
第一次个人编程作业
Github链接
https://github.com/Malancholy/031802136
一、计算模块接口的设计与实现过程。
-
主要还是利用了前人的工具方法并加以整合。
-
主要用到了jieba分词以及向量余弦的方法,故认为代码不是很复杂,没有使用类来实现
-
总体上使用了四个函数:
- Read_Original()用来读入原本文件
- Read_Copy()用来读入抄袭文件
- Caculator_Cos(original_list,copy_list)用来计算向量余弦并返回答案
- Print_Answer(ans)将答案输出
-
原本想用暴力实现,但感觉向量余弦的方式更合理些
-
主要还是利用分词进行判断,但不足之处也明显,如无法明显地区分语义等
-
一个句子中如果加入了否定词,是有理由认为其重复度为0的(毕竟论文可以表述与先前论文相反的陈述并进行论述),但是这并不能检测出来,相反重复率还会很高
-
具体算法流程:
(1)读入原文本与抄袭文本
(2)对原文本与抄袭文本利用jieba进行分词得到两个列表
(3)去除标点符号以及空格空行等字符
(4)求出两个列表的并集并且去重
(5)分别计算原文本列表与抄袭文本在其并集中的重复数,进而构造出两个向量
(6)求出两个向量的夹角余弦值
(7)输出至指定文件
二、计算模块接口部分的性能改进。
-
代码是改进之后的,先前没有使用函数以及各种命名较为随意,再者之前是使用暴力的方式
-
毕竟总体上来看还是向量余弦的方式较好咯
-
性能分析如下(使用自带的profile进行):
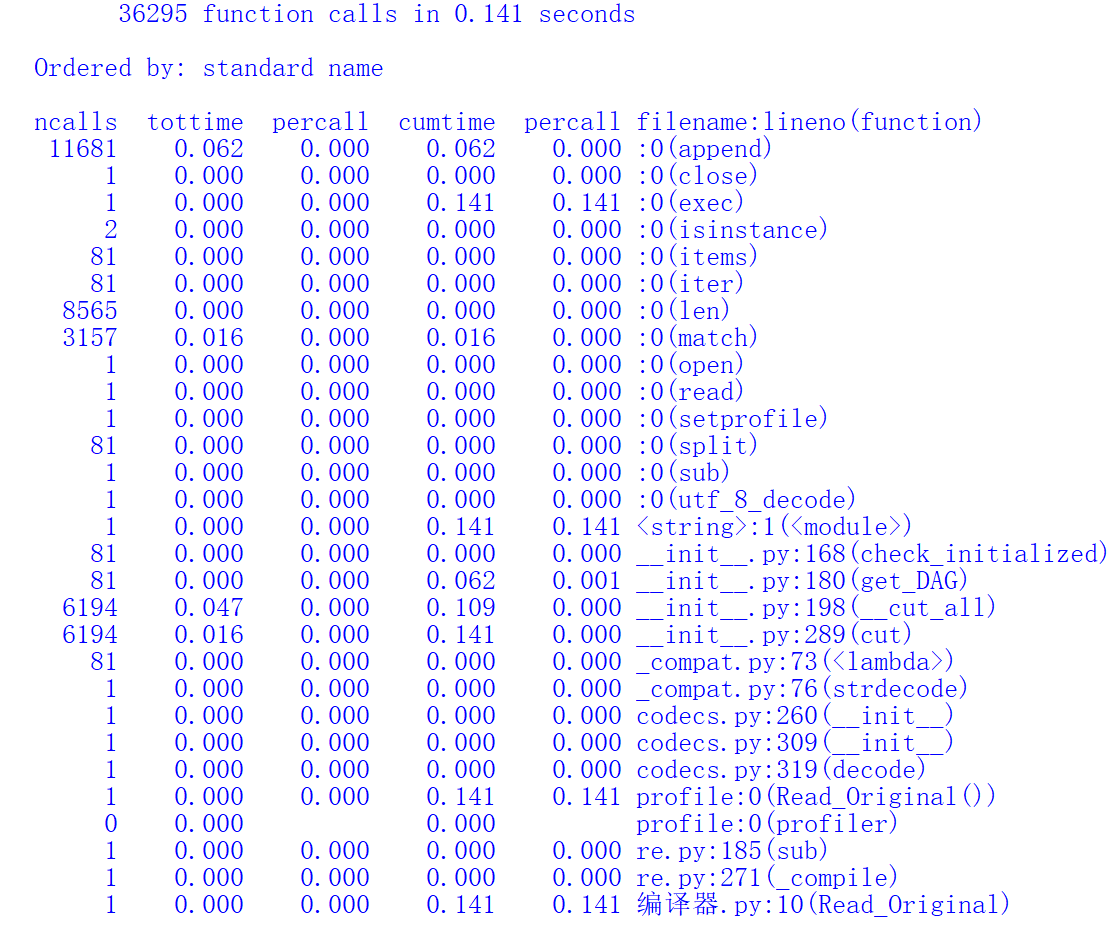
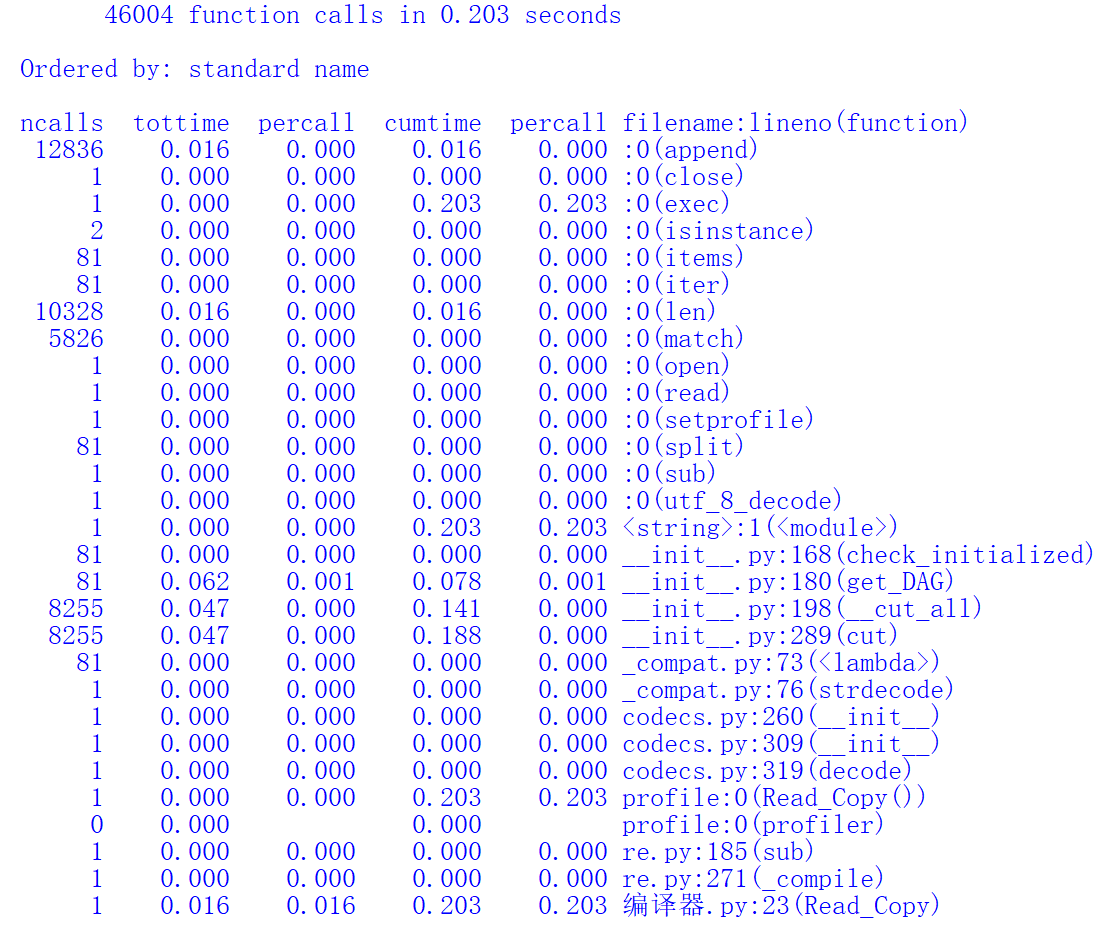
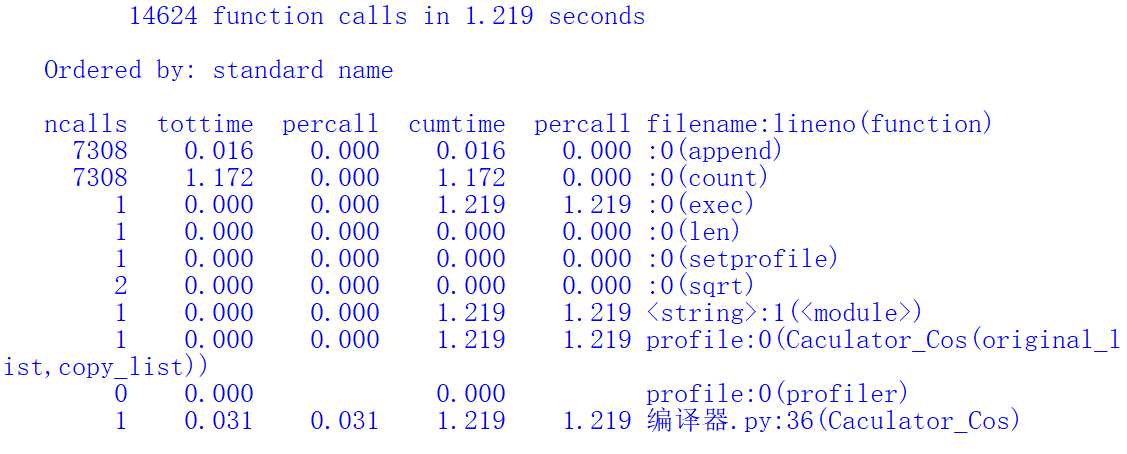

- 消耗最大的还是在向量余弦的计算上,进行了多次的对向量的循环遍历
三、计算模块部分单元测试展示。
- 测试的代码:
import jieba
import re
import math
import profile # 模块定义
vector_a=[]
vector_b=[] # 向量定义
def Read_Original(): # 读入原本文件
try:
original_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/orig.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
original_list=original_txt.read() # 文件读取
original_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",original_list) # 文本处理
original_list=jieba.cut(original_list,cut_all=True) # 文本分词
original_list=list(original_list) # 分词后的结果转换成列表
original_txt.close() # 文件关闭
return original_list # 返回分词后的列表
def Read_Copy1():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/blank.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Read_Copy2():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/orig_0.8_add.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Read_Copy3():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/orig_0.8_del.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Read_Copy4():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/orig_0.8_dis_1.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Read_Copy5():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/orig_0.8_dis_3.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Read_Copy6():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/orig_0.8_dis_7.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Read_Copy7():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/orig_0.8_dis_10.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Read_Copy8():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/orig_0.8_dis_15.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Read_Copy9():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/orig_0.8_mix.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Read_Copy10():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/orig_0.8_rep.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Read_Copy11():# 读入抄袭文件
try:
copy_txt=open("C:/Users/叶昊明/Desktop/个人编程作业样例数据/sim_0.8/000.txt",encoding="utf-8") # 打开文件
except OSError:
print('指定文件不存在!') # 文件不存在则抛出异常处理
copy_list=copy_txt.read() # 文件读取
copy_list=re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",copy_list) # 文本处理
copy_list=jieba.cut(copy_list,cut_all=True) # 文本分词
copy_list=list(copy_list) # 分词后的结果转换成列表
copy_txt.close() # 文件关闭
return copy_list # 返回分词后的列表
def Caculator_Cos(original_list,copy_list): # 计算向量余弦
Together=copy_list+original_list # 合并两个文本列表
Together=list(set(Together)) # 利用集合进行去重
for i in Together:
vector_a.append(original_list.count(i))
vector_b.append(copy_list.count(i)) # 计算两个文本向量
Sum_vector_a=0
Sum_vector_b=0 # 计算向量的内积定义
Sum=0
for i in range(0,len(vector_a)): # 计算夹角余弦值的循环
Sum_vector_a+=vector_a[i]*vector_a[i]
Sum_vector_b+=vector_b[i]*vector_b[i]
Sum+=vector_a[i]*vector_b[i]
try:
ans=Sum/math.sqrt(Sum_vector_b)/math.sqrt(Sum_vector_a)
except ZeroDivisionError:
print('文本经过处理后为空!') # 文件处理后为空则抛出异常,利用计算时分母为0的转义
return ans # 返回答案值
def Print_Answer(ans): # 将答案输出到指定文件
print(ans)
original_list=Read_Original()
copy_list=Read_Copy2()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
copy_list=Read_Copy3()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
copy_list=Read_Copy4()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
copy_list=Read_Copy5()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
copy_list=Read_Copy6()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
copy_list=Read_Copy7()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
copy_list=Read_Copy8()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
copy_list=Read_Copy9()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
copy_list=Read_Copy10()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
copy_list=Read_Copy11()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
copy_list=Read_Copy1()
ans=Caculator_Cos(original_list,copy_list)
Print_Answer(ans)
-
测试的结果:
![]()
-
主要测试了所给的样例,以及自己设计的部分内容;主要围绕异常处理的问题所展开,设计了一个空文本的情况以及一个路径不存在的情况。
-
可以看出结果并不是很理想,可能具体实现的时候出了点问题。
-
尽管知道有许多其他的方法,碍于种种原因并没有去尝试以及对现行方法的更正。
-
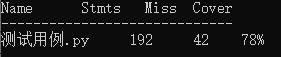
测试覆盖率(使用coverage工具进行):
![]()

四、计算模块部分异常处理说明。
本次设置了两个异常处理机制
-
一个是用来判断文件读入错误的,如输入的文件路径不存在时则会抛出异常
![]()
-
一个是用来判断文本经处理后为空的情况的,如将文本置空会出现以下情况
![]()

五、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| Estimate | 估计这个任务需要多少时间 | 650 | 1070 |
| Development | 开发 | 120 | 60 |
| Analysis | 需求分析 (包括学习新技术) | 200 | 600 |
| Design Spec | 生成设计文档 | 30 | 5 |
| Design Review | 设计复审 | 30 | 5 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| Design | 具体设计 | 30 | 40 |
| Coding | 具体编码 | 30 | 120 |
| Code Review | 代码复审 | 20 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 20 |
| Reporting | 报告 | 20 | 90 |
| Test Report | 测试报告 | 30 | 60 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 680 | 1090 |
六、总结
- 事情依旧蛮多的——想象一下一周的时间被砍掉一大半还能剩下多少时间呢
- 研究不是很深入
- 短时间内复习了下python基础语法
- 利用jieba分词和向量余弦的方式完成此次实践
- 接触到了一些新的奇奇怪怪的东西,以前有设想过,并没有像这次这样实现过
- 比如自己编写程序会设置一些提示异常的语句,只不过没有用到抛出异常这套方式
- 虽然有些东西不是很有实际意义,但总体上来看还是蛮有趣以及蛮有收获的
- 人在路上,依旧前进呗

 浙公网安备 33010602011771号
浙公网安备 33010602011771号