南京大学 静态软件分析(static program analyzes)-- Pointer Analysis Context Sensitive 学习笔记
一、Introduction(Example)
首先用一个例子直观地说明上下文不敏感分析的问题所在
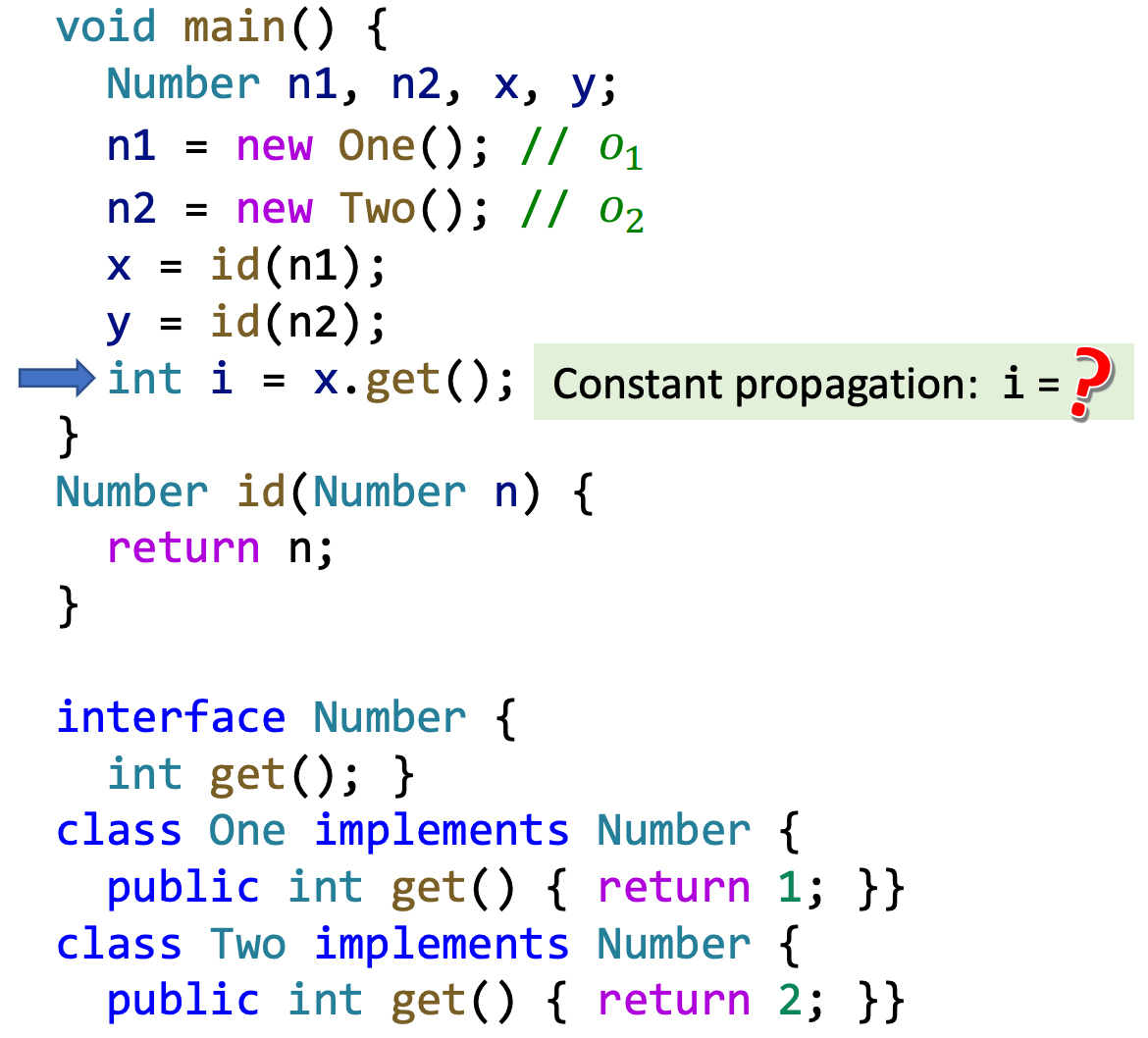


以上例子中,程序在实际执行时,i的值是1;而使用之前的PTA算法中,由于id函数的返回值n可能流向x和y,而o1和o2都可能流向n,导致i的分析结果为{1,2}(常量分析的NAC),因此产生误报。
久其本质,是因为上下文不敏感时,不同的callsite调用同一个方法时,会将它们聚合起来,导致误报。
上下文敏感是如何解决过度传递导致的误报问题的?

 在上下文敏感分析中,在PTA中是对传入的参数进行区别。每出现一个新的上下文调用点,就clone一个相应的变量并标记(行数:变量名)。
在上下文敏感分析中,在PTA中是对传入的参数进行区别。每出现一个新的上下文调用点,就clone一个相应的变量并标记(行数:变量名)。
二、Introduction(Theory)
C.I.(Context Insensitive)
是什么原因导致了上下文不敏感分析的低精度?
- 在动态执行时,对同一个函数的不同调用,往往有着不同的调用上下文(calling contexts),如上一小节的例子中两次对id的调用。
- 不同的调用上下文会被混合并传播,进而形成假的数据流。如上一小节的例子中指针x和y指向两个目标。

C.S.(Context Sensitive)
上下文敏感分析通过区分不同调用上下文的数据流,对调用上下文建模。
The oldest and best-known context sensitivity strategy is call-site sensitivity (call-string), Which represents each context of a
method as a chain of call sites, i.e.,
- a call site of the method,
- a call site of the caller,
- a call site of caller of caller, etc.
(abstract call stacks in dynamic execution)
举个例子,在这一段代码中,对id调用的上下文就是两行call-site,记为[1]和[2]:

进而,我们可以通过对同一函数的不同调用添加标号进行区分,而得到更精确的PFG。
Cloning-Based Context Sensitivity
The most straightforward approach to implement context sensitivity.

Context-Sensitive Heap
面向对象程序(如Java)会频繁修改堆对象,称为heap-intensive(堆密集)。
如果不采用上下文敏感的堆抽象,在处理New语句时,不同上下文创建的对象无法区分(因为每个New语句只对应一个抽象)。堆抽象指对创建对象的抽象。此外,为了进一步提高精度,还需要对堆抽象(对象)添加上下文。
以下面代码举一个例子,

不做标记时,第八行new出来的对象无法区分,只能同一记作

通过对heap进行上下文敏感标记后,可以分别记为3:o8和4:o8,这里标号3和标号4代表不同的heap context。



此外,需要注意的是,上下文敏感和堆敏感要同时使用,才能保证精度,如果仅仅采用堆敏感而不采用上下文敏感,则无法提高精度,

三、Context Sensitive Pointer Analysis: Rules
Domains and Notations
Domain中,methods/variables/objects都升级为带有上下文标识的。

- 引入C表示所有的上下文组成的集合
- c表示具体的某个上下文
值得一提的是,fields不需要带有上下文标记,因为field总是依赖于某一个object。只要object被标记进而通过上下文可被区分了,fields自然也可以被区分。
Rules
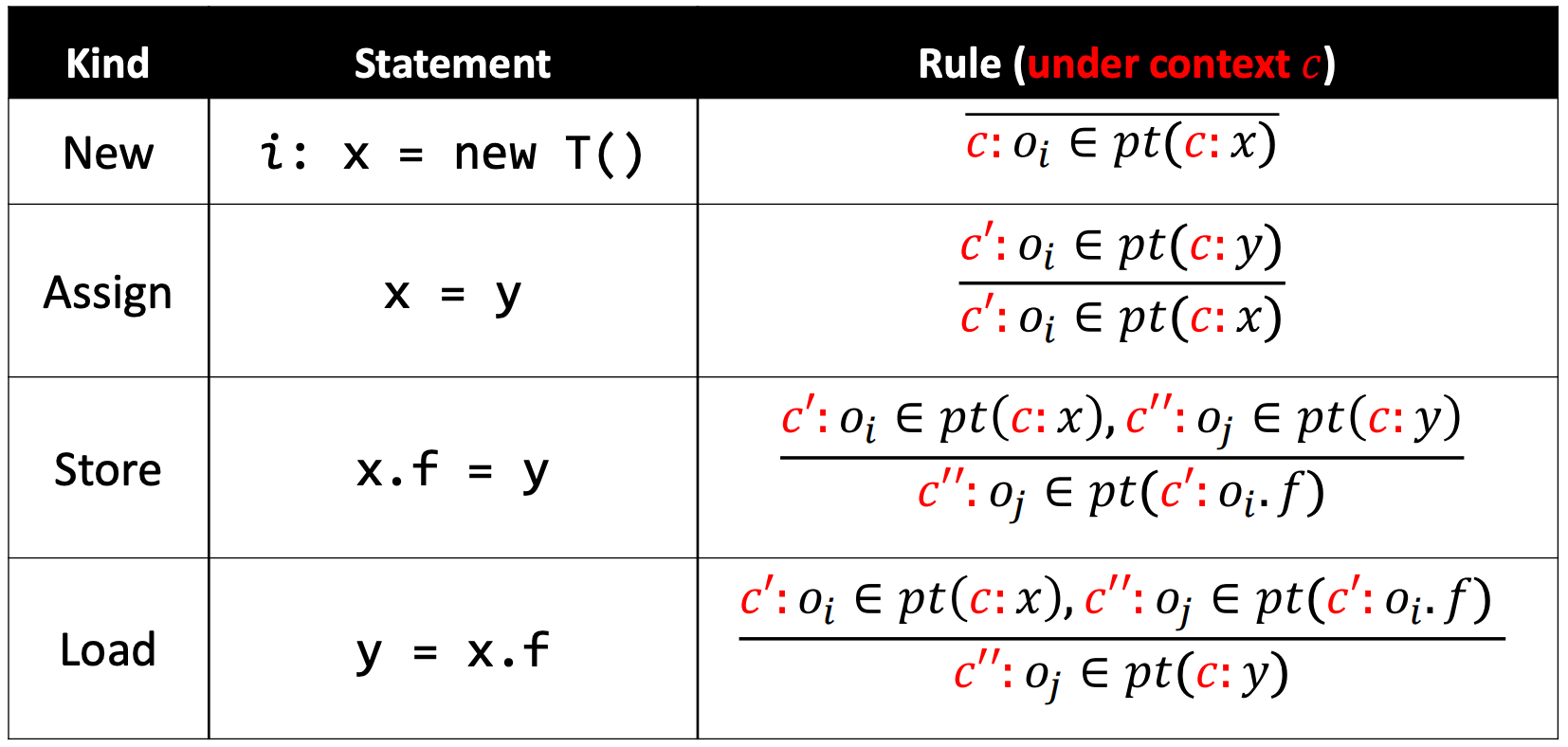
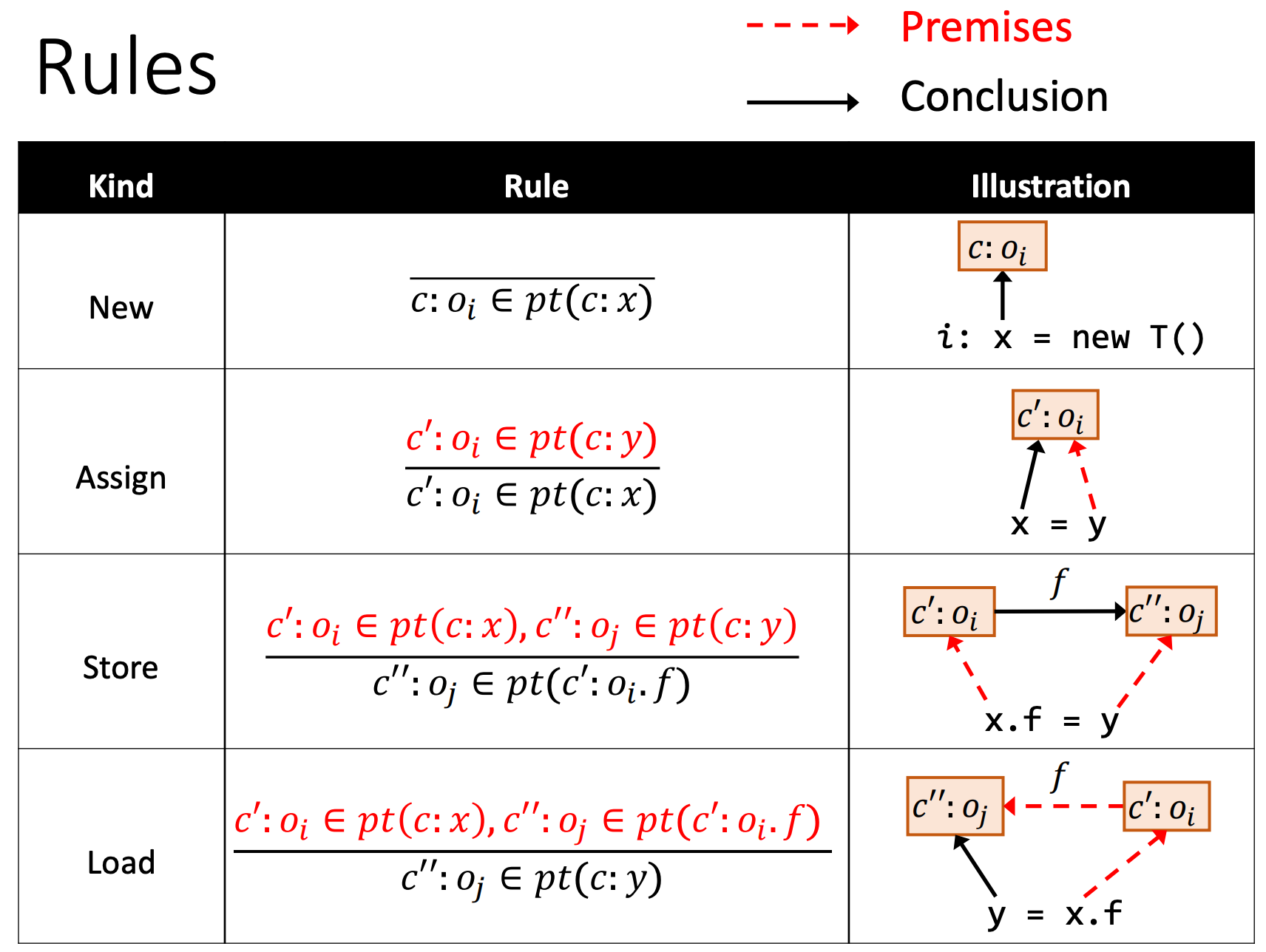

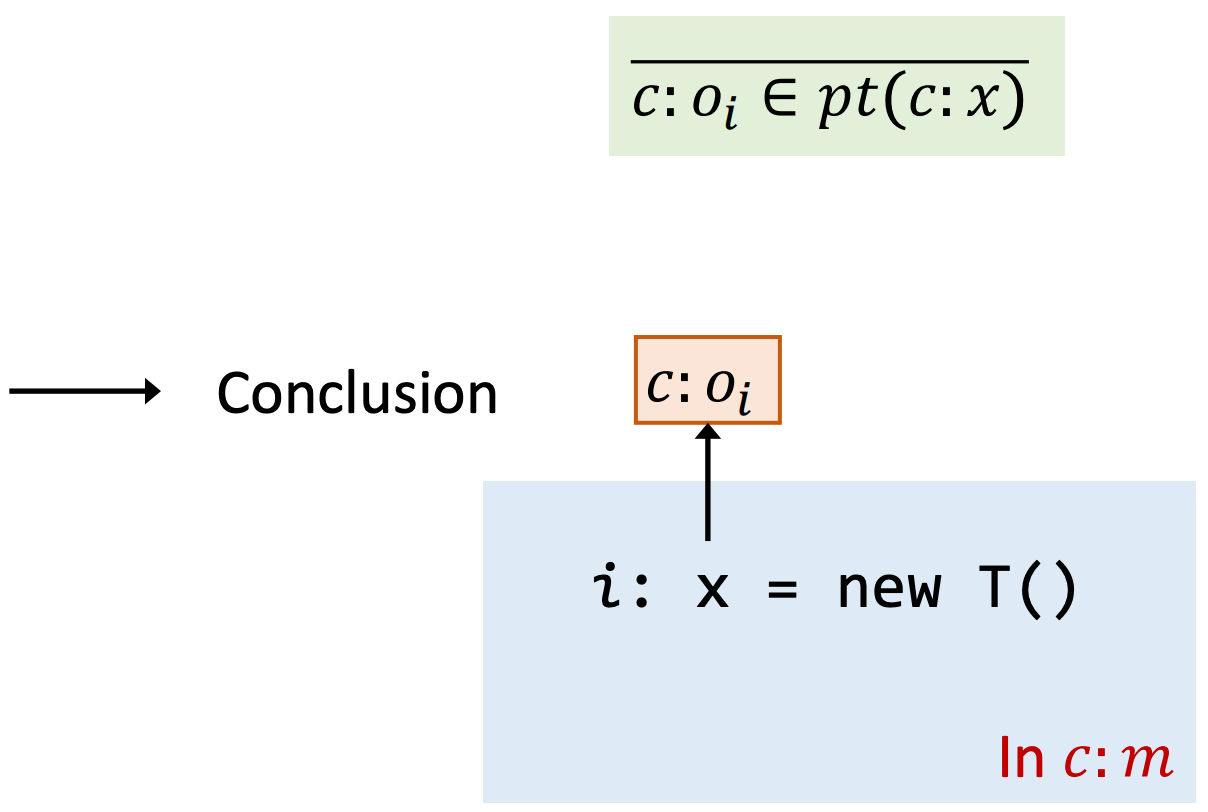
Rule: New
Rule: Assign
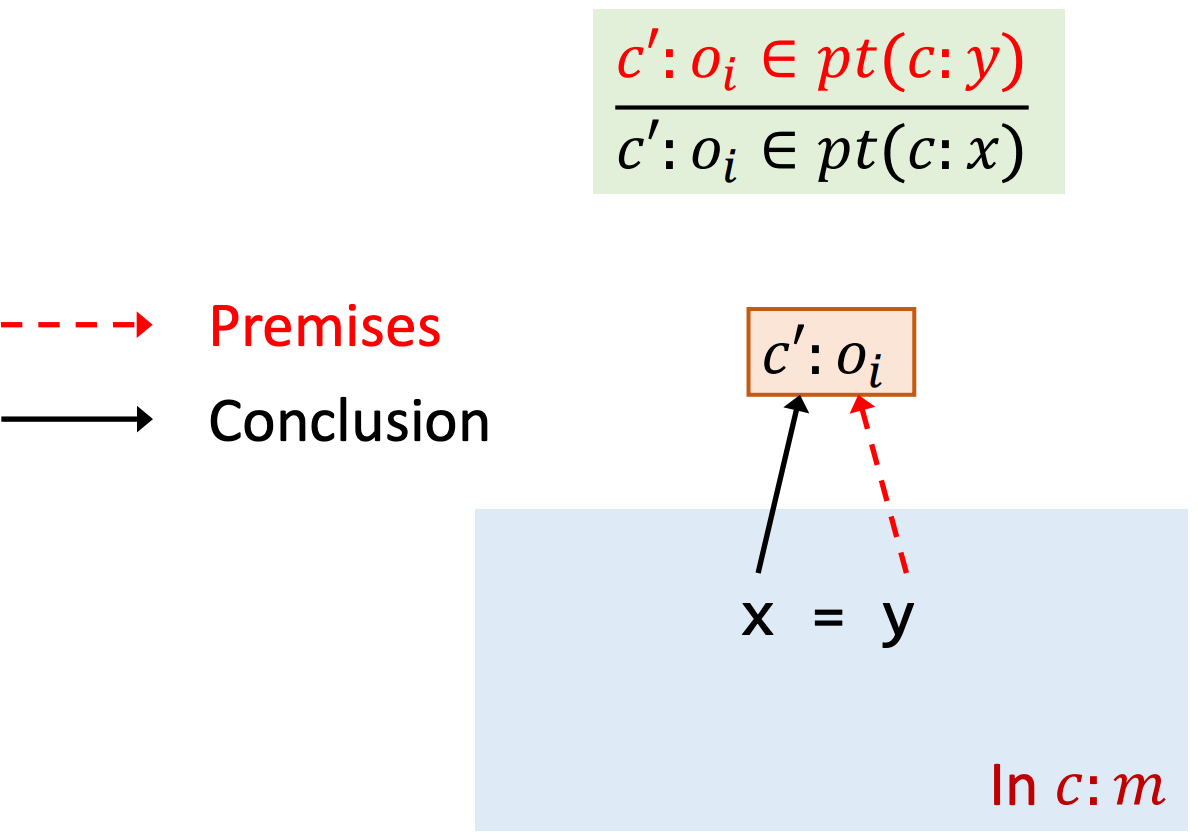
Rule: Store
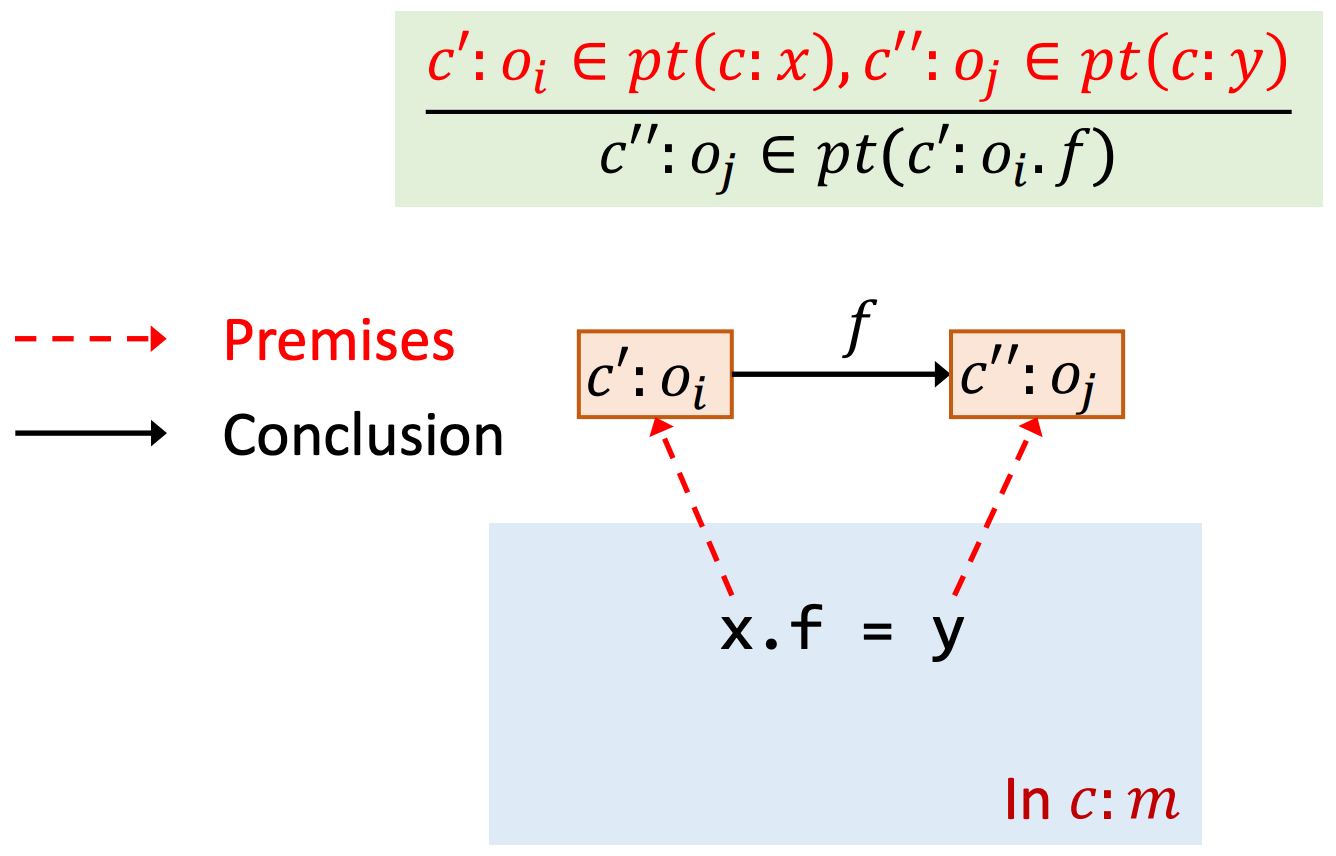
Rule: Load
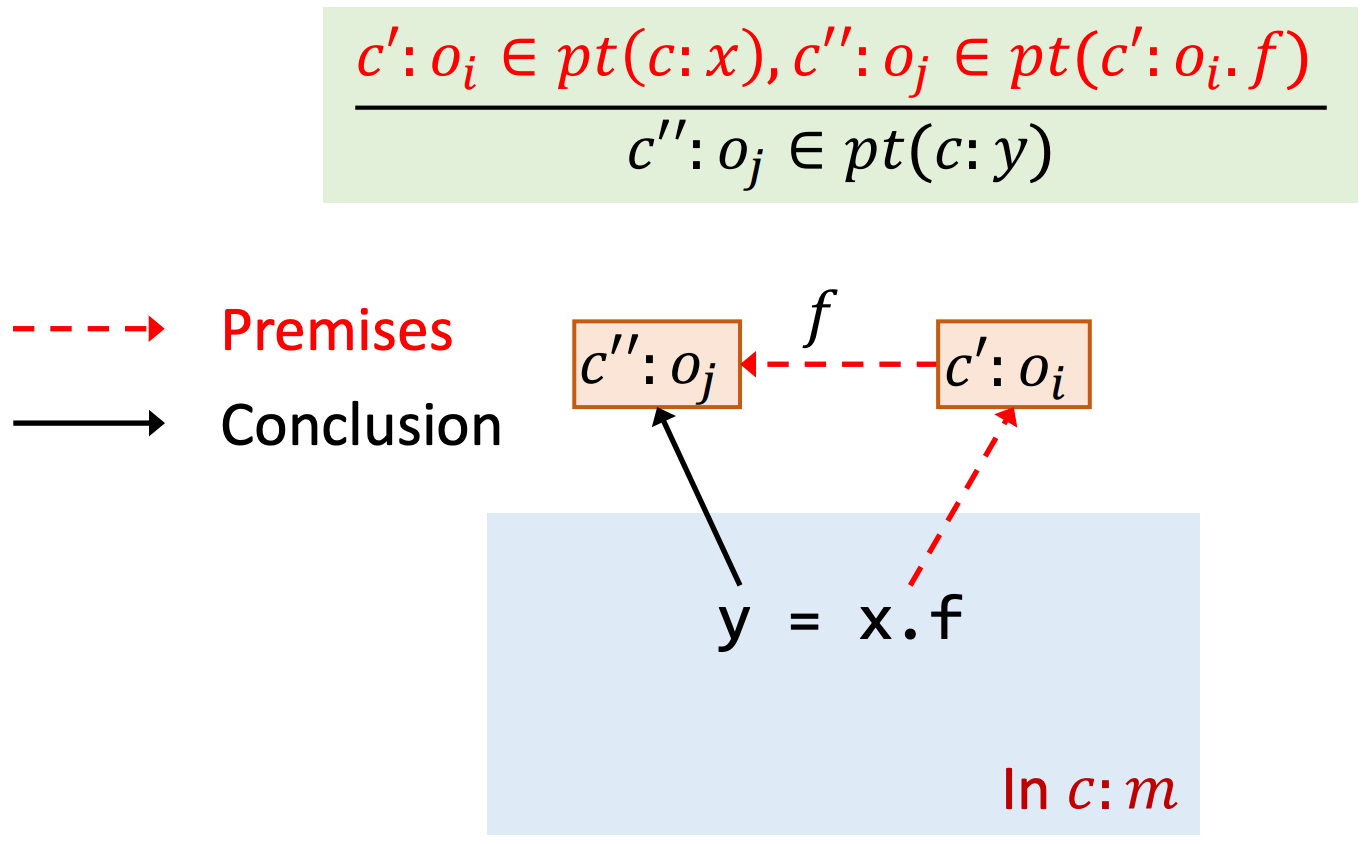
Rule: Call
相比上下文不敏感的PTA分析,对象被增加了上下文标识,

同时,上下文敏感分析增加了一个select函数,它的作用是为object添加上下文标识,例如:
为参数添加上下文标识:

为返回值添加上下文标识:

可以看到,上下文的信息是在处理调用时添加的。
四、Context Sensitive Pointer Analysis: Algorithms
Idea
和context-insensitive pointer analysis相比,除了PFG做了相应改进之外,算法的总体思路没有改变。

具体来说,带有上下文信息的Node和Edge的构成带有上下文信息的PFG:



An Example
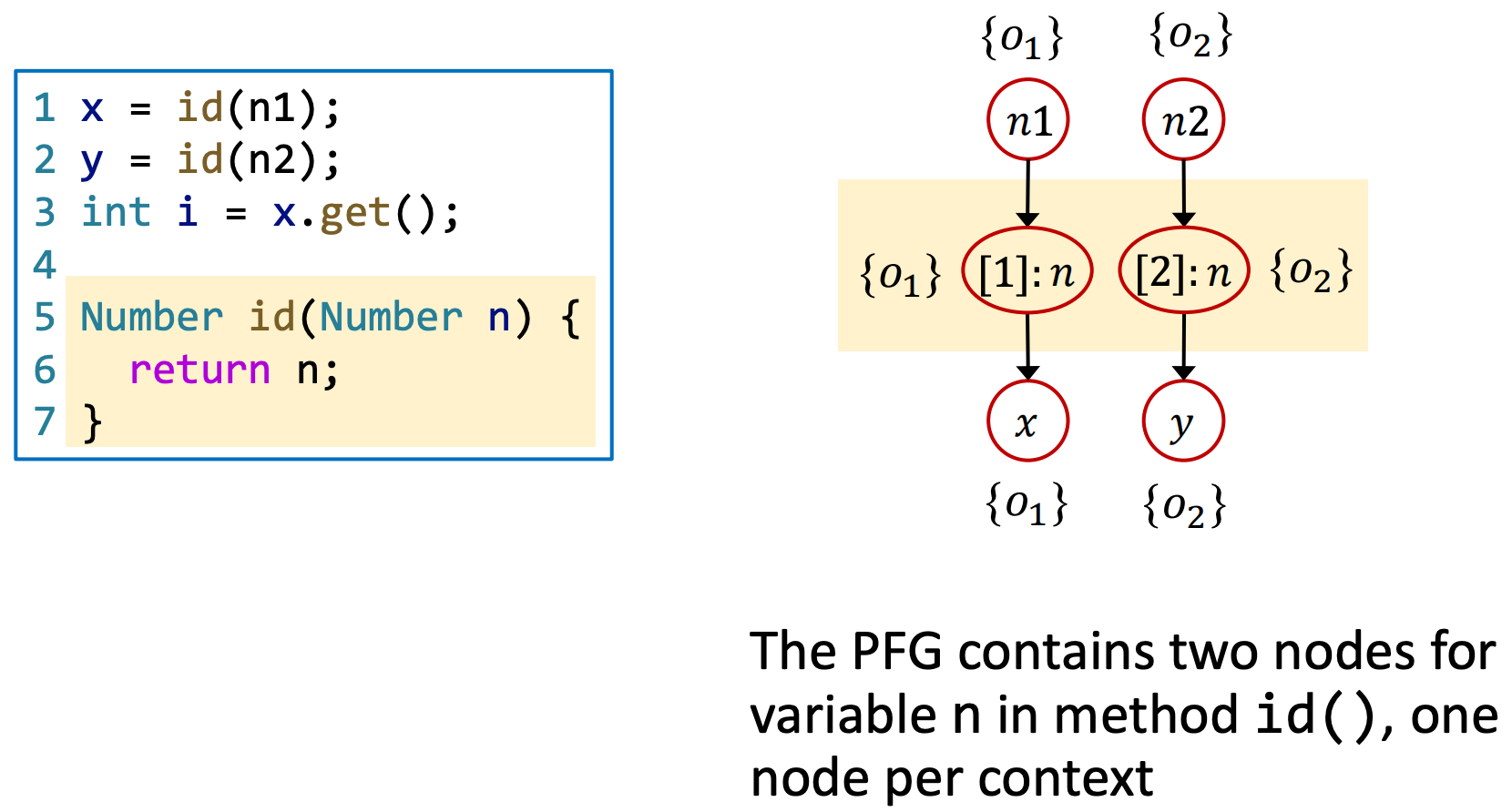
C.S. Pointer Analysis: Algorithm
完整算法如下:

可以看到,上下文敏感(C.S.)是在上下文不敏感(C.I.)指针分析算法的基础上,增加了上下环境c,以及上下文环境选择(select)的过程,我们下面来分析它。
在接下来的内容中我们更关注和上下文相关的部分,而不会详细地关注所有细节。
值得一提的差异是,RM和CG两个集合在本节所述的上下文敏感算法中都是带有上下文信息的。举个例子,在C.S.的分析中,caller和callee都带有上下文信息(ct代表callee的上下文标记,c:2->ct:… c^t:…表示第二行的caller调用了带有ct标记的callee):

AddReachable和AddEdge过程和C.I.是类似的,区别仅在于增加了上下文c,


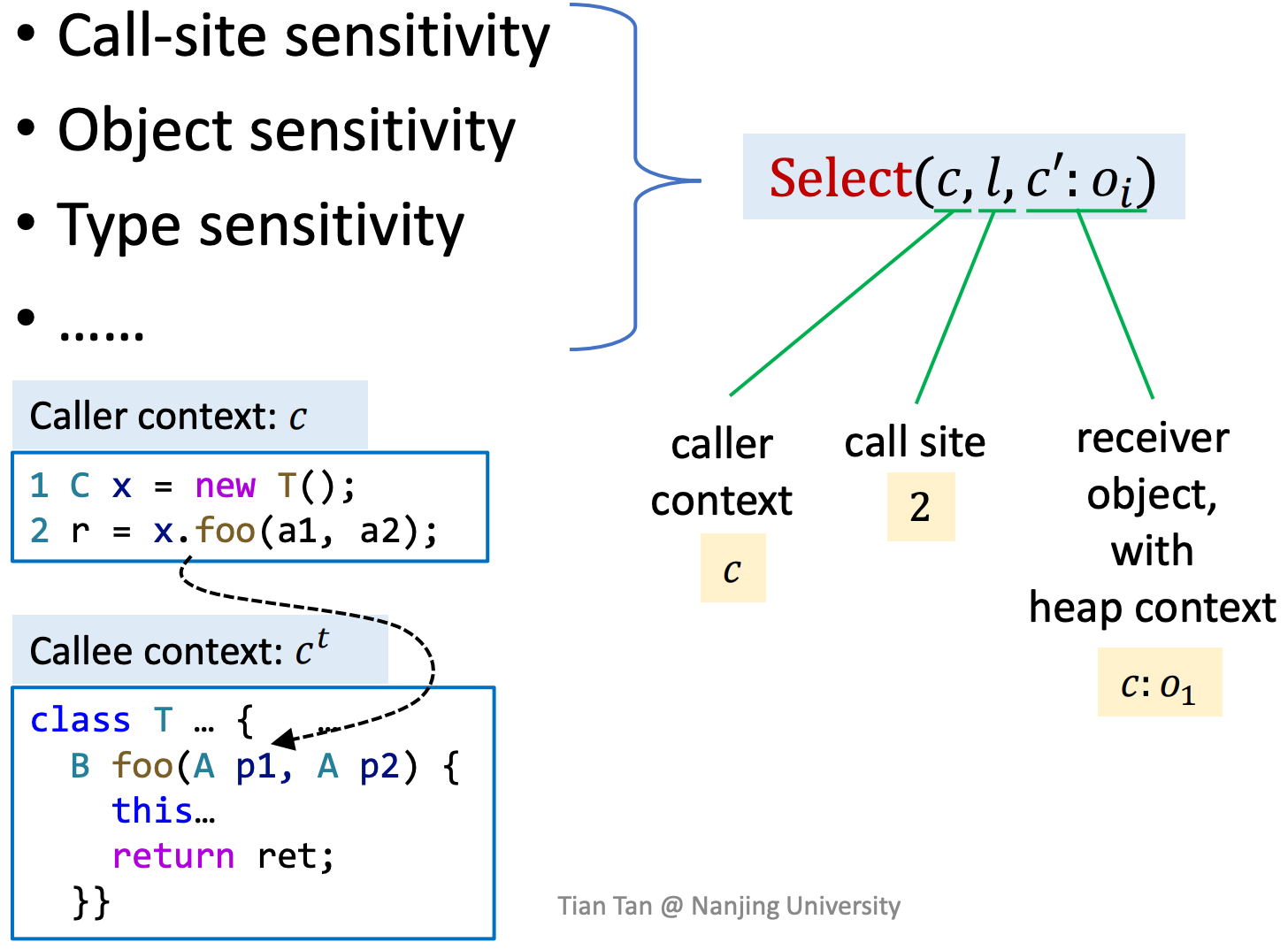
重点关注一下select过程,在ProcessCall中,在进行指针传递之前,需要先决定目标上下文ct,

- ProcessCall接收两个参数,意义是:带有上下文标记的x新增一个带有上下文标记指向目标o。
- m代表目标方法。
- Select接收参数(这里虽然有3个参数,但并非每种实现方式都需要用到所有的3个参数)
- c:x的上下文标记
- l:调用点本身(call site),在例子中以行号标识调用点
- c':oi:receiver object
- Select返回callee的context ct
这里要注意的是,C.I.可以视为C.S. 的一种特殊情况,无论传递给Select的参数是什么,总是返回同样的上下文。即:Select(*,*,*) = []
五、Context Sensitivity Variants
这一章我们来重点分析一下select,对于上下文敏感指针分析来说,Select函数实现时的具体差异,产生了不同的上下文敏感分析的变种方法,
- Call-site sensitivity
- Object sensitivity
- Type sensitivity
- ……
它们有不同的优缺点,
Call-Site Sensitivity
1、k-call-site sensitivity

举一个例子,

如果存在递归,则会产生无数个上下文,此时需要限制递归深度为k。所以叫k-CFA。k-CFA中,只取最后k个上下文(相同的会合并起来,这里比较特别,是从后往前数k个来决定),通常取k<=3。

一般的,函数的上下文通常取2,堆上下文通常取1。处理递归时,如果上下文出现与上一个上下文重复,则停止此处的分析。

还是上面的例子,如果改为”1-call-site“,则有,

2、1-Call-Site: Example
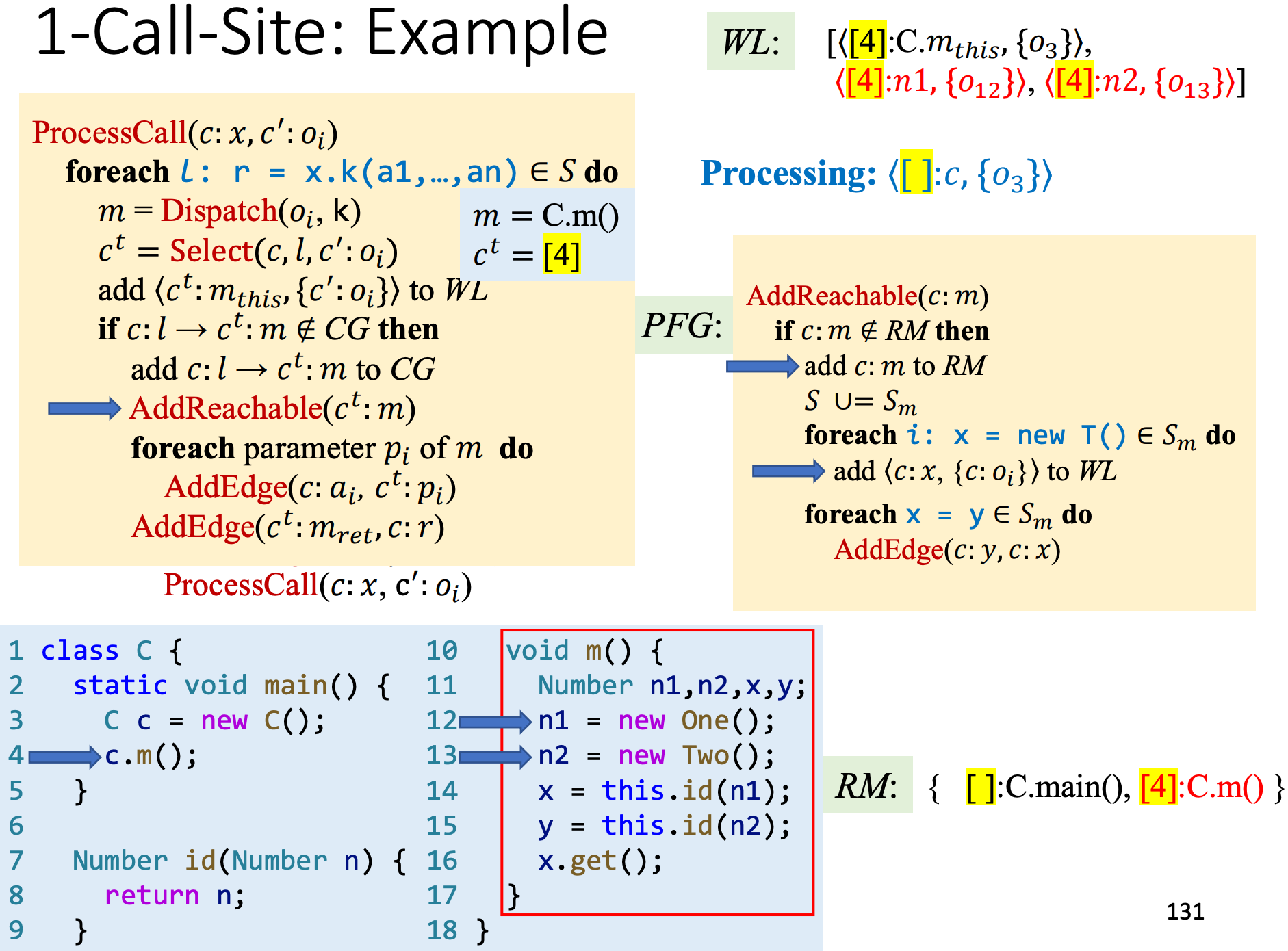
我们用1-Call-Site分析一个例子,看看指针流图PFG和调用关系图CG的结果。

将main函数添加到reachable world中,

开始处理WL,因为是从main进来的,当前caller的上下文还是[],空集


开始处理ProcessCall,c.m()对应caller的context为[4],


建立callsite和callee之间的CG和,并将this加入WL,

开始处理m()里的逻辑,并将C.m()加入reachable world,
开始处理this.id()调用,注意这里14行和15行的this分别处于[14]和[15]的上下文中,
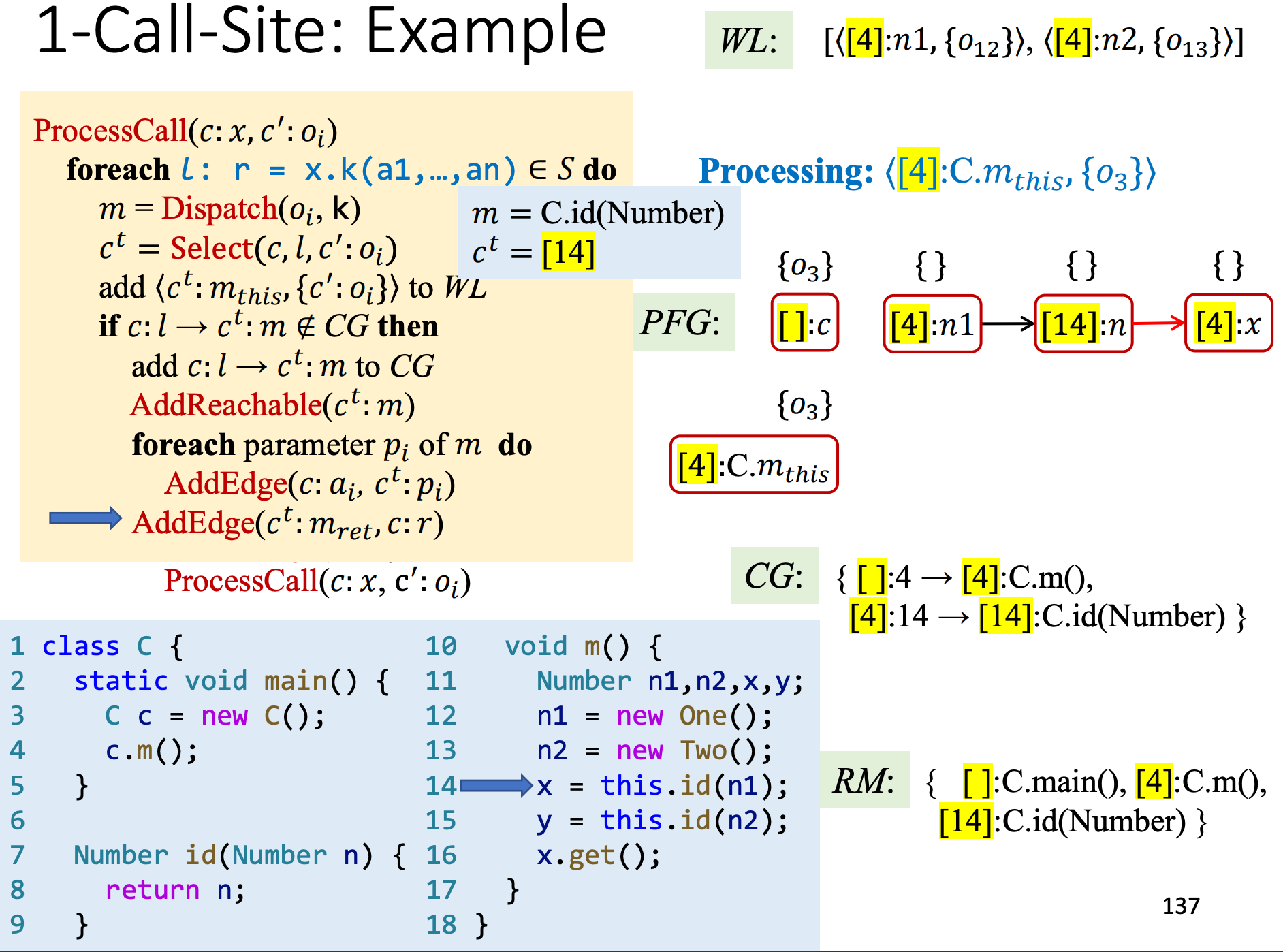
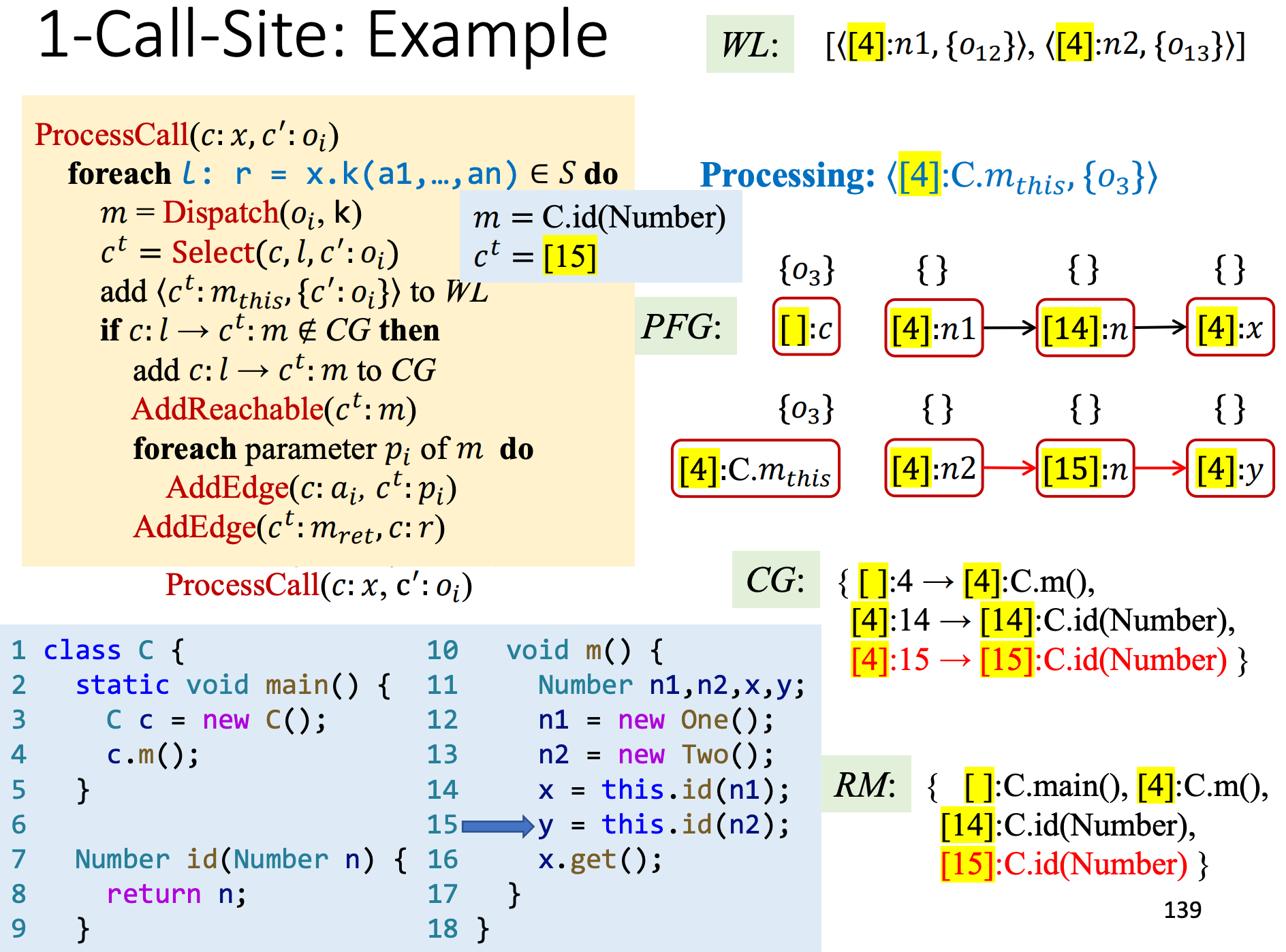
对n1和n2的指针对象进行传递,
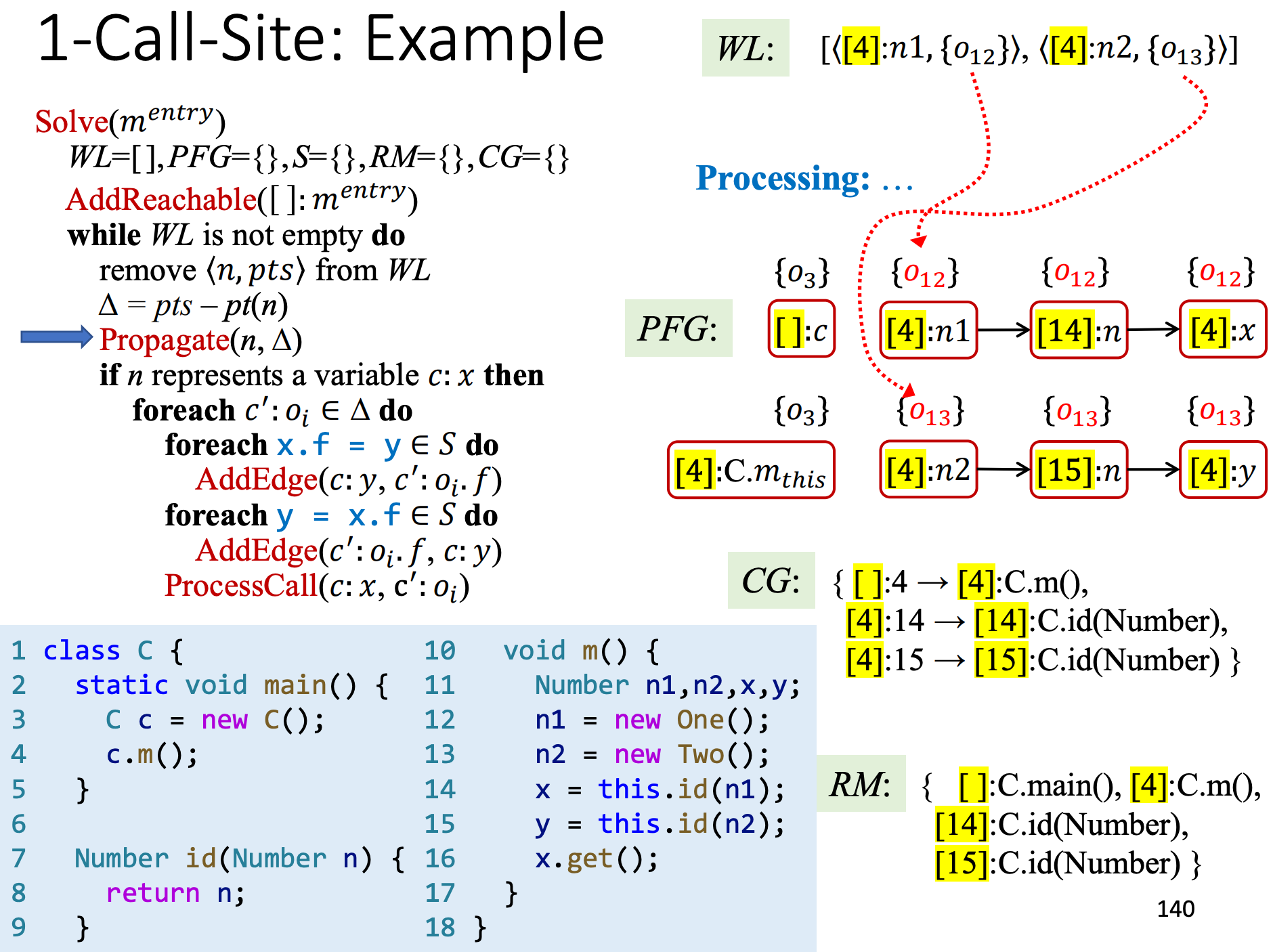
处理x.get()函数调用,注意,在1-call-site条件下,caller的context为[16],这里只有一个函数调用,不涉及返回值赋值处理,x.get()指向的对象是哦o12,
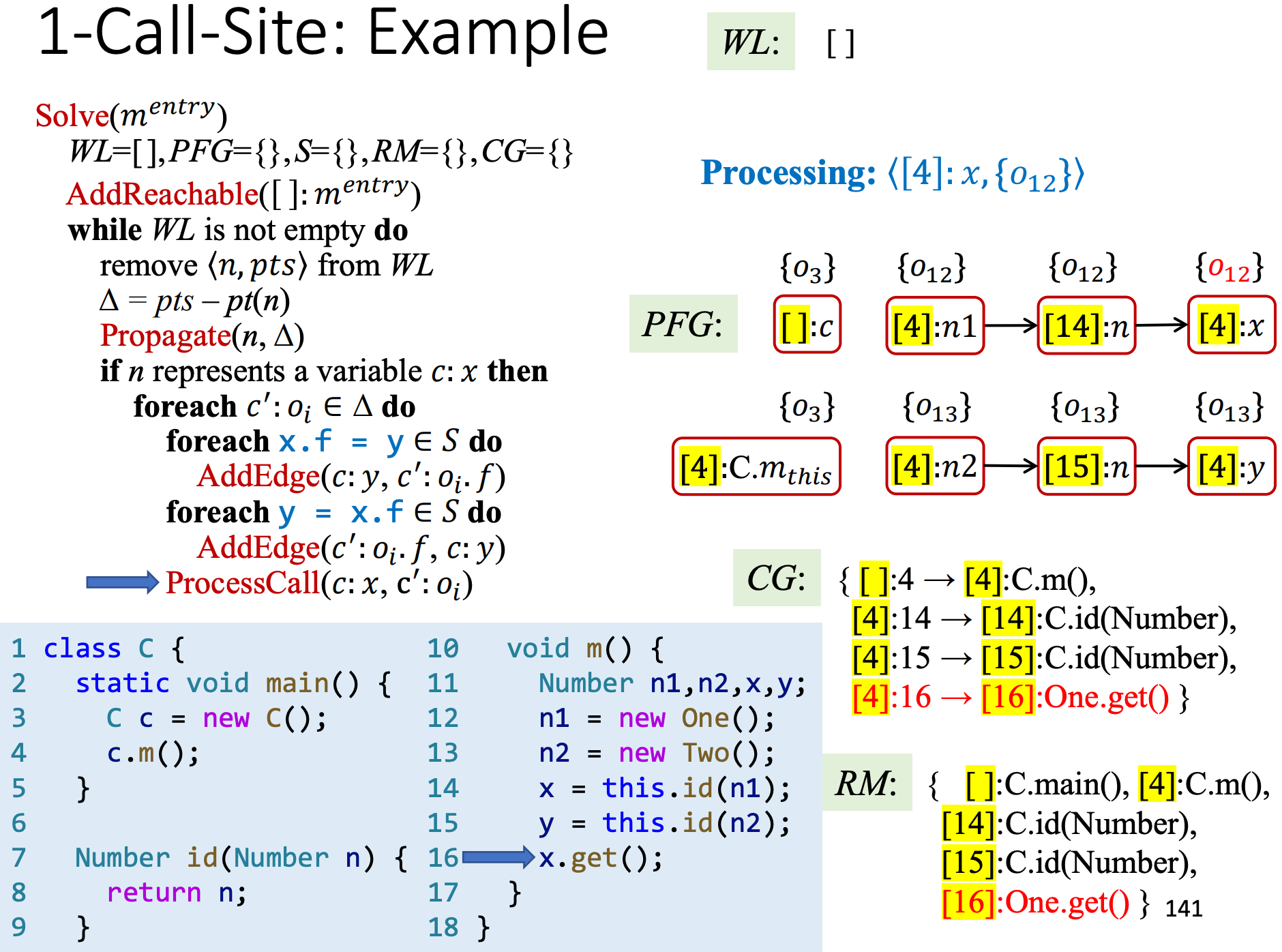
算法结束,

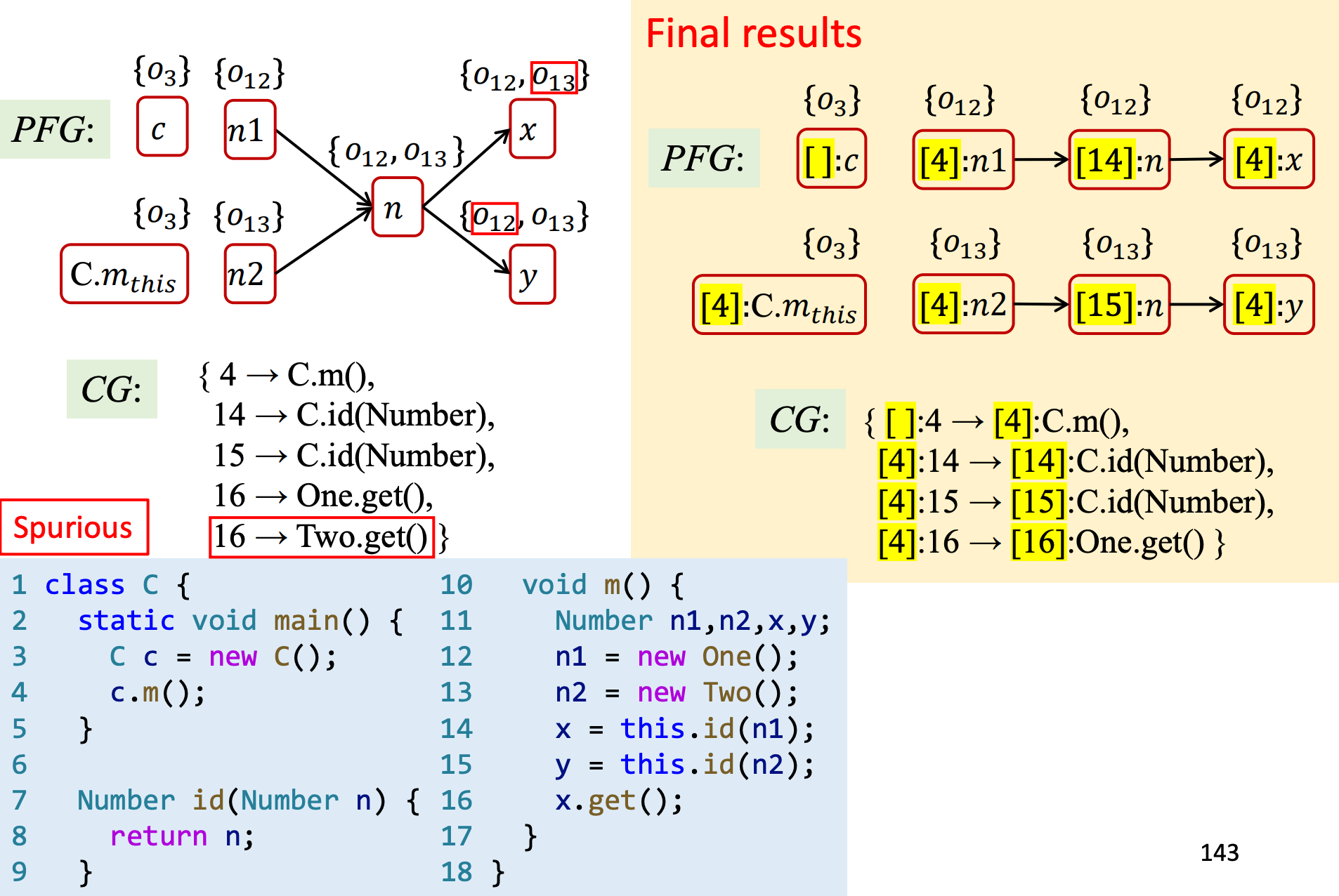
3、C.I.对比C.S.(1-call-site)
和C.I.对比,我们可以发现对于16行处的分析,C.S.(1-Call-Site)更加精确。
Object Sensitivity
以receiver object作为上下文标识

1、当存在同一行代码被多个对象调用时,1-Call-Site的精度比1-Object高
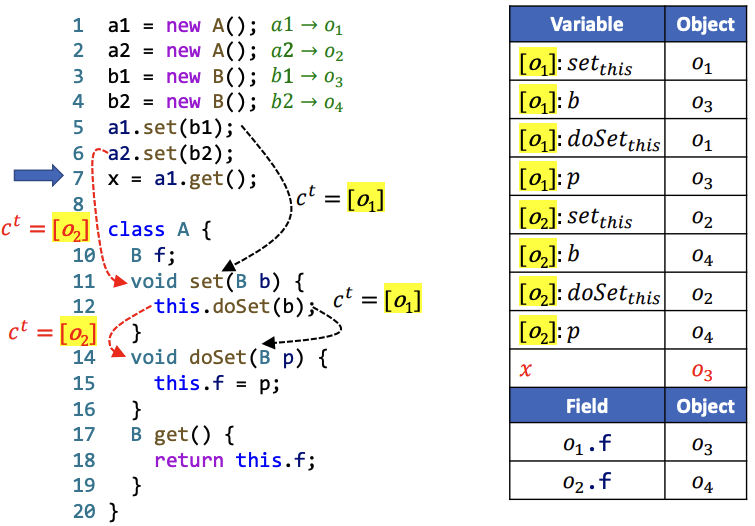
分别用1-Call-Site和1-Object的方式分析以下代码,给出所有指针(包括Variable和Field)所指向的对象。
1-Object的方式分析代码如下,



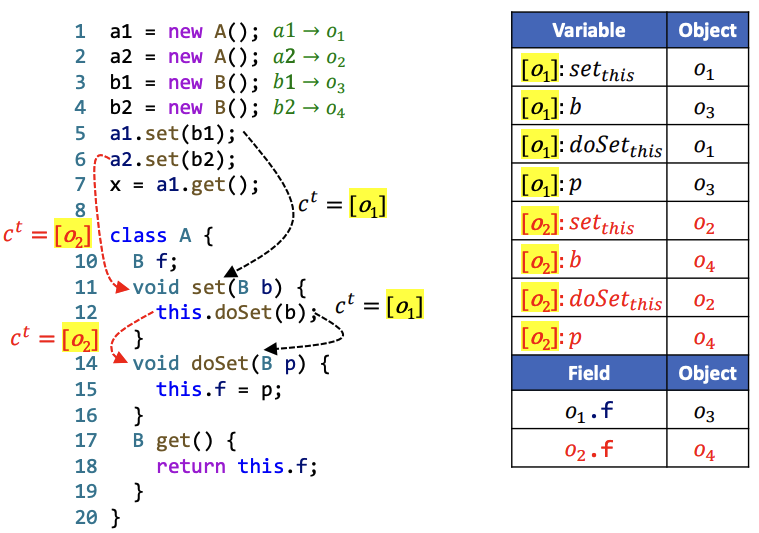
1-Call-Site的代码分析方式如下,


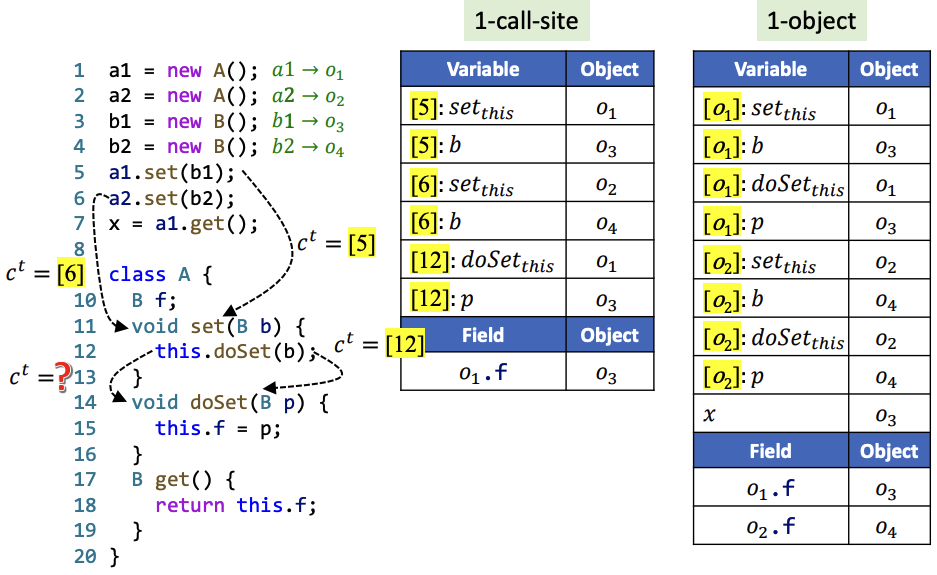
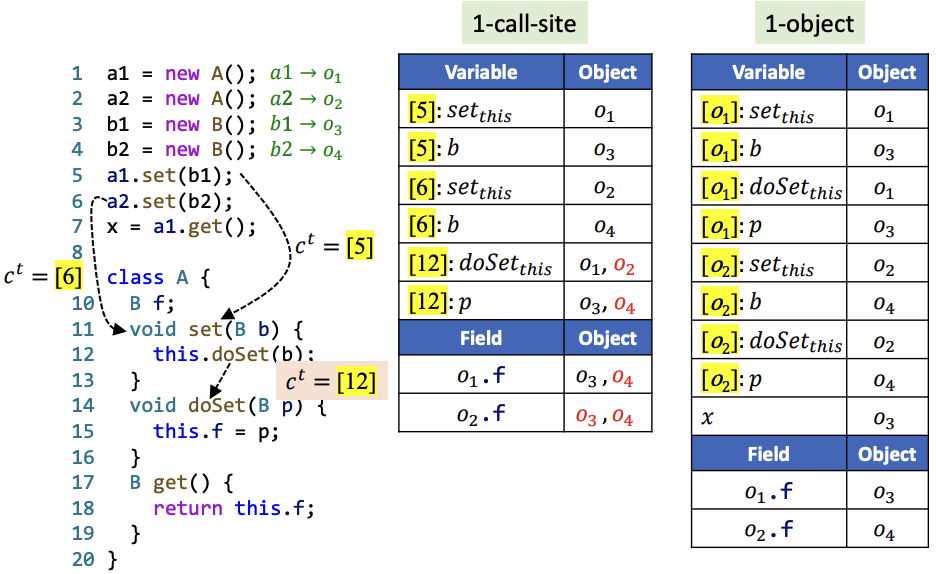


在12行,1-call-site的分析方法产生了不精确分析结果。在Call Graph中我们能够更好地看到这一点:
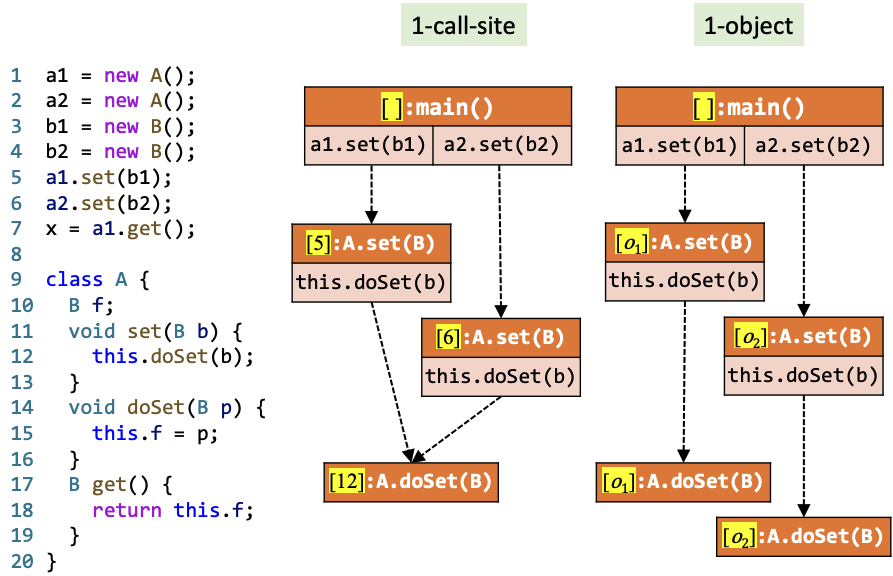
通俗地说,1-call-site只能记得自己是从哪个路口走到当前位置的,而1-object能够记得自己是谁。
需要注意的是,上面这个例子中,选取2-call-site也是可以区分的。
2、当存在同一个对象被多次调用时,1-Object的精度比1-Call-Site的高
比如在分析以下代码时:

由于代码中出现了this调用两次的情况,这两个调用点的receiver是一样的,此时对象敏感的分析方法无法区分两条路径,便产生了误报。
3、C.S.(1-Object)和C.S.(1-Call-Site)的比较总结
- 可以发现,两种方法的准确率不可比较,各自都有出现误报的情况。
- 但是经过实验验证,对于面向对象的语言来说,对象敏感的上下文PTA的效率和准确率都更高,因为这更符合OO语言的特性。
Type Sensitivity
和Object Sensitivity类似,但是粒度更粗而效率更高——这种方法只关注Object是在哪一个Class中被声明的。

下面看一个Object-Sensitivity和Type Sensitivity对比的例子,

Sum up
- Precision: object > type > call-site
- Efficiency: type > object > call-site

 浙公网安备 33010602011771号
浙公网安备 33010602011771号