数据库性能优化
1.数据库访问优化法则
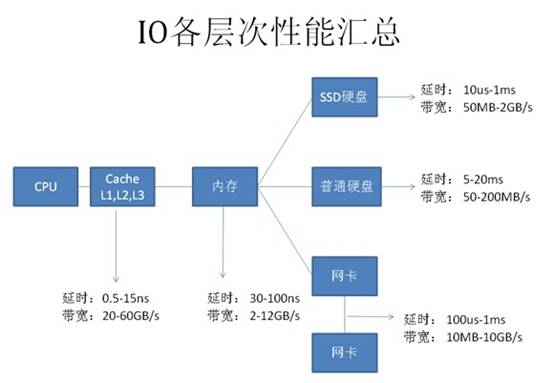
从图上可以看到基本上每种设备都有两个指标:
延时(响应时间):表示硬件的突发处理能力;
带宽(吞吐量):代表硬件持续处理能力。
性能优化法则漏斗图
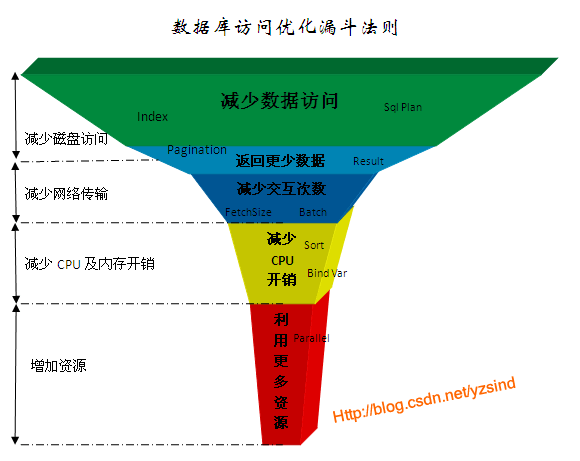
这个优化法则归纳为5个层次:
- 1、 减少数据访问(减少磁盘访问)
- 2、 返回更少数据(减少网络传输或磁盘访问)
- 3、 减少交互次数(减少网络传输)
- 4、 减少服务器CPU开销(减少CPU及内存开销)
- 5、 利用更多资源(增加资源)
二、Oracle数据库两个基本概念
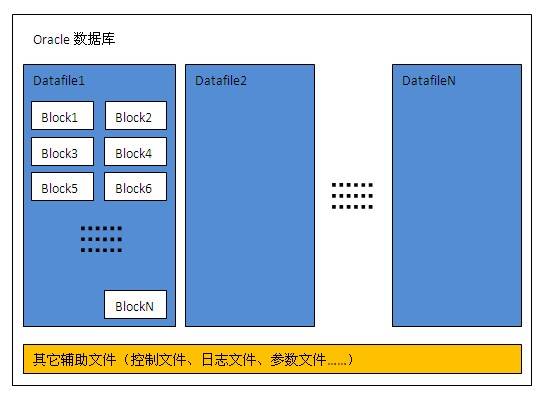
数据块(Block)
数据块是数据库中数据在磁盘中存储的最小单位,也是一次IO访问的最小单位,一个数据块通常可以存储多条记录,数据块大小是DBA在创建数据库或表空间时指定,可指定为2K、4K、8K、16K或32K字节。下图是一个Oracle数据库典型的物理结构,一个数据库可以包括多个数据文件,一个数据文件内又包含多个数据块;
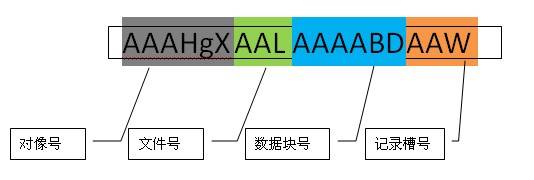
ROWID
ROWID是每条记录在数据库中的唯一标识,通过ROWID可以直接定位记录到对应的文件号及数据块位置。ROWID内容包括文件号、对像号、数据块号、记录槽号,如下图所示:
三、数据库访问优化法则详解
1、减少数据访问
1.1、创建并使用正确的索引
索引有哪些:
B-Tree索引,位图索引,全文索引
B-Tree平衡树索引
叶子节点内容:索引字段内容+表记录ROWID
根节点,分支节点内容:当一个数据块中不能放下所有索引字段数据时,就会形成树形的根节点或分支节点,根节点与分支节点保存了索引树的顺序及各层级间的引用关系。
一个普通的BTREE索引结构示意图如下所示:
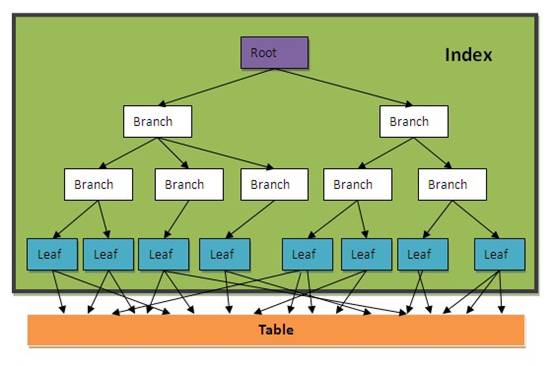
一个表中可以建多个索引,就如一本字典可以建多个目录一样(按拼音、笔划、部首等等)。
一个索引也可以由多个字段组成,称为组合索引,如上图就是一个按部首+笔划的组合目录。
我们一般在什么字段上建索引?
这是一个非常复杂的话题,需要对业务及数据充分分析后再能得出结果。主键及外键通常都要有索引,其它需要建索引的字段应满足以下条件:
1、字段出现在查询条件中,并且查询条件可以使用索引;
2、语句执行频率高,一天会有几千次以上;
3、通过字段条件可筛选的记录集很小,那数据筛选比例是多少才适合?
这个没有固定值,需要根据表数据量来评估,以下是经验公式,可用于快速评估:
小表(记录数小于10000行的表):筛选比例<10%;
大表:(筛选返回记录数)<(表总记录数*单条记录长度)/10000/16
单条记录长度≈字段平均内容长度之和+字段数*2
1.2、只通过索引访问数据
有些时候,我们只是访问表中的几个字段,并且字段内容较少,我们可以为这几个字段单独建立一个组合索引,这样就可以直接只通过访问索引就能得到数据,一般索引占用的磁盘空间比表小很多,所以这种方式可以大大减少磁盘IO开销。
2、返回更少的数据
2.1、数据分页处理
一般数据分页方式有:
2.1.1、客户端(应用程序或浏览器)分页
将数据从应用服务器全部下载到本地应用程序或浏览器,在应用程序或浏览器内部通过本地代码进行分页处理
优点:编码简单,减少客户端与应用服务器网络交互次数
缺点:首次交互时间长,占用客户端内存
适应场景:客户端与应用服务器网络延时较大,但要求后续操作流畅,如手机GPRS,超远程访问(跨国)等等。
2.1.2、应用服务器分页
将数据从数据库服务器全部下载到应用服务器,在应用服务器内部再进行数据筛选。以下是一个应用服务器端Java程序分页的示例:
优点:编码简单,只需要一次SQL交互,总数据与分页数据差不多时性能较好。
缺点:总数据量较多时性能较差。
适应场景:数据库系统不支持分页处理,数据量较小并且可控。
2.1.3、数据库SQL分页
采用数据库SQL分页需要两次SQL完成
一个SQL计算总数量
一个SQL返回分页后的数据
优点:性能好
缺点:编码复杂,各种数据库语法不同,需要两次SQL交互
2.2、只返回需要的字段
通过去除不必要的返回字段可以提高性能,例:
调整前:select * from product where company_id=?;
调整后:select id,name from product where company_id=?;
优点:
1、减少数据在网络上传输开销
2、减少服务器数据处理开销
3、减少客户端内存占用
4、字段变更时提前发现问题,减少程序BUG
5、如果访问的所有字段刚好在一个索引里面,则可以使用纯索引访问提高性能。
缺点:增加编码工作量
由于会增加一些编码工作量,所以一般需求通过开发规范来要求程序员这么做,否则等项目上线后再整改工作量更大
3、减少交互次数
3.1、batch DML
3.2、In List
3.3、设置Fetch Size
3.4、使用存储过程
3.5、优化业务逻辑
3.6、使用ResultSet游标处理记录
4、减少数据库服务器CPU运算
4.1、使用绑定变量
4.2、合理使用排序
4.3、减少比较操作
4.4、大量复杂运算在客户端处理
5、利用更多的资源
5.1、客户端多进程并行访问
5.2、数据库并行处理
6.总结

参考资料
https://www.cnblogs.com/easypass/archive/2010/12/08/1900127.html
https://blog.csdn.net/weixin_39106371/article/details/82117148

 浙公网安备 33010602011771号
浙公网安备 33010602011771号