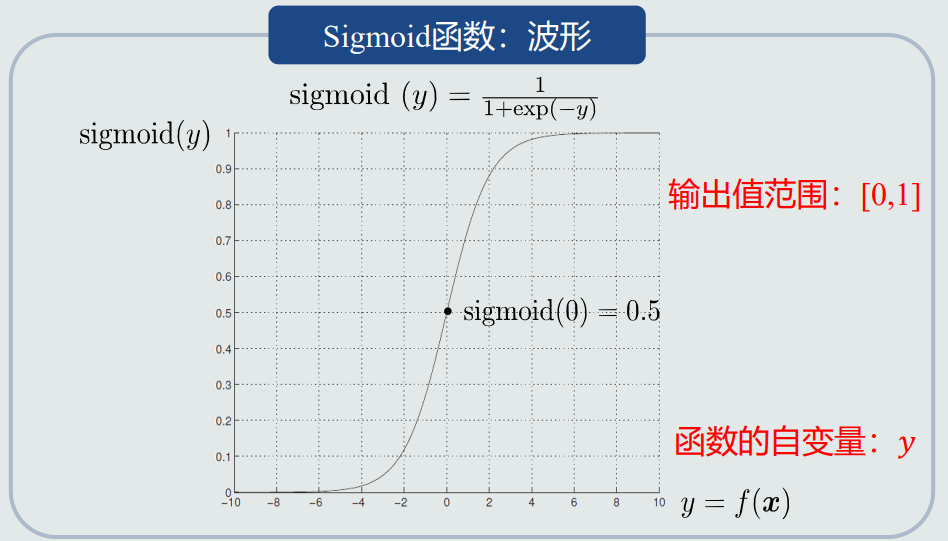
- Sigmoid函数:
![]()
![]()
- Sigmoid函数:连接线性模型和后验概率的桥梁;线性模型𝑓(𝒙) + Sigmoid函数 = 后验概率
- 逻辑回归:
![]()
- 逻辑回归与神经元:
![]()
- 逻辑回归本身是一个非线性模型。
- 逻辑回归用于分类:仍然只能处理两个类别线性可分的情况。但是,sigmoid函数输出了后验概率,使得逻辑回归成为一个非线性模型。因此,逻辑回归比线性模型向前迈进了一步。
- 逻辑回归可以拟合有限的非线性曲线。




4.14、 逻辑回归的学习
- 目标函数:
![]()
- 交叉熵可以用来度量两种分布的差异程度。
- 目标函数优化仍可采用梯度下降法。
- 优化时需要注意梯度消失问题:
![]()
- 如果迭代停止条件设为训练误差为0,或者所有训练样本都正确分类的时候才停止,则会出现过拟合问题。所以,在达到一定训练精度后,提前停止迭代,可以避免过拟合。


4.15、 Softmax判据的概念
- Softmax函数:
![]()
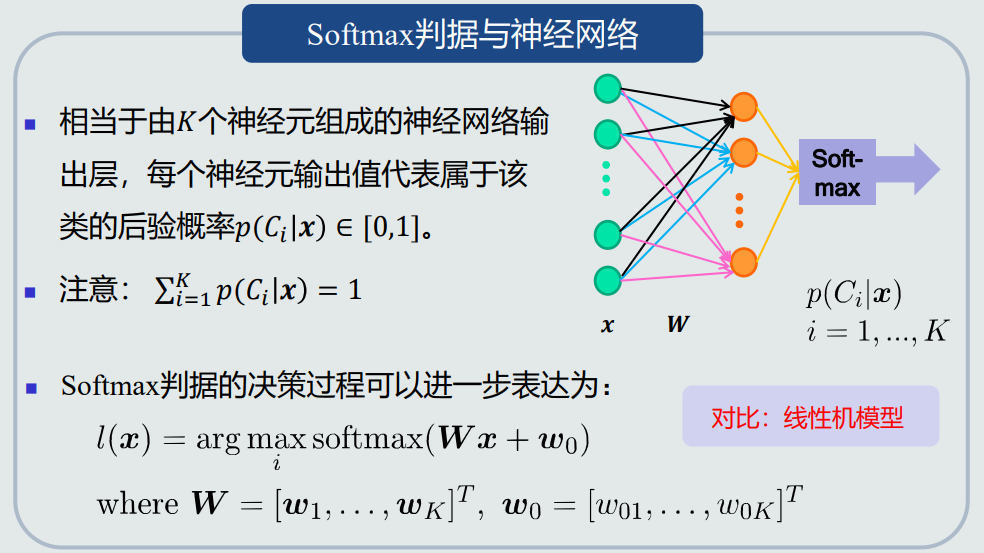
- Softmax判据:
![]()
- 与神经网络的联系:
![]()
- 适用范围:
![]()
- Softmax判据本身是一个非线性模型。
- Softmax判据用于分类:只能处理多个类别、每个类别与剩余类线性可分的情况。但是, Softmax判据可以输出后验概率。因此,Softmax判据比基于one-to-all策略的线性机向前迈进了一步。
- Softmax判据用于拟合:可以输出有限的非线性曲线。



4.16、 Softmax判据的学习
- 待学习的参数:
![]()
- 目标函数使用最大似然估计。
- 概率分布:
![]()
- 梯度分析:
![]()



4.17、 核支持向量机(Kernel SVM)
- Kernel方法的基本思想
![]()
- 高维空间表达:
![]()
- Φ空间的点积其实可以由𝑋空间的点积的非线性组合来计算
- 核函数:在低维𝑋空间的一个非线性函数,包含向量映射和点积功能,即作为𝑋空间两个向量的度量,来表达映射到高维空间的向量之间的点积。
- 决策边界方程也由𝑁𝑠个非线性函数的线性组合来决定。因此,在𝑋空间是一条非线性边界。
- 核函数的条件:
![]()
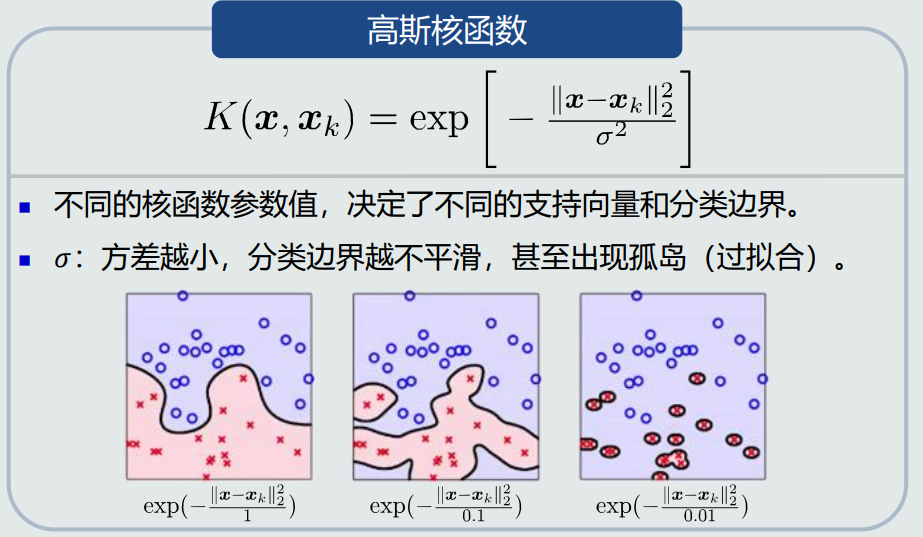
- 常见的核函数:
![]()
![]()
![]()
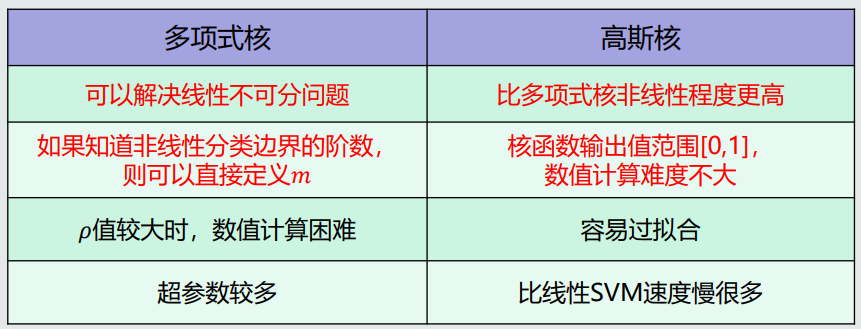
- 核函数优缺点:
![]()






 浙公网安备 33010602011771号
浙公网安备 33010602011771号