System Software for Persistent Memory 阅读笔记
零、名词解释
-
page cache:简单来说就是使用 DRAM 未使用的部分缓存一些 storage 中的块。因为这个思想与 CPU cache 很类似,所以叫做 page cache,目的是减少 CPU 访问外部设备的延迟,并没有使用 SRAM。
-
memory-mapped I/O:简单来说就是把 storage 上的文件映射到内存中,就可以使用普通的访存操作访问外部设备。相关链接
-
fine-grained logging:细粒度日志,对应的是 Coarse-grained,即粗粒度日志。
-
hardware primitive:硬件原语。
-
POSIX:
POSIX 标准针对API而不针对系统调用。判断一个系统是否是 POSIX 兼容要看它是否提供了一组合适的应用程序接口,而不关心它的函数是如何实现的。换言之,一个非 Unix 系统也可能是 POSIX 兼容的,只要它在用户态库函数中提供传统的 Unix 能提供的所有服务。——《深入理解Linux内核·第三版》
- API(应用编程接口)与系统调用:
前者只是一个函数定义,说明如何获得一个给定的服务,而后者是通过软中断向内核态发出一个明确的请求。——《深入理解Linux内核·第三版》
其实API与系统调用之间并不存在必然的联系。有些API直接提供用户态的服务,无需使用系统调用进入内核;有些API会使用许多的封装例程完成特定功能,通常来说一个系统调用对应一个封装例程。
举例来说,malloc是一个 POSIX API,它使用 brk() 系统调用来扩大或者缩小进程的堆。对于应用层编程人员来说,API与系统调用的区别是透明的,它们之间的区别对内核设计人员来说比较重要,因为系统调用属于内核,API(用户态的库函数)不必全部进入内核。
-
ACID:什么是 ACID?
-
TLB shootdown:简言之,就是一个 CPU 导致其他 CPU TLB 的刷新。什么是TLB shootdown?
一、 Abstract AND Introduction
这篇文章实现了一个持久内存(persistent memory,PM)使用的 POSIX 文件系统 PMFS,利用了 PM 的字节可寻址性,通过 memory-mapped IO 使得应用程序可以直接访问 PM,减少了块设备的额外开销。
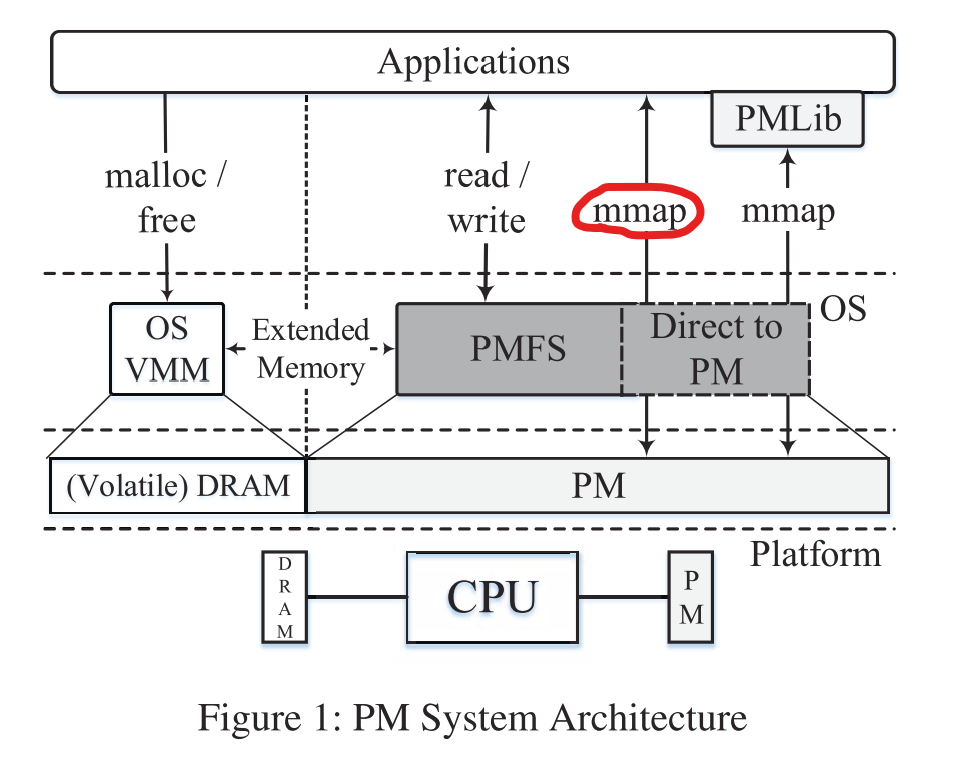
PMFS的优势有以下三点:
- 支持传统的应用软件:因为 PMFS 实现了完整的 POSIX 文件系统接口;
- 轻量级的文件系统:PMFS实现中去除了 block layer;同时,PMFS 利用 PM 的字节寻址性使用原子原地更新(atomic in-place updates),细粒度日志(logging at cache-line granularity)以及写时更新(Copy on write)策略的组合优化了数据一致性;
- 优化的 mmap I/O:传统的文件系统实现中,使用 memory-mapped I/O 需要将 storage 中的页先拷贝到 DRAM 中,PMFS 优化了 mmap IO,使得 PM 内存页直接映射到用户态应用的地址空间。PMFS 还是用了透明大页支持(transparent large page support)来进一步优化 mmap。
PMFS 以 write-back 的方式访问 PM,但是需要一个机制来限制访问的顺序性和数据的持久性。PMFS 提出了一个硬件原语 pm_wbarrier,保证了在数据换出 cache 时数据的持久性。个人感觉,这里持久性带来的额外开销实际上是为了保证数据一致性。
由于软件可以像访问普通内存一样访问 PM,这时一些 stray writes (一般由程序 bug 导致)很可能会修改 PM 中的值并使其持久化,而在传统的文件系统中,PM 连接在外存总线上,对内存的 stray writes 并不会影响外存中数据的持久性。一个简单解决办法是对全部的 PM mapped pages 置只读位,只有在需要更新特定的 pages 时才置可写,写完后重新置为只读。然而这样会带来 TLB shootdowns,所以 PMFS 使用 writes window 来解决这个问题。
另一个问题是验证并确保数据一致性,PMFS 面临的一致性问题更加复杂,因为不仅要考虑处理器的访存顺序,同时还要考虑使用 pm_wbarrier 原语保证持久性所带来的问题。
二、系统架构
为了保证数据一致性,文中提到主要是通过管理访存的顺序和数据的持久化来保证统一性,而一些典型的方法是:
- PM 设备采用写直达策略(write-through),局限性是大量的额外开销和有限的写带宽(~100MB)。
- 使用 non-temporal store 指令,绕过 CPU cache,由于部分 cacheline 的写入所带来的性能问题,并不能广泛应用;non-temporal store
- 一个新的基于 epoch 有序性的 cache 架构,局限性是这需要大量的硬件修改,这些修改往往是在微体系结构上的重大修改。
而单独使用 write-back 的方式并不能满足持久性的需要。因此 PMFS 实现了一个硬件原语(pm_wbarrier)保证从 CPU cache 中 flush 出来的数据的持久性。文中提到 pm_wbarrier 有同步异步两种实现形式,文中采用同步形式。下图简单介绍了一个保证持久性的写集合的工作流程:

同时,因为 cache write-back 的性能对 PM 架构而言十分重要,而目前的 clflush 的强有序性(由 memory fence 如 sfence 等保证)带来了较为严重的性能问题,所以 PMFS 对 clflush 进行了优化。
文中指出,一个主要缺点是软件需要在 PM 中追踪脏 cacheline,同时性能的提升带来了额外的编码复杂性。PMFS 使用了 pm_wbarrier,并且在大部分的软件使用中(比如保证一致性和日志相关的操作)采用上图所述的流程(clflush -> sfence -> pm_wbarrier),并且在一些特定的流写入操作(例如写系统调用)时使用 non-temporal 存储指令。另外,本文假设磨损均衡(wear-leveling)由 PM controller 保证,由软件保证磨损均衡较为复杂。
三、PMFS 的设计与实现
PMFS 的设计目标是:
- 访问接口优化,充分利用 PM 的字节可寻址性。PMFS 在数据布局(data layout)和一致性设计方面进行了优化;
- 设计应用友好的访问。PMFS 尽可能减少复制和软件开销来优化文件 IO 和 mmap,PMFS 中文件 IO 只需要 PM 与用户缓冲区之间的单个副本,而 mmap 避免了完全复制;
- 保护 PMFS 避免 stray writes。PMFS 利用处理器中的写保护控制功能实现了一个原型低开销的写保护机制;
PMFS 的数据布局
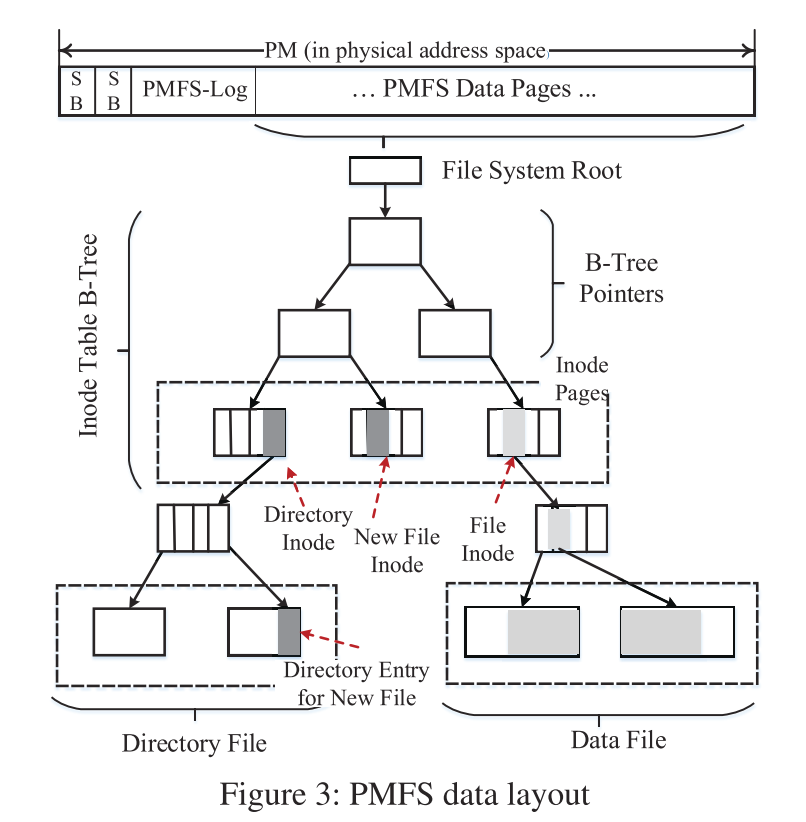
Allocator
PMFS 的分配单位是页,支持全部处理器支持的页大小(4KB,2MB,1GB),默认情况下,为元数据 inode 分配 4KB 的页,为数据页分配的页大小并不限制。因此,内外部碎片问题也变得十分严重,在当前的实现中,PMFS 分配器仅合并相邻的页面,避免较大碎片出现。
Memory-mapped IO(mmap)
mmap 将 PM 的物理内存映射到应用的虚拟地址空间上,在页大小选择上自然出现了使用大页还是小页。如果使用大页,那么页表就会更小,因此会带来更少的页缺失,更快的页查找。然而使用大页会引入大量的内部碎片,降低 PM 性能。所以在 PMFS 中实现了一个页大小的折中策略,当文件不是 copy-on-write 时,例如只读或者 mmap 标记为 MAP_SHARED 的,此时使用大页,因为假如一个很小的支持 COW 的文件,在多个调用者修改文件时,大页会带来大量的内部碎片;其他情况使用 4KB 小页。
Consistency
现代的文件系统大多使用以下其中一种策略保证一致性:
- 写时复制(COW);
- 日志(journaling or logging);
- 日志结构更新(log-structured updates)。
COW 和日志结构文件系统都会带来写放大(write amplification)问题,特别是对于元数据的小更新会带来大量的写操作。而日志(journaling)会以一个更合理的粒度更新元数据。文中分析了对于元数据更新使用这三种策略的开销(写字节数,pm_wbarrier数等),根据结果得到,在64字节或者 cacheline 粒度上进行 logging(文中叫做 fine-grained logging)的额外开销是最小的。但是 journaling 也有一定的局限性,就是所有的更新都会写两遍,一遍写日志,一遍写文件系统。当更新的大小大于COW文件系统的块大小或者日志结构文件系统的段大小时,double write 带来的额外开销和写放大开销会严重影响 logging 文件系统的表现。
因此在 PMFS 中,使用了原子的原地更新(atomic in-place updates)和 fine-grained logging 策略处理元数据的更新,而使用 COW 策略处理文件数据更新。在保持元数据一致性上,使用了比 BPFS 更低的额外开销。
Undo vs Redo
journaling 分为以下两种形式:Undo 和 Redo。
在 Redo 中,在数据写入文件系统前先被记录(logged)并使之持久化,只有当事务成功提交时,文件系统中的数据才被修改。
在 Undo 中,在数据写入文件系统前,先在日志中记录旧数据,之后将数据直接原地写入文件系统中,如果这时出现意外情况,就使用 Undo log 中的旧数据还原数据,抵消之前的修改。
Redo 和 Undo 各有利弊,Undo 使用大量的 pm_wbarrier 原语,每个 log entry 都需要一个,而 Redo 只需要两个 pm_wbarrier 原语(一个保证日志中的所有数据持久性,一个保证向文件系统中写入的数据持久性),与 log entry 的数量无关,额外开销更小。另外,Undo 的实现比 Redo 更简单,因为 Redo 中最新的文件数据在 log 中,因此,所有的读操作都要现在 log 中读来找到最新的数据,带来了额外的开销,而且 log 的粒度越小,搜索的开销越大。然而当事务创建了大量的数据但是只修改了少量的数据时,Redo 的表现理论上比 Undo 要好。
PMFS 中使用 Undo。对于那些无法原子就地更新的数据,PMFS 选择使用细粒度日志策略(fine-grained logging)。
总的来说,PMFS 使用原子原地更新、细粒度日志(更新元数据)以及 COW (更新文件数据)的组合策略保证数据一致性。
Atomic in-place updates
对于16字节,64字节的更新,PMFS 利用了额外的处理器特性保证原子性,从而避免使用日志。
- 8字节的原子更新:处理器原生支持,PMFS 在文件写的时候使用8字节更新 inode 的访问时间。
- 16字节的原子更新:处理器使用 cmpxchg16b 指令支持16字节的原子写,PMFS 使用16字节原地更新 inode 的大小,记录文件修改时间。
- 64字节(cacheline)的原子更新:处理器需要 RTM(Restricted Transactional Memory)的支持。PMFS 在改变 inode 中大量数据域的系统调用中(例如删除一个 inode)使用 cacheline 原子更新。
Journaling for Metadata Consistency

PMFS-Log由一段固定大小的循环缓冲区组成。每个 PMFS-Log Entry 记录了一个对 PMFS metadata 的修改。
每次原子文件操作需要 logging 时,PMFS 会创建一个新的编号为 trans_id 的事务。每次绕回日志后和每次 PMFS 恢复之后,PMFS-Log 的 gen-id 字段都会增加,从而自动使所有过时的日志条目无效。
为了能够分辨 log-entry 是否有效,必须采用以下两种策略其中之一:一是 PMFS 原子性的向 PMFS Log 中写入 Entry,二是 recovery code 必须能够检测出部分写的 entry,个人认为,都是为了保证 entry 对 metadata 修改的原子性。为了保证原子性,可以使用两个 pm_wbarrier 硬件原语,一个保证 entry 写入的原子性,一个保证置有效位的原子性;也可以使用检验和或者 tornbit RAWL,可以把 log-data 转换成多个词,之后每个词都有一个有效位。但是这些方法都会引入大量的额外开销。
在 PMFS 中,增大了 logging-data 的粒度到一个 cacheline 的大小(64byte),而且使用 log-entry 中的 gen_id 字段作为有效位,实际应用思想是在写 log-entry 的最后、log-entry 持久化(个人感觉是在 pm_wbarrier 之前)之前写 gen_id。为了达到这个目的,文中指定编译器不对写 log-entry 的操作进行重排序。
在一个原子操作开始时,PMFS 为该操作尽可能多地分配 log-entry,一旦该操作将要修改 metadata,那么在 PMFS-Log 中分配一个或多个 log-entry 保存旧数据并使之持久化(pm_wbarrier),重复分配 log-entry,直到没有元数据需要被修改,随后提交该事务,刷新所有的脏 cacheline,使用一个 pm_wbarrier 使之持久化。最后,在事务中添加一个 commit log-entry,确保事务数据持久化。
commit log-entry 的 pm_wbarrier 可以被优化,一些子进程中比如其他事务或者 log-cleaner 进程中的 pm_wbarrier 就可以保证事务数据持久化了。log-cleaner thread 通过首先发出单个 pm_wbarrier 来使 commit log-entry 具有持久性,然后自动更新 PMFS-Log 中的头指针,来定期释放与已提交事务对应的 log-entry。
PMFS recovery
当 PMFS 被异常卸载时(掉电、系统崩溃等),下次挂载时会执行 PMFS recovery,检查 PMFS-Log entry 是否有效(gen_id),丢弃那些已经 commit 的事务,恢复那些还没被 commit 的事务。
Consistency of Allocator
因为大量的 free/alloc 操作,所以使用日志维护 Allocator 的一致性会因为大量的 logging 和 ordering 带来大量的额外开销。所以 PMFS 在易失性内存上维护 Allocator 的数据结构,PMFS 将 Allocator 结构保存在干净卸载的保留(内部)inode中。如果发生故障,PMFS 将通过在恢复过程中遍历文件系统B树来重建 Allocator 结构。
PMFS Data Consistency
PMFS 使用 CoW 保证文件数据的一致性(使用 write 系统调用),对于那些不能原地原子更新的 metadata,使用细粒度日志进行更新。文中给出的实现方法中,只保证文件数据在 metadata 之前被持久化。
一个使用 CoW 的问题是 CoW 使用大页,例如 1GB 的大页,这时会带来严重的写放大问题,因为即使只改变很小的数据量也需要复制巨大的数据页。在 PMFS 的实现中,只在文件无需被写修改,例如只读或者被 mmap 标记为 MAP_SHARED 时才使用大页。
一句话总结
PMFS 使用原子原地更新和细粒度日志更新元数据,使用 CoW 更新文件数据,保证数据的一致性和持久性。
Write Protection
这一节主要介绍如何防止 stray writes。

上图主要介绍了出现 stray writes 时的处理办法,列(行名)表示出现 stray writes 的 mapped 地址空间属于用户还是内核,行(列名)表示是在用户态还是内核态出现的 stray writes。如果在用户态出现对用户地址空间或者内核地址空间的误写,此时通过地址空间的划分(基址+偏移寄存器或者分页机制)和特权级的分隔可以分别实现对内存进行保护;如果在内核态出现对用户空间的误写,此时通过处理器的 Supervisor Mode Access Prevention 特性实现保护,这些都是目前已经存在的手段。
但是,在内核态保护对内核的误写困难得多,特别是如果允许多个共享相同内核地址空间的 OS 组件写入 PM。由于 PMFS 是唯一管理 PM 的系统软件,因此解空间要简单得多。
一种“内核到内核”写保护的解决方案是根本不将 PM 映射到内核虚拟地址空间,而仅使用专用于物理内核的临时映射(类似于 Linux 32bit-x86平台的 kmap)。但是问题在于这样会增加 PMFS 的复杂性,同时丧失了直接通过虚拟地址操作 PM 的优势。
PMFS 中的解决方案是比较激进的,在挂载时将全部的 PM 标记为只读,只把那些涉及对 PM 写的代码段升级为 writeable,这种方式文中称为 write windows。PMFS 中通过设置页表的写权限实现 write windows,然而这样会导致昂贵的 TLB shootdown,因此 PMFS 利用了 x86 处理器的 CR0.WP 来进行写保护,只有当 CR0.WP 设置为0时,才允许向只读的页中写,最大的优点在于无需修改页表,避免了 TLB shootdown 开销,下图展示了 CR0.WP 的使用方法:

需要注意的一点是,CR0.WP 在响应中断或者上下文切换时是不会被保存的,个人理解是不会被保存现场,所以如果在写过程中出现了中断,那么在处理完中断回来时,可能 CR0.WP 的值是不正确的,因此,在修改 PM 页时,如上图所示会屏蔽中断,对 PM 页完成修改后立即使能中断。为了防止中断被长时间屏蔽,文中做出了一定程度的折中,PMFS 在细粒度日志中限制每个 write window 中的写入完成数到几个 cacheline,在写系统调用(write())中限制到一个可调整大小(默认为 4KB)。
另外对于那些有更细致的保护机制的处理器,PMFS 也可以较好地兼容。例如在 Itanium 中,修改 protection key register 无需修改 TLB,与使用 CR0.WP 有相似的效果,同时以页为粒度控制访问而不必屏蔽中断。
Implementation
PMFS 使用并扩展了 Linux 内核中的 eXecute In Place(XIP)接口。XIP 提供一系列的 VFS 回调例程来避免 page cache 以及块设备层的使用。在 PMFS 中的 read, write, mmap 等回调例程是在 xip_file_read, xip_file_write, xip_file_mmap 等基础上仿写的。PMFS 还实现了一个 get_xip_mem 回调例程,该例程被 XIP 使用来将虚拟地址转换为 PM 中的物理地址。
PMFS 还实现了一个 page fault handler。该处理程序由操作系统虚拟内存子系统调用,在 xip_file_fault的基础上实现,并扩展完成了对透明的大页面映射的支持。
在挂载期间,PMFS 把 PM 看做支持 write back,并且只读的内存。PMFS 实现了一个新的 ioremap_hpage 接口,在把 PM 映射到内核虚拟空间时自动的使用大页,这会减少 PMFS 的挂载用时和由于页表带来的内存消耗。
POSIX System Calls
Creating a file
在 PMFS 中创建文件需要以下几个直接关于 metadata 的操作:
- 初始化一个分配的 inode;
- 在目录 inode 中新建一个 entry,把这个 entry 指向这个给新文件分配的 inode;
- 更新目录 inode 的修改时间。
在 create 系统调用中,PMFS 新创建一个事务,并且在 PMFS-Log 中为需要的日志条目(5个)分配空间。首先,PMFS 在空闲列表中检索到一个 inode,记录这个 inode(2个entry),并把这个 inode 标记为已分配;接下来 PMFS 检索目录 inode 的叶子结点寻找一个新的目录条目,一旦找到,PMFS 记录这个目录条目(1个entry)并且将其指向这个新文件的 inode。最后,PMFS 记录并且更新目录 inode 的修改时间(1个entry)以及写提交记录信息(1个entry)来完成这个事务。
Writing to a file
PMFS 先计算完成写系统调用需要的页数。如果不需要新的分配,并且仅需要追加写入,PMFS 使用16字节的原子写入更新 inode 大小和修改时间。
如果需要新的分配,PMFS 新建一个事务。在这个事务中,PMFS 首先为 PMFS-Log 分配空闲空间,之后使用 non-temporal 指令向 PM 写入数据;最后 PMFS 记录并更新 inode 的B树指针和修改时间,在写提交记录之前完成事务。
Deleting an inode
仅当没有目录条目引用该文件索引节点时,才可以将其删除。当删除一个索引节点的所有目录条目时(例如,使用 rm),该索引节点将被标记为删除。释放索引节点的所有句柄后,VFS 会向 PMFS 发出回调以删除索引节点。
参考资料
持久内存的系统软件(System Software for Persistent Memory,Eurosys‘14)
深入理解 Linux 内核·第三版
memory-mapped IO vs port-mapped IO
mmap 函数详解
处理器的特权模式下的访问限制
linux 中的 kmap
Linux 的 VFS 详解
XIP 技术

 浙公网安备 33010602011771号
浙公网安备 33010602011771号