
ElasticSearch聚合之桶聚合(Bucket Aggregation)
概览
聚合介绍
ElasticSearch主要提供了三种常用的聚合类型,桶聚合(Bucket Aggregation),指标聚合(Metric Aggregation)和管道聚合(Piple Aggregation)
ElasticSearch中桶的概念类似于SQL的分组(GROUP BY),而指标聚合,类似于SQL的COUNT()、SUM()、MIN()、MAX()等
- 桶(Buckets)满足特定条件的集合
- 指标(Metric)对桶内的文档进行计算
这里看到官方文档光Bucket Aggregation就已经33中了,所以按照使用的次数总结一些经常使用的排序
但是不管哪种聚合类型,大致结构都是下面这个类型,
DSL语句
{
"aggs": {
"agg1": {
"terms": {
"field": "user_name.keyword",
"size": 10
}
},
"agg2": {
"terms": {
"field": "topic_id.keyword",
"size": 10
}
}
}
}
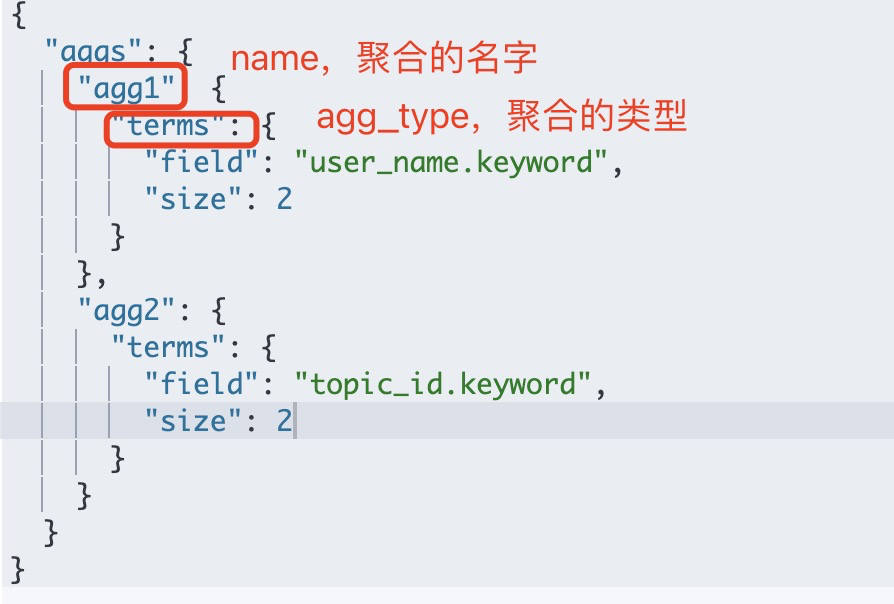
agg为简写,也可以写成aggregations,其中name为这个聚合的名字,供聚合结果取数据时使用,agg_type为自己根据需要的聚合类型
返回结果

返回结果aggregations为整个map结构,key值为聚合时自己设置的name,value为根据聚合类型之后的结果,每个聚合类型不相同
terms聚合
基本语法
GET /_search
{
"aggs": {
"genres": {
"terms": { "field": "genre" }
}
}
}
返回结果
{
...
"aggregations": {
"genres": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "electronic",
"doc_count": 6
},
{
"key": "rock",
"doc_count": 3
},
{
"key": "jazz",
"doc_count": 2
}
]
}
}
}
这里以ElasticsearchRestTemplate的api为例java代码实现如下
public void termsAggregations() {
final String aggName = "terms-agg";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.termsQuery("status", "normal"));
TermsAggregationBuilder agg =
terms(aggName).field("user_name.keyword").size(3).order(BucketOrder.count(false));
NativeSearchQuery query = queryBuilder.withQuery(boolQueryBuilder)
.addAggregation(agg)
.withPageable(PageRequest.of(1, 0))
.build();
SearchHits<TopicDTO> search = esRestTemplate.search(query, TopicDTO.class);
Aggregations aggregations = search.getAggregations();
ParsedTerms aggregation = aggregations.get(aggName);
List<? extends Terms.Bucket> buckets = aggregation.getBuckets();
}
其中doc_count_error_upper_bound为聚合失败的文档个数
sum_other_doc_count为buckets结果的补集文档个数,随聚合参数size变化
buckets为聚合结果,key为聚合时的field,doc_count为聚合个数
参数介绍
size
默认为根据doc_count排序由大到小的10条数据,如果需要一次返回更多的聚合结果,可以调整size大小,但是这个结果不能用于分页,没有页数的限制,只能返回条数大小
order
默认为doc_count降序排序,参数可以为聚合之后的_key或者_count,排序类型可以为asc或者desc
即

注意这里如果同时存在_key和_count排序,只生效最下面的一条排序规则
于此同时,更复杂的,可以根据聚合之后的buckets内再一次借助指标聚合的结果进行排序(ordering by a sub aggregation)
比如上面我根据帖子的例子,根据每个用户的发帖数进行聚合,现在排序我想通过帖子的回复数来进行排序,回复数最高的在前面

其中子聚合的排序前置条件为根据用户名user_name.keyword关键字聚合;也可以通过聚合标识来对桶内进行排序,上述聚合排序也可以写为
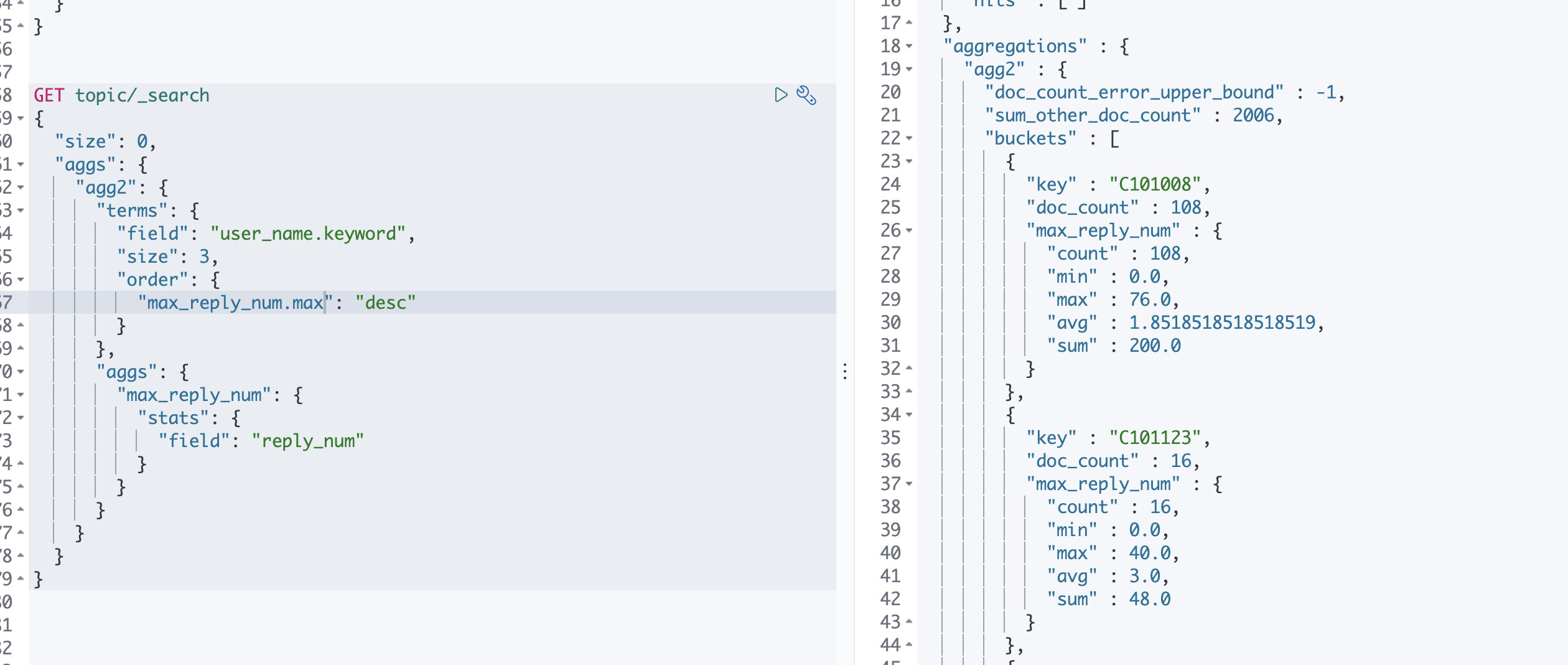
其中子聚合为指标聚合,留着以后再有时间总结...
min_doc_count
min_doc_count可以对聚合之后的doc_count进行过滤,返回超过匹配个数的文档个数

需要返回发帖超过400条的
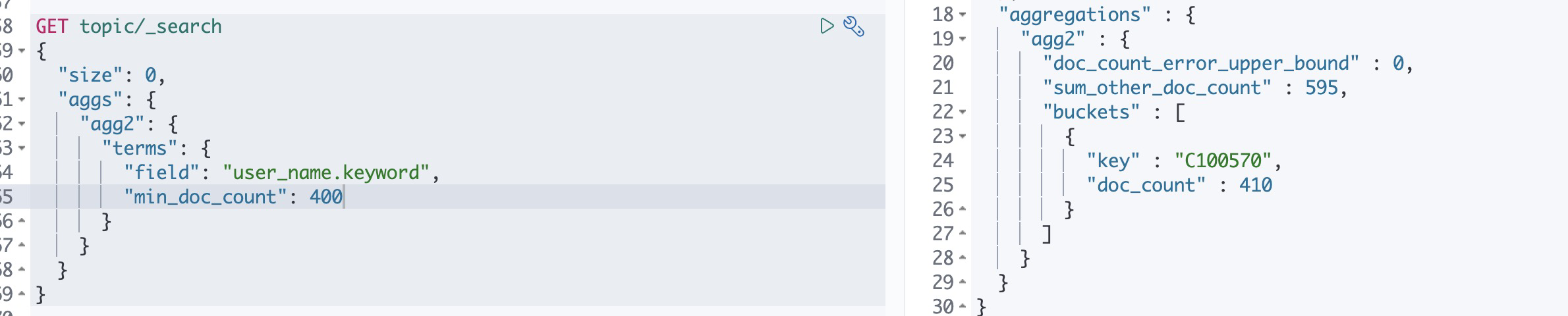
只有一条满足
script
当然,也可以自己自定义脚本啦,如果需要聚合的字段在文档中没有,或者聚合的条件为好几个字段,可以使用script自定义

filter聚合
介绍
前置条件的过滤,在当前的文档集合上下文中定义一个匹配指定过滤器的所有文档bucket,通过用于减小当前聚合上下文到一组特定的文档上
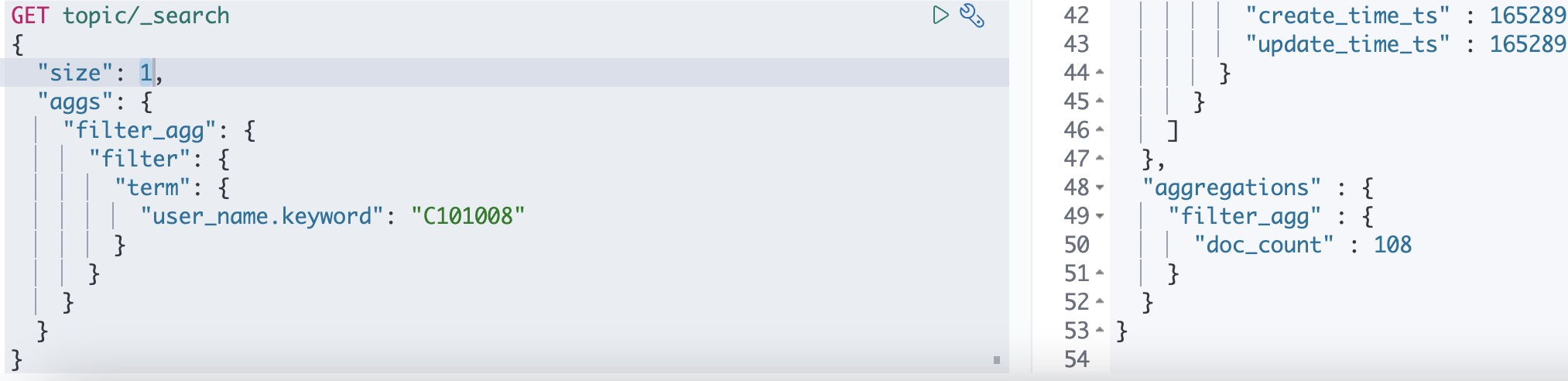
通常用于需要返回查询结果的hits,但是也需要在查询的结果当中取子集来进行聚合,即当前聚合的集合属于查询的结果集,如果不需要返回查询结果集,只需要特定条件的聚合结果,可使用term聚合
上述聚合也可以写为
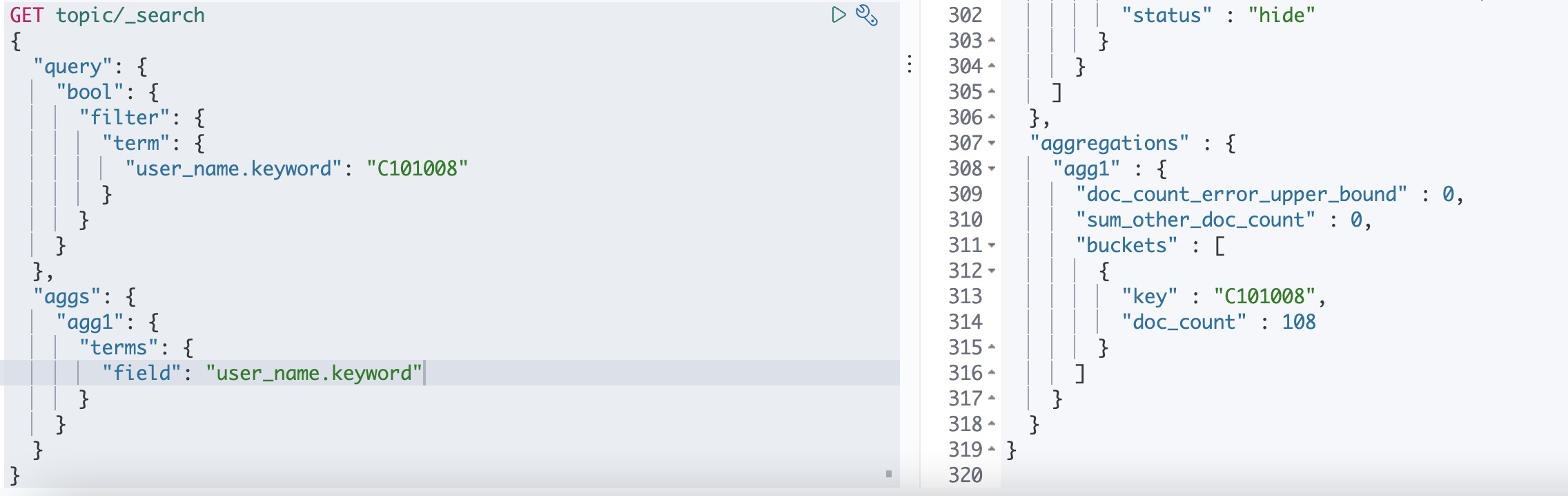
当然下面的filter查询之后再聚合可以直接用上面的替代
filters聚合
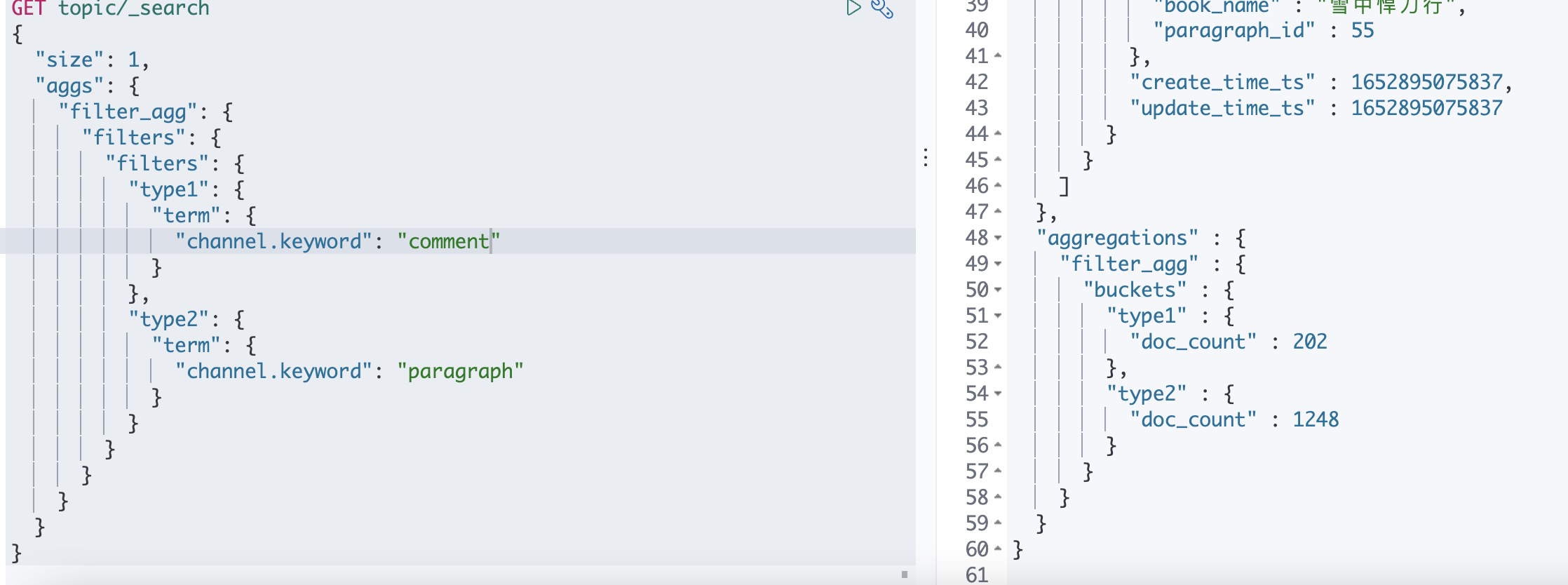
定义多个bucket聚合,每个bucket于一个过滤器匹配,每个bucket收集匹配相关的文档
这里比如帖子类型,有很多种类型,但是只想要"comment"和"paragraph"两种类型的聚合结果,可以使用filters聚合定了两个聚合桶来实现
Range聚合
对Number类型的聚合,基于多桶值源的聚合,使用户能够定义一组范围,聚合之后每个范围代表一个桶,在聚合过程中,将从每个存储范围中检查从每个文档提取的值,并"存储"
相关/匹配的文档,需要注意的是,这个range为半闭半开区间 [form, to)
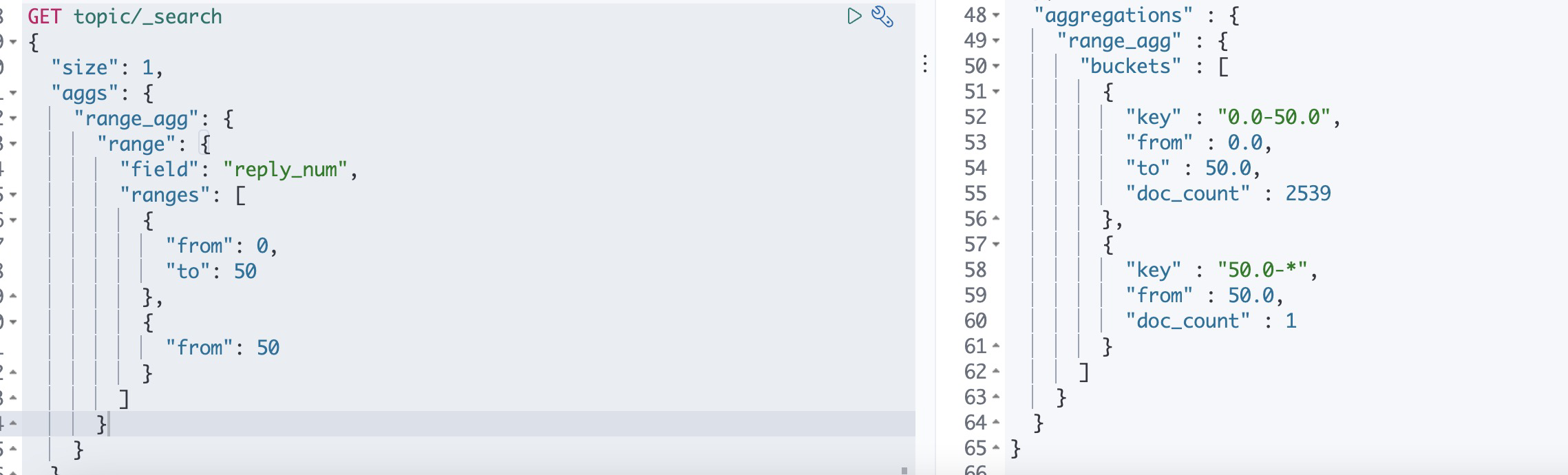
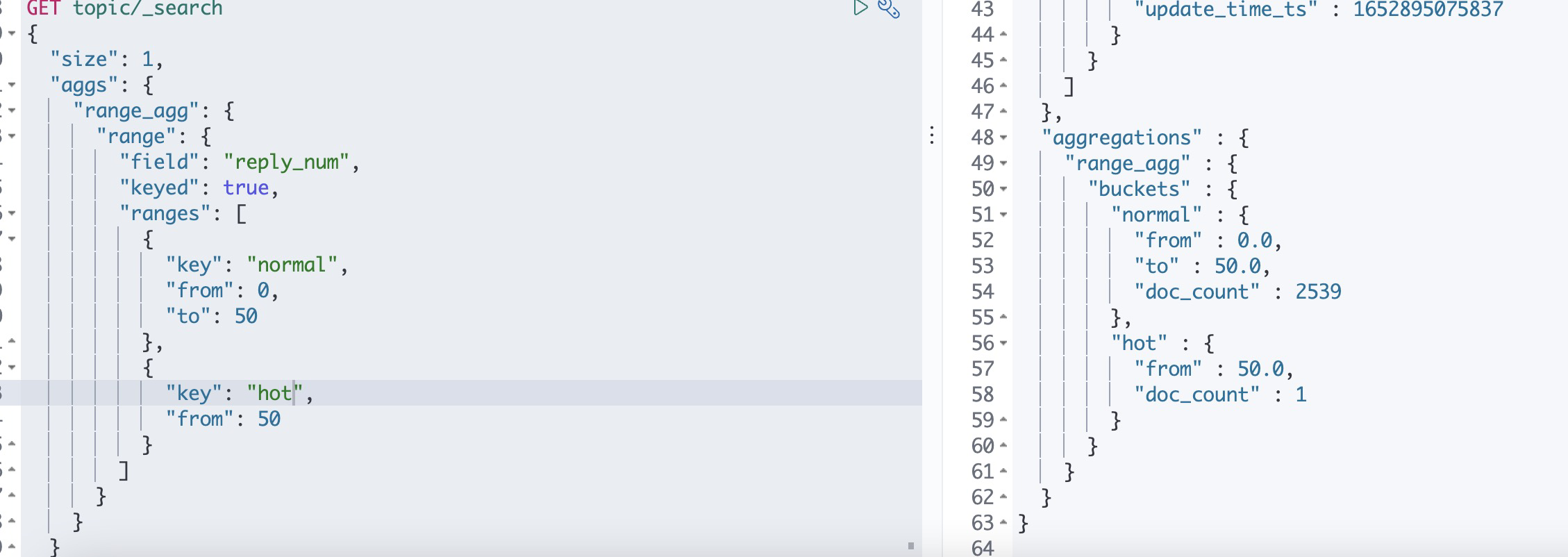
这里定义了两个桶根据帖子的回复数聚合,[0, 50)区间一个桶,[50, +∞)一个桶,聚合的key为from和to范围动态生成的唯一字符
参数介绍
keyed
默认为false,可以看到上述返回的结果为根据聚合的from和to生成的key和from、to、doc_count对象组成的List集合,添加参数keyed将返回为散列hash结构,将使一个唯一的字符串key与一个bucket关联
并将范围作为hash返回

ranges.key
我们发现根据from和to生成的key类似"0.0-50.0"、"50.0-*"这样的key为hash结构时不好获取返回的结果,所以可以传入自定义唯一key来获取返回结果,
参考文档
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号