性能优化
性能优化
1.mariadb 5.5 innodb 升级到 mysql 5.7 tokudb【记得替换存储引擎】
2.去掉无用监控项,增加监控项的取值间隔,减少历史数据的保存周期
3.被动模式改为主动模式
4.针对zabbix-server进程数量调优,谁的进程忙,加大他的进程数量
5.针对zabbix-server缓存调优,谁的剩余内存少,就加大他的缓存
6.针对zabbix历史数据和趋势图的表,进行周期性分表
7.固态硬盘 大内存
8.zabbix proxy
第1章 zabbix版本升级
1.官网下载2.2版本release
[root@git_web02 ~]# rpm -ivh zabbix-release-2.2-1.el7.noarch.rpm
2.修改配置文件
[root@git_web02 ~]# cat /etc/yum.repos.d/zabbix.repo
[zabbix]
name=Zabbix Official Repository - $basearch
baseurl=https://mirrors.tuna.tsinghua.edu.cn/zabbix/zabbix/2.2/rhel/7/$basearch/
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-ZABBIX
[zabbix-non-supported]
name=Zabbix Official Repository non-supported - $basearch
baseurl=https://mirrors.tuna.tsinghua.edu.cn/zabbix/non-supported/rhel/7/$basearch/
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-ZABBIX
gpgcheck=1
3.安装其他软件
[root@git_web02 ~]# yum install zabbix-server-mysql zabbix-web-mysql -y
[root@git_web02 ~]# yum install mariadb-server.x86_64 -y
[root@git_web02 ~]# systemctl start mariadb.service
[root@git_web02 ~]# systemctl enable mariadb.service
4.数据库操作
[root@git_web02 ~]# mysql_secure_installation
[root@git_web02 ~]# mysql -uroot -p123
MariaDB [(none)]> create database zabbix default charset utf8;
MariaDB [(none)]> grant all on zabbix.* to zabbix@localhost identified by '123';
5.导出数据库
[root@git_web02 ~]# cd /usr/share/doc/zabbix-server-mysql-2.2.23/create
[root@ crete]# ls
data.sql image.sql schema.sql【先导表 schema】
[root@ crete]# mysql -uzabbix -p123 zabbix <schema.sql
[root@ crete]# mysql -uzabbix -p123 zabbix <image.sql
[root@ crete]# mysql -uzabbix -p123 zabbix <data.sql
[root@ crete]# vim /etc/zabbix/zabbix_server.conf
...............
DBHost=localhost
DBName=zabbix
DBUser=zabbix
DBPassword=123
...............
[root@ crete]# systemctl start zabbix-server.service
[root@ crete]# systemctl enable zabbix-server.service
6.配置apache文件
[root@ crete]# grep -n "Shanghai" /etc/httpd/conf.d/zabbix.conf
20: php_value date.timezone Asia/Shanghai

7.升级4.0版本
[root@git_web02 ~]# rpm -e zabbix-release
[root@git_web02 ~]# rpm -Uvh https://repo.zabbix.com/zabbix/4.0/rhel/7/x86_64/zabbix-release-4.0-2.el7.noarch.rpm
[root@git_web02 ~]# vim /etc/yum.repos.d/zabbix.repo
gpgcheck=0
baseurl=https://mirrors.tuna.tsinghua.edu.cn/zabbix/zabbix/4.0/rhel/7/$basearch/debuginfo/
8.安装程序包
[root@git_web02 ~]# yum -y install zabbix-server-mysql zabbix-web-mysql zabbix-agent mariadb-server
9.重启
[root@git_web02 ~]# systemctl restart zabbix-server.service

第2章 zabbix分布式监控
alert报警功能没有 其他的功能都有
1.概述
Zabbix通过 Zabbix proxies为基础设施提供有效和可用的分布式监控
代理( proxies)可用于代替 Zabbix server本地收集数据,然后将数据报告给服务器
2.proxy待征
当选择使用/不使用 proxy时,必须考虑几个注意事项:
| proxy | |
|---|---|
| 轻星级( Lightweight) | yes |
| 图形界面( GUI ) | no |
| 独立工作 ( Works independent ) | yes |
| 易子维护( Easy maintenance ) | yes |
| 自动生成数据库( Automatic DB creation )1 | yes |
| 本地管理( local administration ) | no |
| 准皖入式硬件( Ready for embedded hardware ) | yes |
| 单向TCP连接( One way TCP connections ) | yes |
| 集中配置( centralised configuration ) | yes |
| 生成通知( Generates notifications ) | no |
3.zabbix porxy代理概述
zabbix proxy可以代替 zabbix server收集性能和可用性数据然后把数据汇报给 rabbiⅸ server并且在一定程度上分担了zabbix-server的压力。
此外,当所有 agents和 proxies报告给一个 abbiⅸκ server并且所有数据都集中收集时,使用 proxy是实现集中式和分布式监控的最简单方法。
4.zabbⅸ proxy使用场景
1.监控远程区域设备
2.监控本地网络不稳定区域
3.当zabbⅸ监控上千设备时,使用它来减轻 server的压力
4.简化分布式监控的维护

zabbix proxy仅仅需要一条tcp连接到 zabbix server所以防火墙上仅仅需要加上一条规则即可
proxy 收集到数据之后,首先将数据缓存在本地,然后在一定得时间之后传递给 zabbix server,这样就不会因为服务器的任何临时通信问题而丢失数据。这个时间由porxy配置文件中的参数 ProxyLocalBuffer和 ProxyOfflineBuffer决定。
注意:
1.zabbix proxy数据库必须和 server分开,否则数据会被破坏。
2.从 Zabbix server数据库直接更新最新配置的proxy可能会比 Zabbix server新,而 Zabbix server的配置由于CacheUpdateFrequency的原因而无法快速更新。因此, proxy收集发送 Zabbix server数据可能会被忽略 。
使用 agent active模式,一定要记住在 agent 的配置文件参数 ServerActive 加上 proxy 的IP地址。
5.zabbix proxy代理企业场景

6.zabbix proxy分布式监控实操
1.环境规划

2.安装部署zabbix proxy
清华源下载zabbix-release包 拖入
[root@git_web01 ~]# ll
-rw-r--r-- 1 root root 13712 Dec 24 10:22 zabbix-release-4.0-1.el7.noarch.rpm
[root@git_web01 ~]# rpm -ivh zabbix-release-4.0-1.el7.noarch.rpm
[root@git_web01 ~]# yum install zabbix-proxy-mysql -y
3.配置zabbix proxy
[root@git_web01 ~]# yum install -y mariadb-server
[root@git_web01 ~]# systemctl start mariadb
[root@git_web01 ~]# systemctl enable mariadb
[root@git_web01 ~]# mysql
#创建数据库
MariaDB [(none)]> create database zabbix_proxy charset utf8;
#创建用户
MariaDB [(none)]> grant all on zabbix_proxy.* to zabbix_proxy@'localhost' identified by '123';
4.导入数据
#查看数据文件
[root@git_web01 ~]# rpm -ql zabbix-proxy-mysql
/usr/share/doc/zabbix-proxy-mysql-3.2.11/schema.sql.gz
#导入数据
[root@git_web01 ~]# zcat /usr/share/doc/zabbix-proxy-mysql-3.2.11/schema.sql.gz |mysql zabbix_proxy
#查看导入后的数据
[root@git_web01 ~]# mysql
MariaDB [(none)]> show databases;
MariaDB [zabbix_proxy]> show tables;
5.修改zabbix proxy 配置文件
[root@git_web01 ~]# vim /etc/zabbix/zabbix_proxy.conf
Server=10.0.0.71
Hostname=sh-proxy 【用你的地域+主机名 好区分】
DBName=zabbix_proxy
DBHost=localhost
DBUser=zabbix_proxy
DBPassword=123
6.启动zabbix proxy
[root@git_web01 ~]# systemctl start zabbix-proxy
[root@git_web01 ~]# systemctl enable zabbix-proxy
[root@git_web01 ~]# netstat -lntup
7.配置zabbix agent
[root@git_web02 ~]# vim /etc/zabbix/zabbix_agentd.conf
Server=172.16.1.7
ServerActive=172.16.1.7
Hostname=172.16.1.8
HostMetadata=git_web02
[root@git_web02 ~]# systemctl restart zabbix-agent.service
8.页面操作



7.报错解决
21444:20191224:112030.023 cannot send list of active checks to "172.16.1.8": host [172.16.1.8] not found
# 1.查看agent配置文件
Server=172.16.1.7
ServerActive=172.16.1.7
Hostname=172.16.1.8
HostMetadata=git_web02
# 2.可能是zabbix-server 和zabbix-proxy-mysql版本不统一
[root@zabbix ~]# zabbix_server -V
zabbix_server (Zabbix) 4.0.16
[root@git_web01 ~]# zabbix_proxy -V
zabbix_proxy (Zabbix) 3.2.11
[root@git_web01 ~]# yum update https://mirrors.tuna.tsinghua.edu.cn/zabbix/zabbix/4.0/rhel/7/x86_64/zabbix-proxy-mysql-4.0.16-1.el7.x86_64.rpm
21939:20191224:112632.897 cannot send list of active checks to "127.0.0.1": host [Zabbix server] not found
出现该错误的原因是一般是zabbix_agentd.conf里面的Hostname和前端zabbix web里面的配置不一样所造成的
第3章 mysql分表
一:为什么要分表?
如果一个表的每条记录的内容很大,那么就需要更多的IO操作,如果字段值比较大,而使用频率相对比较低,可以将大字段移到另一张表中,当查询不查大字段的时候,这样就减少了I/O操作
如果一个表的数据量很少,那么查询就很快;如果表的数据量非常非常大,那么查询就变的比较慢;也就是表的数据量影响这查询的性能。
表中的数据本来就有独立性,例如分别记录各个地区的数据或者不同时期的数据,特别是有些数据常用,而另外一些数据不常用。
大表对DDL操作有一定的影响,如创建索引,添加字段
修改表结构需要长时间锁表,会造成长时间的主从延迟,影响正常的数据操作
当产品运营很多年时数据量就会变的很大,如QQ的用户表,不知道QQ有多少用户,而且一个人可能有多个QQ号,如订单表,比如淘宝的订单数据有多少,都是惊人的数据量。单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
二:分割方式
分表有两种分割方式,一种垂直分割另一种水平分割。
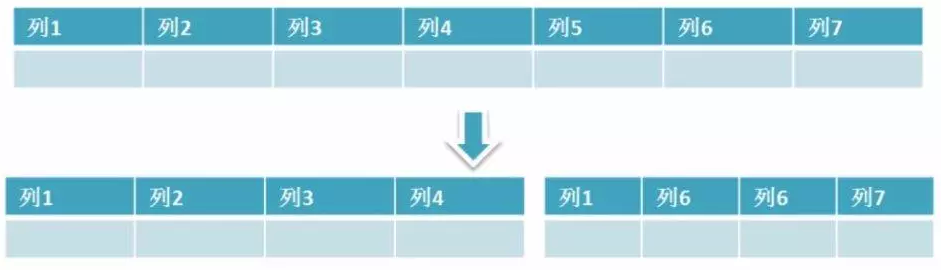
①:垂直分割
简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。 垂直分割一般用于拆分大字段和访问频率低的字段,分离冷热数据。
垂直分割适用于记录不是非常多的,但是字段却很多,这样占用空间比较大,检索时需要执行大量的I/O,严重降低了性能,这个时候需要把大的自读那拆分到另一个表中,并且该表与源表时一对一关系。
垂直分割比较常见:
例如博客系统中的文章表,比如文章tbl_articles(id, titile, summary, content, user_id, create_time),因为文章中的内容content字段可能会比较长,如果放在tbl_articles中会严重影响文章表的查询速度,所以将内容放到tbl_articles_detail(article_id, content),像文章列表只需要查询tbl_articles中的字段即可,如果想要查询文章的具体内容就关联tbl_articles_detail,
像我们经常看到的tbl_order表有对应的tbl_order_detail, 就是减少order字段的数量,将一些使用频率相对较低的放在detail详情表中
垂直拆分的优点:
可以使得行数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂。
②:水平分割
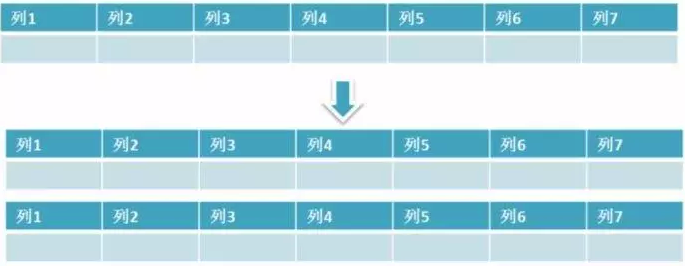
水平拆分是指数据表行的拆分,表的行数超过500万行或者单表容量超过10GB时,查询就会变慢,这时可以把一张的表的数据拆成多张表来存放。水平分表尽可能使每张表的数据量相当,比较均匀。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
水品拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以水平拆分最好分库。
水平拆分能够支持非常大的数据量存储,应用端改造也少,但分片事务难以解决,跨界点Join性能较差,逻辑复杂。
水平拆分会给应用增加复杂度,它通常在查询是需要多个表名,查询所有数据需要union操作。在许多数据库应用中,这种复杂性会超过它带来的优点,因为只要索引关键字不大,则在索引用于查询时,表中增加2-3倍数据量,查询时也就增加读一个索引层的磁盘次数,所以水平拆分要考虑数据量的增长速度,根据实际情况决定是否需要对表进行水平拆分。
例如:电话账单就可以分成多个表:最近3个月的账单数据存在一个表,3个月前的历史账单存放到另一种表,超过一年的历史账单可以存储到单独的存储介质上,这种拆分是最常用的水平拆分方法。
水平分割标准
水平分割最重要的是找到分割的标准,不同的表应根据业务找出不同的标准
用户表可以根据用户的手机号段进行分割如user183、user150、user153、user189等,每个号段就是一张表
用户表也可以根据用户的id进行分割,加入分3张表user0,user1,user2,如果用户的id%3=0就查询user0表,如果用户的id%3=1就查询user1表
对于订单表可以按照订单的时间进行分表
三: 数据库分片方案
客户端代理: 分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。 当当网的 Sharding-JDBC 、阿里的TDDL是两种比较常用的实现。
中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。 我们现在谈的 Mycat、360的Atlas、网易的DDB等等都是这种架构的实现。
四 :中间表查询 大表统计
创建一个中间表,中间表的结构和原始表结构一样,或多字段,将原始表中的部分数据转移到中间表,然后对中间表进行统计。
中间表复制源表部分数据,并且与源表相隔离,在中间表上做统计查询不会对在线应用产生负面影响
中间表上可以灵活的添加索引增加临时用的新字段,从而达到提高统计查询效率和辅助统计查询作用。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号