
Redis中的布隆过滤器
一、前言
Redis提供了HyperLogLog来解精确度不是很高的统计需求,相比set空间减少了很多,也更方便,但是HyperLogLog只是提供了pfadd添加元素,pfcount统计元素,基于HyperLogLog数据结构的实现,无法判断某个数是否存在与这个key中,故没有pfcontain这种指令一说。
举个栗子,当我们刷短视频时,会不停的给我们推荐视频,它每次推荐都需要进行去重,去掉那些我们已经看到过的视频,那么像人均一天刷100个视频/小时,这种数据该怎么去重了,
假如服务端记录每个人的浏览记录,需要查询时再从这个集合中过滤掉已经存在的记录,如果存在关系型数据库当中,每次进行大量的exists查询,存在缓存当中,假如每个人每天存一个key,用户量很大,数据量很大时,推荐的去重性能能跟的上么,存储空间会随着时间线性增长。
基于这种大数据量的去重问题,布隆过滤器(Bloom Filter)闪亮登场,它就是专门解决这种去重问题的,在去重的同时,存储空间可以减少90%以上,但是布隆过滤器也不是那么的准确,存在一定的误判率。

二、布隆过滤器介绍
布隆过滤器可以看成一个不怎么精确的set结构,当使用contains方法判断某个值是否存在时,它可能会误判,默认布隆过滤器实际上是一个很长的二进制向量或者位图和一系列的随机映射函数组成,初始状态,给定长度的位数组所有位置都位1。
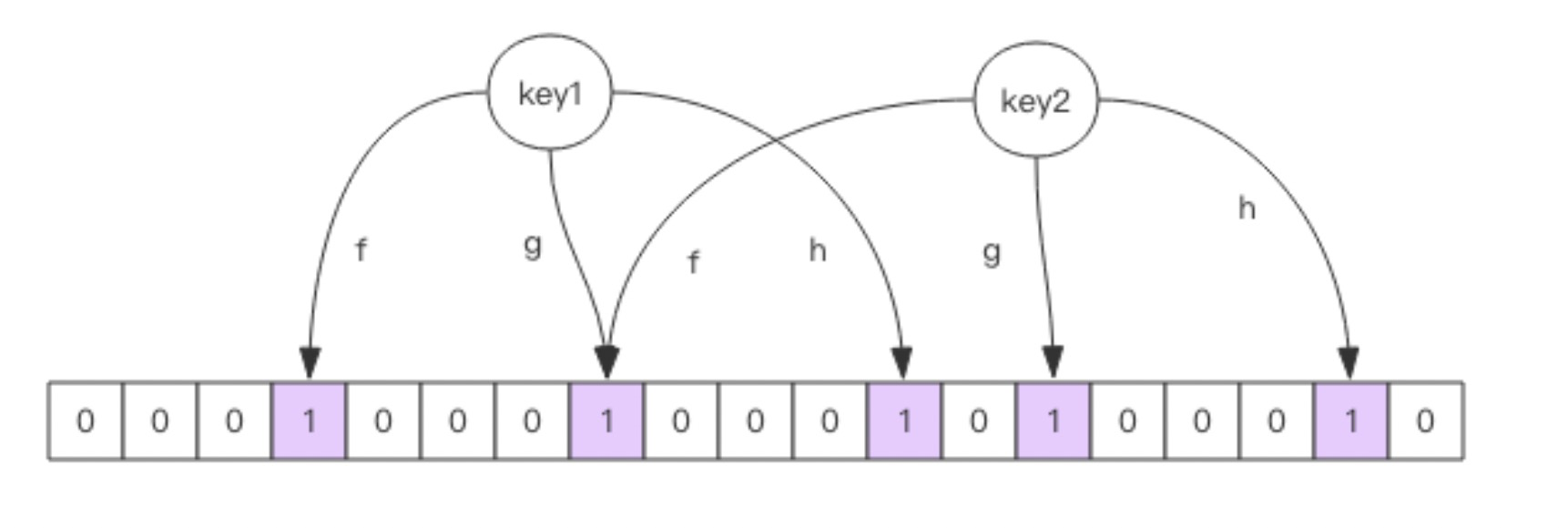
向布隆过滤器中添加元素时,会使用多个hash函数对元素算得一个整数索引值,然后对位数组进行取模运算得到一个位置,每个hash函数都会算得一个不同的位置,,再把位数组的这个位置设置为1,就完成了添加操作
- 将要添加的元素给k个哈希函数
2.得到位于位数组的k个位置
3.将位数组这k个位置设置为1
向布隆过滤器中查询是否存在某个元素时也一样,根据这些hash函数把这几个位置算出来,算完查看对应值是否为1,只要有一个位为0,那么说明这个元素一定不在布隆过滤器当中,如果所有位的值都为1,这并不能说明这个值一定存在,因为某个位置的1可能是其他元素hash运算出来的,所以会发生误判。因为不确定这个位的1是哪个元素产生并置为1的,(所以布隆过滤器没有删除操作,删除某个位的1可能导致其他元素不准确,增大了误判率)如果这个位数组比较稀疏,这个概率就会很大, 相反,如果这个位数组比较密集,这个概率就会很低
1.将要查询的元素给k个哈希函数
2.得到位于位数组的k个位置
3.判断k个位置是否全部位1,如果全部为1,可能存在,如果有一位为0,则一定不存在
布隆过滤器的优缺点:
一个事物不可能好的不得了,凡事都有优缺点,只是孰轻孰重由自己判读,布隆过滤器的优点在于相比其他数据结构,空间和时间都存在巨大优势,由于Redis的最开始是由位数字实现的,占用的空间可以很小,存储和查询的时间都位O(1),散列函数相互没有关系,方便由硬件并行实现,布隆过滤器并不需要存储元素本身,所以在需要相对保密的场合也有一定优势。
缺点:随着元素的增加,误算率会随之增加,在需要绝对精确的场合,以及小量数据情况下,不推荐使用布隆过滤器。
三、redis使用
Redis官方提供的布隆过滤器到了Redis4.0之后提供了插件功能之后正式登场,布隆过滤器作为一个插件加载到Redis server当中,给redis提供了强大的去重功能。
Docker安装:
https://hub.docker.com/r/redislabs/rebloom
docker pull redislabs/rebloom
docker run -p6379:6379 redislabs/rebloom
redis-cli
连接redis-cli我们查看当前已加载的模块module list
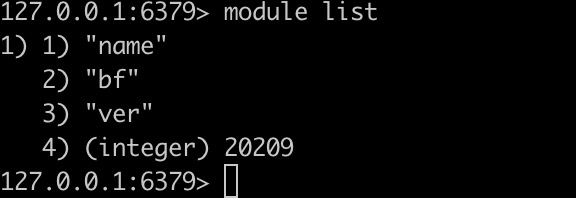
可以看到模块名为bf,版本号为20209
命令:
添加元素
bf.add key ...options...

返回值为1表示添加成功,bf.add一次只能插入一个元素,如果想插入多个,可以使用下面这个命令
bf.madd key ...options...

查询某个元素是否已经存在
bf.exists key ...options...

如果想一次性查询多个元素,使用下面的命令
bf.mexists key ...options...
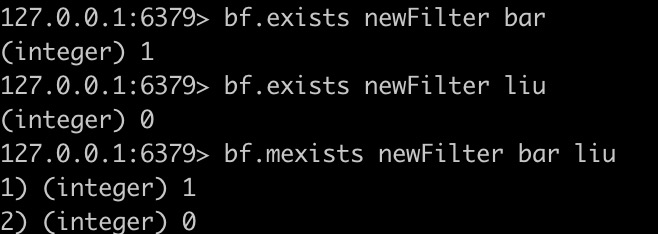
bf.info key [CAPACITY | SIZE | FILTERS | ITEMS | EXPANSION]
查看过滤器的信息
返回值
Capacity:预设容量
Size:实际占用情况
Number of filters:过滤器层数
Number of items inserted:已经实际插入的元素数量
Expansion rate:子过滤器扩容系数(默认为2)
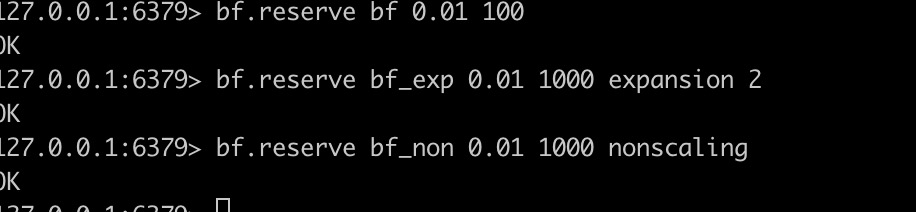
bf.reserve key error_rate capacity [EXPANSION expansion] [NONSCALING]
我们上面创建的过滤器的只是默认参数的过滤器,在我们第一次add的时候自动创建,布隆过滤器的误错率在所难免,但是当参数设置的合理,误错率可以降低很多,我们可以在第一次创建之前使用bf.reserve进行参数设置进行显式创建,如果之前的key存在,bf.reserve会报错,error_rate表示误错率,该值是介于0到1之间的十进制值,例如对于所需的误错率为0.1%(千分之一)error_rate对应的值为0.001,值越低,需要的存储空间越大,capacity表示预计需要放入的元素数量,当实际数量超出这个值时,误判率会上升。参数NONSCALING表示在超出capacity时不创建其他子过滤器,当达到容量时,过滤器会报错,EXPANSION表示超出capacity会创建一个子过滤器,新子过滤器的大小是最后一个子过滤器的大小乘以expansion,expansion的默认值为2.
布隆过滤器的capacity估计的太大,会浪费存储空间,估计的太小,就会影响准确率,在使用之前一定要估算好元素数量,还需要加上一定的冗余空间以避免实际元素数量比估计值高出很多,布隆过滤器的error_rate设置的越小,需要的存储空间就越大,对于不需要特别精确的场合,error_rate设置的稍微大点也无伤大雅,比如刷短视频的推荐,误判率高只会让一小部分视频不能让合适的人看到。
布隆过滤器有两个重要参数,第一个是预计需要添加的元素个数n,第二个是错误率f,公式根据这两个输入得到两个输出,第一个输出是位数组的长度,也就算需要存储空间的大小(bit),第二个是hash函数的最佳数量k,hash函数的数量也会直接影响到错误率,最佳的数量会降低错误率,
k=0.7*(l/n)
f=0.6185^(l/n)
1%的错误率需要7个哈希函数和每个元素10.08个bit
0.1%的错误率需要10个哈希函数和每个元素14.4bit
0.01%的错误率需要14个哈希函数和每个元素20.16bit
我们在使用时可以直接用现有的工具计算存储空间
https://krisives.github.io/bloom-calculator/

bf.debug key
这个命令在最新的官网上不知道为什么不见了,可能不建议我们使用这个指令,这个命令是查看BloomFilter的内部详细信息,(每层的元素数量,所占大小,哈希数,错误率等)

如果为我们往过滤器中添加1000个元素之后的信息,新建过滤器的时候都使用的是默认参数(容量100,扩容系数为2),实际添加进去的数量为994个
bytes 表示当前过滤器占用的字节数
bits 标签当前过滤器占用的bit数组大小(bit大小 bit = byte * 8)
hashes 该层的hash函数数量
hashwidth hash宽度
capacity 当前过滤器预计存放的容量(第一层为初始化容量,因为我们没有设置,所以默认为100,第二层的容量等于第一层的容量 * expansion)

虽然布隆过滤器可以自动扩容,但是建议我们保留估计的所需容量,因为维护和查询每个子过滤器需要额外的内存,并且比创建时具有正确容量的等效过滤器需要消耗更多的CPU时间,
size 该过滤器中已经插入的元素个数,各个过滤器size总和等于Number of items inserted
ratio 该过滤器的错误率,(第一层的错误率为BloomFilter初始化时的错误率 * 0.5,第二层为第一层的0.5倍,以此类推)
四、spring项目中使用
这里主要总结spring或者springboot项目中redis支持布隆过滤器,首先redis-server需要安装布隆过滤器,连接客户端不管是jedis还是redisTemplate都没有封装布隆过滤器的使用,这里使用StringRedisTemplate作为客户端连接,连接池使用JedisPool,由于RedisTemplate没有封装,那我们在项目当中借助Lua脚本自己封装一个。
redis:
bloom:
host: 127.0.0.1
port: 6379
timeout: 200
pool:
max-idle: 10
min-idle: 2
max-wait: 100
max-active: 100
当我们需要使用布隆过滤器时,可以使用bloomRedisTemplate,
package com.example.bloomfilter.config;
import org.checkerframework.checker.nullness.qual.Nullable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.data.redis.core.script.RedisScript;
import java.util.Arrays;
import java.util.Collection;
import java.util.List;
import java.util.stream.Collectors;
/**
* redis操作布隆过滤器基本命令
* @author liufuqiang
*/
public class BloomRedisTemplate extends StringRedisTemplate {
private static final Logger logger = LoggerFactory.getLogger(BloomRedisTemplate.class);
private static final RedisScript<String> BF_RESERVE_SCRIPT =
new DefaultRedisScript<>("return redis.call('bf.reserve', KEYS[1], ARGV[1], ARGV[2])", String.class);
private static final RedisScript<Boolean> BF_ADD_SCRIPT =
new DefaultRedisScript<>("return redis.call('bf.add', KEYS[1], ARGV[1])", Boolean.class);
private static final RedisScript<Boolean> BF_EXISTS_SCRIPT =
new DefaultRedisScript<>("return redis.call('bf.exists', KEYS[1], ARGV[1])", Boolean.class);
private static final RedisScript<List> BF_MULTI_ADD_SCRIPT =
new DefaultRedisScript<>("return redis.call('bf.madd', KEYS[1], ARGV[1])", List.class);
private static final RedisScript<List> BF_MULTI_EXISTS_SCRIPT =
new DefaultRedisScript<>("return redis.call('bf.mexists', KEYS[1], ARGV[1])", List.class);
public <T> T execute (RedisScript<T> script, String key, Object... args) {
return super.execute(script, Arrays.asList(key), args);
}
/**
* 创建布隆过滤器
* @param key key值
* @param errorRate 错误率
* @param capacity 预计放入元素数量
* <a href="https://redis.io/commands/bf.reserve/">BF.RESERVE</a>
* @return
*/
public boolean reserve(String key, double errorRate, int capacity) {
checkArgument( errorRate > 0, "errorRate (%s) must be > 0.0", errorRate);
checkArgument(errorRate < 1.0, "errorRate (%s) must be < 1.0", errorRate);
checkArgument(capacity > 0, "capacity (%s) must be >= 0", capacity);
try {
execute(BF_RESERVE_SCRIPT, key, String.valueOf(errorRate), String.valueOf(capacity));
return true;
} catch (Exception e) {
logger.error("bf reserve error {}", e.getMessage());
return false;
}
}
/**
* 添加元素
* @param key key值
* @param value 需要添加的值
* @return
*/
public boolean add(String key, String value) {
return execute(BF_ADD_SCRIPT, key, value);
}
/**
* 查看元素是否存在
* @param key key值
* @param value 需要判断的值
* @return
*/
public boolean exists(String key, String value) {
return execute(BF_EXISTS_SCRIPT, key, value);
}
/**
* 批量添加元素
* @param key key值
* @param values 需要添加的值
* @return
*/
public List<Integer> multiAdd(String key, Collection<String> values) {
return execute(BF_MULTI_ADD_SCRIPT, key, values.stream().collect(Collectors.joining(" ")));
}
/**
* 批量判断是否存在
* @param key key值
* @param values 需要判断的值
* @return
*/
public List<Integer> multiExists(String key, Collection<String> values) {
return execute(BF_MULTI_EXISTS_SCRIPT, key, values.stream().collect(Collectors.joining(" ")));
}
private static void checkArgument(boolean b, @Nullable String errorMessageTemplate, @Nullable Object p1) {
if (!b) {
throw new IllegalArgumentException(String.format(errorMessageTemplate, p1));
}
}
}
package com.example.bloomfilter.config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;
import org.springframework.data.redis.core.StringRedisTemplate;
import redis.clients.jedis.JedisPoolConfig;
/**
* @author liufuqiang
*/
@Configuration
public class RedisConfig {
@Value("${redis.bloom.host}")
private String host;
@Value("${redis.bloom.port}")
private Integer port;
@Value("${redis.bloom.timeout}")
private Integer timeout;
@Value("${redis.bloom.pool.min-idle}")
private Integer minIdle;
@Value("${redis.bloom.pool.max-idle}")
private Integer maxIdle;
@Value("${redis.bloom.pool.max-active}")
private Integer maxActive;
@Value("${redis.bloom.pool.max-wait}")
private Integer maxWaitMillis;
@Bean(name="bloomJedisPoolConfig")
public JedisPoolConfig bloomJedisPoolConfig(){
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(maxIdle);
jedisPoolConfig.setMaxWaitMillis(maxWaitMillis);
jedisPoolConfig.setMaxTotal(maxActive);
jedisPoolConfig.setMinIdle(minIdle);
return jedisPoolConfig;
}
@Bean(name="stringRedisTemplate")
public StringRedisTemplate stringRedisTemplate(JedisPoolConfig bloomJedisPoolConfig){
StringRedisTemplate stringRedisTemplate = new StringRedisTemplate();
JedisConnectionFactory jedisConnectionFactory = new JedisConnectionFactory(bloomJedisPoolConfig);
jedisConnectionFactory.setTimeout(timeout);
jedisConnectionFactory.setHostName(host);
jedisConnectionFactory.setPort(port);
jedisConnectionFactory.afterPropertiesSet();
stringRedisTemplate.setConnectionFactory(jedisConnectionFactory);
return stringRedisTemplate;
}
@Bean(name = "bloomRedisTemplate")
public BloomRedisTemplate bloomRedisTemplate(JedisPoolConfig bloomJedisPoolConfig){
BloomRedisTemplate bloomRedisTemplate = new BloomRedisTemplate();
JedisConnectionFactory jedisConnectionFactory = new JedisConnectionFactory(bloomJedisPoolConfig);
jedisConnectionFactory.setTimeout(timeout);
jedisConnectionFactory.setHostName(host);
jedisConnectionFactory.setPort(port);
jedisConnectionFactory.afterPropertiesSet();
bloomRedisTemplate.setConnectionFactory(jedisConnectionFactory);
return bloomRedisTemplate;
}
}
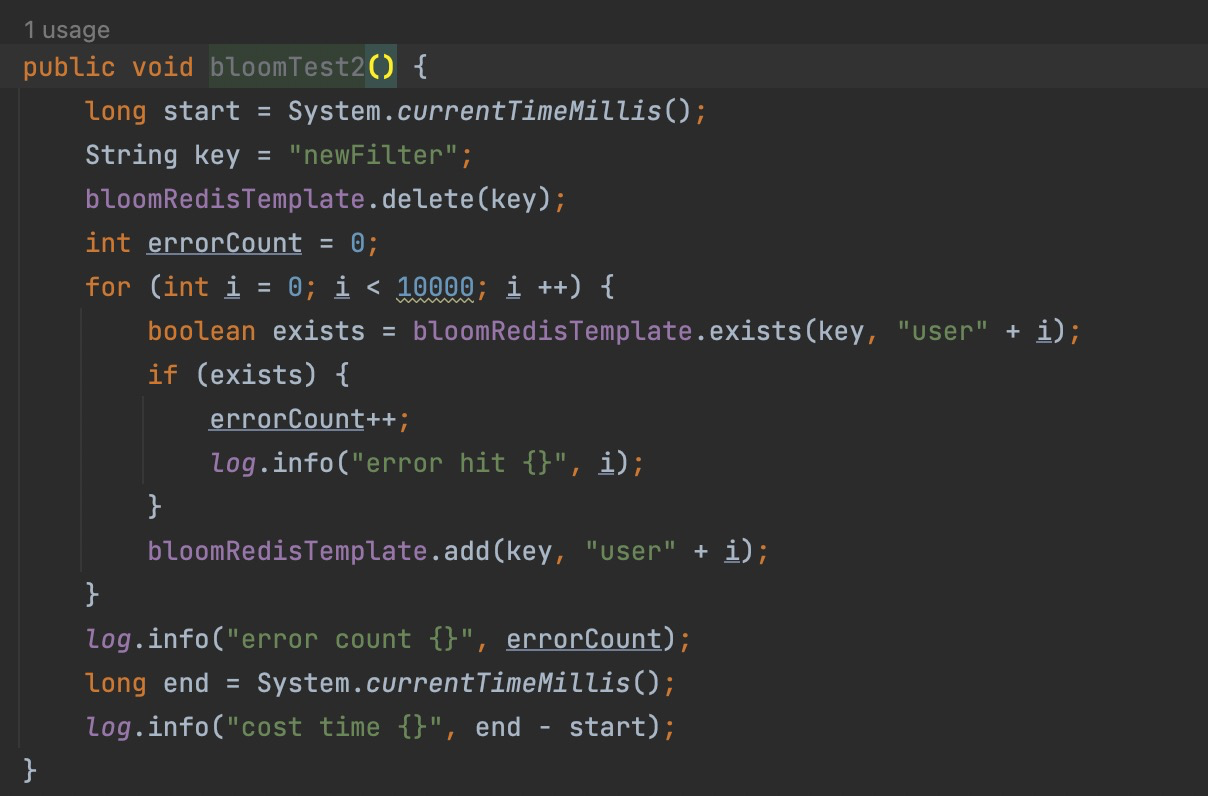
有了上面的封装,我们现在可以很方便的操作redis的布隆过滤器,我们可以简单写个脚本进行测试错误率与性能


我们可以往newFilter中添加10000个值进行测试,可以看到花费了20多秒,但是我们在代码25行判断是否存在这个元素,可以看到BloomFIlter竟然都认识这些元素,添加10000个元素,竟然一个误判的都没有,原因就在于布隆过滤器对于已经见过的元素肯定不会误判

通过输出的信息我们可以看到,添加10000个元素,实际插入了9911个元素,并且新建了6个子过滤器,可以看到默认参数的过滤器插入10000个元素就已经占了大约30K,
所以下面我们改动一下


可以看到输出为93个误判的元素,错误率为0.0093左右,这个是默认参数的,所以我们接下来改动一下脚本
我们利用封装的方法调用bf.reserve命令,错误率为0.01,初始化容量大小为20000,往里面插入10000个元素
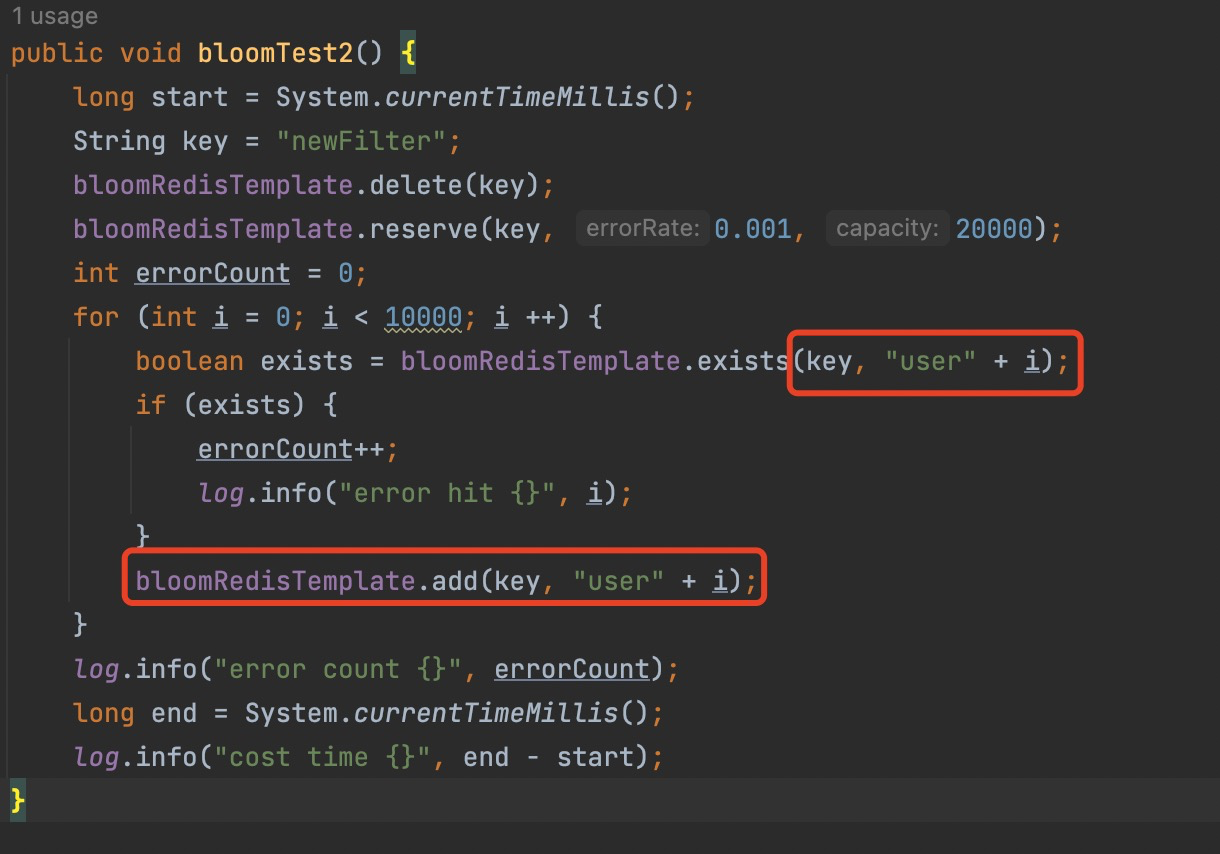
因为判断元素是否存在在前面,添加元素在后面,bloomFilter对于未见过的元素可能会存在误判

通过输出可以看到最终在10000个元素里面误判了3个

并且只创建了一个过滤器,10000个元素占用了大约14k,错误率比我们预计的要低很多。只要不比误判率高,都是正常现象。
五、Google中Guava布隆过滤器
如果用不了redis的布隆过滤器,并且不需要分布式,我们可以使用Google开源的Guava自带的布隆过滤器,用现有的轮子,会用之后再弄懂
Guava是一个开源的Java库,由google开源,安全,可靠,有效的扩展java标准库,里面已经造了轮子,现在大多数项目应该都引用了
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
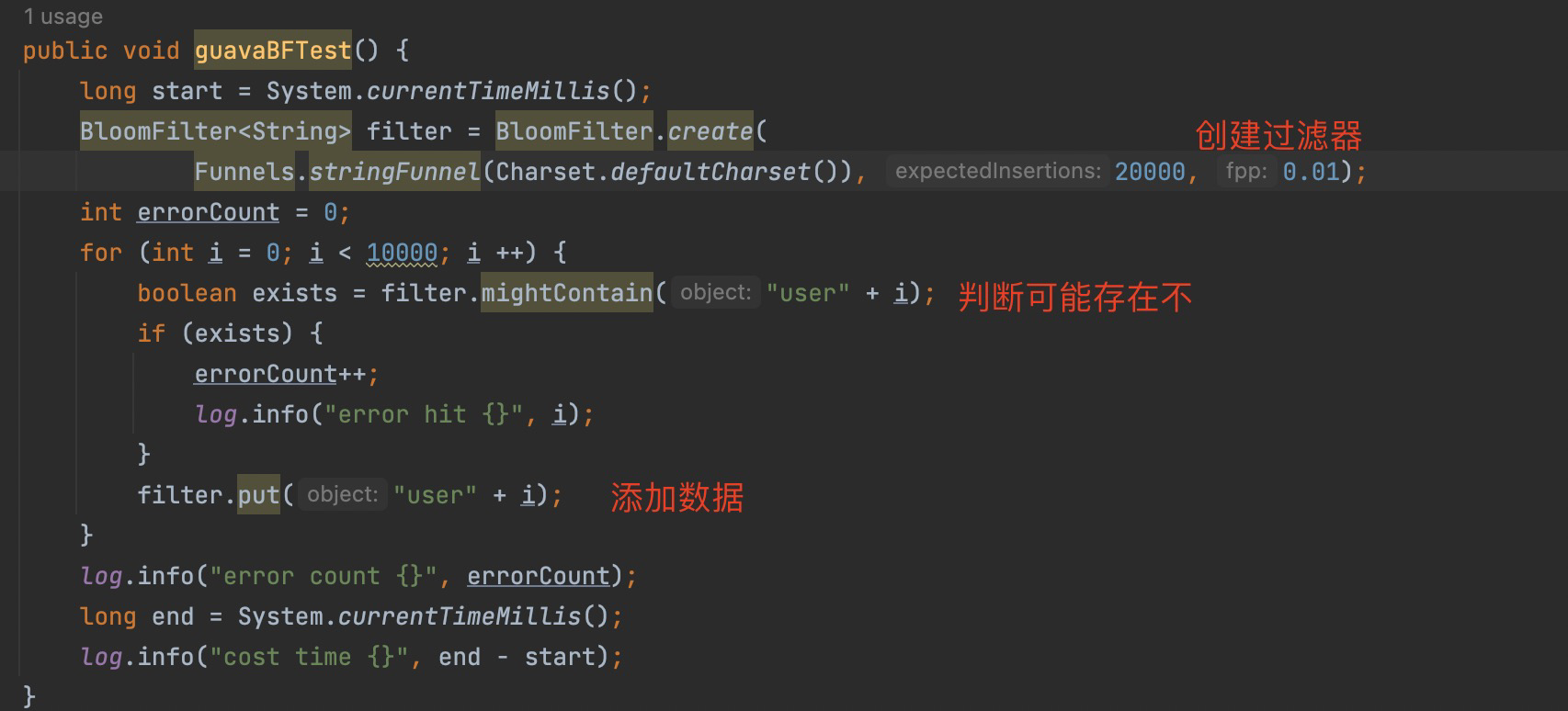
新建测试类,试了好几次,10000个元素错误大概14个左右

当然时间上肯定比redis的快不少,因为redis通过客户端的连接池进行添加数据,查找数据(实际使用中的数据大多数是固定的,可以使用pf.madd命令封装的方法批量添加数据,来减少IO次数,一定程度上来说可以减少很多时间),总体而言,都在容错率范围之内,各有千秋,但是,因为是java库里面生成的,基于JVM内存中的过滤器,无法持久话,重启服务数据全部丢失,也无法存储大量的数据,单个jvm进程,所以无法在分布式系统当中使用这个布隆过滤器;不管是插入查找速度效率高,
redis中的布隆过滤器使用,可以持久化数据,不存在重启失效或者需要定时维护,可以分布式系统中使用;每次操作都需要网络IO,性能相对较差。
测试案例及RedisTemplate调用Lua脚本操作BloomFilter已上传至GitHub
https://github.com/LiuFqiang/bloom-filter.git
参考文档
https://redis.io/commands/?name=bf.
https://blog.csdn.net/yzf279533105/article/details/110877817
《Redis深度历险——核心原理与应用实践》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号