CS144 lab1 TCPReassembler学习笔记
概述
CS144:计算机网络简介
将子串按顺序排列
// 构造一个 `StreamReassembler`,最多可以存储 `capacity` 个字节。 StreamReassembler( const size_t capcity); // 接收一个子字符串并将任何新的连续字节写入流中。 // // `data`: 段 // `index` 表示 `data` 中第一个字节的索引(按顺序放置) // `eof`:该段的最后一个字节是整个流中的最后一个字节 void push_substring ( const string & data, const uint64_t index, const bool eof); // 访问重组的字节流
const ByteStream stream_out();
// 已存储但尚未重组的子串中的字节数 size_t unassembled_bytes () const ; // 内部状态是否为空(输出流除外) bool empty() const ;
常见问题
实验结果

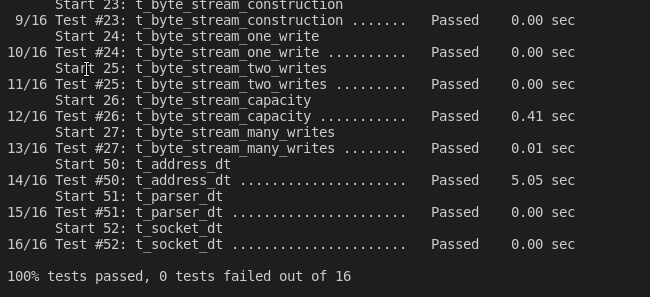
实验总结
这个实验主要是利用lab0写的读写字节流,完成一个字节重组器,对不按序到达的字串重组,排序好后读入字节流中,测试程序会自动读取字节流中的数据.
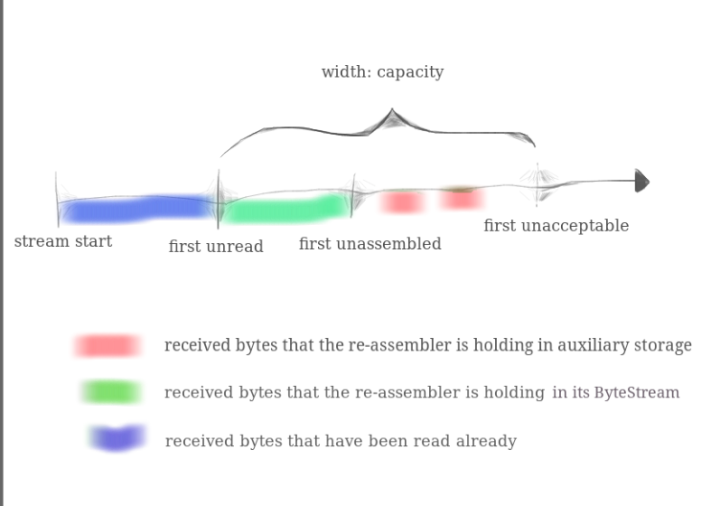
根据实验指示图,我们需要写一个数据结构,维持容量为capcity,绿色部分代表已经读入字节流但是还没读出的部分,红色部分代表还没有重组的部分,蓝色部分表示已经从字节流中读出的部分。
我们接受到data后,将不能重组的部分存储起来,如果能重组则直接重组,然后直接读入字节流。
不用担心读入失败问题,因为初始化时设置字节流的最大容量capcity和我们的数据结构维持的width是一样的,即绿色的部分永远小于width,所以只要能放进width的部分就可以直接读入字节流.
接受到data时,可能有超界的情况,比如:
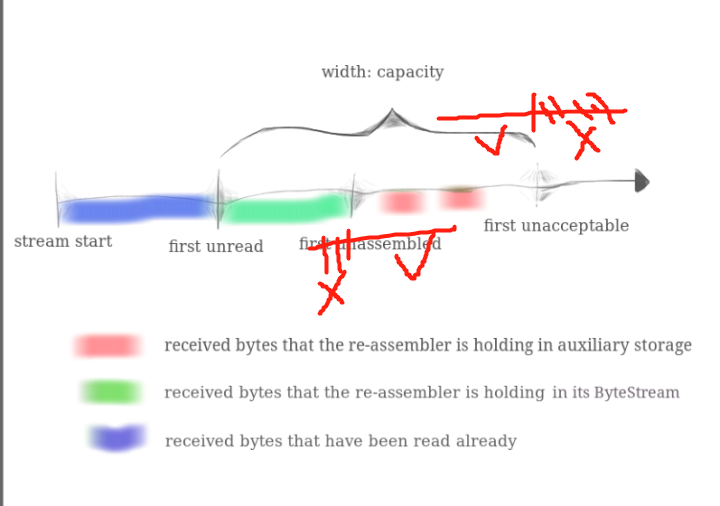
此时我们需要去掉两端多余的部分,保证data在不越界。
蓝色部分已经从字节流中读出,绿色部分也读入了字节流,我们实际需要储存的就只有红色部分,即未重组的子字符串
而每次push子字符串的时候需要重组,重组就要找到该子字符串附近能够重组的子字符串进行重组,于是想到了用set的upper_bound去快速查找
我们用set,自定义一个子字符串结构体node,然后利用其数据的start_index作为排序依据,然后每次push子字符串s1时,
先进行重组操作
用upper_bound找到start_index比它小(迭代器--)的另一个子字符串s2,然后向后一个一个查询,如果与s1可以重组,则将在s2的多出部分添加到s1,并从set中删除s2,最后将s2添加到set中
再进行读入判断
set是按照startindex排序的,所以我们只需要判断第一个节点的start_index是否为目前下一个需要读入到字节流的index,即图中的first_unressmbled,如果是,则表示可以读入,将第一个节点数据读入字节流,然后从set中删除该节点即可
eof判断
创建一个eof_index标记,当传入参数eof为true时,我们设置eof_index为data.size()+index,然后再每次数据读入字节流的时候判断是否读入数据已经到达eof_index,到达了就调用字节流的end_input函数结束读入。
stream_reassembler.hh
#ifndef SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH #define SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH #include "byte_stream.hh" #include <cstdint> #include <string> #include <set> //! \brief A class that assembles a series of excerpts from a byte stream (possibly out of order, //! possibly overlapping) into an in-order byte stream. class StreamReassembler { private: // Your code here -- add private members as necessary. struct node{ size_t start_idx=0; size_t end_idx=0; std::string data=""; node(size_t index,const std::string &DATA){ this->start_idx=index; this->data=DATA; this->end_idx=index+DATA.size()-1; } bool operator<(const node &b)const{ if(start_idx!=b.start_idx)return start_idx<b.start_idx; else return end_idx<b.end_idx; } }; ByteStream _outputStream; //!< The reassembled in-order byte stream size_t _capacity=0; //!< The maximum number of bytes std::set<node>_seg_buffer={}; size_t _input_end_idx=UINT64_MAX; size_t _cur_idx=0; size_t _unassembled_bytes=0; private: void mergeTo(const node&a,node &b); public: //! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes. //! \note This capacity limits both the bytes that have been reassembled, //! and those that have not yet been reassembled. StreamReassembler(const size_t capacity); //! \brief Receive a substring and write any newly contiguous bytes into the stream. //! //! The StreamReassembler will stay within the memory limits of the `capacity`. //! Bytes that would exceed the capacity are silently discarded. //! //! \param data the substring //! \param index indicates the index (place in sequence) of the first byte in `data` //! \param eof the last byte of `data` will be the last byte in the entire stream void push_substring(const std::string &data, const uint64_t index, const bool eof); //! \name Access the reassembled byte stream //!@{ const ByteStream &stream_out() const { return _outputStream; } ByteStream &stream_out() { return _outputStream; } //!@} //! The number of bytes in the substrings stored but not yet reassembled //! //! \note If the byte at a particular index has been pushed more than once, it //! should only be counted once for the purpose of this function. size_t unassembled_bytes() const; //! \brief Is the internal state empty (other than the output stream)? //! \returns `true` if no substrings are waiting to be assembled bool empty() const; }; #endif // SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH
stream_reassembler.cc
#include "stream_reassembler.hh" #include<iostream> // Dummy implementation of a stream reassembler. // For Lab 1, please replace with a real implementation that passes the // automated checks run by `make check_lab1`. // You will need to add private members to the class declaration in `stream_reassembler.hh` using namespace std; StreamReassembler::StreamReassembler(const size_t capacity) : _outputStream(capacity), _capacity(capacity) {} //! \details This function accepts a substring (aka a segment) of bytes, //! possibly out-of-order, from the logical stream, and assembles any newly //! contiguous substrings and writes them into the output stream in order. void StreamReassembler::mergeTo(const node &a,node &b){ if(a.start_idx<b.start_idx){ b.data.insert(b.data.begin(),a.data.begin(),a.data.begin()+b.start_idx-a.start_idx); b.start_idx=a.start_idx; } if(a.end_idx>b.end_idx){ b.data.insert(b.data.end(),a.data.end()-(a.end_idx-b.end_idx),a.data.end()); b.end_idx=a.end_idx; } } //先重组,再提交到缓冲区 void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) { size_t max_idx=_cur_idx-_outputStream.buffer_size()+_capacity-1; if(eof){_input_end_idx=index+data.size();} node nd(index,data); //边界情况 //如果已进入缓冲区的seg包含了该seg,或者该seg的起始idx都大于窗口最大值,或者seg为空直接丢弃 if(_cur_idx>nd.end_idx||nd.start_idx>max_idx||data.empty()){ //可能是eof延迟标记 if(_cur_idx>=_input_end_idx)_outputStream.end_input(); return ; } //去除左右越界数据 if(nd.start_idx<_cur_idx){ nd.data=data.substr(_cur_idx-nd.start_idx); nd.start_idx=_cur_idx; } if(nd.end_idx>max_idx){ nd.data=nd.data.substr(0,nd.data.size()-(nd.end_idx-max_idx)); nd.end_idx=max_idx; } //处理完边界情况,当前seg的data都在nextIdx和maxIdx之间,把可以重合的seg重组 if(!_seg_buffer.empty()){ set<node>::iterator it=_seg_buffer.upper_bound(nd); if(it!=_seg_buffer.begin()){ it--; } while(it!=_seg_buffer.end()){ //如果有交集,则删除迭代器,重合部分添加在nd中,别问我为什么判断要写这么丑,直接放里面不行嘛,嗯,你可以试试 int a=it->end_idx-(nd.start_idx-1),b=(nd.end_idx+1)-it->start_idx; if(a>=0&&b>=0){ mergeTo(*it,nd); _unassembled_bytes-=it->data.size(); it=_seg_buffer.erase(it); } //没有交集,但是seg已经在右侧,再往右找也找不到能产生交集的seg,退出 else if(it->start_idx>nd.end_idx){ break; }else{ it++; } } } //提交到缓冲区,找seg最前的部分,判断是否能读入字节流 if(nd.start_idx==_cur_idx){ _outputStream.write(nd.data); _cur_idx=nd.end_idx+1; if(_cur_idx>=_input_end_idx)_outputStream.end_input(); }else{ _seg_buffer.insert(nd); _unassembled_bytes+=nd.data.size(); } } size_t StreamReassembler::unassembled_bytes() const { return _unassembled_bytes; } bool StreamReassembler::empty() const { return _unassembled_bytes==0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号