爬虫随笔(一)某网站实战
爬虫随笔,某牛
前几天一直在看js逆向,现在分享一下本人近期学习记录
首先分享一个网站,这个网站可以获得request所需要的header和cookie
https://curlconverter.com/
爬取网站就不挂了
简单观察发现,该网站是滑动加载,我们可以在滑动加载时获得我们所需要的接口,发现两个链接,里面负载一模一样

当然正常来说点不进去,但是怎么获得数据呢?别急,我们先根据url来打xhr断点,然后再搜索关键字,JSON.parse,就可以得到所需js格式,抄下即可
但是在我们给所需代码上断点时,我们发现,打上断点以后还需要多次运行代码才会产生我们所需要的数据,根据观察我们发现每次下拉刷新时,作用域的值不太一样,而我们把第一次获得的数据进行解密时,发现该数值储存company_id和company_code
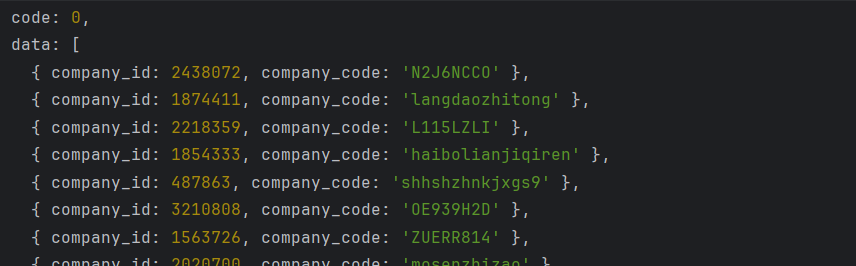
而且我们还发现负载中有一个sig,我们推测该数据是加密以后传回服务器获得我们需要的具体数值,但是加密该如何做到?
直接在之前打断点处搜索sig,我们会得到加密的js代码,复制进去即可(加密和解密我就不贴出来了,自行寻找吧),然后我们该写我们的爬虫了。嗷还有一个,通过滑动自动加载,我们发现有一个数据叫n,该数据长这样
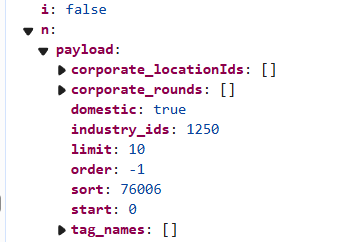
而且我们每次加载页数时值都会改变,推测sig是从n加密过来的,差不多就这样,我们上代码
# -*- coding:utf-8 -*-
# @FileName :code1.py
# @Time :2025/1/26 20:37
# @Author :Yukio
from http.client import responses
import requests
import execjs
def use_encrypt_params():
with open("encrypt.js", encoding="utf-8") as f:
js_code = f.read()
docjs = execjs.compile(js_code)
n1 = {
"payload": {
"industry_ids": 1250,
"domestic": True,
"corporate_locationIds": [],
"tag_names": [],
"corporate_rounds": [],
"sort": 76006,
"order": -1,
"start": 0,
"limit": 10
}
}
params = docjs.call('main', n1)
# print(params)
return params
def get_data(params):
url = ""
response = requests.post(url, json=params, cookies=cookies, headers=headers).json()
# print(response['d'])
return response['d']
def decrypt_data(data_params):
with open("decrypt.js", encoding="utf-8") as f:
js_code = f.read()
doctjs = execjs.compile(js_code)
data = doctjs.call('main', data_params)
# print(data)
print('将获取数据为:',len(data['data']))
encrypted_data = [i['company_code'] for i in data['data']]
return encrypted_data
def encrypted_detail_params(encrypted_data):
with open('encrypt.js', encoding='utf-8') as f:
js_code = f.read()
doctjs = execjs.compile(js_code)
n1 = {
"payload": {
'codes':encrypted_data
}
}
encrypted_detail_data = doctjs.call('main', n1)
return encrypted_detail_data
def get_detail_data(encrypted_detail_data):
url = ''
responses = requests.post(url, json=encrypted_detail_data, cookies=cookies, headers=headers).json()
# print(responses['d'])
return responses['d']
def final_decrypt(detail_data):
with open('decrypt.js', encoding='utf-8') as f:
js_code = f.read()
docjs = execjs.compile(js_code)
final_data = docjs.call('main', detail_data)
print(final_data)
if __name__ == "__main__":
params = use_encrypt_params()#传入我们需要获取的数据量,加密以后得到params
data_params = get_data(params)#params传给接口,返回数据得到data_params
encrypted_data = decrypt_data(data_params)#data_params解密得到encrypted_data,
# print(encrypted_data)
encrypted_detail_data = encrypted_detail_params(encrypted_data)#encrypted_data放入payload加密后得到encrypted_detail_data
# print(encrypted_detail_data)
detail_data = get_detail_data(encrypted_detail_data)#然后传入接口得到detail_data
final_decrypt(detail_data)#detail_data解密得到最终结果
ok这大概是我全部的学习经历,该过程只使用学习记录,未进行商业用途(叠甲
本文来自博客园,作者:Liyukio,转载请注明原文链接:https://www.cnblogs.com/Liyukio/p/18701559

 浙公网安备 33010602011771号
浙公网安备 33010602011771号