南京大学 静态软件分析(static program analyzes)-- Pointer Analysis Foundations 学习笔记
一、Pointer Analysis: Rules
Notations

分别定义
- 变量
- 域
- 对象(用下标标识是在第几行创建的对象)
- 实例域和指针(是变量和实例对象的并)
- 指向关系
pt(p)代表的是指针p可能指向的对象。如在下面的代码块后,pt(x)可能指向的目标可以记为o2,o4(以行号作为object的下标)。

Pointer Analysis: Rules
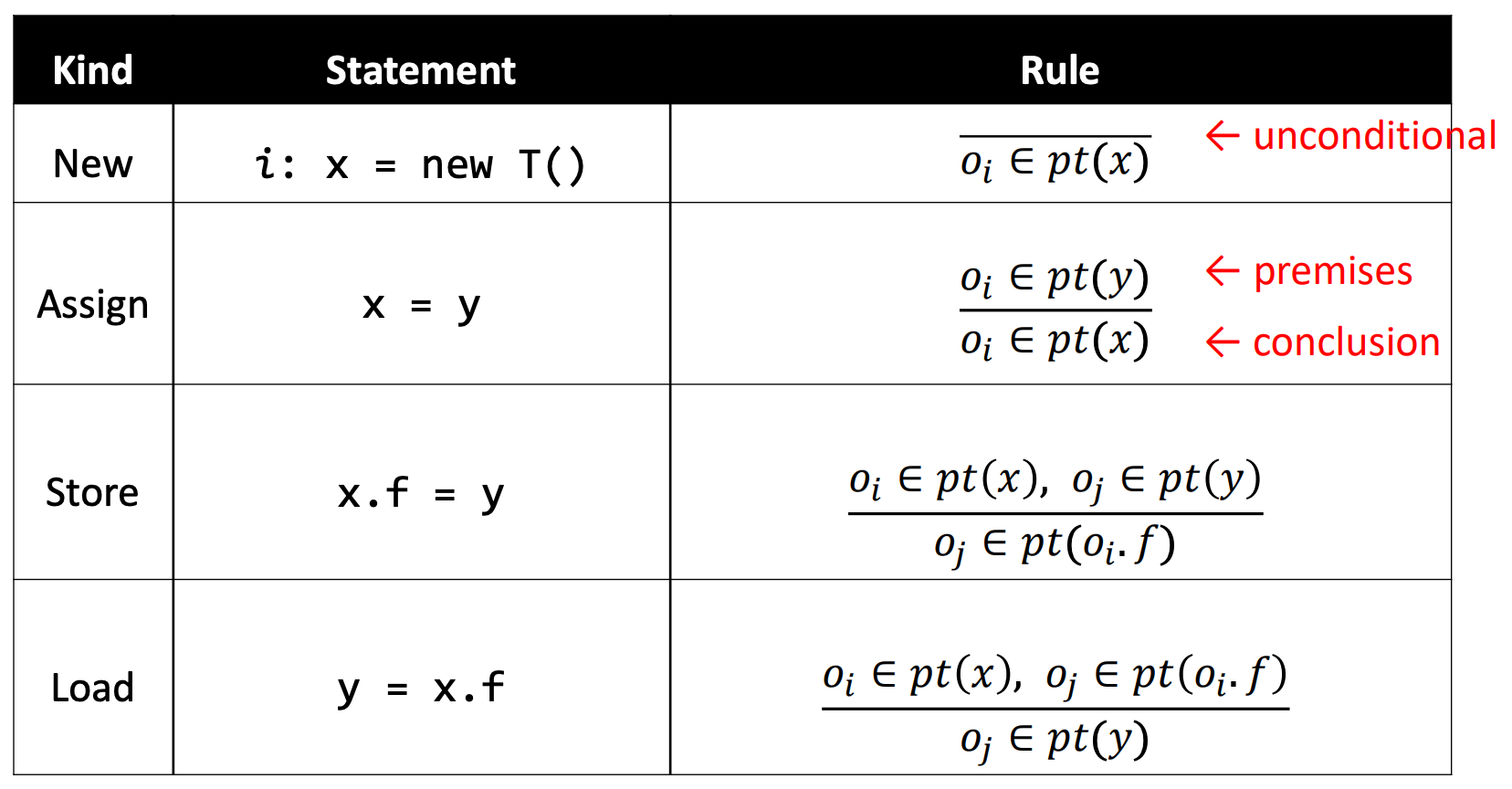
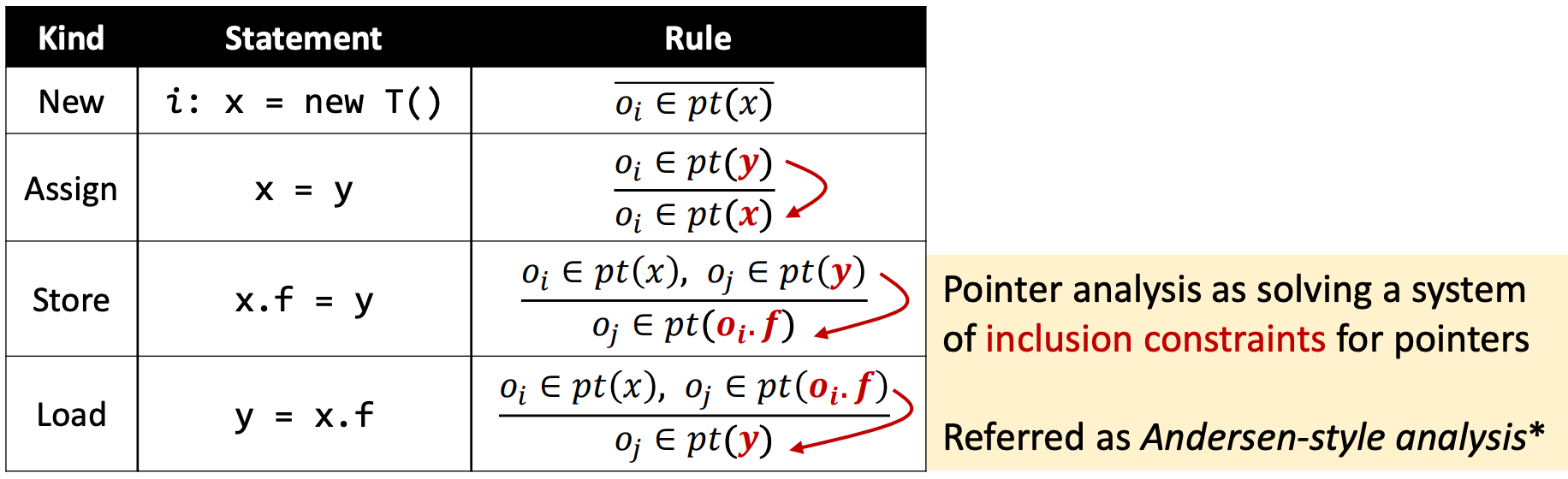
横线上的内容是前提(Premises),横线下的内容是结论(Conclusion)。
看到new语句,我们就将新建的对象加入pt(x)。
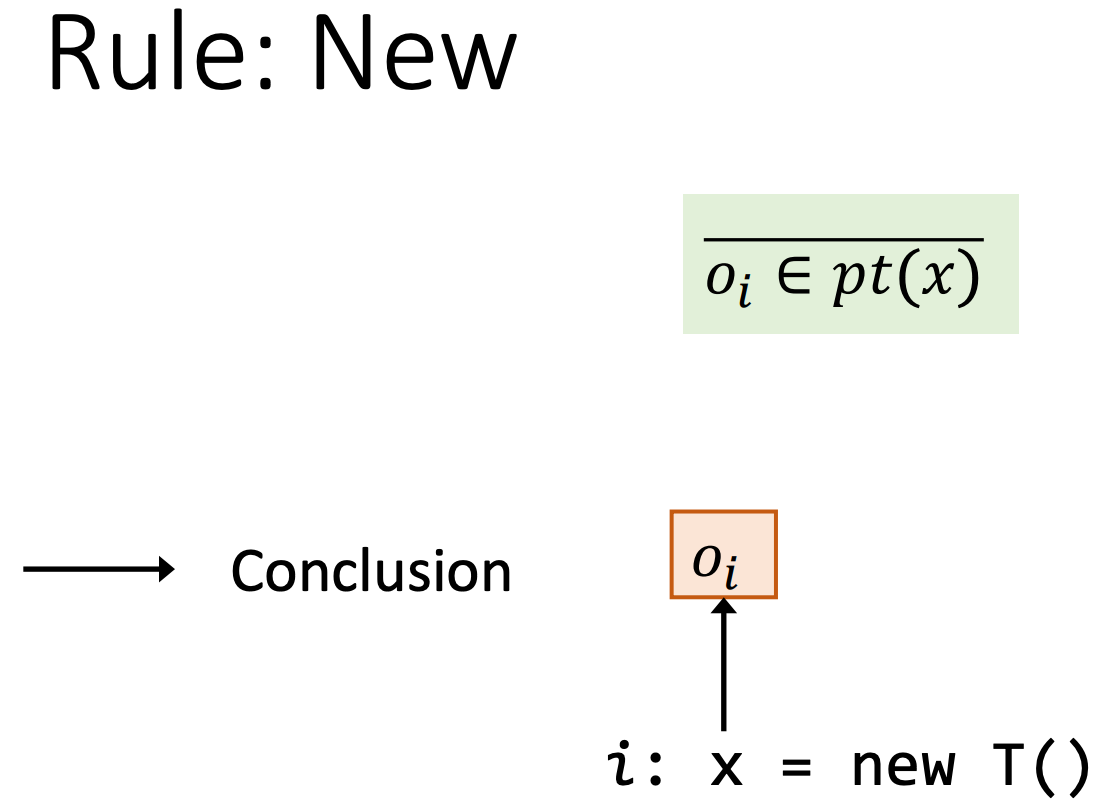
对于Assign语句,我们将x指向y指向的对象。
即原本oi属于指针关系集pt(y),现在oi也属于指针关系集pt(x)。
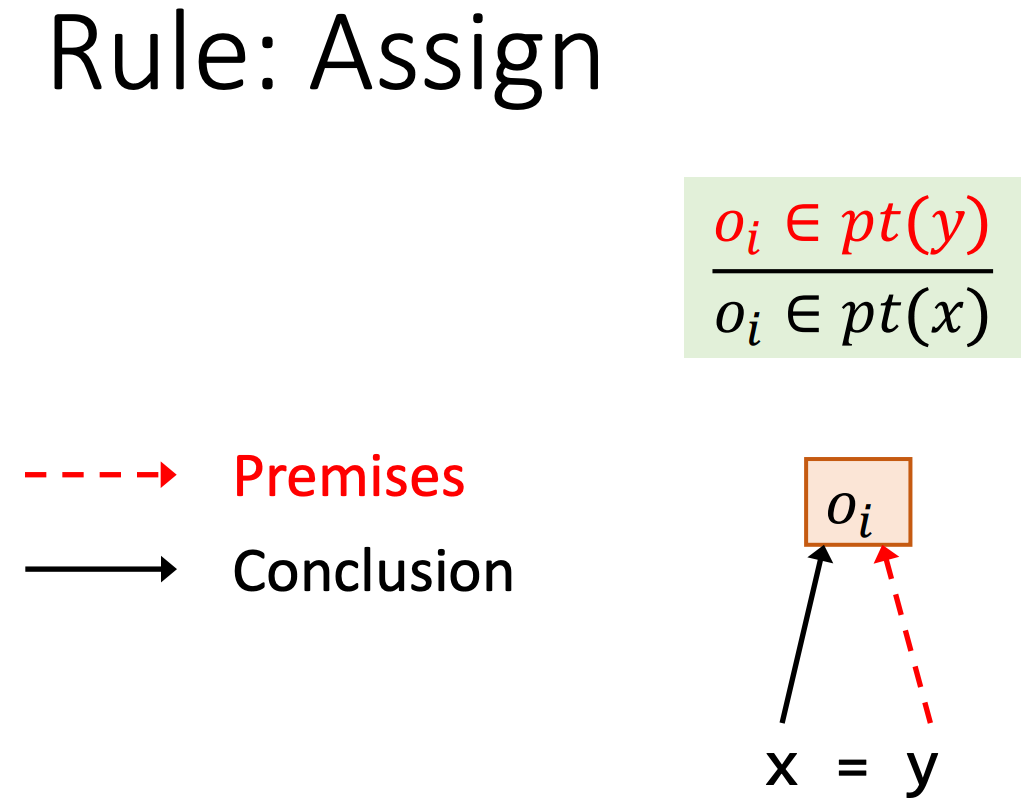
对于Store语句,我们将x.f指向y指向的对象。
即原本oj属于指针关系集pt(y),oi属于指针关系集pt(y),现在oj也属于指针关系集pt(oi,f)。
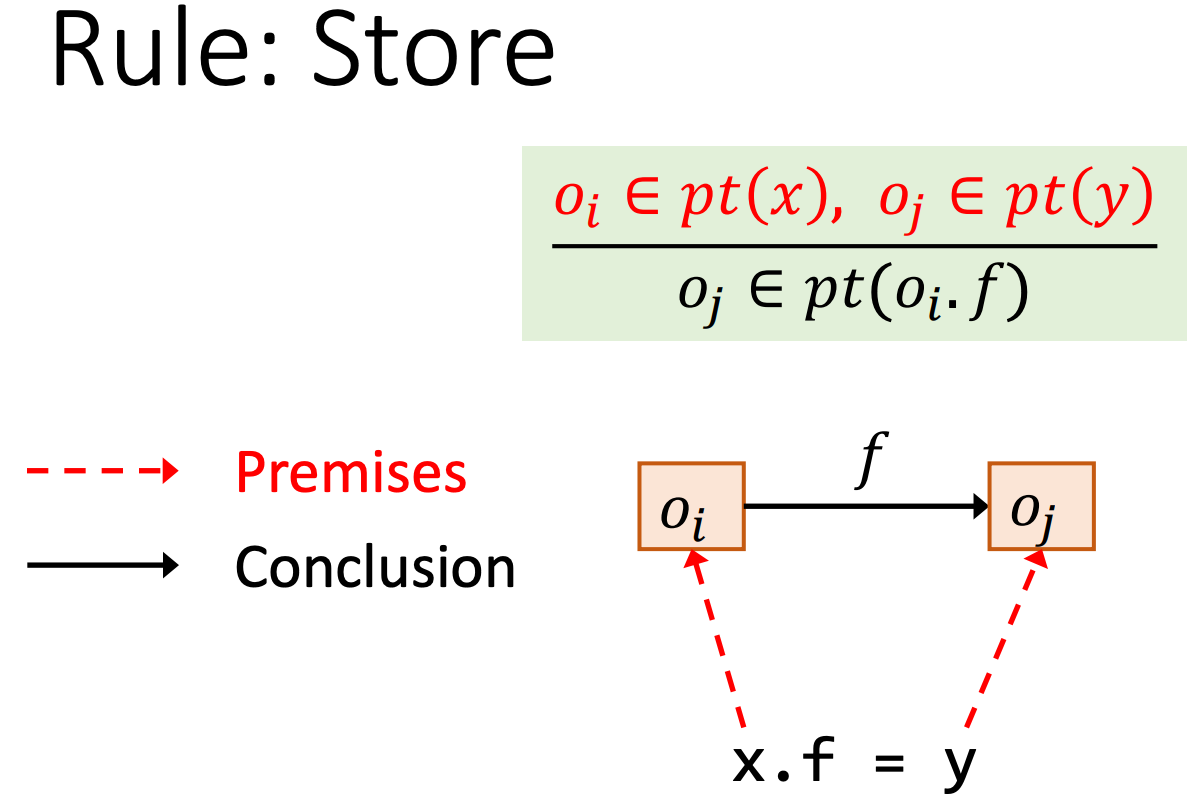
对于Load语句,我们将y指向x.f指向的对象。
即原本oj属于指针关系集pt(oi,f),oi属于指针关系集pt(x),现在oj也属于指针关系集pt(y)。

Summary

二、How to Implement Pointer Analysis
概念
本质上来说,指针分析是在指针间传递指向关系(Essentially, pointer analysis is to propagate pointsto information among pointers (variables & fields))。所谓指向关系,通俗来说就是指向对象(变量、域成员)的oi。
更通俗地理解,将程序的变量和field之间指针集传播的情况都记录下来(使用四个规则进行指向信息的传播,而最开始的指针信息都来自于New)。
所谓Andersen-style分析,是把指针分析看作是一种包含关系(包含约束),eg,
- x = y,x包含y。将这种包含关系看作一种约束,并对这些约束进行求解。
- 前提:x = y,oi ∈ pt(y)
- 结论:pt(y) ∈ pt(x)
实现指针分析的关键:当一个指针的指向集(pt(x))发生变化时,更新与它相关(𝑥’s successors)的其他指针。
实现这个目的的算法:PFG(指针流图)。
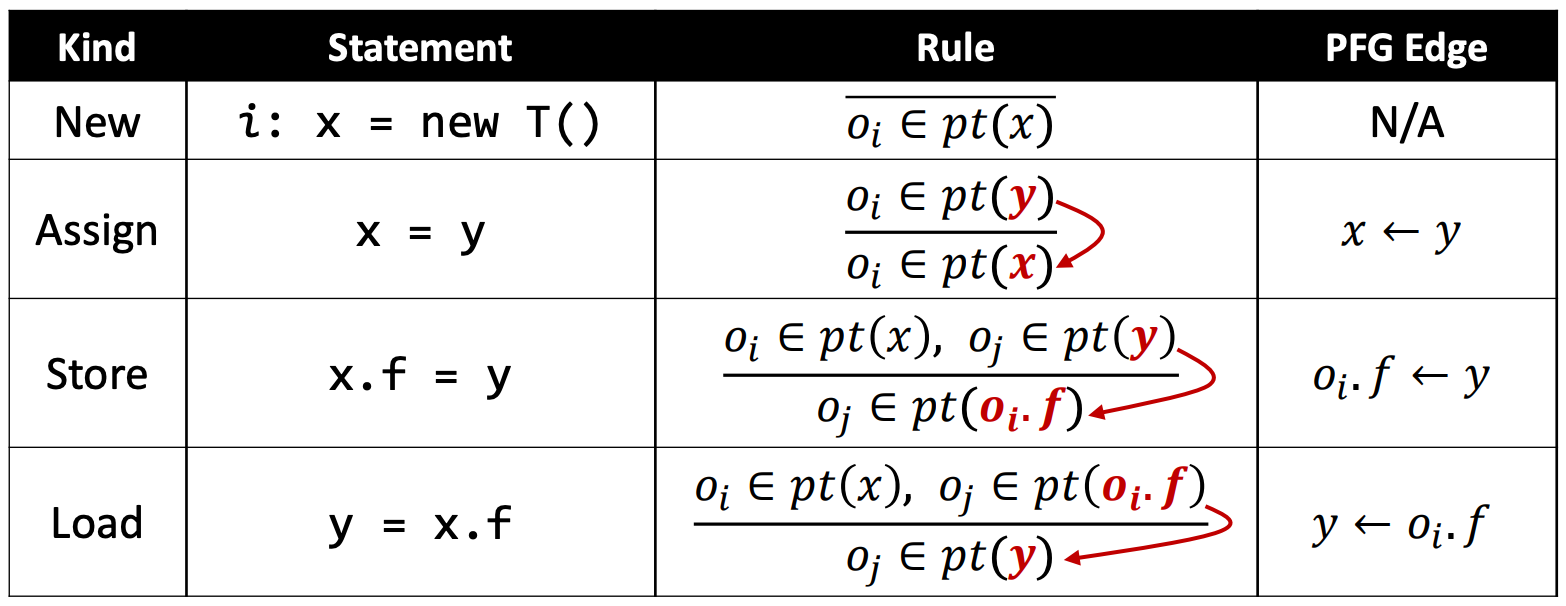
Pointer Flow Graph (PFG)
Pointer flow graph of a program is a directed graph that expresses how objects flow among the pointers in the program.
- Nodes: Pointer = V ⋃ (O × F):A node n represents a variable or a field of an abstract object
- Edges: Pointer × Pointer:An edge 𝑥 → 𝑦 means that the objects pointed by pointer 𝑥 may flow to (and also be pointed to by) pointer y
PFG edges are added according to the statements of the program and the corresponding rules.
Pointer Flow Graph: An Example
假设c和d一开始都指向oi ,根据上述规则,我们能够从左侧的程序语句从上到下构建出右侧的指针流图。
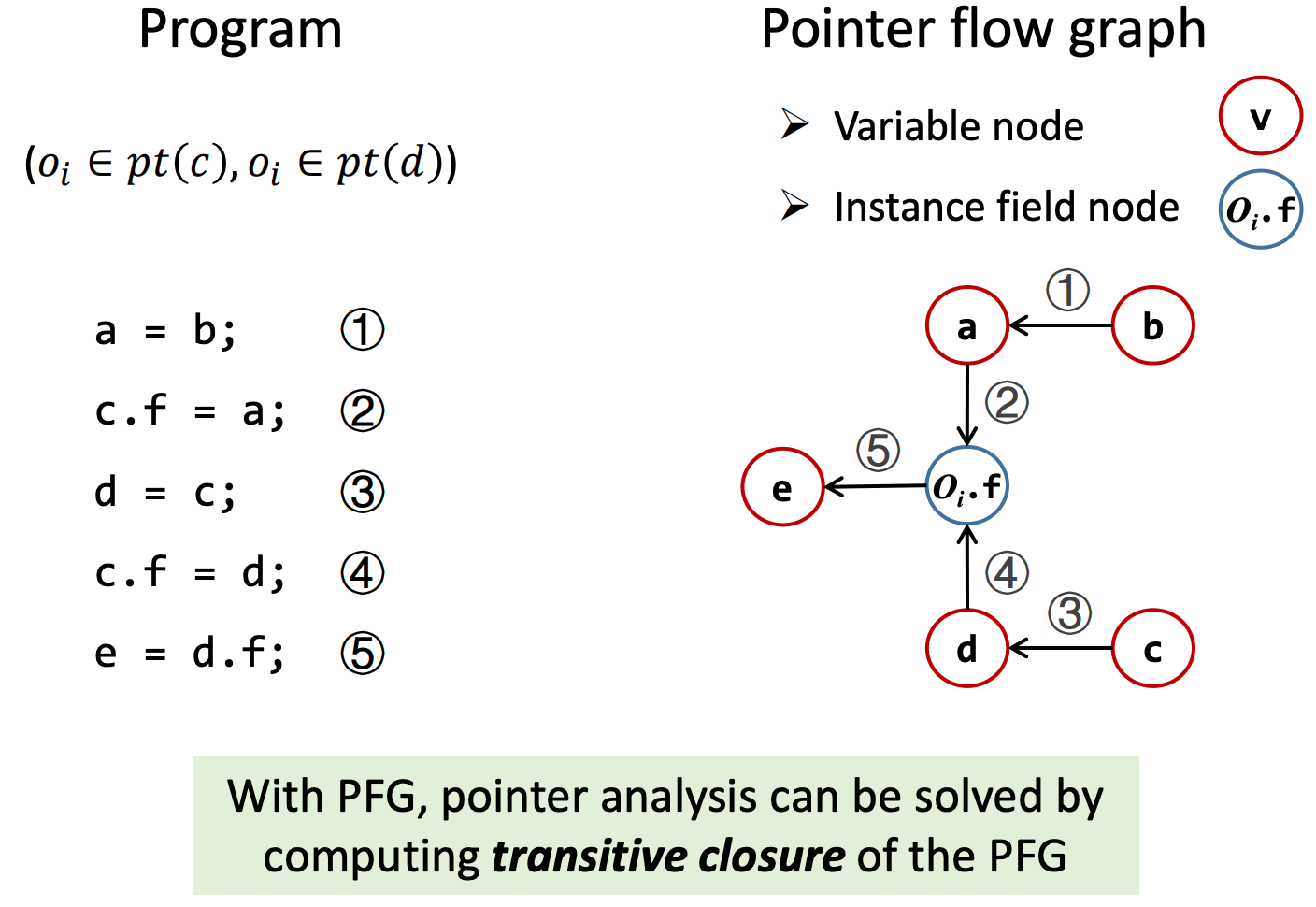
由上图可知,所有b所指向的对象更新时,都要传递到e中。这是一个求传递闭包(transitive closure)的过程。
接下来我们考虑j位置的一条新语句b = new T();

注意图中的节点只可能是v或是oi.f,而不是c.f,因为c.f是具体的指针表达式,我们只抽象出一个集合。在JAVA中,这个集合是一个Class可能的Instance。
Implementing Pointer Analysis
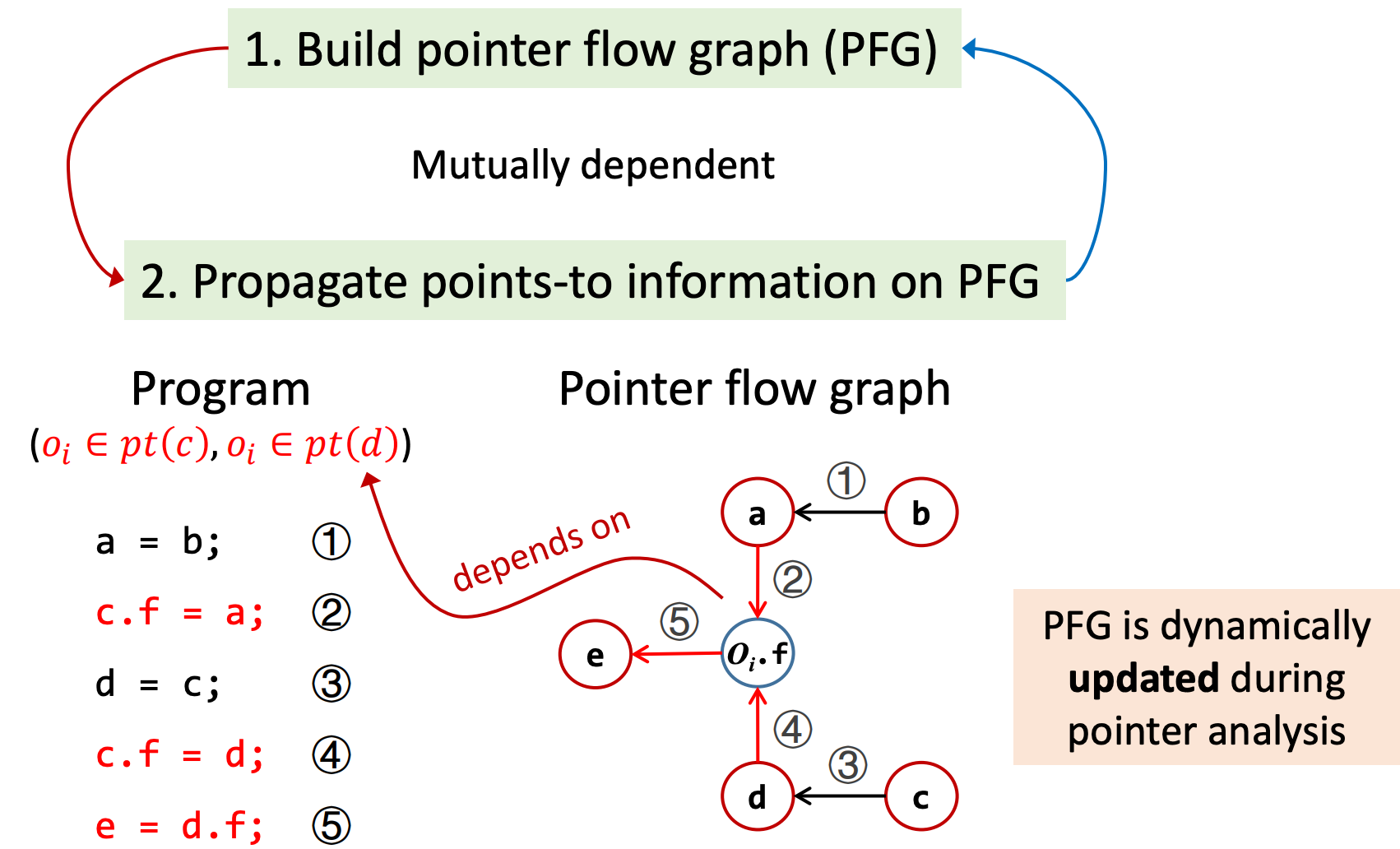
PFG的整个构造过程,需要在构建PFG和在已有的PFG上传递指向关系这两个步骤间循环往复。这两个步骤是相互依赖的(指向信息会影响PFG的结构,因为边的构造来源于指向信息),所以需要精心设计算法来实现分析,并且在指针分析时,PFG会被实时更新。
三、Pointer Analysis: Algorithms
数据流分析是一个宽泛的概念,没有定式,PTA可以看作是数据流分析的一种。
Worklist (WL)
- Worklist contains the points-to information to be processed
- 𝑊L ⊆ < Pointer, 𝒫(O) >*
- Each worklist entry <𝑛, pts> is a pair of pointer 𝑛 and points-to set pts, which means that pts should be propagated to pt(𝑛)
- E.g., [𝑥,{𝑜𝑖} , 𝑦,{𝑜𝑗, 𝑜𝑘} , 𝑜𝑗.𝑓,{𝑜𝑙} …
四个红框部分对应之前提到的四种基本语句:New、Assign、Store和Load。接下来做详细讲解。

接下来我们分别来详细讨论。
Handling of New and Assign
Init and adding edges

首先考虑两种简单的语句:New和Assign,
前三行代码做初始化的工作,并针对所有的New语句,将所有的初始指向关系加入WorkList。注意pt(n)初始化后为空集{},随着算法的迭代会增加元素。

之后的两行代码处理Assign语句,添加y->x的边到PFG中,同时将原来y的所有指向都添加给x。添加边的具体算法如下,
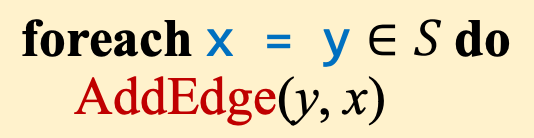

对于AddEdge函数中第二个if要注意:仅在第一次添加s->t到PFG时添加pt(s)的信息到t,是因为Propagate中的语句能够处理后续的pt(s)变化。
Propagate

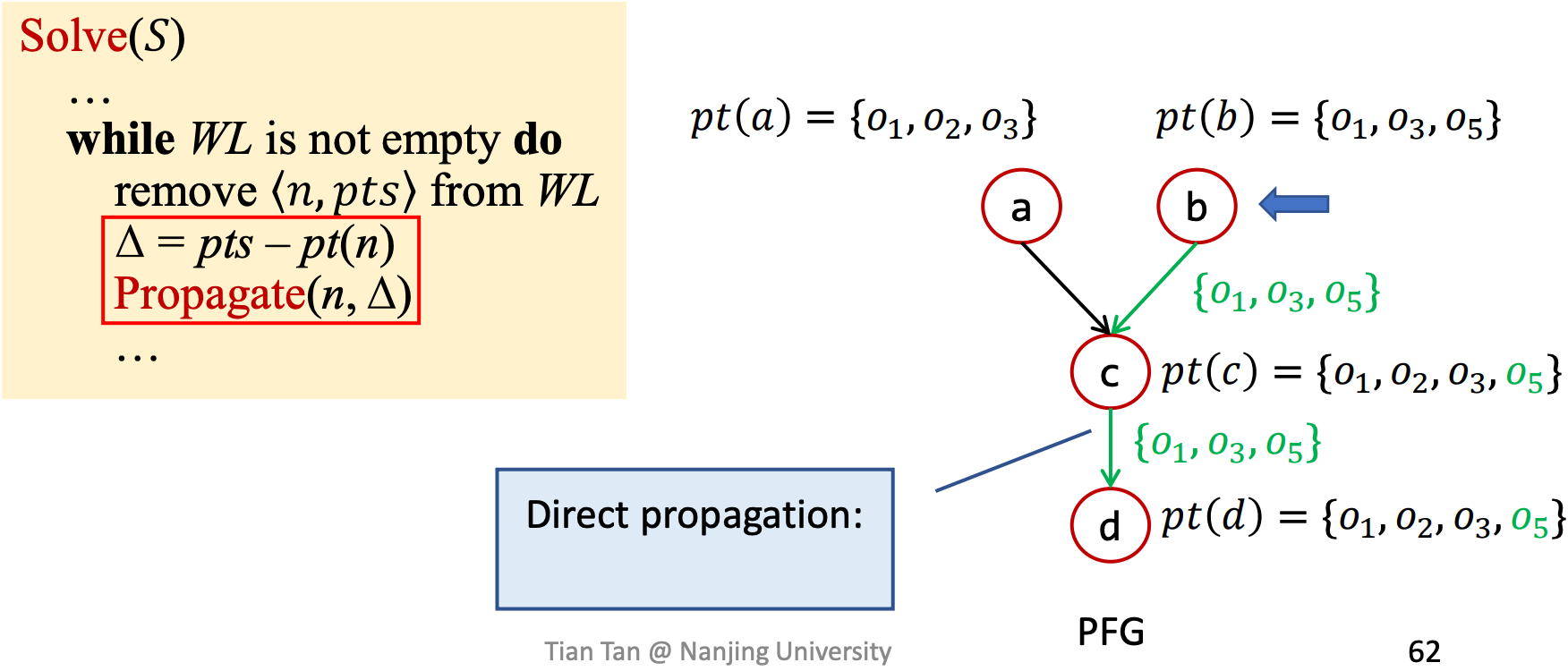
在真实的指针分析中,对象的数量非常巨大(上亿),我们通过Differential Propagation来消除冗余。

首先我们考虑不使用Differential Propagation的情况,首先是a->c->d的传递路线。

然后是b->c->d的传递路线,虽然{o1,o3}之前已经在c所指向的集合中了,但依然需要参与传播,这是冗余的。
我们再来看使用Differential Propagation的情况,只需要传播{o5}一项即可。在实际应用中这能够大大减小开销。
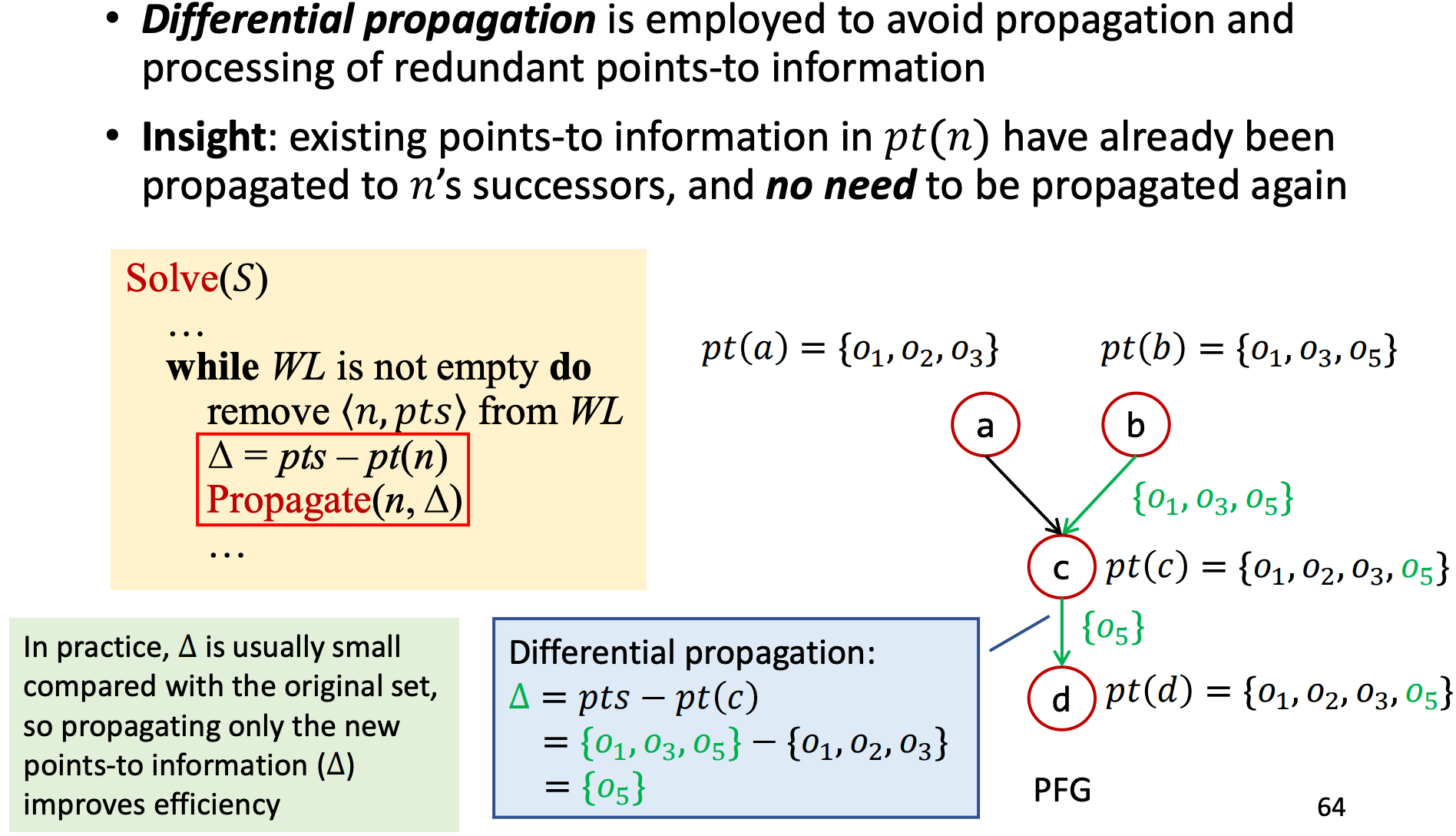
去重后,指针对象传播的具体算法如下,

propagate会从当前节点n递归处理其后继节点的指针传递。
Handling Store and Load

The Algorithm-Review

Example
尝试用上述算法,计算以下代码的PFG。

1、初始化

2、处理new、assign语句


3、指针递归传播


4、处理load、store


继续处理WL,

继续处理WL,

处理完毕,WL为空,PFG构建完毕,

四、Pointer Analysis with Method Calls
CHA和PTA对构建Call Graph的区别
- CHA:基于声明类型,不精确,引入错误的调用边和指针关系。
- 指针分析:基于pt(a),即a指向的类型,更精确,构造更准的CG并对指针分析有正反馈(所以过程间指针分析和CG构造同时进行,相对更复杂)。
考虑下面这样一小段代码,显然,我们必须要有过程间的分析,才能有更准确的分析结果。

如果a的指向对象清楚了,就能确定a.bar()调用了哪个对象的bar(),从而得到b的指向对象。
Rule: Call

通俗地理解,Rule for Call本质上是在抽象函数调用的过程,包括:
- 保存现场
- 构造调用栈帧
- 传递参数
- 跳转到目标函数开始执行……
- 目标函数执行完毕跳转回来
- 从预定的位置取返回值(若需要)
- 恢复现场,继续往下执行……
在静态分析中,我们更多地关心数据流,而非控制流。而针对Java,处理函数调用的数据流可以分为以下四个部分:
- 确定目标方法。用Dispatch函数完成:根据oi和调用的方法签名k查找目标方法,具体的:找出
pt(x),中的所有k函数 - 传receiver object:x指向的对象传给方法的
this,即将pt(x)赋给各个方法中的this - 传参数:对于pt(aj), 1<=j<=n,将其 传给各个方法的对应参数。为了方便实现这一步,会建立PFG边:a1->mp1,...,an->mpn,其中mpn表示m方法中的第n个变量
- 传返回值:pt(mret)传给pt(r)。为了方便实现这一步,会建立PFG边r <- mret。



Question: Why not add PFG edge 𝑥 → mthis?


在PTA中,在每次算法执行时,oi 是确定的某个(只有一个)对象,然后针对这个对象做Dispatch,能够找到对应的唯一的receiver object.
Interprocedural Pointer Analysis
和用CHA做过程间分析时一样,PTA需要将分析的过程和Call graph构建的过程结合起来。

和CHA不同的是,这次我们只分析从main方法(或者一般性地说,程序入口)开始可达的部分。原因有二:
- 提升分析速度。因为我们能够避免分析不会被执行到的死代码。
- 提升分析精度。避免了unreachable部分的代码调用reachable部分方法时可能引起的精度下降。
Algorithm: PA with Method Calls

黄色标记的部分是这次新加入的部分。绿色部分是对新的全局变量的说明:
- S里的statements就是RM里methods的statements(语句)
- Call Graph和指针集作为最后的输出。
下面我们来详细看这个算法,
1、Function: AddReachable
AddReachable的作用是:
- 输入参数m是最新的可达方法。
- 函数修改维护全局的RM、S和,并处理新的方法m中的New和Assign语句。

这里注意一个问题,为什么要检查l->m是否在CG中,即为什么同样的l->m可能不止一次地被处理?
l代表call site。可以用行号作为call site的label。因为同样可能通过Dispatch返回同一个m,所以这里需要做一个if判断。
2、Function:ProcessCall
ProcessCall的作用是:
- 输入的是x新指向的目标。
- 函数在可达的语句集合S中,选择所有与x有关的过程调用,做之前提到的数据流相关四步处理(确定被调用方法、传对象、传参数,传返回值)。


An Example
举一个具体的例子,利用PTA构建Call Graph和PFG。

我们逐步来分析,
1、初始化

2、从入口点mentry开始扩展“reachable world”,添加new语句WL中

3、开始处理WL


4、处理b.foo ProcessCall



这里注意,如果是CHA,在进行dispatch构建CFG的时候,会存在过传递误差问题。
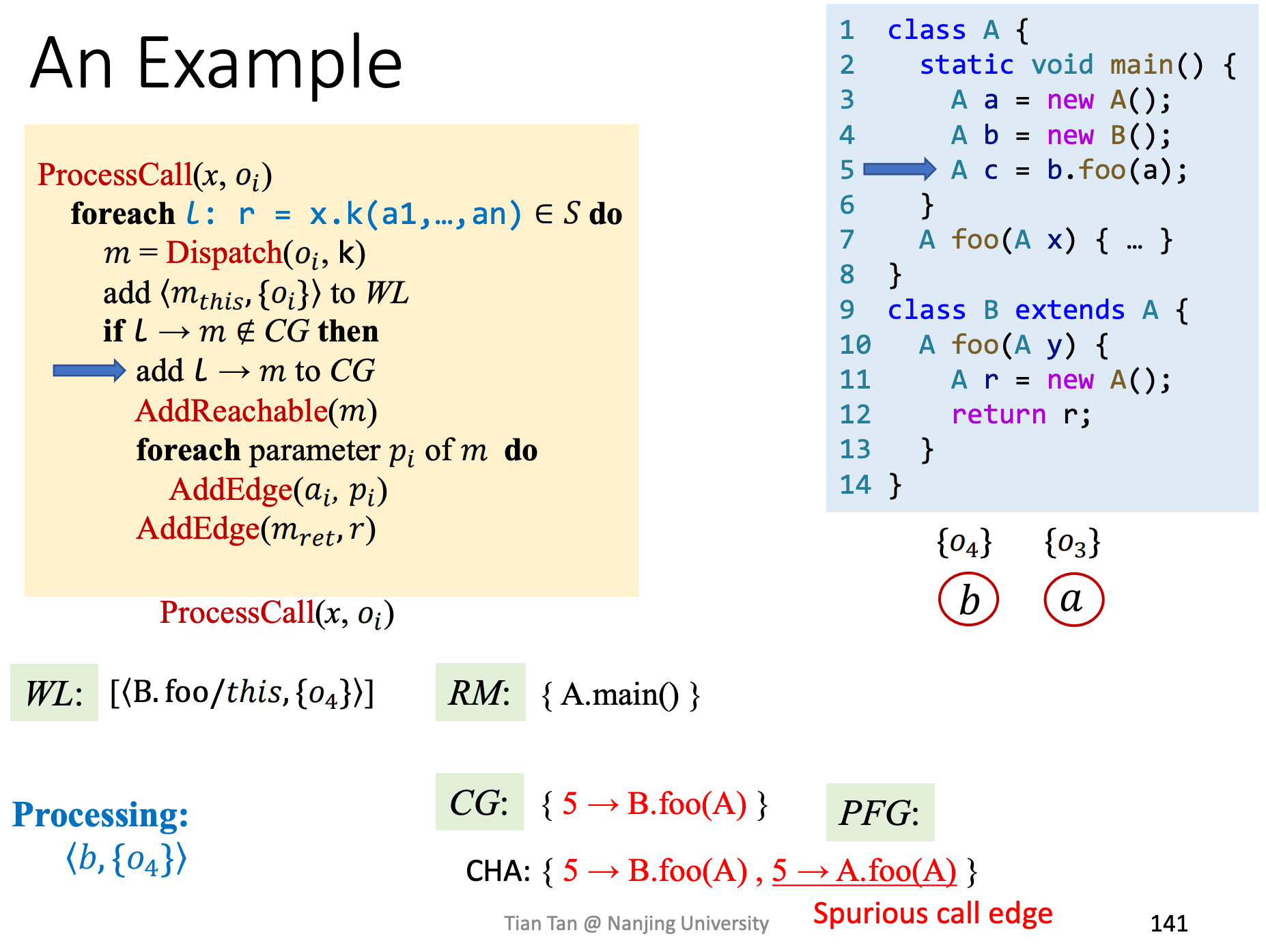
5、继续处理被Call的Process
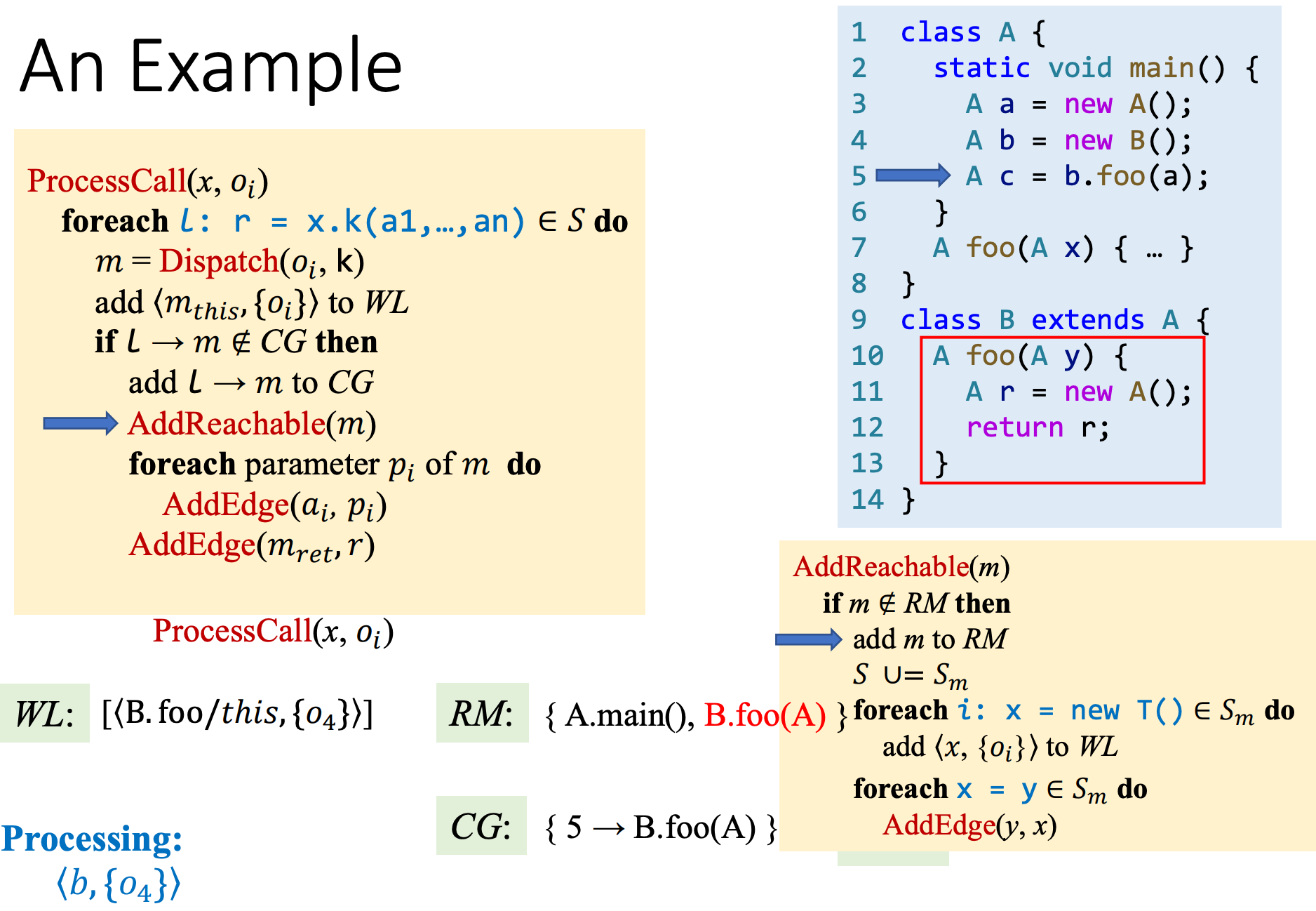


6、继续处理WL


7、参数传递

8、继续进行propagate

8、分析完成,CG和PFG构建完成


 浙公网安备 33010602011771号
浙公网安备 33010602011771号