FineGAN
概
利用GAN生成图片, 特别的是, 这是一种分层的生成方式: 背景 + 轮廓 + 色彩和纹理. 同时这个网络还可以用于无监督的分类.
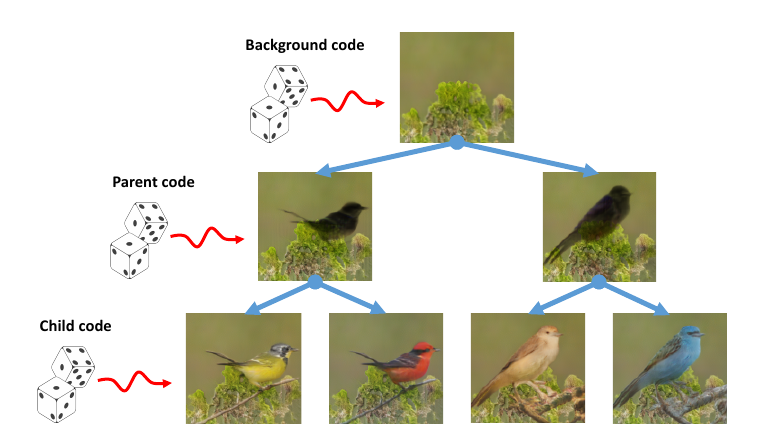
主要内容
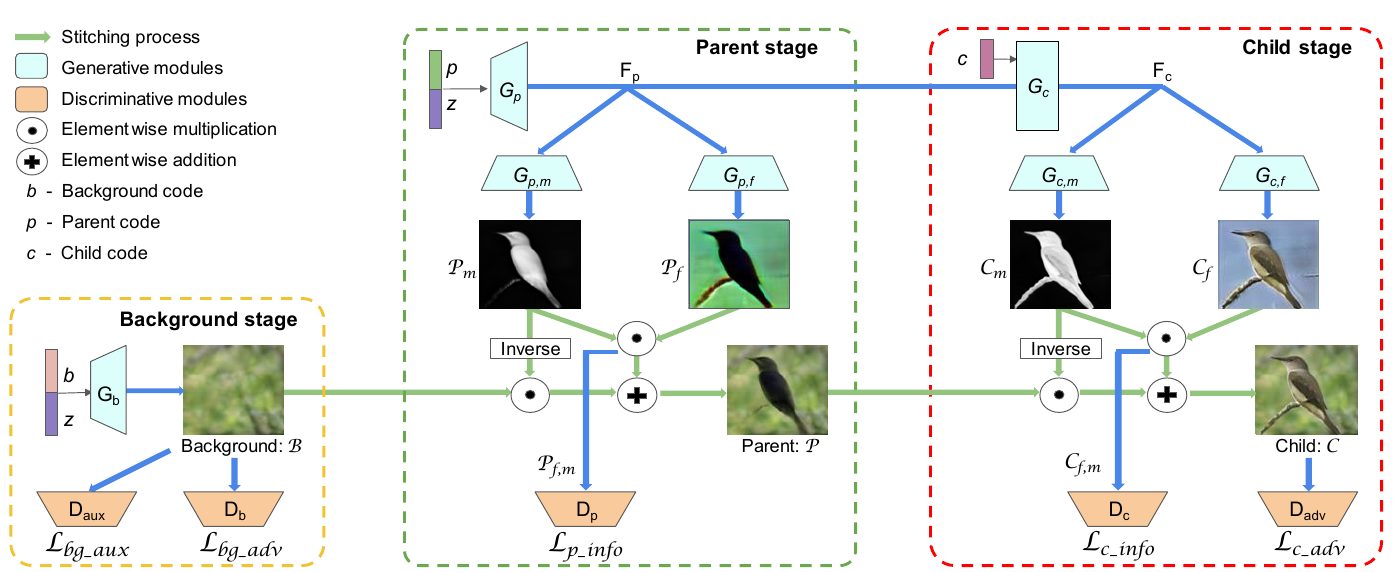
具体流程如下图所示:
-
背景code \(b\) + 隐变量\(z\) 生成背景 \(\mathcal{B}\);
-
轮廓code \(p\) + \(z\) 生成掩码\(\mathcal{P}_m\) 和轮廓\(\mathcal{P}_f\);
-
色彩和纹理code \(c\) 生成掩码\(\mathcal{C}_m\)和实例\(\mathcal{C}_f\).
-
最后的图片为
隐变量
注意到, 整个网络用到了4个隐变量, 分别是\(b, p, c\) 和\(z\), 其中
其中\(N_b, N_p, N_c\)皆为超参数.
另外, 基于一个直接理解, 即轮廓是较为抽象的信息, 同一类的物体的轮廓往往是一致, 但是同一类的物体要进行细分依赖于\(c\)即色彩和纹理, 所以作者假设\(N_p < N_c\), 多个\(c\)会共享一个\(p\)(虽然我不知道怎么实现这个的). 另外, 由于背景往往和物体有很大的联系, 比如鸭子飞到树上是比较少见的事情, 所以在训练的时候, 作者会选择令\(b=c\), 相当于少采样了一次. 但是在测试的时候, 这个约束可以不关, 我们完全可以让鸭子飞到太空上.
背景
利用背景信息, 其实一个很直接很直接的问题是, 怎么得到背景信息呢? 这实际上是一个分割问题, 作者会利用检测器将图片中的背景信息提取出来, 所以上面的\(D_b, D_{bg\_aux}\) 都是基于patch而非整个图片工作的. 这样, 对于生成器\(G_b\)生成的图片, 我们同样可以进行相同的操作了.
\(D_b\)便是普通的用于判断图片真假的判别器, 后者\(D_{bg\_aux}\)似乎是用来判断这个patch是否是背景图片的, 这能够使得网络更好的生成背景图片.
轮廓
轮廓这部分生成器会生成掩码和实例, 并且之前的特征会继续传给下一个阶段使用.
要知道, 想要通过判别器\(D\)来训练生成器的一个很重要的条件是真实数据是存在的, 但是我们实际上并没有这部分数据(即轮廓), 所以作者采用了类似InfoGAN的info损失:
其中\(D_p\)是用来近似条件分布的.
色彩和纹理
这部分是类似上面的, 因为我们同样没有色彩和纹理的数据, 同样有一个\(\mathcal{L_{c\_info}}\)的损失, 以及最后, 三个部分结合起来是最后的图片, 这部分可以直接用普通的adversarial loss \(\mathcal{L}_{c\_adv}\).
用于无监督分类
这个倒是没什么特别的, 就是再训练\(\phi_p, \phi_c\), 将图片\(\mathcal{C}_j\) 映射到隐变量\(c, p\), 并根据这些特征利用K均值分类.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号