
pyspark 集成hive
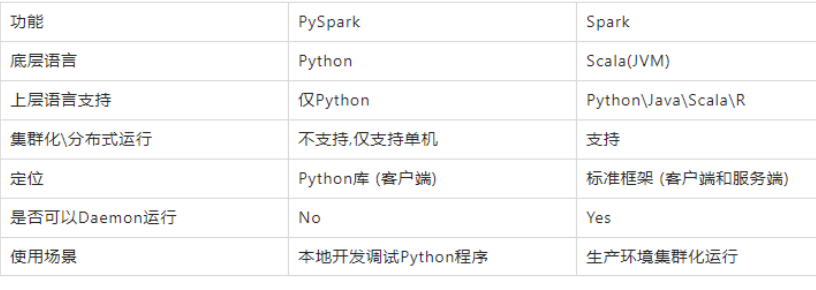
1:PySpark类库和标准Spark框架的简单对比
2: 安装
将/spark/python/pyspark 复制到 python 的安装包中 或者 pip install pyspark (注意版本对应关系)
3:spark on hive
- 本质: 将hive的执行引擎替换为spark 的执行引擎!
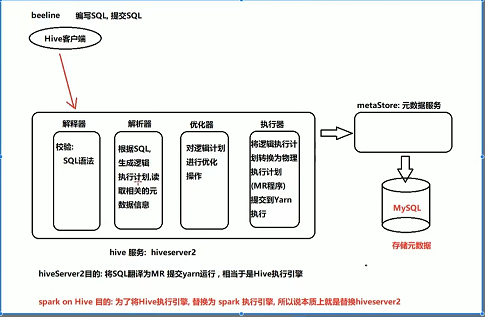
- 配置:
- 校验hive的是否正常运行(即链接hive,执行sql操作,看是否正常运行)
-
确保 hive的conf目录下的hive-site.xml中配置了metastore服务地址
<property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property>
- 将hive/conf/hive-site.xml 复制到 spark/conf 下,将mysql-connector-java-5.1.46.jar 复制到spark的jars/
- 启动spark-sql,show databases 看是否正常运行
-
root@hadoop jars]# spark-sql Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 22/07/17 11:29:33 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable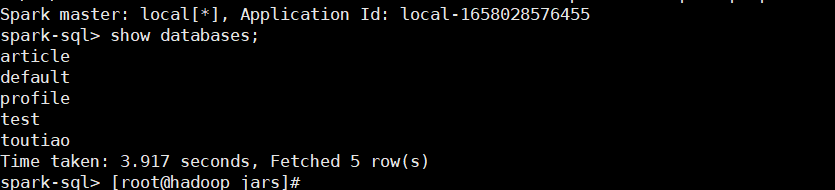
-
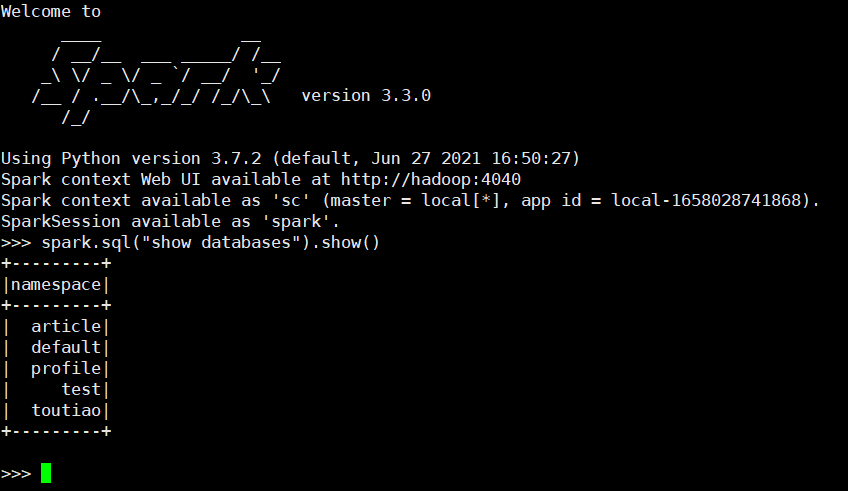
- 启动spark/bin/下的pyspark
4:在python代码中集成hive
-
Spark SQL分布式执行引擎
-
已经完成了spark集成hive的操作, 但是目前集成后, 如果需要连接hive, 此时需要启动一个spark的客户端(pyspark,spark-sql, 或者代码形式)才可以, 这个客户端底层, 相当于启动服务项, 用于连接hive服务, 进行处理操作, 一旦退出了这个客户端, 相当于这个服务也不存在了, 同样也就无法使用了
- 在spark/sbin下有个thriftserver服务,这份服务可以理解为spark的hiveserver2服务!
- 如何启动spark的分布式执行引擎呢?
-
[root@hadoop sbin]# pwd /root/bigdata/spark/sbin [root@hadoop sbin]# ./start-thriftserver.sh --hiveconf hive.server2.thrift.port=10000 --hiveconf hive.server2.thrift.bind.host=hadoop --hiveconf spark.sql.warehouse.dir=hdfs://hadoop:9000/user/hive/warehouse --master local[*]
-
-
- 有了这个服务,我们就可以在python代码中集成hive了
-
import findspark findspark.init() from pyspark import SparkConf from pyspark.sql import SparkSession import os import sys PYSPARK_PYTHON = "/usr/local/python3/python" JAVA_HOVE = "/usr/local/java/jdk1.8.0_131/" # 当存在多个版本时,不指定很可能会导致出错 os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON os.environ["JAVA_HOVE"] = JAVA_HOVE class SparkSessionBase(object): SPARK_APP_NAME = None SPARK_URL = 'local[*]' SPARK_EXECUTOR_MEMORY = '2g' SPARK_EXECUTOR_CORES = 2 SPARK_EXECUTOR_INSTANCES = 2 ENABLE_HIVE_SUPPORT = False HIVE_URL = "hdfs://hadoop:9000//user/hive/warehouse" HIVE_METASTORE = "thrift://hadoop:9083" def _create_spark_session(self): conf = SparkConf() config = ( ("spark.app.name", self.SPARK_APP_NAME), # 设置启动的spark的app名称,没有提供,将随机产生一个名称 ("spark.executor.memory", self.SPARK_EXECUTOR_MEMORY), # 设置该app启动时占用的内存用量,默认2g ("spark.master", self.SPARK_URL), # spark master的地址 ("spark.executor.cores", self.SPARK_EXECUTOR_CORES), # 设置spark executor使用的CPU核心数,默认是1核心 ("spark.executor.instances", self.SPARK_EXECUTOR_INSTANCES), ("spark.sql.warehouse.dir", self.HIVE_URL), ("hive.metastore.uris", self.HIVE_METASTORE), ) conf.setAll(config) # 利用config对象,创建 spark session 对象 if self.ENABLE_HIVE_SUPPORT: return SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate() else: return SparkSession.builder.config(conf=conf).getOrCreate()


