


tensorflow 中repeat、shuffle、batch的顺序关系
1、repeat表示将数据集一个epoch一个epoch的拼接起来
2、shuffle表示将buffer_size内的数据打乱
3、batch将一个buffer_size内的数据集组成一个整体
下面先简单看下例子:
ds = tf.data.Dataset.from_tensor_slices(tf.constant([j for j in range(10)])) ds = ds.repeat() # 将数据按照epoch拼接 iterator = ds.make_initializable_iterator() sess = tf.InteractiveSession() sess.run(iterator.initializer) for j in range(20): print(sess.run(iterator.get_next())) # 下面是2个epoch的拼接 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
#shuffle 是将buffer_size内的数据打乱 # 先repeat后shuffle将导致有的数据出现两次的时候,其它数据还未出现 ds = tf.data.Dataset.from_tensor_slices(tf.constant([j for j in range(10)])) ds = ds.repeat() ds = ds.shuffle(buffer_size=10) iterator = ds.make_initializable_iterator() sess.run(iterator.initializer) for j in range(20): print(sess.run(iterator.get_next())) 2 3 2 #注意这里出现了第二个2 4 5 8 1 6 1 5 0 1 0 6 7 1 8 0 4 7 # 先shuffle后repeat能保证先在一个epoch选buffer_size个数据打乱,等一个epoch数据选完了,再打乱下一个epoch ds = tf.data.Dataset.from_tensor_slices(tf.constant([j for j in range(10)])) ds = ds.shuffle(buffer_size=10) ds = ds.repeat() iterator = ds.make_initializable_iterator() sess.run(iterator.initializer) for j in range(20): print(sess.run(iterator.get_next())) 5 8 2 0 7 1 4 3 9 6 # 在这之前没有出现相同的数据,因为在这之前是一个epoch 0 9 1 7 2 5 6 3 8 4
# batch与repeat的关系 #记住repeat是将epoch数据重复 #先repeat后batch使的不管数据集到底有多少数据,每一个batch的数据量是相同的 ds = tf.data.Dataset.from_tensor_slices(tf.constant([j for j in range(10)])) ds = ds.repeat() ds = ds.batch(6) iterator = ds.make_initializable_iterator() sess.run(iterator.initializer) for j in range(20): print(sess.run(iterator.get_next())) [0 1 2 3 4 5] [6 7 8 9 0 1] #每一个batch的数据量都是相同的,尽管一个epoch被取完了 [2 3 4 5 6 7] [8 9 0 1 2 3] [4 5 6 7 8 9] #先batch后repeat保证每次将一个epoch内的数据组成batch,不足一个batch_size的也不管 ds = tf.data.Dataset.from_tensor_slices(tf.constant([j for j in range(10)])) ds = ds.batch(6) ds = ds.repeat() iterator = ds.make_initializable_iterator() sess.run(iterator.initializer) for j in range(20): print(sess.run(iterator.get_next())) [0 1 2 3 4 5] [6 7 8 9] #不足一个batch的数据就留空 [0 1 2 3 4 5] [6 7 8 9] [0 1 2 3 4 5]
综上,在使用tf.data加载数据时,应该使用.shuffle() -> .repeat() -> .batch() -> .prefetch()的顺序
Tensorflow 图片IO的方式汇总:
这里不采用matplotlib工具包,因为在使用plt.imsave()时,存储的图片是32位的,这令我感到奇怪,没有找到原因,现在先不考虑plt的文件IO方式
import tensorflow as tf import matplotlib.pyplot as plt # 读取文件 # 方法(1) imageRawData = tf.gfile.GFile('./dog.jpg','rb').read() # 方法(2) imageRawData = tf.read_file('./dog.jpg') # 这2种方法读取的文件都是2进制的,所以要解析成uint8的数组格式 imageUint = tf.image.decode_jpeg(imageRawData) # 转变成[0.0 - 1.0]的数值 imageFloat = tf.image.convert_image_dtype(imageUint,tf.float32) # 编辑图片操作,如翻转 imageFlip = tf.image.flip_left_right(imageFloat) # 使用plt.imshow()显示一下图片 with tf.Session() as sess: plt.imshow(sess.run(imageFlip)) plt.show() # 保存图片 # 与读入图片对应,有2种方法,思路均为:转变格式uint8 ==> 编码成2进制 ==> 指定位置存储 # 首先,转变成uint8类型 saveUint = tf.image.convert_image_dtype(imageFlip,tf.uint8) # 然后,编码成2进制 saveBinary = tf.image.encode_png(saveUint) # 最后,指定位置存储 # 方法1: with tf.Session() as sess: with open('./dog1.png','wb') as f: f.write(sess.run(saveBinary)) # 方法2: with tf.Session() as sess: with tf.gfile.GFile('./dog.png','wb') as f: f.write(sess.run(saveBinary))
tf读取数据集的方法:
大致可以分成两种方法:
1. 将数据集编码成TFRecord格式,再用tf.data.TFRecordDataset()将TFRecord文件导入,存储成数据集,不过这时数据集的每项都是一个系列,并不能直接被读取,还需要解析,代码如下。
def parse(record): # 解析dataset每个项目的方法 features = tf.parse_single_example(record,features={ 'image':tf.FixedLenFeature([],tf.string), # 这里的键'image','label'与定义TFRecord文件时的拼写要一致 'label':tf.FixedLenFeature([],tf.int64) }) image = tf.decode_raw(features['image'],out_type=tf.uint8) label = tf.cast(features['label'],dtype=tf.int32) return image, label dataset = tf.data.TFRecordDataset('./TFRecord/MNIST_Train.tfrecords') dataset = dataset.map(parse) # 直接读取TFRecord的数据集不能被使用,因为它是二进制的序列,需要解析成图片 dataset_shuffle = dataset.shuffle(10) dataset_batch = dataset_shuffle.batch(2) iterator = dataset_batch.make_initializable_iterator() image,label = iterator.get_next() with tf.Session() as sess: iterator.initializer.run() for i in range(2): for j in range(2): img,lb = sess.run([tf.reshape(image[j],[28,28]), label[j]]) print('label:',lb) plt.imshow(img,cmap='gray') plt.show()
这种格式在TF框架下读取速度更快,但是需要有有一部将数据编码成TFRecord的过程,过程不难,但是有些限制自由
TFRecord格式的数据是存放在tf.trian.Example协议缓冲区里的, 协议缓冲区的定义方法如下图所示,依次定义相应的属性即可,但是需要记住Feature属性字典的键,否者在解析时将报错。

2. 将图片的路径转换成张量,使用tf.data.Data.from_tensor_slices()转换成字符串数据集,再使用map函数读取每个字符串对应的图片和标签,并返回:
def readImage(filename): img_raw = tf.read_file(filename) # 读取张量的字符串,并返回字符串内容 img = tf.image.decode_jpeg(img_raw) # 将字符串数据转换成矩阵数字 img = tf.image.convert_image_dtype(img, dtype=tf.float32) img = tf.image.central_crop(img, 0.4) # 对数据预处理,如果上边的decode_jpeg换成decode_raw()则会报错 return img def createDatasetFromDirectory(path,extension='.jpg'): import glob import os filesname = sorted(glob.glob(os.path.join(path,'*'+extension))) filesnameTensor = tf.constant(filesname) dataset = tf.data.Dataset.from_tensor_slices(filesnameTensor) dataset = dataset.map(readImage) return dataset
- tf.train.Saver(var_list=None, reshape=False, sharded=False, max_to_keep=5, keep_checkpoint_every_n_hours=10000.0, name=None, restore_sequentially=False, saver_def=None, builder=None, defer_build=False, allow_empty=False, write_version=2, pad_step_number=False, save_relative_paths=False, filename=None)的用法:
__init__(self, var_list=None, reshape=False, sharded=False, max_to_keep=5, keep_checkpoint_every_n_hours=10000.0, name=None, restore_sequentially=False, saver_def=None, builder=None, defer_build=False, allow_empty=False, write_version=2, pad_step_number=False, save_relative_paths=False, filename=None)
'var_list'
如果是'Nonw',则将所有的可保存的变量均保存
定义被存储和恢复的变量。可以传入一个字典'dict',或是一个列表'list'
->'dict': 键是checkpoint文件中要被存储或者重构的变量的名字
->'list': checkpoint文件中变量将被赋予成节点名
例如:
v1 = tf.Variable(..., name='v1')
v2 = tf.Variable(..., name='v2')
#pass the variables as a dict
saver = tf.train.Saver({'v1':v1, 'v2':v2})
# or pass them as a list
saver = tf.train.Saver([v1, v2])
# Passing a list is equivalent to passing a dict with the variable op names as keys
savers = tf.train.Saver({v.op.name: v for v in [v1, v2]})
-
- 这是一个类
- 用于向checkpoint保存和从checkpoint恢复变量
- checkpoint是专有格式的二值文件,它保存了变量名与相应张量值之间的映射关系
- 测试一个checkpoint文件的最好方式就是使用Saver类加载它
- Saver类可以自动列举checkpoint文件名,并提供一个计数器,例如第1个,第2个。。。。因此,在训练模型时,这种机制可以使你维护多个checkpoints,为了避免充满内存,saver类自动地管理着checkpoint文件,例如Saver类可以仅仅存储N个最新的文件,或者每N hours of training保存一个。
- 如下所述,通过向可选参数‘global_step’中传入数值,为一个checkpoint文件加上序号
saver.save(sess, 'my-model', global_step=0) ==>filename:'my-model-0' saver.save(sess, 'my-model', global_step=1000)==>filename'my-model-1000'
另外,Saver()构造器的可选参数帮助控制checkpoint文件的增殖性
max_to_keep:
'''默认为5。表示需要保存的最近文件的最大数量,新生成的文件会删除老文件。如果是None或0,系统不会删除任何的checkpoint文件,但是仅仅保存最新的1个checkpoint文件。'''
keep_checkpoint_every_n_hours
'''默认为10,000小时。表示训练过程中,每n小时保存1次checkpoint文件。在漫长的训练过程结束之后,如果后期希望分析模型时如何获得进步的,定义这个参数非常有必要!
'''
训练程序中保存checkpoint的示例:
#create a saver
saver = tf.train.Saver(...variables..)
#Launch the graph and train, saving the model veery 1,000 steps
sess = tf.Session()
for step in xrang(100000):
sess.run(...training_op...)
if step%1000 ==0:
#Append the step number to the checkpoint name:
saver.save(sess,'my-model',global_step=step)
除了checkpoint文件,savers还维护硬盘上存有recent checkpoints 列表的协议缓冲区。这一功能被用于管理有序的checkpoint文件,并且通过‘latest_checkpoint()’,这一函数可以很方便的查找最新checkpoint文件的路径。协议缓冲区被存储在一个叫做‘checkpoint’的文件中。
如果你创建了好几个savers,为了区分,在调用save()方法时,你可以为协议缓冲区文件定义一个不同的文件名
方法: restore(self, sess, save_path) # 恢复之前保存的变量 This method runs the ops added by the constructor for restoring variables. 它需要一个已经建好图的会话中,被恢复的变量不必须初始化,因为恢复本身就是初始化变量 ‘save_path’参数有两种选择:要么从之前调用save()的方法中返回路径,要么调用‘latest_checkpoint()’
save(self, sess, save_path, global_step=None, latest_filename=None,
meta_graph_suffix='meta', write_meta_graph=True, write_state=True,
strip_default_attrs=False) # 保存变量
This method runs the ops added by the constructor for saving variables
同样地,需要一个建好图的会话。要被保存的变量必须先被初始化。该方法返回一个新创建的checkpoint文件的的路径,该路径可以直接传给'restore()'方法
tf.train.lastest_checkpoint(checkpoint_dir, latest_filename=None) #找到最新保存的checkpoint文件的文件名 Args: checkpoint_dir # 变量被保存的目录 Returns: 返回路径!当目录下有最新的checkpoint的路径;当目录下没有checkpoint文件,返回None
sv = tf.train.Supervisor(logdir=log_path, init_op=init)#logdir用于保存checkpoint 和 summary
saver = sv.saver #创建saver
with sv.managed_session() as sess: # 会自动去logdir中去找checkpoint,如果没有的话,自动执行初始化
pass
关于tf.train.Supervisor()的用法查看:https://www.cnblogs.com/zhouyang209117/p/7088051.html
- tf.maximum, tf.minimun, np.maximum, np.minimum; tf.reduce_max, tf.reduce_min, np.max, np.min.
'''
返回逐像素的最大值/最小值
'''
1. tf.maximum(x, y, name=None) , tf.minimum(x, y, name=None)#返回x,y逐像素的最大值
a = tf.random_uniform([2,2],0, 10, dtype=tf.int32, seed=1)
b = tf.random_uniform([2,2],3, 9, dtype=tf.int32, seed=1)
print("a:\n",sess.run(a)) # a: [[7,9],[3,2]
print('b:\n',sess.run(b)) # b:[[6, 8],[6,7]]
print('res:\n',sess.run(tf.maximum(a,b))) # 输出[[8 8],[9 4]]
print('res:\n',sess.run(tf.minimum(a,b))) # 输出[[1, 5], [6, 3]]
2. np.maximum()和np.minimun()一样返回逐像素最大最小质
'''
返回轴上的最大/最小值
'''
tf.reduce_max(input_tensor, axis=None, keepdims=None, name=None, reduction_indices=None, keep_dims=None) #注意只有一个输入张量
tf.reduce_min(input_tensor, axis=None, keepdims=None, name=None, reduction_indices=None, keep_dims=None) # 注意只有一个输入张量
np.max(a, axis=None, out=None, keepdims=<no value>, initial=<no value>)
np.min(a, axis=None, out=None, keepdims=<no value>, initial=<no value>)
- tf.data.Dataset创建的dataset类中repeat的使用方法:
- repeat(num=None)复制一个dataset共num次,假设数据集中有100个样本,训练时希望训练5个epoch,那么仅仅使用一个数据集的100个样本是不够的,所以要repeat(5),便产生了500个样本,用于训练。特别的,当num=None/-1时,数据集被无限重复。如下:
import tensorflow as tf dataset = tf.data.Dataset.range(10).shuffle(2).batch(3).repeat() # 将数据集先打乱,然后组成batch,之后重复无限次 iterator = dataset.make_one_shot_iterator() iterator_next = iterator.get_next() with tf.Session() as sess: for i in range(10): print(sess.run(iterator_next)) [out] [1 2 0] [3 5 6] [4 8 9] [7] [1 0 2] [4 5 3] [7 6 9] [8] [0 2 1] [4 5 3]
- tesorflow中的control_dependencies(self, control_inputs):
- 使用with关键字,要求所有定义在context下的操作,应该与control_inputs存在控制关系,例如:
with g.control_dependencies([a, b, c]): # `d` and `e` will only run after `a`, `b`, and `c` have executed. d = ... e = ...
- tensorflow的tf.identity(value, name),输入:张量,返回:一个相同类型,相同内容的张量。
a = tf.random_uniform([1]) b = tf.identity(a) with tf.Session() as sess: print(sess.run([tf.equal(a,b),a,b])) [out] [array([ True]), array([0.09417546], dtype=float32), array([0.09417546], dtype=float32)]
- 安装cygwin的方法查看:
- 特别注意:我习惯于安装anaconda,并在anaconda下安装python、tensorflow、pytorch等等,所以,在安装cygwin时候,无需安装任何扩展包,直接一直下一步到底即可!不需要看任何安装教程,尤其不用专门安装python2/3,不用安装第三方包,不用安装第三方包!
- 一直无脑下一步以后,安装成功以后,cygwin会自动寻找anaconda下的python、 tensorflow、pytorch!
- 安装完cygwin以后,将bin目录添加到环境变量中,则可以在cmd命令行中执行Linux下的代码!!!可以在cmd下执行Linux代码,可以在cmd下执行Linux代码!
- python 关于Argparse的用法笔记:
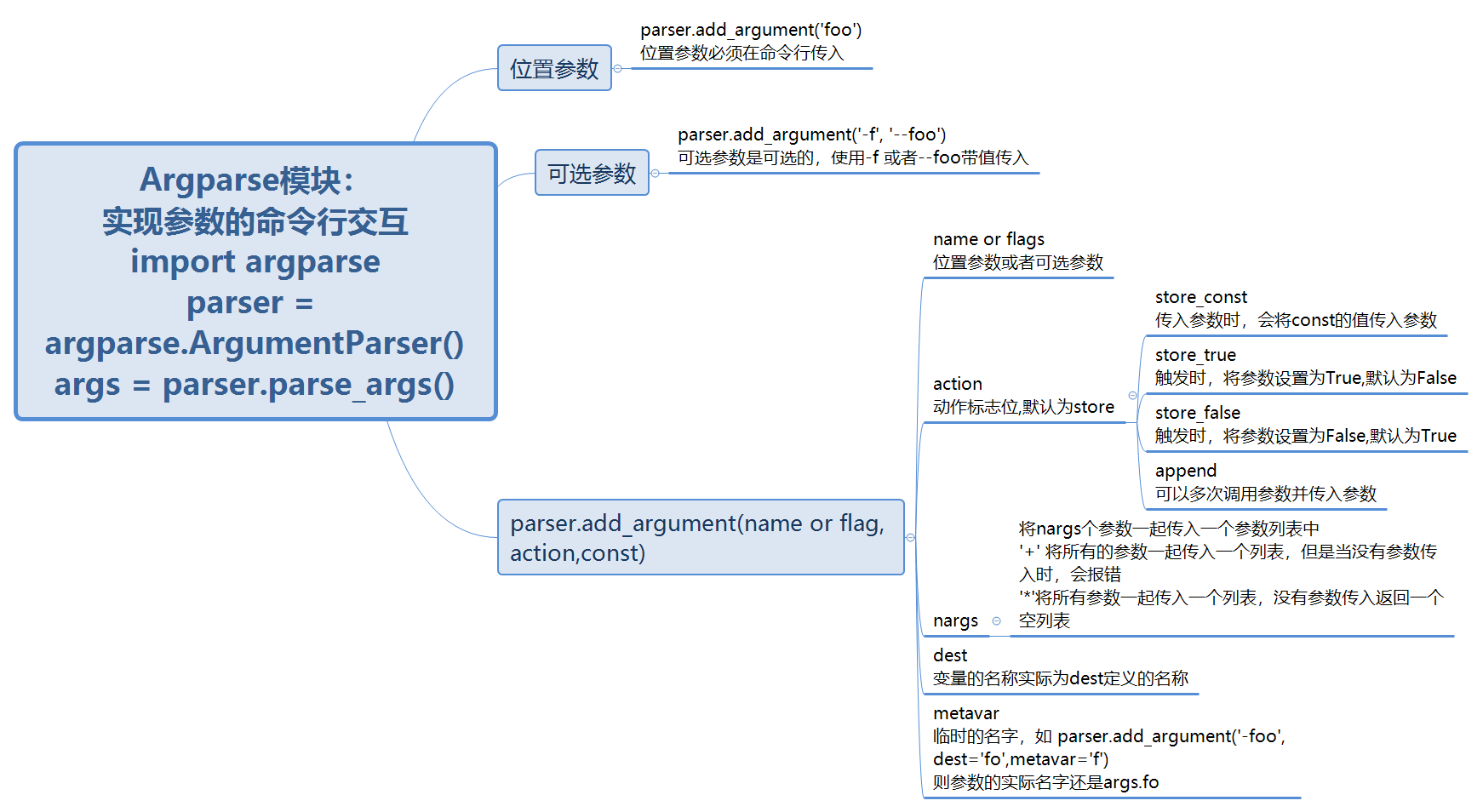
- python 中随机数seed的使用汇总:
""" numpy.random.seed()""" import numpy as np np.random.seed(2) # 每次使用numpy生成的随机数都是相同的,注意观察下面代码 a1 = np.random.rand(1) # a1: [0.4359949] b1 = np.random.rand(1) # b1: [0.02592623] np.random.seed(2) a2 = np.random.rand(1) # a2: [0.4359949] b2 = np.random.rand(1) # b2: [0.02592623] """tf.random.set_random_seed() 初始化图随机数,即每次建图,相同位置的随机数都相同 """ tf.random.set_random_seed(10) a = tf.random_uniform([1]) b = tf.random_uniform([1]) print('sess1') with tf.Session() as sess1: print('a1: ',sess1.run(a)) print('b1: ',sess1.run(b)) print('sess2') with tf.Session() as sess2: print('a2: ',sess2.run(a)) print('b2: ',sess2.run(b)) [out] sess1 a1: [0.47374308] b1: [0.5860243] sess2 a2: [0.47374308] b2: [0.5860243]
- 这里再对colab 和 jupyter notebook运行外部.py文件做统一整理
%run example.py [--args arg] # 运行外部py程序,其后可以传输必要的交互参数 !python example.py [--args arg] # 类似Linux,运行外部.py文件,可以传入参数 |-------------------------- |%% shell |python example.py [--args arg] # cell最开头加入%%shell是将整个cell看做一个shell交互窗口,因此每段代码不必再加! |sh example.sh # 这是在shell下的cell中运行.sh文件的方法,一般.sh文件定义了default参数 ---------------------------- 在windows的cmd窗口中运行example.py文件: 1. 首先cd到文件所在路径 2. 使用一条语句'python example.py [--args arg]'运行代码 注意python 与example.py一并输入
- dataset.prefetch() 主要作用是加快数据加载数据的速度,实现GPU处理和CPU加载的快速衔接。
- __name__ == '__main__'的意思:当某A.py程序作为主程序直接运行时,则A.py的__name__就是'__main__';但是,当A.py作为模块被导入到B.py程序时,则A.py的__name__就是A,所以,程序将作为模块被调用时,要想使得某些部分不被运行(例如程序的测试部分),就可以在其前面加上if __name__ =='__main__'
- python魔法方法:构造和析构
- def __init__(self): 类的初始化方法。不要给__init__方法定义任何的返回值,即在__init__方法中,不要有return返回值
- __new__是类的构造方法,__init__是类的初始化方法,所以在创建实例对象时,__new__被首先调用,然后再用__init__初始化实例对象。__new__方法用于修改继承的不可改变的类
-
class MyStr(str): # 定义一个MyStr类,继承str类,str类是不可改变的 def __new__(cls, s): # 当创建MyStr类的时候会首先使用__new__构造一个类,名为cls print('call __new__') s = s.upper() return super().__new__(cls, s) # 使用str类传入当前构造的MyStr类和参数s def __init__(self, s): # 初始化方法的参数与构造方法的参数要一致,否则报错 super().__init__() print('call __init__') print(s) string = MyStr('I Love U') print(string) [out] call __new__ call __init__ I Love U I LOVE U # 字符串全部转换成了大写
- python的魔法方法:当对象进行相关运算时,会自动调用类中的魔法方法。我们可以重写魔法方法,从而实现相应的功能。
- python的self代表什么:
- python类中定义的self相当于绑定实例化对象本身。举个例子
class Paper(): # 类的首字母都大写 def __init__(self, student): self.student = student # 这里self.student表示实例化对象的属性 def publish(self): # 这里传入self即表示实例化对象本身。 print('Student {} will publish a Top paper' .format(self.student)) sa = Paper('xuez') # 创建不同的实例对象,因此self指代的也不同。 sa.publish() # 相当于 publish(sa),于是sa.student = 'xuez'就被打印出来 sb = Paper('XZ') sb.publish() [out]: Student xuez will publish a Top paper Student XZ will publish a Top paper
- python类中定义的self相当于绑定实例化对象本身。举个例子
- python的魔法方法:它们被双下划线包围:__xx__。当python创建实例对象时,这些魔法方法会被自动调用,例如__init(self)__ 等等。例如
class Name(): def __init__(self, name): self.name = name def setGender(self, gender): print('{}\'s gender: {}'.format(self.name, gender)) p1 = Name('xuez') p1.setGender('Boy') p2 = Name('XZ') p2.setGender('Girl') [out] xuez's gender: Boy XZ's gender: Girl 如果实例化对象时,不传入参数,则使得魔法方法__init__(self, name)没有被赋值,那么就会报错: p3 = Name() [out] TypeError: __init__() missing 1 required positional argument: 'name'
- python 类中的私有变量与方法
- 使用双下划线开头__xx表示类的私有方法;
- 私有方法只能在类内部访问,在类外部无法直接访问,但是可以使用 实例对象._类名__私有变量 进行访问;如下:
class PrivateTest(): def __init__(self,name, gender): # __xx__魔法方法在类实例化时会自动调用 self.__name = name # 私有变量(属性)表示成 __xx, 只能在类内部访问 self.gender = gender def __getGender(self): # 私有方法表示成 __getGender() print(self.gender) def getName(self): print(self.__name) # 只能在类内部访问私有变量/属性 person = PrivateTest('xuez', 'Boy') print(person.gender) person.getName() [out] Boy xuez 但是 print(person.__name) # 实例对象访问私有属性 报错 person.__getGender() # 实例对象访问私有方法 报错 可以使用下面的方法改进 print(person._PrivateTest__name) person._PrivateTest__getGender() [out] xuez Boy
-
- 区别于魔法方法:__xx__
- 内部方法:_xx
- python 方法重写与super()方法:
- 我们知道python类可以实现子类继承父类,但是在子类中需要重写父类方法又不覆盖父类怎么办?使用super()方法
-
class Person(): # 定义父类 def __init__(self): self.eat = '米饭, 面条, 馄饨' self.sleep = '8h, 10h, 12h' self.work = '996, 955' def setGender(self,gender): self.gender = gender print(self.gender) class Teachers(Person): # 子类Teacher继承父类 pass t = Teachers() t.setGender('Girl') # 继承了父类的子类可以调用父类的方法 [out] Girl class Athelete(Person): def __init__(self): super().__init__() # super()保证子类继承父类时,虽然重写了父类的方法,但是不会覆盖父类方法 self.jump = '10m, 20m, 30m' def setGender(self, gender): super().setGender('Boy') # 这是另一个super(),但是一般不这样使用 print('Athlete\'s gender:' + gender)
- python类中的组合:有些类不能明确的继承父类,但是需要在类中调用该指定类,就形成了组合。
- python 匿名函数:lambda; 过滤器: filter;映射:map
- 匿名函数:lambda [arg1 [,arg2,.....argn]]:expression:不具体定义函数名,但实现函数意义。
- 过滤器:filter(function, iterable):使用函数/none,过滤出可迭代对象为True的元素,作为列表返回
- 映射:map(function, iterable, ...):将可迭代对象依次送入定义的函数进行计算,返回列表对象
- 将svBRDF看做是BRDF的集合,测得单点的BRDF,然后将空间中具有相同特性的位置映射成该BRDF就构成了svBRDF
- Normal map: 法向贴图;漫反射贴图:diffuse map;均质的光滑度:roughness;高光反射强度:specular coefficient
- python 安装opencv-python库:pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
- 使用cv2读取和显示图像
-
![]() View Code
View Codeimport cv2 img = cv2.imread('dog.jpg') # 返回ndarray img = cv2.resize(img,(500,500)) cv2.namedWindow('dog') # 为显示图像创建窗口 cv2.imshow('dog',img) cv2.waitKey(0) # 参数为0,直到键盘敲入任意键执行下一个代码;参数>0,表示 x ms cv2.destroyAllWindows() # 关闭所有窗口
- python 卸载tensorflow: pip uninstall tensorflow
- python 安装tensorflow: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow==1.13.1


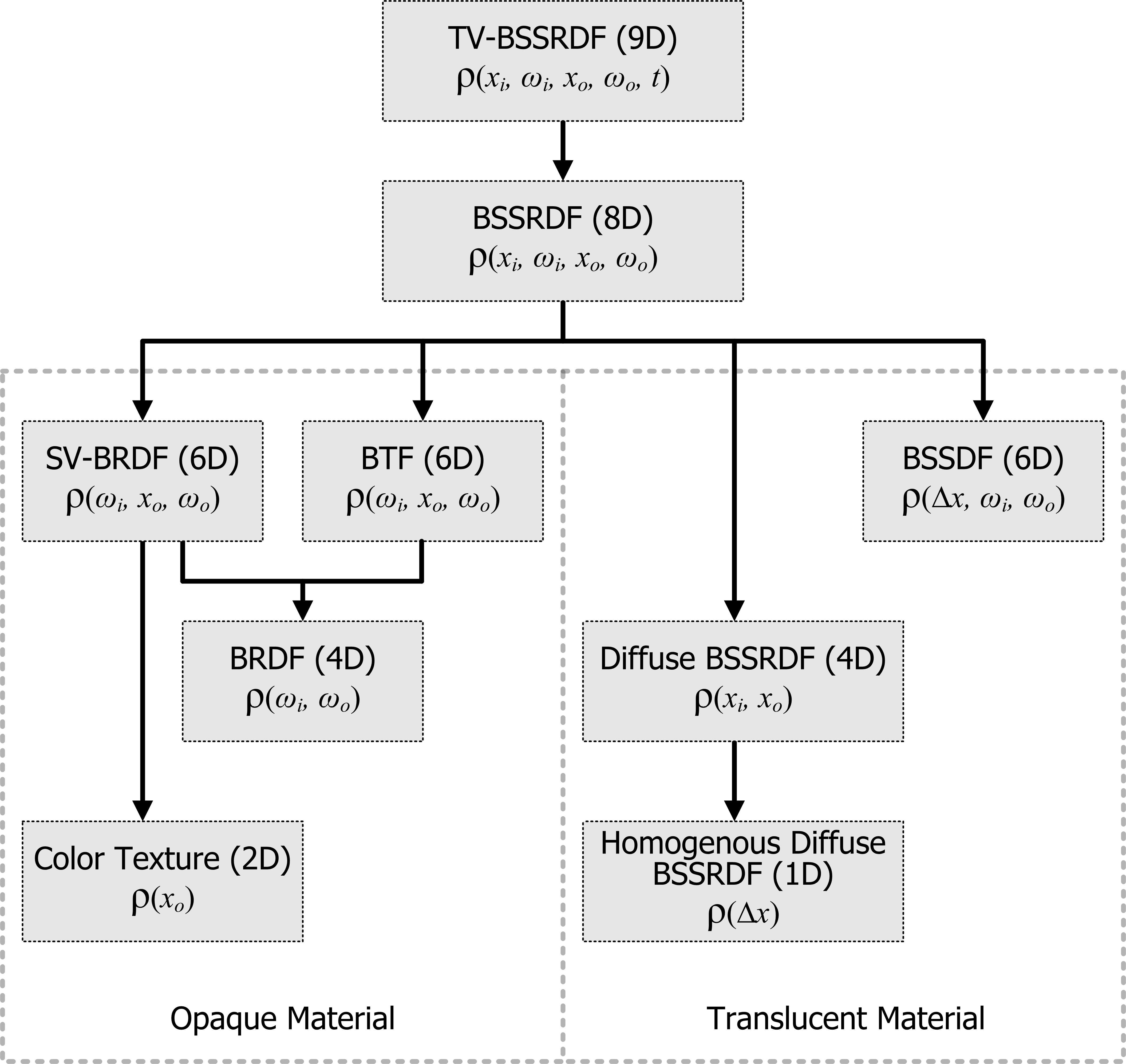
- 什么是svBRDF,BTF和BRDF?
- 共性:描述材质表面反射特性的物理量。BRDF:双向反射分布函数;BTF:双向纹理函数;svBRDF:表面变化BRDF。
- 差异:
- 数据维度依次减少,如左图所示;
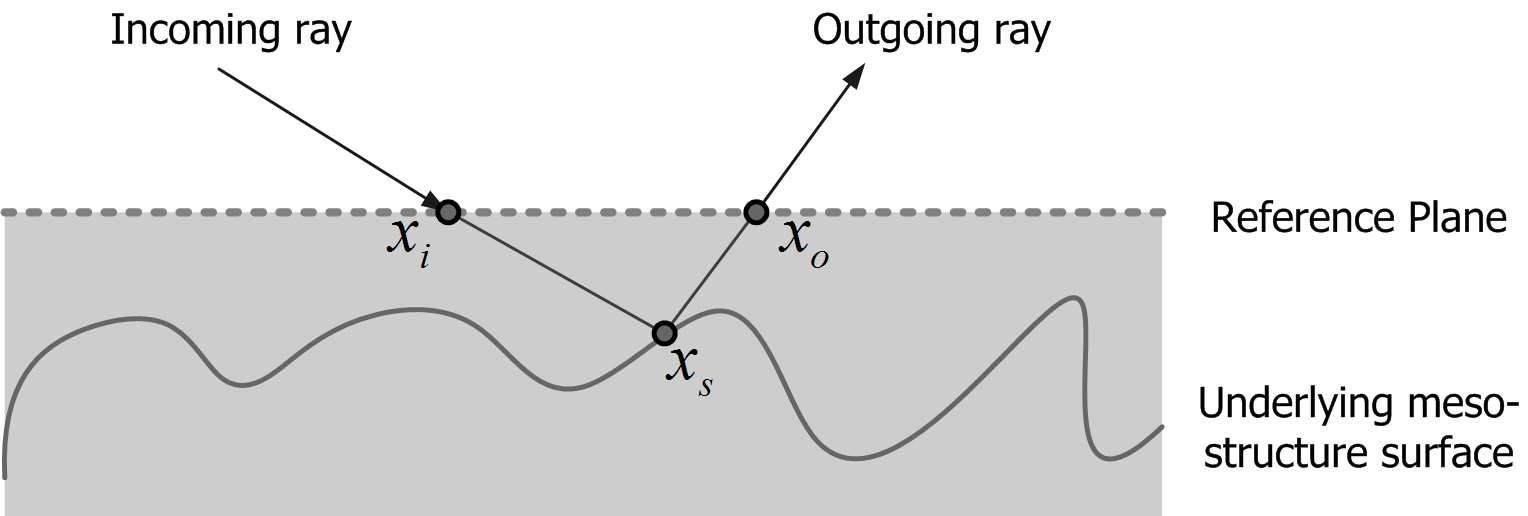
- 表征物理意义不同,如右图所示。svBRDF(5D)描述表面各点反射特性,xi 和 xo位于同一点,忽略微观表面;BTF(5D)描述微观表面的反射性,xi和xo位于不同点,形式上svBRDF和BTF相同,但本质不同,直观的说,svBRDF描述物体表面的反射特性;BTF描述次表面的反射特性(反射发生在物体内部);BRDF(4D)描述的物体表面的反射特性,假设处处都相同。因此svBRDF是不同点处BRDF的集合。
![]()
![]()
- 基于数据驱动的建模与重构
- 将全光函数解构成几个嵌套或者叠加的子部分,然后采用不同的建模方式分别建模各个部分。
- 高级于基于图像建模的方式(黑盒)和参数化建模模型(白盒)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号