〈2022-3-9〉使用<beautifulsoup>爬取ISO标准网站:已完成,代码记录(问题很多勉强把数据采集完了就这样吧)
TC:
from urllib.request import urlopen from bs4 import BeautifulSoup import pymysql conn=pymysql.connect(host='127.0.0.1',user='root',passwd='******',port= 3306 ,db='ISO',charset='utf8') cursor = conn.cursor() if conn: print("database[ISO] 连接成功!") def catch(url): address_url = 'https://www.iso.org/' text = urlopen(url).read() soup = BeautifulSoup(text,'html.parser') global tbody if soup.find('table',id='datatable-committees'): table = soup.find('table',id='datatable-committees') tbody = table.find('tbody') elif soup.find('table',id='datatable-committee-children'): table = soup.find('table',id='datatable-committee-children') tbody = table.find('tbody') TC = set() i = 0 j = 0 k = 0 for tr in tbody: if len(tr) > 1: k += 1 td = tr.findAll('td') tc = tr.a.string.strip() title = td[1].string.strip() address = address_url[:-1]+tr.a['href'] sql_select = 'select count(ID) from tc_basic where tc = %s and address = %s' cursor.execute(sql_select,(tc,address)) select_count = cursor.fetchall() # print('select_count:',select_count) if select_count[0][0] == 0: i += 1 # print('This is new data ! \n ----------Insert data !---------') sql_maxID = 'SELECT MAX(ID) FROM tc_basic' cursor.execute(sql_maxID) row = cursor.fetchall() if row[0][0] is None: id = 1 # print('This is first data! ID is : ', id) else: lastID = int(row[0][0]) id = lastID + 1 # print('Continue to insert , the next ID is : ', id) sql = 'insert into tc_basic values (%s,%s,%s,%s)' cursor.execute(sql,(id,tc,title,address)) conn.commit() else: j += 1 # print('This data already exists in the database! \n ----------Update data !---------') pass else: pass print('采集完毕!共计',k,'条数据:其中新增数据',i,'条,重复数据',j,'条。') if (__name__ == '__main__'): url = 'https://www.iso.org/standards-catalogue/browse-by-tc.html' print('采集中:',url) catch(url) x = 1 sql_upID = 'SELECT MAX(ID) FROM tc_basic' cursor.execute(sql_upID) row = cursor.fetchall() while x <= row[0][0]: sql_addr = 'SELECT address FROM tc_basic WHERE id =%s' cursor.execute(sql_addr,(x)) addr = cursor.fetchall() address_url = addr[0][0].strip() print('二次采集第',x,'条 addr:',address_url) catch(address_url) x += 1
Stage:
from urllib.request import urlopen from bs4 import BeautifulSoup import pymysql conn=pymysql.connect(host='127.0.0.1',user='root',passwd='******',port=3306 ,db='ISO',charset='utf8') cursor = conn.cursor() if conn: print("database[ISO] 连接成功!") def catch(url): text = urlopen(url).read() soup = BeautifulSoup(text,'html.parser') table = soup.find('table',attrs={'class':'table table-condensed responsive-table'}) tbody = table.find('tbody') # print('tbody:',tbody) sid = 1 for tr in tbody: if len(tr) > 1: num_td = 0 for td in tr: if td.text.strip(): if num_td == 0: num_td += 1 pass else: stage_id = sid stage_mix = td.text.strip() # print('stage:',stage_mix) stage_no = stage_mix[:5] print('stage:',stage_no) interpretation = stage_mix[5:] print('interpretation:',interpretation) num_td += 1 sid += 1 sql = 'insert into stage values (%s,%s,%s)' cursor.execute(sql,(stage_id,stage_no,interpretation)) conn.commit() print('采集完毕!共计',sid-1,'条数据。') if (__name__ == '__main__'): url = 'https://www.iso.org/stage-codes.html' print('采集中:',url) catch(url)
ICS:第一层
from urllib.request import urlopen from bs4 import BeautifulSoup import pymysql conn=pymysql.connect(host='127.0.0.1',user='root',passwd='******',port=3306 ,db='ISO',charset='utf8') cursor = conn.cursor() if conn: print("database[ISO] 连接成功!") def catch(url): address_url = 'https://www.iso.org/' text = urlopen(url).read() soup = BeautifulSoup(text,'html.parser') table = soup.find('table',id='datatable-ics') tbody = table.find('tbody') ics_id = 1 for tr in tbody: if len(tr) > 1: ics = tr.a.string.strip() print('ics:',ics) address = address_url[:-1] + tr.a['href'] print('address:',address) FIELD = tr.find('td',attrs={'data-title':'Field'}) field = FIELD.text.strip() print('field:',field) sql = 'insert into ics_basic values (%s,%s,%s,%s)' cursor.execute(sql,(ics_id,ics,field,address)) conn.commit() ics_id += 1 print('采集完毕!共计',ics_id-1,'条数据。') if (__name__ == '__main__'): url = 'https://www.iso.org/standards-catalogue/browse-by-ics.html' print('采集中:',url) catch(url)
ICS:第二层
from urllib.request import urlopen from bs4 import BeautifulSoup import pymysql import re conn=pymysql.connect(host='127.0.0.1',user='root',passwd='******',port=3306 ,db='ISO',charset='utf8') cursor = conn.cursor() if conn: print("database[ISO] 连接成功!") def catch(url,B_id,mark): address_url = 'https://www.iso.org/' text = urlopen(url).read() soup = BeautifulSoup(text,'html.parser') table = soup.find('table',id='datatable-ics-children') if table: tbody = table.find('tbody') i = 0 j = 0 k = 0 for tr in tbody: if len(tr) > 1: k += 1 if tr.find('a'): ics = tr.a.string.strip() address = address_url[:-1] + tr.a['href'] if mark == 1: address_list.append(address) else: print('第二次采集,地址不再追加。') pass else: td_ics = tr.find('td',attrs={'data-title':'ICS'}) ics = td_ics.text.strip() address = 'null' if mark == 1: address_list.append(address_url) else: print('第二次采集,地址不再追加。') pass print('ics:',ics) print('address:',address) FIELD = tr.find('td',attrs={'data-title':'Field'}) field_all = FIELD.text.strip() re_field = re.sub('\n+',';', field_all) re_re_field = re.sub(' +', ' ', re_field) field = re_re_field print('re_re_field:',re_re_field) # print('field_all:',field_all) sql_select = 'select count(ICS_ID) from ics where ICS = %s' cursor.execute(sql_select,(ics)) select_count = cursor.fetchall() # print('select_count:',select_count) if select_count[0][0] == 0: i += 1 # print('This is new data ! \n ----------Insert data !---------') sql_maxID = 'SELECT MAX(ICS_ID) FROM ics' cursor.execute(sql_maxID) row = cursor.fetchall() if row[0][0] is None: id = 1 # print('This is first data! ID is : ', id) else: lastID = int(row[0][0]) id = lastID + 1 # print('Continue to insert , the next ID is : ', id) sql = 'insert into ics values (%s,%s,%s,%s)' cursor.execute(sql,(id,ics,field,B_id)) conn.commit() else: j += 1 # print('This data already exists in the database! \n ----------Update data !---------') pass print('采集完毕!共计',k,'条数据:其中新增数据',i,'条,重复数据',j,'条。') else: pass if (__name__ == '__main__'): global address_list address_list = [] x = 1 sql_upID = 'SELECT MAX(ICS_B_ID) FROM ics_basic' cursor.execute(sql_upID) row = cursor.fetchall() while x <= row[0][0]: sql_addr = 'SELECT address FROM ics_basic WHERE ICS_B_ID =%s' cursor.execute(sql_addr,(x)) addr = cursor.fetchall() url = addr[0][0].strip() print('初次采集第',x,'条 address:',url) catch(url,x,1) x += 1 print('address_list:',len(address_list)) y = 1 sql_upID = 'SELECT MAX(ICS_ID) FROM ics' cursor.execute(sql_upID) row = cursor.fetchall() while y <= len(address_list): key = y-1 addr = address_list[key] sql_B_id = 'SELECT ICS_B_ID FROM ics WHERE ICS_ID =%s' cursor.execute(sql_B_id,(y)) id = cursor.fetchall() B_id = id[0][0] print('二次采集第',y,'条 address:',addr) catch(addr,B_id,2) y += 1
Standard:
from urllib.request import urlopen from bs4 import BeautifulSoup import pymysql conn=pymysql.connect(host='127.0.0.1',user='root',passwd='******',port=3306 ,db='ISO',charset='utf8') cursor = conn.cursor() if conn: print("database[ISO] 连接成功!") def catch(url,TC_ID): address_url = 'https://www.iso.org/' text = urlopen(url).read() soup = BeautifulSoup(text,'html.parser') table = soup.find('table',id='datatable-tc-projects') if table: tbody = table.find('tbody') i = 0 j = 0 k = 0 for tr in tbody: if len(tr) > 1: k += 1 span = tr.find('span') # print('span:',span) kinds = {'ok-circle':'Published standards' ,'record':'Standards under development' ,'ban-circle':'Withdrawn standards' ,'remove-circle':'Projects deleted'} for kind in kinds.keys(): # print('kind:',kind) s = kind in str(span) # print(kind,':',s) if s: global span_kind span_kind = kinds[kind] print('span_kind:',span_kind) continue td_Standard = tr.find('td',attrs={'data-title':'Standard and/or project'}) # print('td:',td_Standard) standard = td_Standard.a.text.strip() print('standard:',standard) summary = td_Standard.find('div',attrs={'class':'entry-summary'}).text.strip() print('summary:',summary) address = address_url[:-1] + td_Standard.a['href'] print('address:',address) td_Stage = tr.find('td',attrs={'data-title':'Stage'}) # print('td:',td_Stage) stage = td_Stage.a.string.strip() print('stage:',stage) sql_select = 'select count(STANDARD_ID) from standard where STANDARD = %s and address = %s' cursor.execute(sql_select,(standard,address)) select_count = cursor.fetchall() # print('select_count:',select_count) if select_count[0][0] == 0: i += 1 # print('This is new data ! \n ----------Insert data !---------') sql_maxID = 'SELECT MAX(STANDARD_ID) FROM standard' cursor.execute(sql_maxID) row = cursor.fetchall() if row[0][0] is None: STANDARD_ID = 1 # print('This is first data! ID is : ', id) else: lastID = int(row[0][0]) STANDARD_ID = lastID + 1 # print('Continue to insert , the next ID is : ', id) #将 ICS 数据写入 standard-ics表 li = tr.select('li') # print('li:',li) num_li = 0 while num_li < len(li): ICS_string = li[num_li].string.strip() num_li += 1 sql_ics = 'select ICS_ID from ics where ICS = %s' cursor.execute(sql_ics,(ICS_string)) select_ics = cursor.fetchall()[0][0] # ICS_ID = int(str(select_ics).replace(' ','')) print(ICS_string,':',select_ics) sql_standard_ics = 'insert into standard_ics values (%s,%s,%s)' cursor.execute(sql_standard_ics,(STANDARD_ID,num_li,select_ics)) conn.commit() #从 stage表 中获取对应的 STAGE_ID sql_stage = 'select STAGE_ID from stage where STAGE = %s' cursor.execute(sql_stage,(stage)) select_stage = cursor.fetchall() STAGE = select_stage[0][0] #standard数据入库 sql = 'insert into standard values (%s,%s,%s,%s,%s,%s,%s)' cursor.execute(sql,(TC_ID,STANDARD_ID,standard,summary,STAGE,span_kind,address)) conn.commit() else: j += 1 # print('This data already exists in the database! \n ----------Update data !---------') pass else: pass print('TC_ID(',TC_ID,')采集完毕!共计',k,'条数据:其中新增数据',i,'条,重复数据',j,'条。') else: pass if (__name__ == '__main__'): sql_startID = 'SELECT MAX(TC_ID) FROM standard' cursor.execute(sql_startID) row_sta = cursor.fetchall() if row_sta[0][0] is None: startID = 1 else: startID = row_sta[0][0] sql_endID = 'SELECT MAX(ID) FROM tc_basic' cursor.execute(sql_endID) row_end = cursor.fetchall() endID = row_end[0][0] print(startID,':',endID) while startID <= endID: # tc_basic表中共有 751 条数据 sql_url = 'SELECT address FROM tc_basic WHERE id =%s' cursor.execute(sql_url,(startID)) addr = cursor.fetchall() url = addr[0][0].strip() print('采集中:',url) catch(url,startID) startID += 1
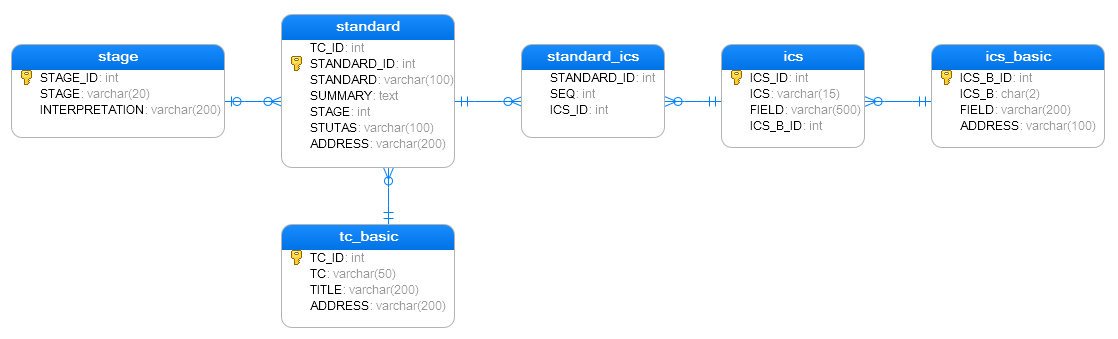
数据库模型:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号