从完整备份恢复单个innodb表
从完整备份恢复单个innodb表
转载自:http://www.cnblogs.com/gomysql/p/6600616.html#top
注意:这个方法只适合用于mysql8.0以前版本,从mysql8.0开始,innodb表只有一个ibd文件!!!
知数堂 大师兄的博客
现在大多数同学在线上采取的备份策略都是xtrabackup全备+binlog备份,那么当某天某张表意外的删除那么如何从xtrabackup全备中恢复呢?从mysql 5.6版本开始,支持可移动表空间(Transportable Tablespace)那么利用这个功能就可以实现单表的恢复,同样利用这个功能还可以把innodb表移动到另外一台服务器上。可以参考:https://yq.aliyun.com/articles/59271
下面进行从xtrabackup全备恢复单表的测试。
前提条件:数据库里所有表的frm文件存在
1. 开启了参数innodb_file_per_table
2. 安装工具:mysql-utilities,其中mysqlfrm可以读取表结构。
yum install mysql-utilities -y
查看原表中的数据:

mysql> select * from yayun.t1; +------+------+ | id | name | +------+------+ | 1 | aa | | 2 | bb | | 3 | cc | | 4 | dd | +------+------+ 4 rows in set (0.00 sec) mysql>
3. 执行备份:
innobackupex --defaults-file=/data/mysql/3306/my.cnf --user=root --password=123 --sock=/data/mysql/3306/mysqltmp/mysql.sock /data/
4. apply-log
innobackupex --defaults-file=/data/mysql/3306/my.cnf --apply-log /data/2017-03-22_16-13-00/
删除t1表:
mysql> use yayun Database changed mysql> drop table t1; Query OK, 0 rows affected (0.13 sec) mysql>
5. 读取表结构
mysqlfrm --diagnostic /data/2017-03-22_16-13-00/yayun/t1.frm
输出:
# Reading .frm file for /data/2017-03-22_16-13-00/yayun/t1.frm: # The .frm file is a TABLE. # CREATE TABLE Statement: CREATE TABLE `yayun`.`t1` ( `id` int(11) DEFAULT NULL, `name` char(180) DEFAULT NULL ) ENGINE=InnoDB; #...done.
6. 建表:
mysql> use yayun
Database changed
mysql> CREATE TABLE `yayun`.`t1` (
-> `id` int(11) DEFAULT NULL,
-> `name` char(180) DEFAULT NULL
-> ) ENGINE=InnoDB;
Query OK, 0 rows affected (0.08 sec)
mysql>
7. 加一个写锁,确保安全
mysql> lock tables t1 write; Query OK, 0 rows affected (0.00 sec) mysql>
8. 丢弃表空间:
mysql> alter table t1 discard tablespace; Query OK, 0 rows affected (0.07 sec) mysql>
9. 从xtrabackup备份中拷贝ibd文件,并且修改权限
[root@db_server_yayun_01 ~]# cp /data/2017-03-22_16-13-00/yayun/t1.ibd /data/mysql/3306/data/yayun/ [root@db_server_yayun_01 ~]# chown -R mysql.mysql /data/mysql/3306/data/yayun/t1.ibd
10. 载入表空间:
mysql> alter table t1 import tablespace; Query OK, 0 rows affected, 1 warning (0.15 sec) mysql> show warnings; +---------+------+------------------------------------------------------------------------------------------------------------------------------------------+ | Level | Code | Message | +---------+------+------------------------------------------------------------------------------------------------------------------------------------------+ | Warning | 1810 | InnoDB: IO Read error: (2, No such file or directory) Error opening './yayun/t1.cfg', will attempt to import without schema verification | +---------+------+------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql>
这里有警告,可以忽略。详情可以看:https://yq.aliyun.com/articles/59271
查询数据是否一致:
mysql> select * from t1; +------+------+ | id | name | +------+------+ | 1 | aa | | 2 | bb | | 3 | cc | | 4 | dd | +------+------+ 4 rows in set (0.00 sec) mysql>
11. 最后解锁:
mysql> unlock tables; Query OK, 0 rows affected (0.00 sec) mysql>
https://yq.aliyun.com/articles/59271
Question & Tips
flush tables .. for export需要注意什么
flush tables .. for export 会加锁,这时候,千万不能退出终端或session,否则加锁无效且.cfg文件自动删除。
如果没有.cfg文件,还能够import成功吗
可以,但是这样就没办法认证schema了
Level Code Message
Warning 1810 InnoDB: IO Read error: (2, No such file or directory) Error opening './test/t.cfg', will attempt to import without schema verification
1 row in set (0.00 sec)
如果discard了,还能select吗
很不幸,是不可以被select的
ERROR 1814 (HY000): Tablespace has been discarded for table 't'
discard 是什么意思,我就不能对其做任何操作了吗
discard的意思就是从数据库detached,会删除ibd文件,保留frm文件。
也就意味着,你可以对frm文件操作,比如:rename table,drop table ,但是不能对ibd文件操作,比如:dml
这样传输表的速度快吗?对io负载大吗?
这几步中,最慢的是import,其他几乎是瞬间完成。比较import做的事情也很多吗,anyway,都比mysqldump要快很多很多倍。
至于io负载,当然是有的,但是还是要优于mysqlimport很多很多哇。
如果两边表结构不一致,可以导入过来吗?
很遗憾,会报错
ERROR 1808 (HY000): Schema mismatch (Number of columns don't match, table has 5 columns but the tablespace meta-data file has 4 columns)
所以,这里也有一个缺陷就是,如果你有ibd文件,还不一定能够恢复,你必须还要知道该表的表结构才行
特别注意: 必须使用.cfg来帮助认证schema,否则很可能导致MySQL卡死
mysql-utilities是一个用python2.6写的一个工具集
root@VM_45_133_centos ~]# rpm -qa |grep mysql-utilities
mysql-utilities-1.3.6-1.el6.noarch
[root@VM_45_133_centos ~]# rpm -ql mysql-utilities
/usr/bin/mysqlauditadmin
/usr/bin/mysqlauditgrep
/usr/bin/mysqldbcompare
/usr/bin/mysqldbcopy
/usr/bin/mysqldbexport
/usr/bin/mysqldbimport
/usr/bin/mysqldiff
/usr/bin/mysqldiskusage
/usr/bin/mysqlfailover
/usr/bin/mysqlfrm
/usr/bin/mysqlindexcheck
/usr/bin/mysqlmetagrep
/usr/bin/mysqlprocgrep
/usr/bin/mysqlreplicate
/usr/bin/mysqlrpladmin
/usr/bin/mysqlrplcheck
/usr/bin/mysqlrplshow
/usr/bin/mysqlserverclone
/usr/bin/mysqlserverinfo
/usr/bin/mysqluc
/usr/bin/mysqluserclone
参考文章:
https://www.modb.pro/db/48635
聊到MySQL5.7 到 8.0.23数据字典更改,当然原先frm 文件不见了,多出了mysql.ibd文件。那到底改了什么。仅仅是文件名字的替换。
1.SDI是什么
Serialized Dictionary Information是指表结构元数据。MySQL 8.0通过在元数据发生变化时序列化元数据,提供了崩溃安全性。它的输出是JSON (JavaScript对象表示法)格式,称为序列化字典信息(SDI)。
对于InnoDB表,SDI与InnoDB用户表空间中的数据一起存储。对于MyISAM和其他存储引擎,它被写入数据目录中的.sdi文件。
除了临时表空间和撤销表空间文件外,所有InnoDB表空间文件中都存在SDI。InnoDB表空间文件中的SDI记录仅描述表空间中包含的表和表空间对象。
SDI数据通过对表或检查表的DDL操作进行更新的。
MySQL服务器使用DDL操作期间访问的内部API来创建和维护SDI记录。
当MySQL服务器升级到一个新的版本或版本时,SDI数据不会更新。
记录数据方式:对于InnoDB,一条SDI记录需要一个索引页,默认大小为16KB。但实际SDI数据被压缩以减少存储空间。
分区表:
对于由多个表空间组成的分区InnoDB表,SDI数据存储在第一个分区的表空间文件中。
注意,这个SDI只是元数据的备份。它不是元数据本身。数据字典完全存在于InnoDB数据字典表空间中。
2.SDI文件内容分析
SDI数据的存在提供了元数据冗余。那么,如果数据字典不可用,可以使用ibd2sdi工具(mysql8.0自带在安装文件bin目录下)直接从InnoDB表空间文件中提取对象元数据。
ibd2sdi是一个用于从InnoDB表空间文件中提取序列化字典信息(SDI)的实用程序,导出格式为 序列化为JSON。所有的InnoDB表空间文件都存在SDI数据。
file-per-table 表空间文件上运行(*.ibd files)文件,
一般表空间文件 (*.ibd files)。
系统表空间文件 (ibdata* files)
数据字典表空间(mysql.ibd)。
它不支持temporary表空间或undo表空间。
ibd2sdi可以在运行时使用,也可以在服务器离线时使用。在进行与SDI相关的DDL操作、回滚操作和undo log purge操作时,可能会出现ibd2sdi读取存储在表空间中的SDI数据失败的短时间间隔。
ibd2sqi目前功能,只是单纯的提取字典信息。核心还是抽取数据部分。
mysql8.0
下面进行从xtrabackup全备恢复多表的测试。
前提条件:数据库里所有表的ibd文件存在,并且能生成sdi文件
环境:A机器(包含要恢复的所有表文件),B机器(要恢复A机器的表数据)
0、通过 xtrabackup 备份 testdb库,在A机器执行
shell> innobackupex --defaults-file=/mysql/conf/my5508.cnf --user greatsql --password greatsql -H127.0.0.1 -P5508 --databases testdb /mysql/dbbackup
1、生成json文件,在A机器执行
#!/bin/bash # Written by steven # Name: ibdtojson.sh # Version: v1.0 # Parameters : 输入ibd文件所在父目录路径,格式:/data/app,注意路径后面不加/ # Function: 把mysql8单个库下面的所有表的ibd文件导出为json文件,脚本会自动遍历参数目录下的所有ibd文件,并在当前目录下创建ibd_json目录用来保存导出的json文件 # Create Date: 2019-08-27 basedir=$1 #保存输入的参数 ibd2sdicmd=/usr/local/mysql/bin/ibd2sdi #ibd2sdi命令路径 if [ -z "$basedir" ]; then echo "Usage: ./ibdtojson.sh /path/to/db/ " echo "请输入ibd文件所在父目录路径,格式:/data/app,注意路径后面不加/ " exit 2 fi if [ ! -d "$basedir" ]; then echo "Usage: ./ibdtojson.sh /path/to/db/ " echo "请输入ibd文件所在父目录路径,格式:/data/app,注意路径后面不加/ " exit 2 fi dir_json=./ibd_json TIMEOLD=$(date +"%Y-%m-%d-%H-%M-%S") if [ ! -d "$dir_json" ]; then mkdir $dir_json else mv $dir_json ${dir_json}_${TIMEOLD} && mkdir $dir_json fi for file in $basedir/*.ibd do data=${file##*/} $ibd2sdicmd $file >$dir_json/$data.json done
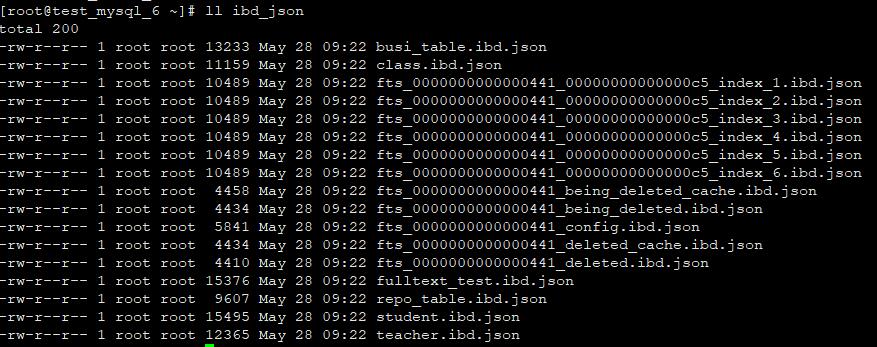
2、把生成出来的json文件转为sql文件,在A机器执行


#!/usr/bin/env python # -*- coding:utf-8 -*- # @Author : huazai # @Time : 2023/5/20 19:10 # @File : my2ibd.py # @Description : 要先安装numpy, pip install numpy,唯一索引只能恢复成二级索引 # @comment : 脚本会在当前目录下生成【sql年月日】的文件夹,存放生成好的sql文件 import json import re import os import sys import logging import numpy as np from datetime import datetime import argparse fmt_date = '%Y-%m-%d %H:%M:%S.%s' fmt_file = '%(lineno)s %(asctime)s [%(process)d]: %(levelname)s %(filename)s %(message)s' log_file = 'my2ibd.log' logger = logging.getLogger('my2ibd') logger.setLevel(logging.INFO) file_handler = logging.FileHandler(log_file, mode='a') file_handler.setFormatter(logging.Formatter(fmt_file, fmt_date)) logger.addHandler(file_handler) class innodb_ibd(): def __init__(self): pass def get_json(self, base_dir): pass def get_dir(self): abs_path = os.path.abspath(__file__) base_path = os.path.dirname(abs_path) p1 = os.path.join(base_path, 'ibd_json') data = os.listdir(p1) json_list = [] for data1 in data: json_list.append(os.path.join(p1, data1)) return json_list def get_ddl(self,jsonpath): ddl_res = '' # ibd_list = self.get_dir() ibd_list = [name for name in os.listdir(jsonpath) if name.endswith('.ibd.json') and not name.startswith('fts_00000')] for idb_js in ibd_list: idb_js = os.path.join(jsonpath + idb_js) with open(f"{idb_js}", "r", encoding='utf-8') as f: data: dict = json.load(f) data_ddl = data[1] engine = data_ddl.get('object').get('dd_object').get('engine') comment = data_ddl.get('object').get('dd_object').get('comment') table_name = data_ddl.get('object').get('dd_object').get('name') cols = '' ddl = '' hn = "'" bm = "`" coll = {} column_list = [] logger.info(f'handle table: {table_name}') ddl += f"DROP TABLE IF EXISTS `{table_name}`;\n" ddl += f"CREATE TABLE `{table_name}`" cols = '' for column in data_ddl['object']['dd_object']['columns']: if column['name'] in ['DB_TRX_ID', 'DB_ROLL_PTR', 'DB_ROW_ID', 'FTS_DOC_ID']: continue else: column_list.append(bm + column['name'] + bm) cols += f"\n`{column['name']}` {column['column_type_utf8']}{'' if column['is_nullable'] else ' NOT NULL '}" cols += f"{' DEFAULT NULL' if column['default_value_null'] and column['default_value_utf8'] != 'CURRENT_TIMESTAMP' else ''}" cols += f"{' NULL ' if column['update_option'] == 'CURRENT_TIMESTAMP' else ''}" cols += f"{' default ' + hn + column['default_value_utf8'] + hn if column['default_value_utf8'] and column['default_value_utf8'] != 'CURRENT_TIMESTAMP' else ''}" cols += f"{' AUTO_INCREMENT ' if column['is_auto_increment'] else ''} {' DEFAULT ' + column['default_value_utf8'] if column['default_value_utf8'] == 'CURRENT_TIMESTAMP' and column['update_option'] != 'CURRENT_TIMESTAMP' else ''}" cols += f"{' DEFAULT ' + column['default_value_utf8'] + ' ON ' + 'UPDATE ' + column['update_option'] if column['default_value_utf8'] == 'CURRENT_TIMESTAMP' and column['update_option'] == 'CURRENT_TIMESTAMP' else ''} " cols += f"{' comment ' + hn + column['comment'] + hn if column['comment'] else ''}," index_name = data_ddl.get('object').get('dd_object').get('indexes') foreign_name = data_ddl.get('object').get('dd_object').get('foreign_keys') indexl = [] foreign_key_list = [] pk = "PRIMARY KEY" ix = "index " full = "FULLTEXT KEY " for i in index_name: idx_name = f"{pk if i['name'] == 'PRIMARY' else ''}{ix + '`'+i['name']+'`' if i['name'] != 'PRIMARY' and i['type'] != 4 else ''}{full +'`'+ i['name']+'`' if i['type'] == 4 else ''}" idxl = [] for idx_c in i['elements']: if idx_c['length'] < 4294967295: idxl.append(idx_c['column_opx']) if len(idxl) == 0: continue for nnn in idxl: indexl.append(f'{idx_name}({",".join([column_list[x] for x in idxl])})') for foreign_i in foreign_name: for elements in foreign_i['elements']: fidx_name = f"{'CONSTRAINT `' + foreign_i['name'] + '` FOREIGN KEY' + '(' + column_list[elements.get('column_opx')] + ')' + ' REFERENCES `' + foreign_i['referenced_table_name'] + '`(`' + elements['referenced_column_name'] + '`)'}" foreign_key_list.append(fidx_name) indexl2 = list(np.unique(indexl)) foreign_key_list2 = list(np.unique(foreign_key_list)) index = ",\n".join([x for x in indexl2]) foreign_index = ",".join([x for x in foreign_key_list2]) col_index = f"{cols}\n{index}" if len(index) > 0 else f"{cols[:-1]}" dh = ',\n' ddl = f"{ddl}({col_index}{dh + foreign_index if foreign_name else ''}\n) ENGINE={engine} {' COMMENT ' + hn + comment + hn if comment else ''};".strip() ddl = ddl + "\n\n" ddl_res = re.sub(' +', ' ', ddl) now = datetime.now() # 获得当前时间 timestr = now.strftime("%Y_%m_%d") path_sql = 'sql' + timestr if not os.path.exists(path_sql): os.makedirs(path_sql) with open("{}/{}.sql".format(path_sql, table_name), mode='w', encoding='utf-8') as sql_object: sql_object.write(ddl_res) logger.info("sql generated at: {}/{}.sql".format(path_sql, table_name)) return ddl_res if __name__ == '__main__': # 需要json文件路径参数 parser = argparse.ArgumentParser(description='convert json file into sql file') parser.add_argument('-d', '--dir', dest="dir", required=True, help='the diretory of json file, such as /path/to/ibd_json') args = parser.parse_args() if os.path.isdir(args.dir): files = os.listdir(args.dir) if len(files) > 0: res = innodb_ibd() # 把参数传入 res.get_ddl(args.dir) logger.info('the parameter is not a dir or is a empty dir') sys.exit(1)
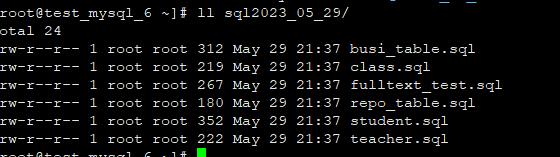
3、将生成的所有表sql文件统一导入到一个sql文件里,在A机器执行,导入完毕之后,把all.sql文件传到B机器,注意:如果有用到外键,一定要修改sql文件,把要引用的主表(父表)放在前面,子表放在后面,也就是先建父表再建子表
cat /root/sql2023_05_29/* > ./all.sql
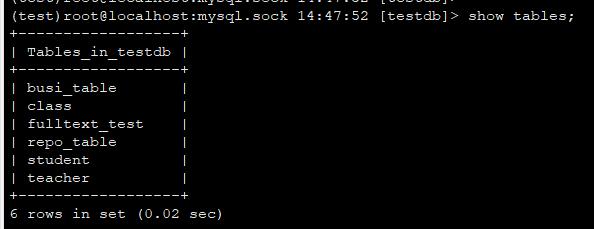
4、登入mysql,创建一个数据库,在B机器执行
create database testdb;
5、导入all.sql文件,在B机器执行
/usr/local/mysql/bin/mysql -uroot -p -S /data/mysql/mysql3306/tmp/mysql.sock testdb </tmp/all.sql
6、生成丢弃/导入表空间的 SQL 语句,需要在在my.cnf里添加 secure_file_priv = '/tmp' 并重启mysql,在B机器执行
# 生成锁表和丢弃表空间的SQL
mysql> select concat('lock tables ',table_schema,'.',TABLE_NAME , ' write', '; ','alter table ',table_schema,'.',TABLE_NAME , ' discard tablespace', ';') from information_schema.tables where TABLE_SCHEMA = 'testdb' /*指定数据库*/ into outfile '/tmp/lockanddiscard.sql';
# 生成导入表空间的SQL
mysql> select concat('lock tables ',table_schema,'.',TABLE_NAME , ' write', '; ','alter table ',table_schema,'.',TABLE_NAME , ' import tablespace', ';') from information_schema.tables where TABLE_SCHEMA = 'testdb' /*指定数据库*/ into outfile '/tmp/lockandimport.sql';
7、执行锁表和丢弃表空间的 SQL 语句,在B机器执行,注意:外键的父表是不能丢弃表空间的,也就是说外键父表无法恢复
mysql> source /tmp/lockanddiscard.sql;
查看底层数据文件,在B机器执行可以看到ibd文件已被丢弃

8、执行prepare 备份文件,注意这里需要加 --export 选项,用于生成import table所需的.exp文件,它允许导出单个表以进行导入到另一个服务器,在A机器执行
shell> innobackupex --apply-log --export /mysql/dbbackup/2022-12-29_10-11-07
查看备份文件目录,可以看到prepare备份文件后,多了 cfg,exp结尾的文件,在A机器执行
shell> ll -h /mysql/dbbackup/2022-12-29_10-11-07/testdb/ total 271M -rw-r----- 1 root root 67 Dec 29 10:11 db.opt -rw-r----- 1 root root 8.5K Dec 29 10:11 sbtest10.frm -rw-r--r-- 1 root root 578 Dec 29 10:57 sbtest10#P#p0.cfg -rw-r----- 1 root root 16K Dec 29 10:57 sbtest10#P#p0.exp -rw-r----- 1 root root 9.0M Dec 29 10:11 sbtest10#P#p0.ibd -rw-r--r-- 1 root root 578 Dec 29 10:57 sbtest10#P#p1.cfg
9、传输备份文件,将准备好的备份文件中后缀名为cfg,ibd,exp的文件传输到B机器的testdb库下
scp -r /mysql/dbbackup/2022-12-29_10-11-07/testdb/*.ibd /mysql/dbbackup/2022-12-29_10-11-07/testdb/*.cfg /mysql/dbbackup/2022-12-29_10-11-07/testdb/*.exp root@192.168.100.11:/mysql/dbdata/data5508/data/testdb/
10、在修改传输过来的文件的属主属组,在B机器执行
shell> chown -R mysql.mysql /data/mysql/mysql3306/data/*
11、执行导入表空间的 SQL 语句,在B机器执行
mysql> source /tmp/lockandimport.sql;
12、 执行解锁语句,在B机器执行
mysql> unlock tables;
13、检查一张表是否正常,在B机器执行
mysql> select * from testdb.student; +----+------------+------+------+ | id | teacher_id | name | sex | +----+------------+------+------+ | 1 | 1 | 2 | 2 | +----+------------+------+------+ 1 row in set (0.00 sec)
14、检查恢复出来的表是否正常,在B机器执行
/usr/local/mysql/bin/mysqlcheck -c -uroot -p -S /data/mysql/mysql3306/tmp/mysql.sock testdb
Enter password:
testdb.busi_table OK
testdb.class OK
testdb.fulltext_test
Warning : InnoDB: Index content_tag_fulltext is marked as corrupted
error : Corrupt
testdb.repo_table OK
testdb.student OK
testdb.teacher OK
注意:
(1)从mysql8.0开始,传输表空间不需要exp和cfg文件,只需要有ibd文件即可,并且直接在操作系统把ibd文件cp出来,在还原机器import tablespace也可以
(2)全文索引表不能通过传输表空间进行恢复
f


 浙公网安备 33010602011771号
浙公网安备 33010602011771号