

OO第一单元总结
前言:
第一单元的三次作业在有惊无险的情况下终于结束了,由于自己是一只编程菜鸡,所以每周日发布指导书之后,就开始构思这次作业的思路。一般在周六上午与室友交流后,确定大致结构,然后周六下午开始动手写代码,从底层要使用的基本的类写起,一般在周日晚上经过一天半的写写改改后,代码就能完成作业要求的基本功能,再用周一的时间检查特殊输入、WF、及复杂功能,并在周一晚上进行提交,并针对中测结果对代码进行进一步的改进。这样下来,三次作业都顺利通过了强测的正确性测试,令我十分振奋。可惜的是,前两次作业都因为优化不全,所以在性能分上略有损失,第三次作业更是因为构建出的数据采用了树的结构,苦思良久也没能找到优化的方法,所以性能分一分未得,实在惭愧。不过虽然没有做到尽善尽美,在这三次作业行进的过程中,我确实感受到自己编写代码的能力有了大大的提高,尤其是第三次作业,更是感觉到触摸到了一些面向对象的思想。现在在这里对前三次的作业做一个总结,来审视自己在这三次作业当中的收获与不足。
一.基于度量来分析自己的程序结构
第一次作业
第一次作业时感觉最困难的地方在于正则表达式的运用(由于之前完全没接触过)与爆栈问题的解决。
程序结构
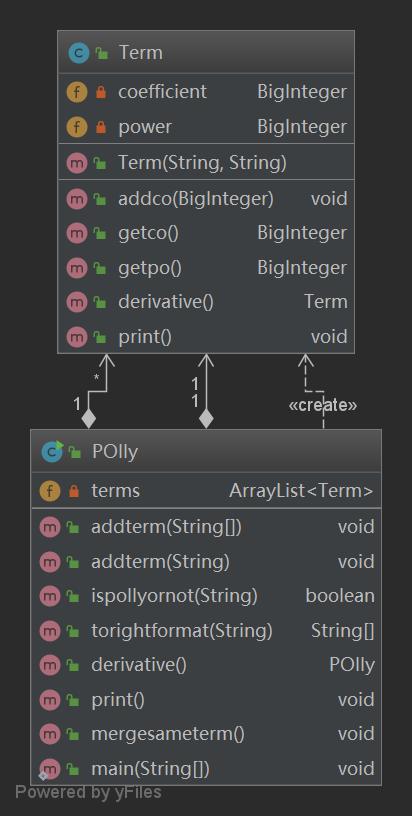
在观看了大佬们的博客后,学会了用IDEA自带的diagram功能制作UML图,画出第一次作业的程序结构如下:
可以看到这次作业只有两个类:
一个是Term类,用于存储、求导、打印单个带系数的幂函数,这个类还是比较面向对象的,第二次作业基本是沿用了这个类。
另一个是POlly类,用于处理字符串的判断,读入,切割,用arraylist存储多个Term,并对存储的Term进行求导、打印、合并,这个类就非常的面向过程了,这是导致我第二次作业不得不重构的原因。
度量分析
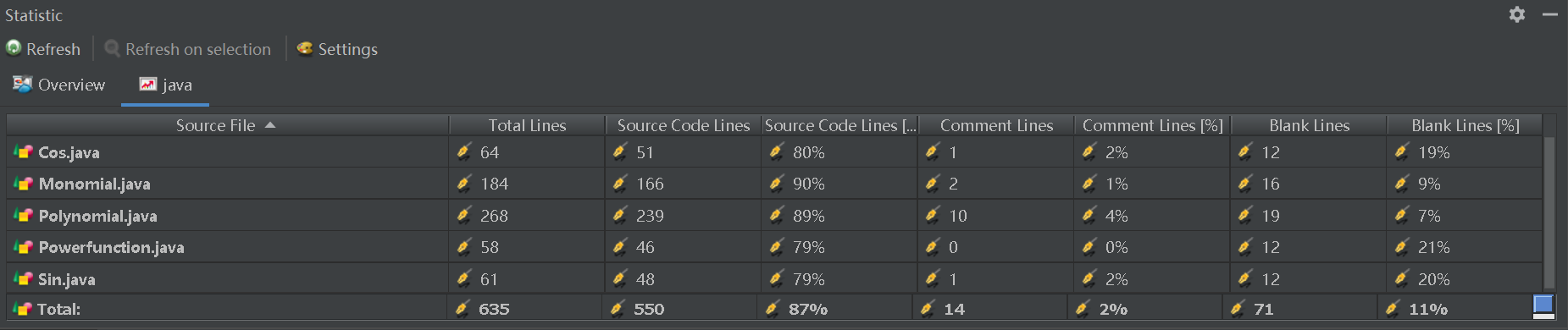
学习大佬的博客后,采用statistic插件和MetricsReloaded插件对代码的复杂度进行了分析:


可以看到:
POlly.ispollyornot的循环复杂度很高:这是由于我在判断切割出来的字符串是否是符合幂函数格式时使用了大量if-else语句,这样做的初衷是想分开判断不同格式,以减轻爆栈压力,但是同时也增加了测试难度。
POlly.addterm的模块设计复杂度和循环复杂度均很高:这是由于我在判断切割出的字符串的系数、指数状况时使用了大量if-else语句,现在想想,这些判断应该由Term的构造方法来做,这样就能降低两个模块之间的耦合度,同时降低方法的循环复杂度。
其他:
另外我们宿舍在这次作业中发现了一种能够解决这次作业正则表达式爆栈问题的方法:
写出能够表达每一项的正则表达式,然后使用String的replaceAll方法,然后判断替换后的函数是不是空串,来达到判断格式的目的,经过实验,能够有效防止爆栈。
第二次作业
第二次作业相对来说感觉是比较简单的一次,主要的精力在三角函数的化简上。
程序结构
使用IDEA自带的diagram功能制作UML图如下:
可以看到这次作业的类更有层次,有一点继承的味道,可惜当时还不会继承,还是按照独立的类写的:
基础的类有Powefunction,Cos,Sin,在在三个类里主要实现了他们对应的求导和打印功能。
中间的类是Monomial,是一个n*x^n*sin(x)^n*cos(x)^n的类,可以用来表示所有形式的项。
最高级的类是Polynomial,用于表示多个项组成的表达式。
其中基础的类写方法时基本都是从头开始写,中间的类的方法是由基础的类的方法堆积出来的,最高级的类的方法又是由中间的类的方法堆积出来的,当时感觉很棒,因为这是以前编程没有的体验。

度量分析
采用statistic插件和MetricsReloaded插件对代码的复杂度进行分析:
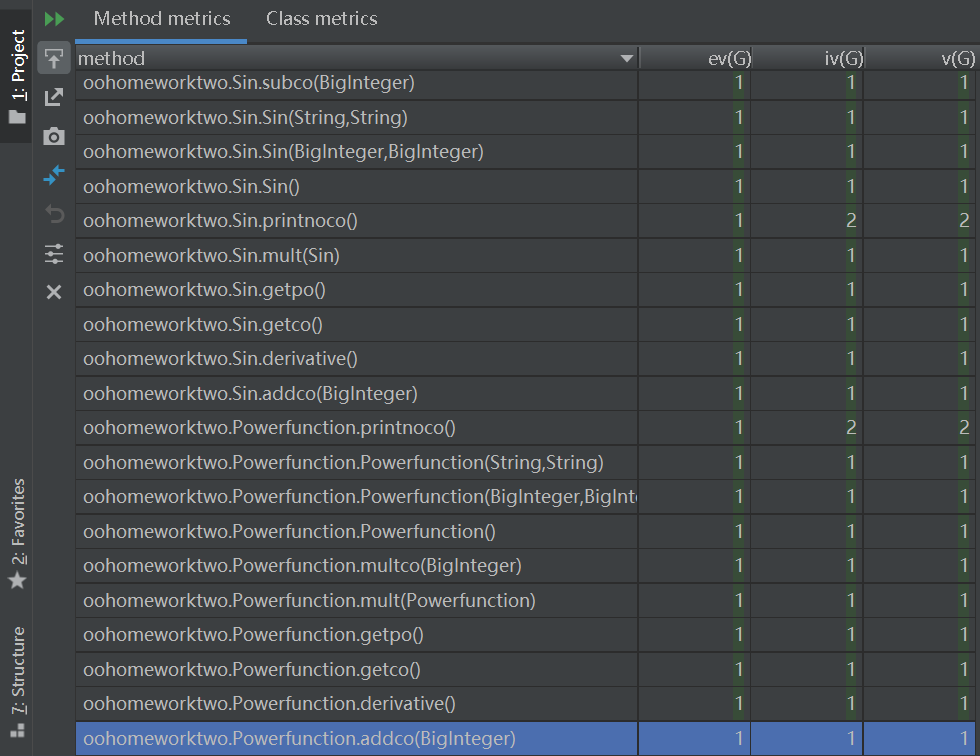
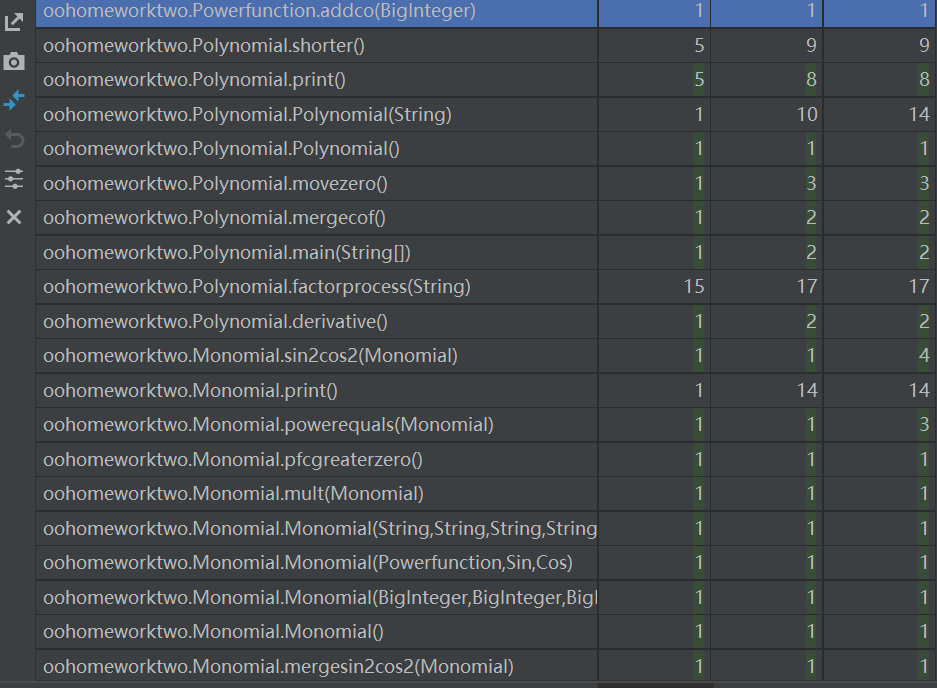
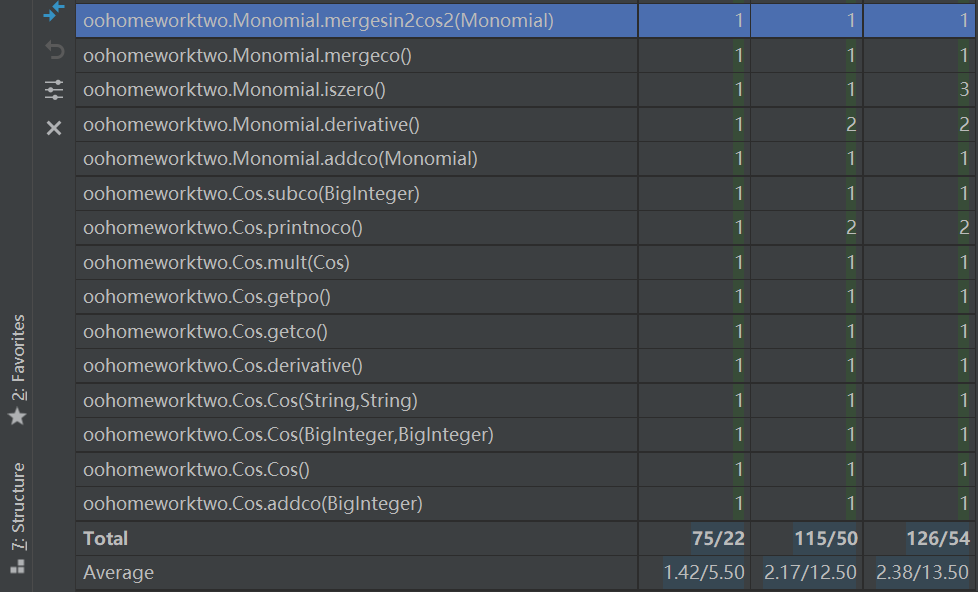
可以看到
Polynomial.Polynomial的模块设计复杂度和循环复杂度均很高:这是由于我把字符串的格式判断放在了里面,这就带来了大量的if-else语句,同时由于对于Monomial的类型判断也放在了这一级,所以大量调用了Monomial中的方法,使得模块耦合度很高,如果重构,这些判断应该放在Monomial中。
Polynomial.factorpreocess的基本复杂度、模块设计复杂度和循环复杂度几乎都要爆表了,这是因为我把对字符串的预处理(多个运算符变一个、切割)等大量操作都写到了这个方法里,从名字也可以看出来这个方法是我当时放在Polynomial的构造函数里放不下了,才单独写的,结果最后这个方法完全面向过程,又臭又长,而且由于后面发现了一些没想到的WF,又往里面硬塞了很多代码,使得这个方法非常难读,不易维护。
现在回想,应该将对于字符串的处理单独写一个handler类,而不是放在Polynomial,这样不仅更合逻辑,而且也能有效降低代码的复杂度,使得便于阅读维护。
其他:
这次作业里运用了第一次作业读别人代码时学到的逐项处理、边处理边判断WF的思想,使字符串的处理更加合理
第三次作业
第三次作业感觉是最难的一次作业,然后也完全没有时间做优化(主要是怕做出bug)。
程序结构
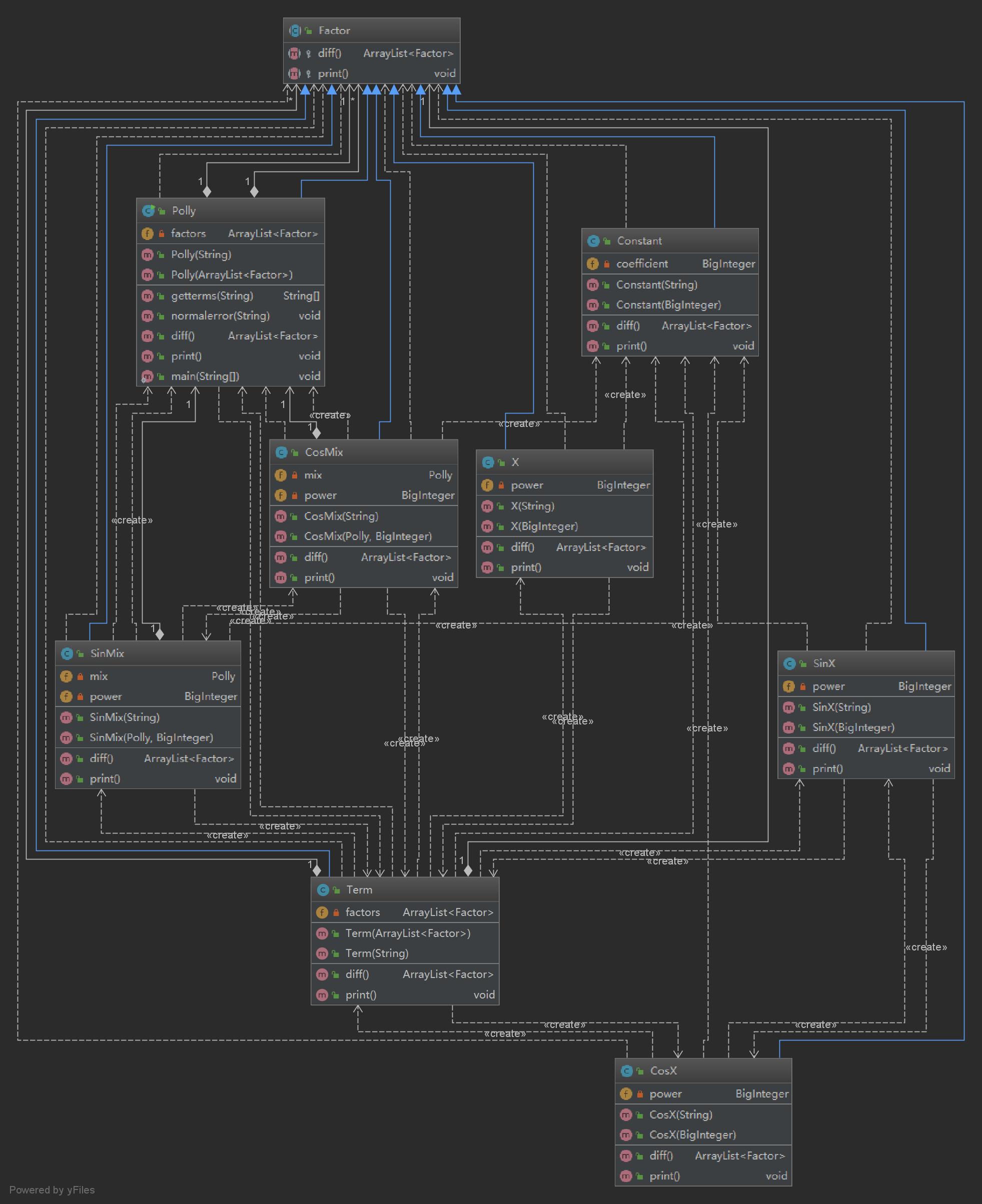
使用IDEA自带的diagram功能制作UML图如下:
这次类的关系有点复杂,总的来说,就是:
Factor类是一个抽象的父类,从基础到高级,它的子类有:
Constant(常数),Sin,Cos,SinMix(复合sin),CosMix(复合cos),Term(项),Polly(表达式)
这些类之间的关系,以及求导之后的结果,严格符合他们的数学关系,从而自然做到了递归调用。
度量分析
采用statistic插件和MetricsReloaded插件对代码的复杂度进行分析:
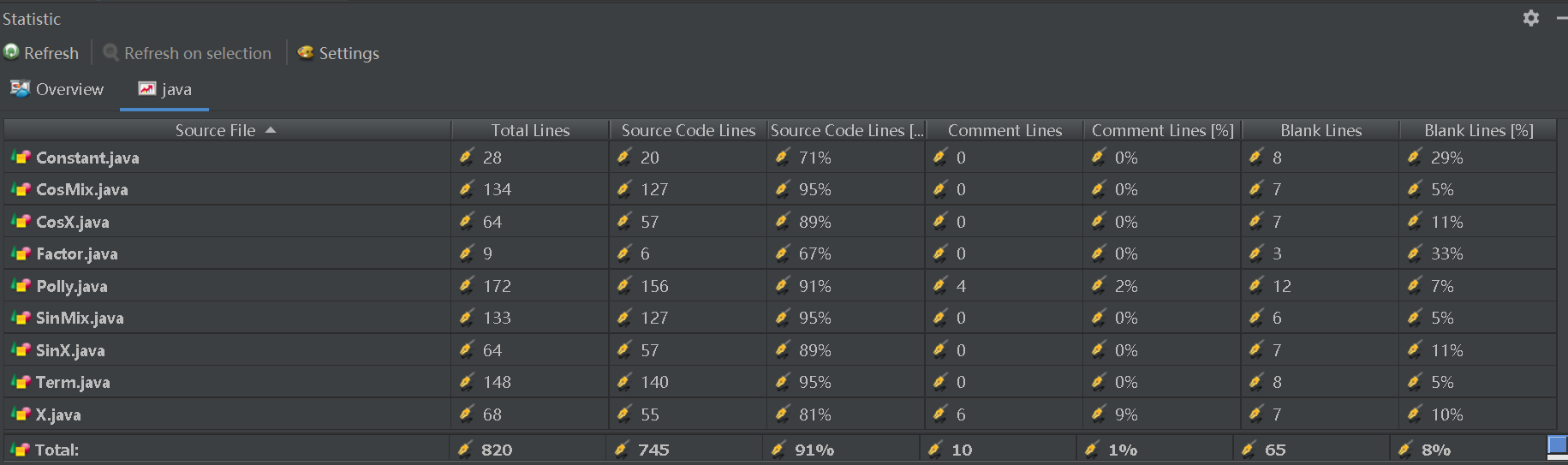
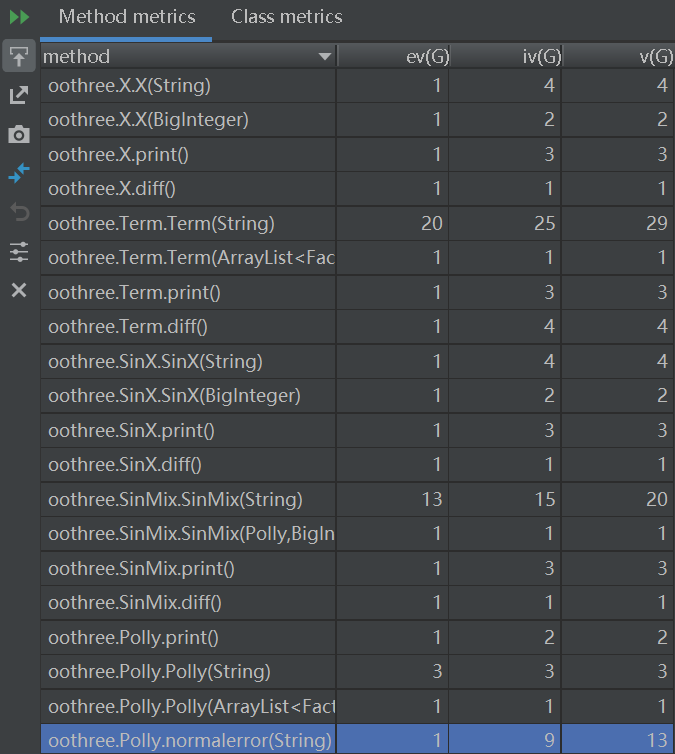

可以看到:
Term,SinMix,CosMix的构造函数基本复杂度、模块设计复杂度和循环复杂度都很高,这是因为设计时为了让更高层次的代码尽量简洁,我将这三项,单项的字符串判断写在了他们对应的构造函数里,以做到边构造边判断,这样看起来虽然代码复杂度不是很好,但是实际上用起来还是比较方便的,只要注意不出错就行了。
其他:
这次的优化是真的难,连思路都没有,听了讨论课才有一点思路。
二.分析自己的BUG
第一次作业
由于第一次对指导书产生了误解,认为是测试数据中空白字符只包括‘\t'与' ',所以导致出现了’\f''\v'的WF的BUG,通过在输入字符串之后设置一个合法字符集进行判断,成功修复了BUG。
第二次作业
由于第二次采用的是边切字符串边判断格式正确性,在切成项的时候,是按‘*’进行split,但是没有考虑到多个‘*’号的情况,所以再次出现WF的BUG,通过增加一个判断多个‘*‘相连的字串存在是不合法的判断成功修复了BUG。
第三次作业
这一次作业没有被测出BUG。
三.找他人代码的策略
第一次作业
1.通过水群大佬的发言找BUG:即不合法空白字符的BUG。
2.阅读他人代码,在草稿纸上画出流程图,寻找逻辑上的BUG,重点查看了有正则表达式的部分,别人的BUG主要错在正则表达式未包含所有特殊情况。
第二次作业
1.阅读他人代码,在草稿纸上画出流程图,寻找逻辑上的BUG,重点查看了有正则表达式的部分,但是这次未能找出BUG。
2.构造一些特殊数据,来测试他人代码的完备性,但是也没能找出BUG。
第三次作业
1.通过对拍器,暴力拍出了他人的BUG
四.Applying Creational Pattern
由于第二次作业是第一次作业的重构,第三次作业是第二次作业的重构,所以这里重点讨论第三次作业的重构思路:
由于在上文中知道,代码复杂度的问题,主要是由于将字符串的处理写在了函数类的方法中,所以首先可以考虑单独写一个类为InputHandler来进行字符串处理,降低代码之间的耦合。
同理可以考虑将字符串的打印也与函数类分开来,单独写一个OutputHandler来进行结果的打印。
除此之外还需要考虑的是一个化简得问题,可以考虑增加一个类,将输出的结果的字符串进行化简,即先计算出一个结果,输出到化简的类中,重新构造一个表达式的树,再进行化简,这样可以把一些简单的化简,比如多余括号,带因数为0的项,通过字符串处理的方式简单化简掉。
五.结语
在这三次作业中,通过自己写代码,读他人的代码,修复自己的BUG和听大佬们讲讨论课学到了很多新的方法,思路,收获颇多,希望在之后的OO作业历程中也能坚持下去,越做越好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号