
python 中的requests库,进行请求,发现一直使用的 r.text ,返回的内容,看不懂。如下图所示:

经查阅资料,发现 requests库 ,r.text返回的是decode处理后的Unicode型的数据,r.content 返回的是bytes 二进制的原始数据。如果headers 没有charset字符集指定的编码方式,r.text 会调用chardet 来计算字符集。
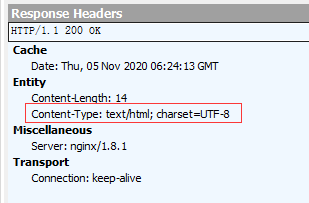
查看response的headers,如下:

而标准的response响应,是返回如下:
HTTP权威指南中,显示
如果HTTP响应中Content-Type字段没有指定charset,则默认页面是'ISO-8859-1'编码。
这种处理英文没问题,一遇到中文,就会出现乱码。
解决:
1.清楚 该站的字符集编码,可以使用r.encoding='xxx'模式,然后再r.text()会根据设定的字符集进行转换后输出。
返回中文应该可以正常查看。代码如下:
r.encoding='utf-8'
print(r.text),
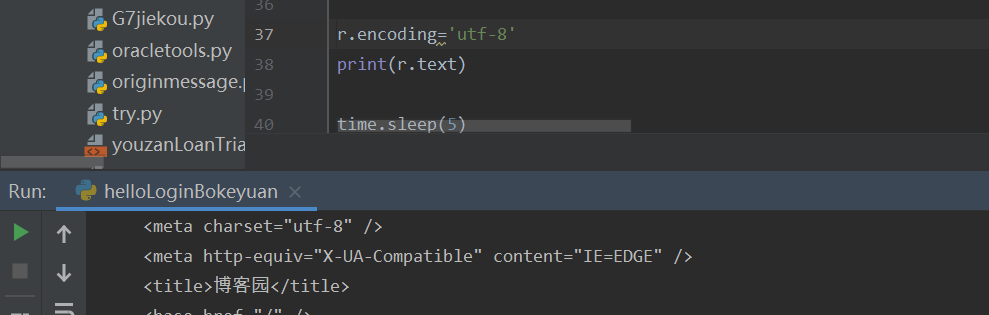
2. fiddler抓包,显示response已经 encoded了,让decode

请求后的响应response,先获取bytes 二进制类型数据,再指定encoding,即可。
如:
bytes=r.content
print(bytes.decode(encoding="utf-8"))
3.使用apparent_encoding可获取程序真实编码
r.encoding = r.apparent_encoding
print(r.text)
也可以正常查看response中的 中文。
此文,记录一下自己学习过程中遇到的坑。 详细更多资料,可查看下面 两篇文章,看后清楚很多。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号