
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | https://edu.cnblogs.com/campus/xbsf/2019nwnucs |
| 这个作业要求链接 | https://edu.cnblogs.com/campus/xbsf/2019nwnucs/homework/12527 |
| 我的课程学习目标 | (1)掌握软件项目个人开发流程。(2)掌握Github发布软件项目的操作方法 |
| 这个作业在哪些方面帮助我实现学习目标 | 项目设计开发以及提交到Github |
| 项目Github的仓库链接地址 | https://github.com/MJJBQ/software_project |
任务一:点评班级博客
| 点评博客同学姓名 | 点评博客链接 | 点评博客内容 |
|---|---|---|
| 阮凯 | https://www.cnblogs.com/RuanKaio/p/15968375.html#5025890 | 如果可以添加目录导航,整个页面看起来会更好!我认为一个好的软件是存在BUG的!不能做出完全没有BUG的软件,任何软件都有缺陷,这是软件测试的领域的一个真理。 |
| 潘晴 | https://www.cnblogs.com/panqing/p/15971081.html#5032025 | 在问题1中,我认为一个合格的程序员并不是说他精通多少语言,精通语言只是其中所具备的一部分。 |
| 郭清华 | https://www.cnblogs.com/N0Name/p/15954466.html#5032023 | 对于第三个问题,博主在团队合作中可以提前与队友制定好工作分派 |
任务二:阅读《构建之法》
已详细阅读《构建之法》第1章、第2章,已掌握PSP流程,并在本次实验中运用。
- 第1章
重要概念:软件=程序+软件工程 - 第2章
单元测试:程序要进行单元测试来保证程序的健壮性。
回归测试:如果在原版本上运行的测试用例通过的话,在下一版本上再运行时,却没有通过,这就是软件"退化",所以需要进行回归测试。在新版本上运行所有已经通过的测试用例,来验证后面的版本没有出现软件"退化"的情况。但是如果是模块功能发生了变化,那么测试用例也需要修改来测试新的模块。
效能分析:就是找出程序运行时,哪个函数或方法消耗的时间多,就是程序运行的瓶颈所在,进行效能分析,从而对相应模块的代码进行优化。
PSP的特点:- 不局限于某一种软件技术 (如编程语言), 而是着眼于软件开发的流程, 这样不同应用的工程师可以互相比较。
- 不依赖于考试, 而主要靠工程师自己收集数据, 然后统计提高。
- 在小型,初创的团队中, 高质量的项目需求很难找到,这意味着给程序员的输入质量不高,在这种情况下, 程序员的输出 (程序/软件) 往往质量不高, 然而这并不能全部由程序员负责。
- PSP 依赖于数据
- 需要工程师输入数据, 记录工程师的各项活动, 这本身就需要不小的代价。
- 如果数据不准确或有遗失, 怎么办? 让工程师编造一些?
- 如果一些数据不利于工程师本人 (例如: 花很多时间修改缺陷), 我们怎么能保证工程师能如实地记录这些数据呢?
- PSP的目的是记录工程师如何实现需求的效率, 而不是记录顾客对产品的满意度。工程师可能很高效地开发出一个顾客不喜欢的软件, 那这个工程师还是一个优秀的工程师么?
任务三:项目开发
1.需求分析
本项目需要设计一个可以使用动态规划算法、贪心算法以及回溯算法实现{0-1}背包问题求解的软件。背包问题是NP Complete问题,也是一个经典的组合优化问题,有着广泛而重要的应用背景。{0-1}背包问题是最基本的KP问题形式,比起背包问题不需要考虑每一种物品该放入多少,而是只考虑放入不放入,实现起来相对容易。需求中一共给出了9组数组,这些数据存在18个文件中,18个文件分为2组,其中每一组里面的.in文件中存储了该组每个物品的重量和价值,.out文件中存储了背包容量。项目要求对任意一组数据都可以使用动态规划算法、贪心算法以及回溯算法进行求解,获得求解结果和求解过程所需要的时间。最后将求解结果写入到txt或者excel文件中。
2.功能设计
2.1基本功能
本项目基本功能主要有数据读入、数据散点图绘制、数据按照重量非递增排序、动态规划算法解决0-1背包问题、贪心算法解决0-1背包问题、回溯算法解决0-1背包问题以及结果保存。
2.2扩展功能
本项目扩展功能主要有多算法排序和散点图坐标绘制。多算法排序根据数据排列顺序、使用不同排序算法进行排序,这里主要使用了冒泡排序、选择排序和插入排序。散点图坐标绘制通过计算坐标轴长度和数据量个数等间隔划分坐标轴。
3.设计实现
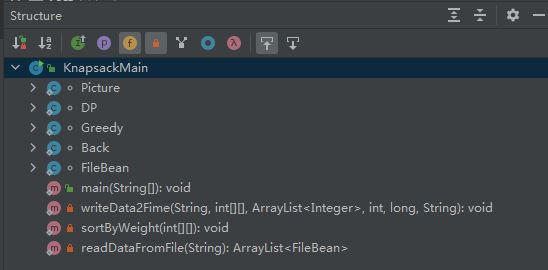
本项目一共包括KnapsackMain、Picture、DP、Greedy、Back和FileBean六个类,KnapsackMain是主类,里面有程序入口main方法,还有根据重量非递增排序方法sortByWeight。这里使用三种排序方式实现。文件数据读取方法readDataFromFile,该类使用FileReader和BufferReader读取文件数据。结果回写文件方法writeData2Fime,该类使用FileWriter和BufferedWriter回写文件数据。Picture类用来绘制散点图,该类继承Jpanel类,主要对paintComponent方法进行了重写。DP类负责使用动态规划算法解决0-1背包问题,Greedy类负责使用贪心算法解决0-1背包问题,Back类负责使用回溯算法解决0-1背包问题,FileBean是对文件数据的封装,主要包括文件名、文件数据和背包容量。Picture、DP、Greedy、Back和FileBean都是KnapsackMain类的静态内部类,类之间关系结构如图所示。
4.测试运行
4.1 文件读写功能测试,如下图所示,读取所有文件数据,并显示文件名列表。

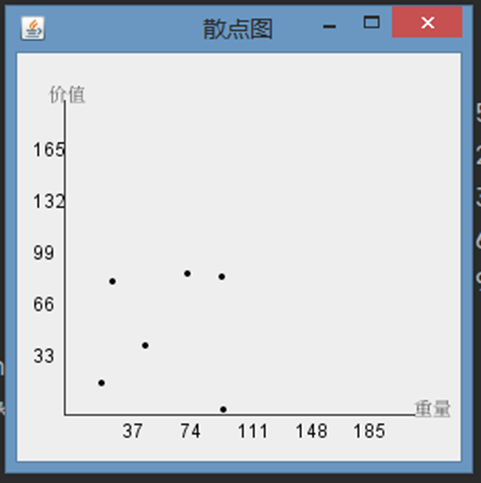
4.2 散点图绘制功能测试,如下图所示,绘制所选数据源的散点图,并显示扩展的坐标刻度。
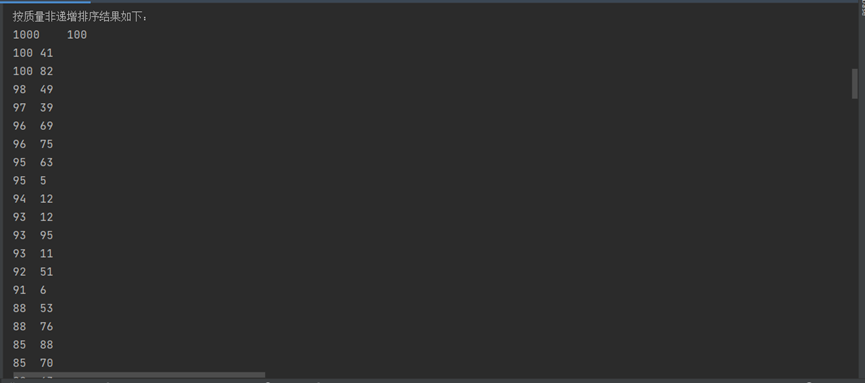
4.3 按重量非递增排序功能测试,如下图所示,对选择数据源进行排序,并显示排序后的数据。
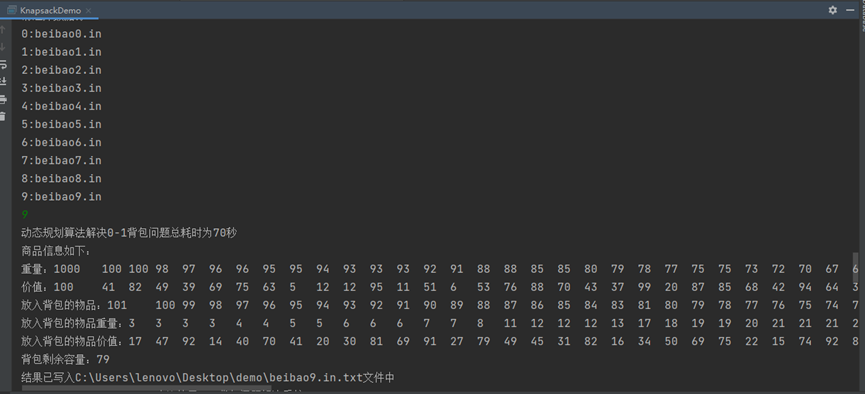
4.4 动态规划求解功能测试,如下图所示,对选择数据源使用动态规划算法求解,并显示求解结果。
4.5 贪心法求解功能测试,如下图所示,对选择数据源使用贪心算法求解,并显示求解结果。
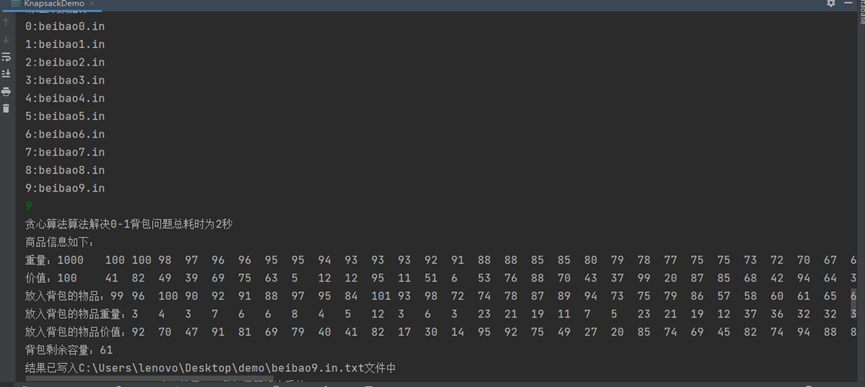
4.6 回溯法求解功能测试,如下图所示,对选择数据源使用回溯算法求解,并显示求解结果。

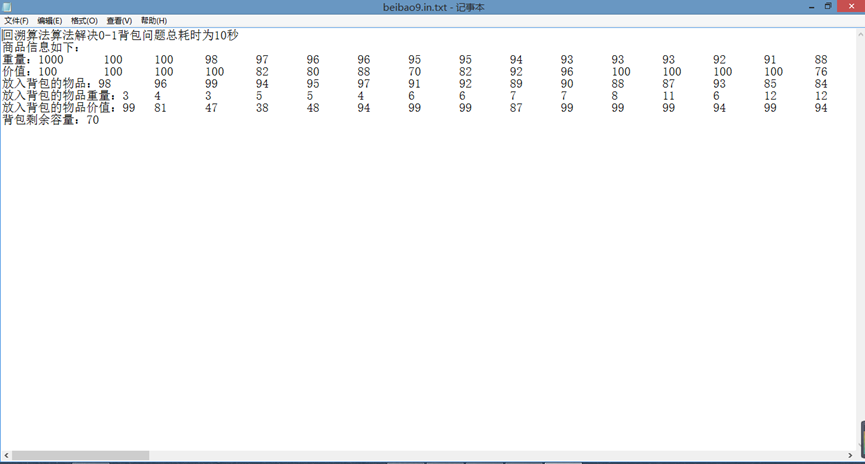
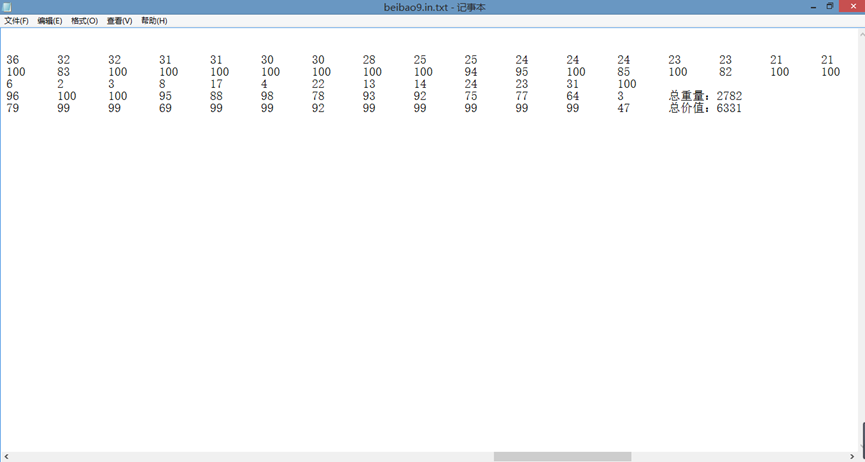
4.7 结果回写功能测试,如下图所示,每次对问题求解后都会写入对应文件。
5.粘贴自己觉得比较独特的或满意的代码片段,用博客园的代码控件来显示。
5.1文件数据读取代码
点击查看代码
private static ArrayList<FileBean> readDataFromFile(String root) {
ArrayList<FileBean> fileLists = new ArrayList<FileBean>();
File rootPath = new File(root);
if (rootPath.exists()) {
File files[] = rootPath.listFiles();
if (files == null || files.length == 0) {
System.out.println("文件夹为空");
return null;
} else {
String realName = null;
Map realMap = null;
for (File item : files
) {
if (item.isFile()) {
String name = item.getName();
String type = name.substring(name.lastIndexOf(".") + 1);
int totalWeight = 0;
if (type.equals("in")) {
try {
realName = name;
BufferedReader br = new BufferedReader(new FileReader(item));
String line;
List lists = new ArrayList<>();
while ((line = br.readLine()) != null) {
lists.add(line);
}
br.close();
int i = 0;
int data[][] = new int[lists.size()][2];
Iterator<String> iterator = lists.iterator();
while (iterator.hasNext()) {
String array[] = iterator.next().split(" ");
data[i][0] = Integer.valueOf(array[0]);
data[i][1] = Integer.valueOf(array[1]);
i++;
}
Map map = new HashMap<>();
map.put(name, data);
realMap = map;
} catch (FileNotFoundException e) {
e.printStackTrace();
return null;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
if (type.equals("out")) {
try {
BufferedReader br = new BufferedReader(new FileReader(item));
String line;
while ((line = br.readLine()) != null) {
totalWeight = Integer.valueOf(line.toString().trim());
}
br.close();
FileBean bean = new FileBean();
bean.setData(realMap);
bean.setName(realName);
bean.setTotalWeight(totalWeight);
fileLists.add(bean);
} catch (FileNotFoundException e) {
e.printStackTrace();
return null;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
}
}
return fileLists;
}
}
return null;
}
点击查看代码
@Override
protected void paintComponent(Graphics g) {
super.paintComponent(g);
Graphics2D draw = (Graphics2D) g;
draw.setRenderingHint(RenderingHints.KEY_ANTIALIASING, RenderingHints.VALUE_ANTIALIAS_ON);
int w = getWidth();
int h = getHeight();
draw.draw(new Line2D.Double(DIS, DIS, DIS, h - DIS));
draw.drawString("价值", DIS - 10, DIS);
draw.draw(new Line2D.Double(DIS, h - DIS, w - DIS, h - DIS));
draw.drawString("重量", w - DIS, h - DIS);
int ymin = (h - 2 * DIS) / data.length;
int xmin = (w - 2 * DIS) / data.length;
draw.setPaint(Color.black);
int ydis = ymin;
int xdis = xmin;
for (int i = 0; i < data.length; i++) {
int x = data[i][0];
int y = data[i][1];
if (i != data.length - 1) {
draw.drawString(xdis + "", xdis + DIS, h - DIS + 15);
draw.drawString(ydis + "", DIS - 20, h - (ydis + DIS));
xdis += xmin;
ydis += ymin;
}
draw.fill(new Ellipse2D.Double(x + DIS, h - (y + DIS), 4, 4));
}
}
点击查看代码
for (int i = 0; i < data.length; i++) {
//选择排序
//首先在未排序的数列中找到最小(or最大)元素,然后将其存放到数列的起始位置;
//接着,再从剩余未排序的元素中继续寻找最小(or最大)元素,然后放到已排序序列的末尾。
//以此类推,直到所有元素均排序完毕。
for (int j = i + 1; j < data.length; j++) {
if (data[j][0] > data[i][0]) {
int temp1 = data[j][0];
data[j][0] = data[i][0];
data[i][0] = temp1;
int temp2 = data[j][1];
data[j][1] = data[i][1];
data[i][1] = temp2;
}
}
}
for (int i = 1; i < data.length; i++) {
//插入排序
for (int j = i ; j > 0; j--) {
if (data[j][0] > data[i][0]) {
int temp1 = data[j][0];
data[j][0] = data[i][0];
data[i][0] = temp1;
int temp2 = data[j][1];
data[j][1] = data[i][1];
data[i][1] = temp2;
}
}
}
for (int i = 0; i < data.length; i++) {
//冒泡排序
for (int j = 0 ; j < data.length-1-i ; j++) {
if (data[j][0] > data[i][0]) {
int temp1 = data[j][0];
data[j][0] = data[i][0];
data[i][0] = temp1;
int temp2 = data[j][1];
data[j][1] = data[i][1];
data[i][1] = temp2;
}
}
}
点击查看代码
private static void writeData2Fime(String path, int[][] data, ArrayList<Integer> list, int totalWeight, long time, String model) {
File file = new File(path + ".txt");
sortByWeight(data);
if (!file.exists()) {
try {
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
try {
BufferedWriter bw = new BufferedWriter(new FileWriter(file));
bw.write(model+"算法解决0-1背包问题总耗时为"+time+"秒");
bw.newLine();
bw.write("商品信息如下:");
bw.newLine();
bw.write("重量:");
for (int j = 0; j < data.length; j++) {
bw.write(data[j][0] + "\t");
}
bw.newLine();
bw.write("价值:");
for (int j = 0; j < data.length; j++) {
bw.write(data[j][1] + "\t");
}
bw.newLine();
bw.write("放入背包的物品:");
for (int j = 0; j < list.size(); j++) {
bw.write(list.get(j) + "\t");
}
bw.newLine();
bw.write("放入背包的物品重量:");
int weight = 0;
for (int j = 0; j < list.size(); j++) {
bw.write(data[list.get(j) - 1][0] + "\t");
weight += data[list.get(j) - 1][0] - 1;
}
bw.write("总重量:" + weight);
bw.newLine();
bw.write("放入背包的物品价值:");
int value = 0;
for (int j = 0; j < list.size(); j++) {
bw.write(data[list.get(j) - 1][1] - 1 + "\t");
value += data[list.get(j) - 1][1] - 1;
}
bw.write("总价值:" + value);
bw.newLine();
bw.write("背包剩余容量:" + (totalWeight - weight));
bw.flush();
bw.close();
BufferedReader br = new BufferedReader(new FileReader(file));
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
System.out.println("结果已写入" + file.getAbsolutePath() + "文件中");
} catch (IOException e) {
e.printStackTrace();
}
}
任务四:项目源码
项目源码已提交至Github账号中:https://github.com/MJJBQ/software_project
总结
-
在设计软件时,为了更好地遵循“模块化”设计思想,我对同一类问题,使用相同的方法解决,比如每一求解完成后,都对数据按重量非递增排序都通过调用sortByWeight方法实现。对于相似的操作,全部分装在一个类中,比如和动态规划相关的算法,全部用封装在DP类中。
-
展示PSP,这个环节重要的是让自己看到自己的估计和实际消耗时间,哪个环节耗时最多,哪个环节估计和实践相差巨大?为什么?
贪心算法的实现耗时最多,对递归程序出口没弄清楚,程序一直调用,造成栈溢出。文件读写环节估计和实践相差较大,原因在于理论逻辑清除,编程技术不熟练。
PSP展示
| PSP2.1 | 任务内容 | 计划共完成需要的时间(h) | 实际完成需要的时间(h) |
|---|---|---|---|
| Planning | 计划 | 2 | 1.5 |
| - Estimate | - 估计这个任务需要多少时间,并规划大致工作步骤 | 2 | 1.5 |
| Development | 开发 | 30 | 40 |
| - Analysis | - 需求分析(包括学习新技术) | 10 | 12 |
| - Design Spec | - 生产设计文档 | 2 | 1.5 |
| - Design Review | - 设计复审(和同事审核设计文档) | 1 | 1 |
| - Coding Standard | 代码规范 | 1 | 1 |
| - Design | - 具体设计 | 2 | 5 |
| - Coding | - 具体编码 | 8 | 13 |
| - Code Review | 代码复审 | 3 | 3 |
| - Test | - 测试(自我测试,修改代码,提交修改) | 5 | 8 |
| Reporting | 报告 | 3 | 2 |
| - Test Report | - 测试报告 | 2 | 1 |
| - Size Measurement | - 计算工作量 | 1 | 0.5 |
| - Postmortem & Process Improvement Plan | - 事后总结 ,并提出过程改进计划 | 0.5 | 1 |
如果所有环节你都认真做了,此处你应该有很多经验愿意与大家分享。.
本次项目对我来说很有意义,通过一周多的时间写了600多行代码,在编码能力提升的同时,对常见的排序算法和优化算法有了更多的了解,特别在贪心算法使用递归实现时,对
程序出口条件的不清楚,使得程序一直递归调用,造成栈溢出。通过本次项目,在以后的实验中我可能会更加用心。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号