

可用性(Available)、可靠性(Reliable)、扩展性(Scalability)、可维护性(Maintainability)、容错性(Fault Tolearance)(Non-functional System Characteristics)
Posted on 2024-10-09 00:50 LKB_HUGH 阅读(3758) 评论(0) 收藏 举报在非功能相关的系统需求中,主要可用性(Available)、可靠性(Reliable)、扩展性(Scalability)、可维护性(Maintainability)、容错性(Fault Tolearance)这五个性质。
一、可用性(Available)
1. 定义可用性(What is availability)
可用性是指某些服务或基础设施可用客户端访问并在正常条件下运行的时间百分比。例如,如果一项服务具有100%的可用性,则意味着该服务始终按预期按预期运行并响应(正常运行)
从定义上看,可用性重在客户端与服务端的请求正常反应的时间比
2. 测量可用性(Measuring availability)
Available(百分比) = (总运行时间 - 服务暂停服务时间)* 100 / 总运行时间
注释:总运行时间(Total time),服务暂停服务时间(Amount Of Time Service Was Down)
从上面的公式可以知道,可用性在于服务是否能正常运行
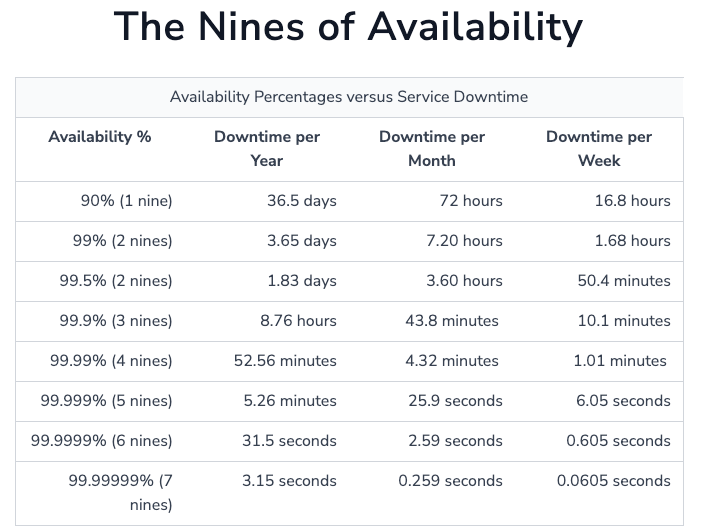
3. 业界使用9的数量来形容可用性程度
二、可靠性(Reliable)
1. 定义可靠性
Reliability, R, is the probability that the service will perform its functions for a specified time. R measures how the service performs under varying operating conditions.(暂时无法理解)
2. 测量可靠性
我们经常使用平均故障间隔时间 (MTBF)和平均修复时间 (MTTR)作为衡量R指标。(我们争取更高的MTBF值和更低的MTTR值。)
- MTBF = (总时间 - 停机时间总和)/ 失败总数
- MTTR = 总维护时间 / 维修个数
注释:总时间(Total Elapsed Time)、停机时间总和(Sum of Downtime)、失败总数(Total Number of Failures)、总维护时间(Total Maintenance Time)、维修个数(Total Number of Repairs)
3. 对比可用性
Reliability and availability are two important metrics to measure compliance of service to agreed-upon service level objectives (SLO).【可靠性和可用性是衡量服务是否符合商定的服务级别目标 (SLO)的两个重要指标。】
- 例子1
某个系统可能 90% 可用,但只有 80% 的时间可靠。 - 例子2
假设我们将“系统”视为数据中心内部的东西(硬件 + 软件)。假设该数据中心发生网络故障,没有外部流量流入,也没有内部流量流出。在这种情况下,即使在数据中心内部,所有系统都运行良好(瞬时可靠性 100%),瞬时可用性也可能为零(因为客户端无法访问服务)。
三、扩展性(Scalability)
定义扩展性(What is scalability?)
可扩展性是指系统在不影响性能的情况下处理不断增加的工作负载的能力。(Scalability is the ability of a system to handle an increasing amount of workload without compromising performance.)
工作负载可以有不同的类型,包括:
- 请求工作负载(Request workload): 系统处理的请求的数量(This is the number of requests served by the system.)
- 数据/存储工作负载(Data/storage workload): 系统存储的数据量(This is the amount of data stored by the system.)
可扩展性的不同维度(The different dimensions of scalability)
- 规模可扩展性(Size scalability):如果我们可以简单地向系统添加额外的用户和资源,那么系统的规模就可以扩展。(A system is scalable in size if we can simply add additional users and resources to it.)
- 管理可扩展性(Administrative scalability):支持越来越多的组织或用户轻松共享单个分布式系统的能力。(This is the capacity for a growing number of organizations or users to share a single distributed system with ease.)
- 地理可扩展性(Geographical scalability):这涉及到该程序在保持可接受的性能限制的同时满足其他地区需求的难易程度。换句话说,该系统可以轻松地为广阔的地理区域以及较小的地理区域提供服务。(This relates to how easily the program can cater to other regions while maintaining acceptable performance constraints. In other words, the system can readily service a broad geographical region, as well as a smaller one.)
不同的可扩展性方式(Different approaches of scalability)
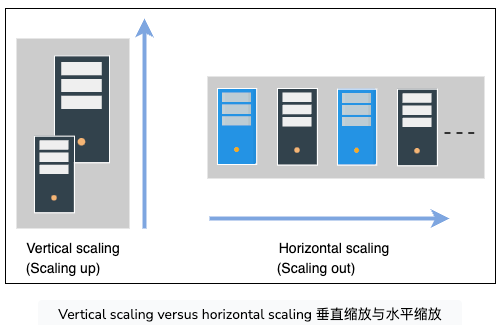
- 垂直可扩展性-扩大规模(Vertical scalability—scaling up):是指通过向现有设备提供附加功能(例如,附加 CPU 或 RAM)来进行扩展。垂直扩展允许我们扩展现有的硬件或软件容量,但我们只能将其扩展到服务器的限制。垂直扩展的美元成本通常很高,因为我们可能需要特殊的组件来扩展。(refers to scaling by providing additional capabilities (for example, additional CPUs or RAM) to an existing device. Vertical scaling allows us to expand our present hardware or software capacity, but we can only grow it to the limitations of our server. The dollar cost of vertical scaling is usually high because we might need exotic components to scale up.)
- 水平可扩展性-横向扩展(Horizontal scalability—scaling out):是指增加网络中的机器数量。我们使用商品节点来达到此目的,因为它们具有有吸引力的美元成本优势。这里的问题是我们需要构建一个系统,使许多节点可以集体工作,就像我们有一个巨大的服务器一样。(refers to increasing the number of machines in the network. We use commodity nodes for this purpose because of their attractive dollar-cost benefits. The catch here is that we need to build a system such that many nodes could collectively work as if we had a single, huge server.)
![image]()
四、可维护性(Maintainability)
1. 定义可维护性(What is maintainability)
除了构建系统之外,之后的主要任务之一是通过查找和修复错误、添加新功能、保持系统平台更新以及确保系统平稳运行来保持系统正常运行。定义示例性系统设计的此类要求的显着特征之一是可维护性。我们可以将可维护性的概念进一步分为三个基本方面:
- 可操作性(Operability):指系统在正常情况下能够顺利运行、在故障情况下能够达到正常状态的难易程度(This is the ease with which we can ensure the system’s smooth operational running under normal circumstances and achieve normal conditions under a fault.)
- 清晰性(Lucidity):这是指代码的简单性。代码库越简单,就越容易理解和维护,反之亦然。(This refers to the simplicity of the code. The simpler the code base, the easier it is to understand and maintain it, and vice versa.)
- 可修改性(Modifiability):这是系统轻松集成修改的、新的和未预见的功能的能力。(This is the capability of the system to integrate modified, new, and unforeseen features without any hassle.)
1.1 个人理解
按照我之前的理解,可维护性主要在coding时期的Lucidity与Modifiability,并没有理解到原来在出现故障时的Operability。
个人理解可以基于这俩个层面:
- 出现业务bug时的修复的Operability
- 出现非业务情况的系统异常时的修复的Operability
2. 量化可维护性(Measuring maintainability)
注意:可维护性使我们能够深入了解系统在运行时进行维修和修改的能力。(Note:Maintainability gives us insight into the system’s capability to undergo repairs and modifications while it’s operational.)
2.1 指定时间内的恢复概率
定义:可维护性M是服务在故障发生的指定时间内恢复其功能的概率。 M衡量服务恢复正常运行状态的便捷程度。(Maintainability, M, is the probability that the service will restore its functions within a specified time of fault occurrence. M measures how conveniently and swiftly the service regains its normal operating conditions.)
例子:假设某个组件在半小时内定义的可维护性值为 95%。在这种情况下,半小时内将组件恢复到完全活动状态的概率为 0.95。(For example, suppose a component has a defined maintainability value of 95% for half an hour. In that case, the probability of restoring the component to its fully active form in half an hour is 0.95.)
2.2 MTTR(mean time to repair)
- MTTR = 总维护时间 / 维修个数
注释:总维护时间(Total Maintenance Time)、维修个数(Total Number of Repairs)
换句话说,MTTR 是修复和恢复故障组件所需的平均时间。我们的目标是使 MTTR 值尽可能低。 (In other words, MTTR is the average amount of time required to repair and restore a failed component. Our goal is to have as low a value of MTTR as possible.)
四、容错性(Fault Tolearance)
1. 定义容错性(What is fault tolerance)
容错是指系统即使一个或多个组件发生故障也能持续执行的能力。这里,组件可以是软件或硬件(Fault tolerance refers to a system’s ability to execute persistently even if one or more of its components fail. Here, components can be software or hardware.)
容错技术(Fault tolerance techniques)
复制(Replication)
最广泛使用的技术之一是基于复制的容错。通过这种技术,我们可以复制服务和数据。我们可以用健康节点替换故障节点,用其副本替换故障数据存储。大型服务可以透明地进行替换,而不会影响最终客户。
对于副本的复制的挑战
当数据发生任何更新时,所有副本都需要定期更新以保持一致性。更新副本中的数据是一项具有挑战性的工作。
- 当系统需要强一致性时,我们可以同步更新副本中的数据。然而,这降低了系统的可用性。
- 当我们可以接受最终一致性时,我们还可以接受异步更新副本中的数据,导致我们可能在数据未覆盖所有节点前需要读旧数据(resulting in stale reads until all replicas converge)。
这是俩种一致性的权衡,要么牺牲可用性、要么牺牲点一致性。 CAP定理
检查点(Checkpointing)
检查点事一种将系统状态保存到稳定存储中的技术,以便在之后由于错误或服务中断而发生故障时进行检索。检查点是一种容错技术,在不同的时间间隔的很多阶段中执行(heckpointing is a fault tolerance technique performed in many stages at different time intervals)。当分布式系统发生故障时,我们可以从前一个检查点获取最后计算的数据并从哪里开始工作。
检查点事针对系统中不同的单独进程执行的,其方式使得它们代表系统实际执行的全局状态。根据状态的不同,我们可以将检查点分为俩种类型
- 一致状态(Consistent state):一种一致的状态,其中系统的所有单独进程对系统中发生的共享状态或事件序列具有一致的视图。在一致状态下拍摄的快照具有一致状态的数据,代表系统的可能情况。为了使检查点保持一致,通常需要满足以下条件:
-
- 保存检查点之前完成的所有数据更新。任何正在进行的数据更新都要回滚,就好像它们没有启动一样(All updates to data that were completed before the checkpoint are saved. Any updates to data that were in progress are rolled back as if they didn’t initiate.)
-
- 检查点包括已发送或接收的所有消息。没有消息在传输中(飞行中),以避免消息丢失的情况。(Checkpoints include all the messages that have been sent or received up until the checkpoint. No messages are in transit (in-flight) to avoid cases of missing messages.)
-
- 系统组件及其状态之间的关系和依赖关系与正常操作期间的预期相符。(Relationships and dependencies between system components and their states match what would be expected during normal operation.)
- 不一致状态(Inconvenient state):这是系统不同进程保存的状态存在差异的状态。换句话说,不同流程之间的检查点并不连贯和协调。(This is a state where there are discrepancies in the saved state of different processes of a system. In other words, the checkpoints across different processes are not coherent and coordinated.)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号