Redis学习资料
英文:
5. Comparison of memcache, redis and ehcache as distributed caching framework
6. MemCached vs Redis for ASP.NET and Entity framework?
8. Best Redis library for Java
Redis存储机理:(点击图片看大图)

应用:
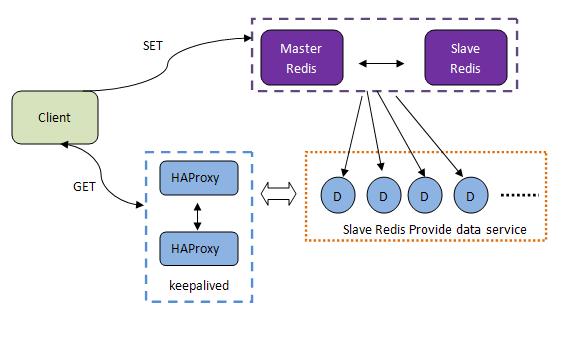
3. 集群部署:
使用Redis的五个错误:
(from: quora)
I don't know why you'd choose to be so specific about a particular number of "mistakes" (or caveats). It sounds like you're fishing for the contents for some article you're going to post to Yahoo! Insider (N Foos to Blah for the BlahBlah).
That said:
Here are a few things I'd suggest thinking about when you are considering using Redis:
- Choose consistent ways to name and prefix your keys. Manage your namespace.
- Create a "registry" of key prefixes which maps each to your internal (perhaps wiki) documents for those application which "own" them.
- For every class of data you put into your Redis infrastructure: design, implement and test the mechanisms for garbage collection and/or data migration to archival storage.
- Design, implement and test a sharding (consistent hashing) library before you've invested much into your application deployment and ensure that you keep a registry of "shards" replicated on each server.
- Isolate all your K/V store and related operations into a your own library/API or service and absolutely enforce the use of that API/service with an unrelenting and mercilessly iron hand
Let me explain each of these points in turn:
You should assume, from the outset, that your Redis infrastructure will be a common resource used by a number of applications or separate modules. You can have multiple databases on each server (numbered 0 through 31 by default, though you can increase the number of these). However, it's best to assume that you'll need to use key prefixes to avoid collisions among various different application/modules.
Consistent key prefixing: Manage your namespace:
Your applications/modules should provide the flexibility to change these key prefixes dynamically. Be sure that all keys are synthesized from the application/module prefix concatenated with the key that you're manipulating; make hard-coding of key strings verboten.
Registry: Document and Track your namespace:
I suggest that you have certain key patterns (prefixes or glob patterns) as "reserved" on your Redis servers. For example you can have __key_registry__ (similar to the Python reserved method/attribute names) as a hash of key prefixes to URLs into your wiki or Trac or whatever internal documentation site you use. Thus you can perform housekeeping on your database contents and track down who/what is responsible for every key you find in any database. (Institute a policy that any key which doesn't match any pattern in your registry can/will be summarily removed by your automated housekeeping).
Garbage Collection:
In a persistent, shared, key/value store, and in the case of Redis, in particular (where the full key/value store must fit in RAM at all times --- VM/swap storage is deprecated) the collection of garbage is probably the single major maintenance issue.
So you need to consider how you're going to select the data that needs to be migrated out of Redis (perhaps into your SQL/RDBMS or into some other form of archival storage), and how you're going to track and purge data which is out-of-date or useless.
The obvious approaches involve the use of the EXPIRE or EXPIREAT features/commands. This allows Redis to manage the garbage collection for you, either relative to your manipulation (creation or update) of any given key, or in terms of an absolute (seconds since the epoch) time specification. The only trick about Redis expiration is that you must re-set it every each update to a key.
This approach is fine for situations where it applies naturally. However, it's not useful if you want to cache data/keys indefinitely and only clean entries. For that I'd recommend you use a "ZSET" --- a set with values and "scores" which can be queried by ranges of those scores ... usually used for ordered/sorted collections. In my model you'd add items to the set, keys, and their associated timestamps (when you've added or updated the corresponding key/value pairs to the database itself. Then you can query that ZSET with something like: ZRANGEBYSCORE __EXPIRY__ 0 $SOME_EPOCH_TIME to get the subset of these which were added/updated more than a specific time ago. You can iterate over this results removing the corresponding key/value pairs until you've freed up enough space on the server to meet your needs (or accomplished other garbage collection requirement you'd set for yourself).
Another useful approach is to maintain one or more queues (Redis lists, manipulated by the RPUSH/LPUSH and RPOP/LPOP commands, their B* blocking cousins, or the rather tricky BRPOPLPUSH/RPOPLPUSH commands) which you use for persisting things to more durable bulk storage (such as your SQL RDBMS). Basically this functions as a work queue listing the keys (and perhaps some form of identifier regarding the canonical data store) that have been changed in Redis and which, therefore, need to be replicated out to your bulk storage. You can monitor the length of such queues to ensure that you're not experiencing an ever growing backlog.
Sharding:
Redis doesn't provide sharding. You should probably assume that you'll grow beyond the capacity of a single Redis server (slaves are for redundancy, not for scaling, though you can offload some read-only operations to slaves if you have some way to manage the data consistency --- for example the ZSET of key/timestamp values describe for expiry can also be used for some offline bulk processing operations; also the pub/sub features can be used for the master to provide hints regarding the quiescence of selected keys/data.
So you should consider writing your own abstraction layer to provide sharding. Basically imagine that you have implemented a consistent hashing method ... you run every synthesized key through that before you use it. While you only have a single Redis server then the hash to server mapping always ends up pointing to your only server. Later if you need to add more servers then you can adjust the mapping so that half or a third of your keys resolve to your other servers. Of course you'll want to implement this so that the failure on a primary server causes your library/service module to automatically retry on the secondary and possibly any tertiary server. Depending on your application you might even have the tertiary attempts fetch certain types of data from an another data source entirely (your SQL RDBMS, for example).
This is one area, in particular, where I'd like to see a robust third party (or antirez created) library written to handle all the fussy bits. Consistent hashing isn't difficult ... but it does require quite a bit of carefully written code to implement --- and it's something that should be kept well away from most of your applications coders. You want something that just works and continues to work even as you add additional server capacity (requiring migration utilities for all the keys which have been affected) and failures (requiring that you have already handled replication of data to secondary and/or tertiary servers).
Decouple your Redis Operations from your Application:
I hope you've seen foreshadowing of just how important this suggestion is to every other suggestion I've made. None of this will work if you have people just using your Redis infrastructure as an ad hoc, bottomless resource.
Don't think of your application as using Redis!
You are writing an application which uses a set of services. It just so happens that (some of) those services are provided by Redis servers. However, you should treat that as an implementation detail and focus on what services you need and what API you are providing to your application developers to provide them.
There is nothing that Redis offers that you can't accomplish through numerous alternatives. Every feature of Redis can be approximated or provided, to some degree, using an SQL/RDBMS backend if you write the correct sorts of code (possibly including stored procedures, triggers, etc and/or separate daemons) and implement the correct schema to do it.
If you focus on the API that you need to provide to your applications developers than you have some hope of replacing those parts which, inevitably, need to be replaced later (for whatever reason). You also provide considerably more flexibility as you develop additional applications and modules that need to interact with your existing databases.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号