离线强化学习基础知识
1.Offline RL概述
1.1 什么是Offline RL
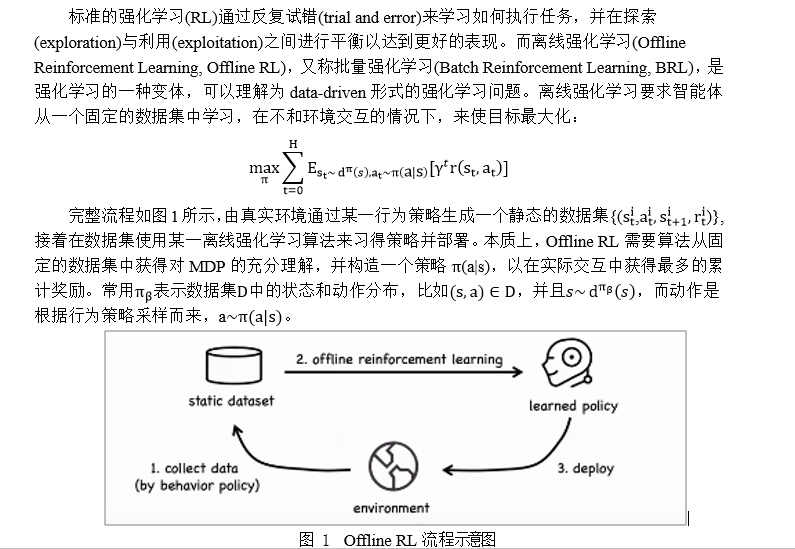
1.2. On-policy, Off-policy, and Offline RL对比
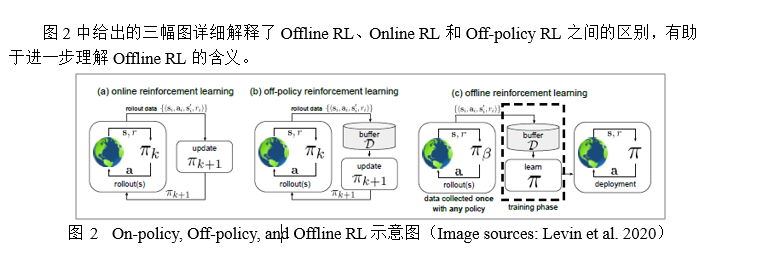
1.3. Imitation Learning and Offline RL对比

1.4. 为什么Offline RL成为了研究热点

1.5. Offline RL中的困难

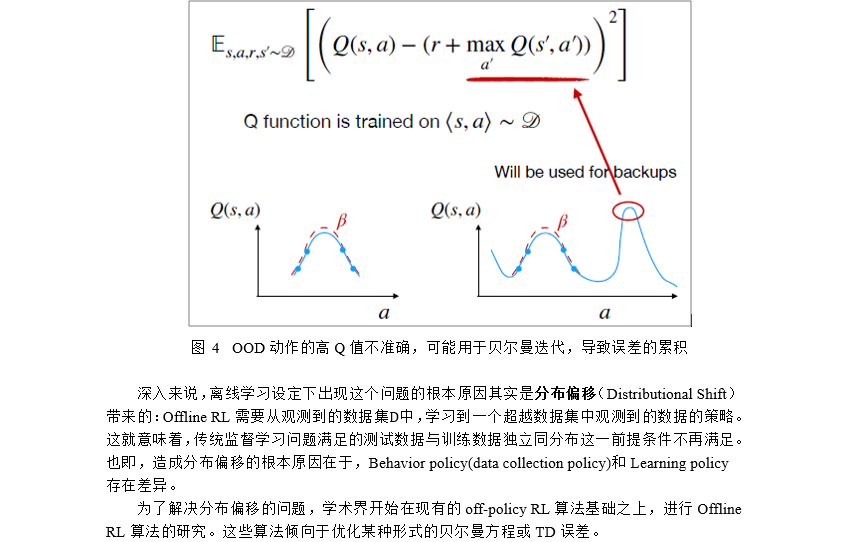
2.Offline RL算法分类
遵循Aviral Kumar与Sergey Levine在NeurIPS 2020 Tutorial中的分类方式,我们将现有的Offline RL算法分为四大类:
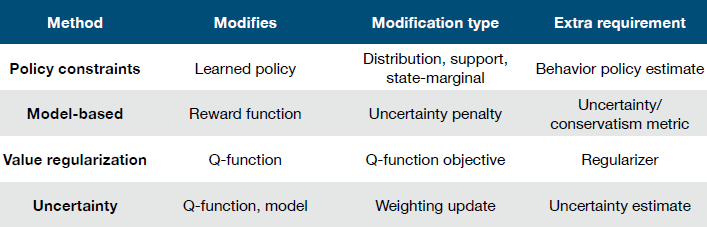
1、 策略约束(Policy constraint)
2、 值函数正则(Value-regularized)
3、 Model-based
4、 Uncertainty-based
下图列举了不同方法下对应修改的部分、修改类型以及额外要求:
2.1 策略约束


2.2 Model-based方法

2.3 值函数正则

2.4 不确定性估计

2.5 小结
策略约束方法,需要某种形式的对于行为策略的评估,方法通常较为保守;
Model-based方法,好处是当数据集覆盖的范围比较大时,可以利用到模型学出来的泛化,从而能够对一些不在数据集中的状态进行训练。因此方法在数据集覆盖的范围比较大时表现比较好;
值函数正则化方法,由于值函数正则对行为策略没有限制,因此相比策略约束不那么保守;
不确定性估计方法,其在高覆盖率的数据集中可以很好地工作,但仍然落后于策略约束等其他方法。
综上,近期针对离线强化学习方面问题的解决方案旨在减小分布偏移,或是通过限制策略与数据的偏差,或是通过估计(认知)不确定性作为分布偏移的衡量标准。
3.Offline RL领域关键发展
下图为离线强化学习领域关键发展的时间轴。
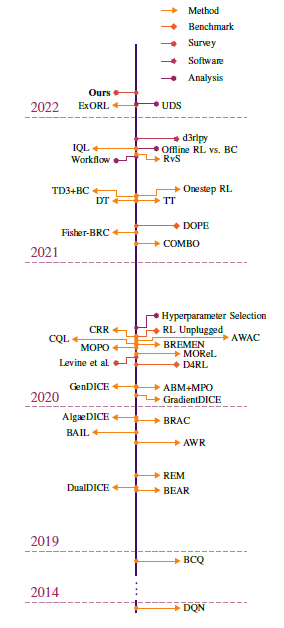
3.1 策略约束
1、 BCQ
是最早的离线强化学习算法,它使用显式策略约束方法。
2、 BEAR
它首次区分了策略约束中的distribution matching and support matching, 它采用support matching的策略约束方法。
3、 AWR
使用隐式策略约束方法,核心思想是:将策略优化过程看成是极大似然估计问题,在策略提升过程中,用优势函数进行权重似然估计。
4、 BRAC
通过给值函数增加惩罚(用策略之间的差异计算)来策略改进或策略评估,它提出度量方法选择不重要,超参数选择比较重要。
5、 AWAC
使用隐式策略约束方法,用Q函数估计优势以减小方差,提高样本效率。
6、 Fisher-BRC
使用显式策略约束方法,用fisher散度。
7、 TD3+BC
使用隐式策略约束方法,为了简化复杂的算法而提出的,方法简单、无任何复杂数学公式、可实现性强(开源)、对比实验非常充分的算法。
3.2 Model-based方法
1、 MOReL
基于动力模型度量模型的认知不确定性。
2、 MOPO
使用模型集成中的最大预测不确定性。
3、 BREMEN
4、 COMBO
值函数正则结合Model-based,可以简单理解为CQL用在Model-based的设定上。
3.3 值函数正则
1、 AlgaeDICE
在贝尔曼误差目标中引入一个正则项,将从所学策略中采样的动作的Q值推低,以避免高估OOD动作中的值。
2、 CQL
向目标函数添加值正则化项来学习真实Q函数的下界。
提出在offline-rl中Q learning过程中加入正则项来缓解over-estimate的问题。通过正则项可以学习到真实Q的lower bound,这样扩大估计值和真实值Q的距离,缓解offline RL中存在的distribution shift问题。
3、 COMBO(值函数正则+Model-based)
可以简单理解为CQL用在Model-based的设定上。
3.4. 不确定性估计
1、 REM
对Q函数的随机凸组合进行抽样,并使用它们来估计给定状态-动作组的Q值。
4. Offline RL数据集
离线强化学习领域最主要的benchmark是D4RL数据集,同时DeepMind公开的RL Unplugged也是一个可选方案。
4.1. Why D4RL?
1、 D4RL 收集了大型数据集,包括交互式环境中智能体的记录(即自动驾驶Carla、AntMaze、Mujoco、kitchen等),种类非常丰富,数据质量非常高,数据的采集综合了6类因素:
(1) Narrow and biased data distributions
(2) Undirected and multitask data
(3) Sparse rewards
(4) Suboptimal data.
(5) Non-representable behavior policies, non-Markovian behavior policies,and partial observability.
(6) Realistic domains
2、 D4RL提供了非常简单的API接口,方便于学习者直接去获取数据集完成智能体的训练。
3、 D4RL定义了标准的衡量指标
4、 D4RL提供了丰富的baseline基准,包括了常见的Offline算法,包括BCQ、BEAR、BRAC等等


 浙公网安备 33010602011771号
浙公网安备 33010602011771号