结对作业二
结对作业二
| 结对成员 | 221801202毛富林、221801211宋方滐 |
|---|---|
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 (福州大学) |
| 这个作业要求在哪里 | 结对作业二 |
| 这个作业的目标 | 对已爬取的论文进行基本操作 |
| 其他参考文献 | 万能的度娘、构建之法、哔哩哔哩 |
目录
git仓库及代码规范
git仓库:点这里
代码规范:点这里
云服务器:点这里(从封面开始展示)
(tips:如果链接出现了问题,请直接联系学号221801202或者221801211,因为我们对价格高达28元的阿里云服务器不熟练,不知道会出现什么问题)
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 2100 | 2460 |
| • Analysis | • 需求分析(包括学习新技术) | 640 | 720 |
| • Design Spec | • 生成设计文档 | 60 | 60 |
| • Design View | • 设计复审 | 90 | 90 |
| • Coding Standard | • 代码规范(为目前的开发制定合适的规范) | 40 | 40 |
| • Design | • 具体设计 | 100 | 120 |
| • Coding | • 具体编码 | 810 | 980 |
| • Coding Review | • 代码复审 | 60 | 90 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 300 | 360 |
| Reporting | 报告 | 300 | 360 |
| • Test Repor | • 测试报告 | 200 | 240 |
| • Size Measurement | • 计算工作量 | 60 | 60 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 40 | 60 |
| 合计 | 2420 | 2840 |
成品展示
-
基础功能部分
-
整体展示
- 从封面开始简单地描述,点击Learn about进入首页。首页上方是导航栏,起初是想将对论文所有的操作分布在导航栏上,但经讨论后觉得完全没必要,所以导航栏就是简单的风格,后续如有需要,会修改、增加功能。接着是热词走势图,然后用一个表格展示论文简要信息,考虑到标题、摘要、关键词等篇幅过长等整体感官的影响,因此我们决定当文本超出限制时就显示省略号或者hidden,此时可以点击“查看”按钮,阅读详细信息。
- 效果展示如下

-
论文查看、删除
- 点击删除,会删除数据库里的相应记录;点击论文列表里的查看,可以跳转到页面,依次展示论文标题,所属的会议名称,会议的年份,关键词,在正文部分显示内容摘要,并在结尾附上原文的的链接(我们测试过,想要进这些外网的链接有点看运气,大多时候都能进去的),最后点击按钮返回到论文列表页面。
- 效果展示如下

-
论文搜索
- 按照正常人类的搜索习惯,我们实现了精准搜索和模糊搜索:(where paper_tile="xxxxxx")——输入完整的论文标题即可精准查询,或者(where paper_title like 'xxx%')——在表里匹配前几个字符,实现模糊查询。
- 效果展示如下

-
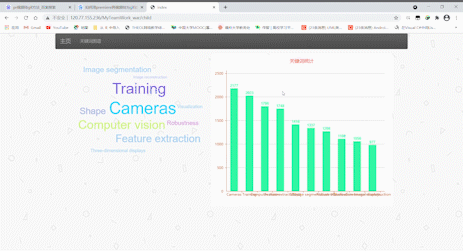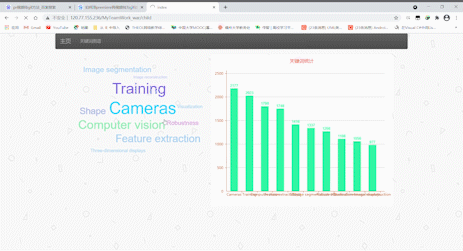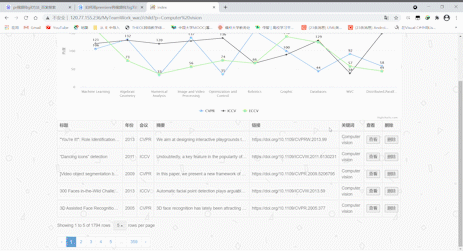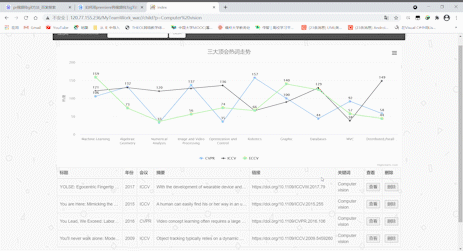
标签云及关键词图谱
- 点击导航栏的关键词图谱可以跳转,在新的页面可以查看由10个关键词形成的标签云和一张根据关键词数量形成的条形图。标签云里的关键词依据数量而获得权重(weight),数量越多,权值越大,标签也就越大,点击标签云里的关键词也可以跳转到首页,并且下方的表格会显示所点击关键词的所有记录。
- 效果展示如下
-
-
附加部分
-
爬虫的初步实现
-
这个真的很难。。。。。。不过我们也朝着大致的方向前进,比如:对外网的论文爬取实在是太难实现,因为那些老师、助教给网站是Javascript解析的,而且外网爬起来很慢。基本我们能力的局限性,我们只好把目光转向国内的网站。目前,基本的功能是能够完成的,爬取的网站用HTML和JSON两种方式保存(title是键,后面的是值)。
-
效果展示如下
-
命令行输出展示
-
爬取的JSON文件
-
-
爬取的HTML
-
-
-
对论文列表的分页功能
- 具体效果见上述GIF图
- 这是一个头疼的问题,因为老师、助教给的论文json文件,解析完后发现竟然多达万数行,没部署在服务器上的时候,加载慢的要死,还经常卡死,因此表格的行数会在一页中一直增加下去。所以我们干脆就限制每页的行数,并实现分页,这样的话加载起来就没那么卡了。(任然存在的小问题:每次重新加载的时候还是有一点慢,部署在云服务器上感觉还不错,虽然是价格高达28的阿里云服务器,1G的。)
-


设计实现过程
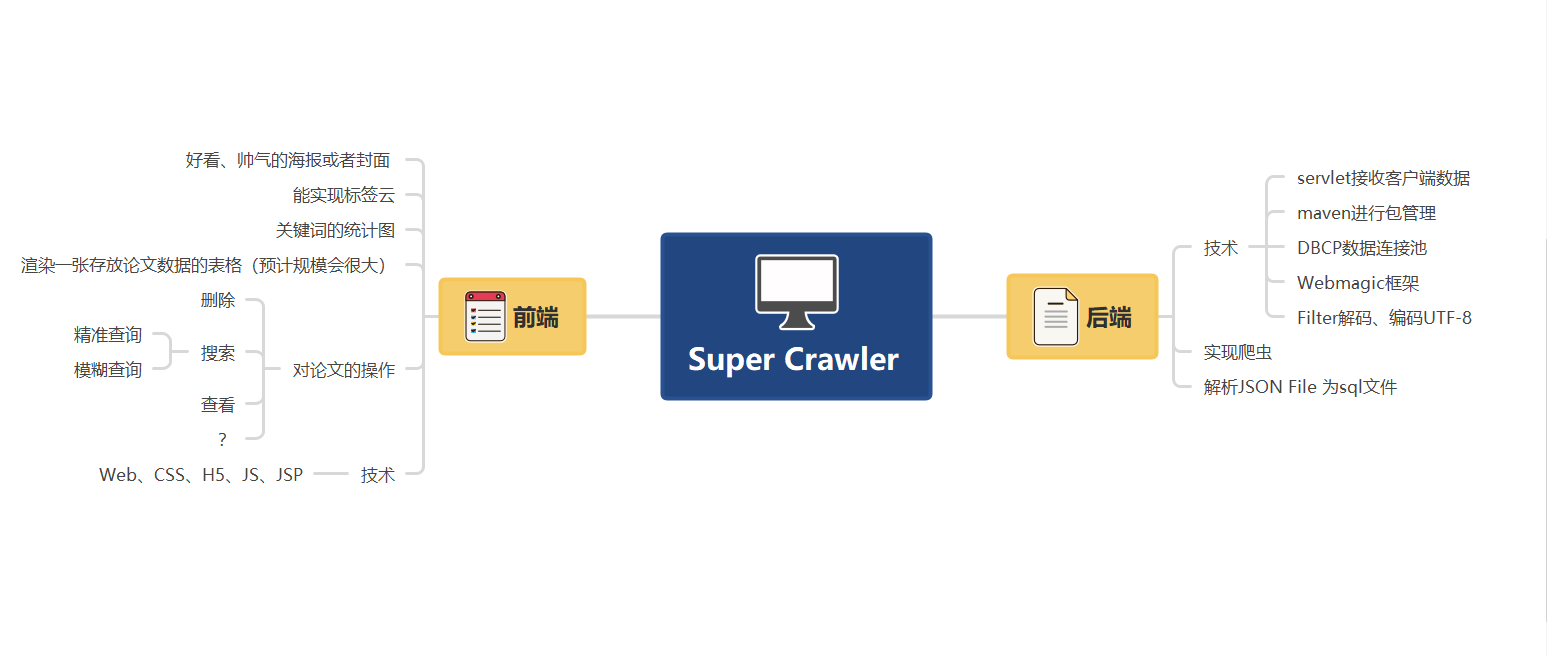
思维导图:
- 如下展示的是我们起初的设计导图。
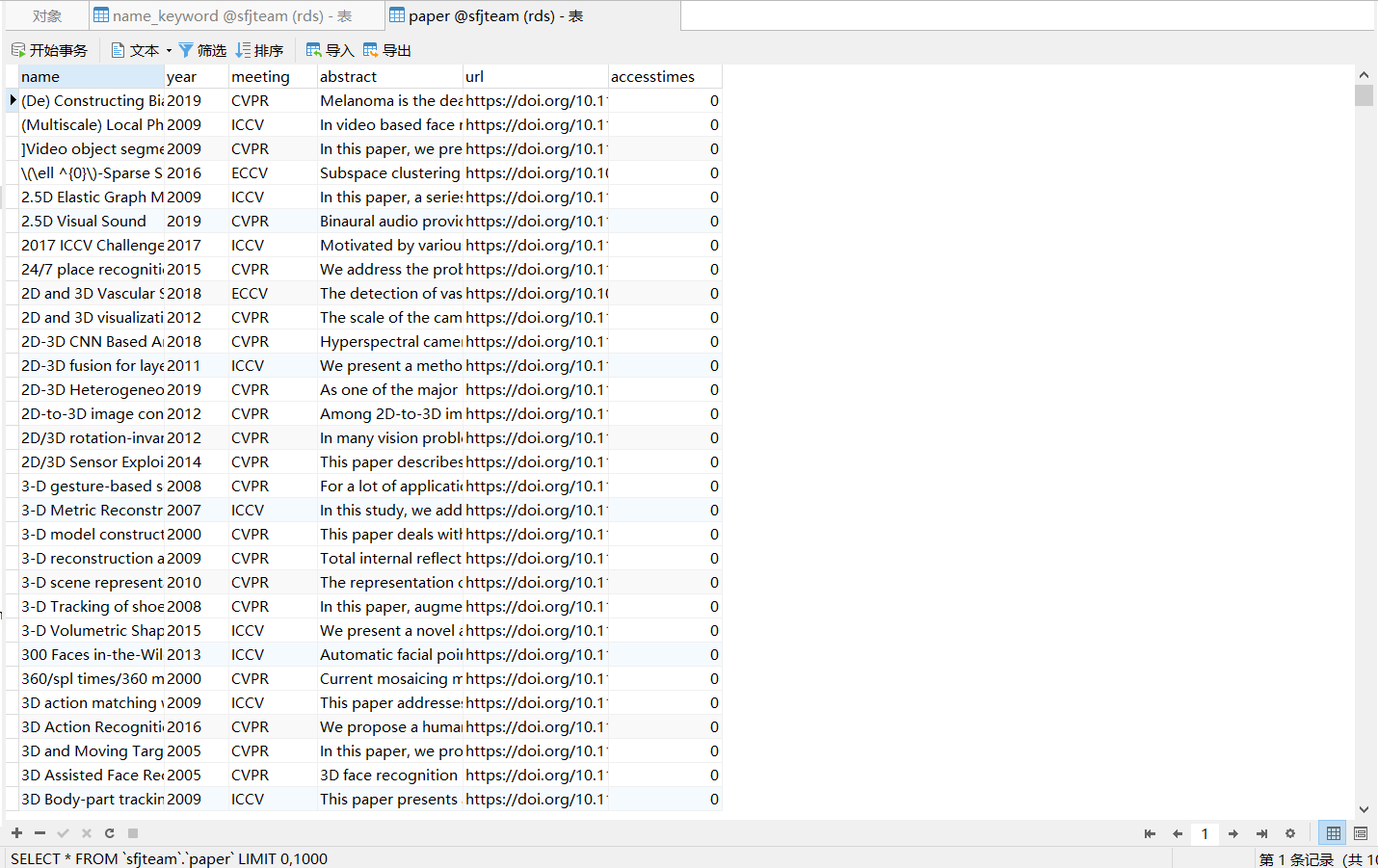
数据库表格
-
解析完成后的数据库。
前、后端项目
-
前端项目
- 后端项目

代码说明
后端
Keynum类(存放关键词和次数)
public class Keynum {
private String keyword;
private int appeartimes;
Paperinfo(存放论文信息)
public class PaperInfo {
private String title;
private String year;
private String meeting;
private String abstr;
private String url;
private String keyword;
PaperInfoDao实现类(用于实现与paper表和name_keyword表的连接操作)。
定义了添加关键词的方法“addwordkey”。
public class PaperInfoDAOImpl implements PaperInfoDAO {
public String addwordkey(PaperInfo paperInfo,String str) {
String sql = "select * from name_keyword where name = \"" + str + "\"";
String temp = "";
try {
connection = DBUtil1.getConnection(); //待优化
preparedStatement = connection.prepareStatement(sql);
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
temp += (resultSet.getString("keyword") + ","); //将所有找到的关键词通过逗号连接
}
} catch (SQLException e) {
e.printStackTrace();
}
return temp;
}
展示表格的方法“selectPaperInfos”
public PaperInfo selectPaperInfo(String str) { //展示单个页面
String sql = "select * from paper where name = \"" + str + "\"";
PaperInfo paperInfo = new PaperInfo();
try {
connection = DBUtil1.getConnection(); //优化
preparedStatement = connection.prepareStatement(sql);
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
paperInfo.setTitle(resultSet.getString("name"));
paperInfo.setYear(resultSet.getString("year"));
paperInfo.setMeeting(resultSet.getString("meeting"));
paperInfo.setAbstr(resultSet.getString("abstract"));
paperInfo.setUrl(resultSet.getString("url"));
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
DBUtil1.close(resultSet,preparedStatement,connection);
}
String string = addwordkey(paperInfo,str);
paperInfo.setKeyword(string);
return paperInfo;
}
模糊查询的方法“getinfo”
public List<PaperInfo> selectPaperInfos() { //展示列表
List<PaperInfo> list = new ArrayList<PaperInfo>();
String sql = "select * from paper"+ " limit 1000"; //限制显示1000行数据
try {
connection = DBUtil1.getConnection(); //待优化
preparedStatement = connection.prepareStatement(sql);
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
PaperInfo paperInfo = new PaperInfo();
paperInfo.setTitle(resultSet.getString("name"));
paperInfo.setYear(resultSet.getString("year"));
paperInfo.setMeeting(resultSet.getString("meeting"));
paperInfo.setAbstr(resultSet.getString("abstract"));
paperInfo.setUrl(resultSet.getString("url"));
paperInfo.setKeyword("hidden...");
list.add(paperInfo);
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
DBUtil1.close(resultSet,preparedStatement,connection);
}
return list;
}
展示表格的方法“selectPaperInfos”
public List<PaperInfo> getinfo(String title) { //模糊查询
List<PaperInfo> list = new ArrayList<PaperInfo>();
String sx = "'"+title+"%'"; //设置可以自动搜索带有title的论文
String sql = "select * from paper where name like " + sx;
try {
connection = DBUtil1.getConnection(); //待优化
preparedStatement = connection.prepareStatement(sql);
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
PaperInfo paperInfo = new PaperInfo();
paperInfo.setTitle(resultSet.getString("name"));
paperInfo.setYear(resultSet.getString("year"));
paperInfo.setMeeting(resultSet.getString("meeting"));
paperInfo.setAbstr(resultSet.getString("abstract"));
paperInfo.setUrl(resultSet.getString("url"));
paperInfo.setKeyword("hidden...");
list.add(paperInfo);
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
DBUtil1.close(resultSet,preparedStatement,connection);
}
return list;
}
通过标签云显示对应列表的方法“getkey”
public List<PaperInfo> getkey(String keyword) {
List<PaperInfo> list = new ArrayList<PaperInfo>();
String sql = "select * from paper,name_keyword where name_keyword.keyword = \"" + keyword + "\"" + "and paper.name = name_keyword.name"; //通过两张表连接搜寻
String name =null;
try {
connection = DBUtil1.getConnection(); //待优化
preparedStatement = connection.prepareStatement(sql);
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
PaperInfo paperInfo = new PaperInfo();
paperInfo.setTitle(resultSet.getString("name"));
paperInfo.setYear(resultSet.getString("year"));
paperInfo.setMeeting(resultSet.getString("meeting"));
paperInfo.setAbstr(resultSet.getString("abstract"));
paperInfo.setUrl(resultSet.getString("url"));
paperInfo.setKeyword(resultSet.getString("keyword"));
list.add(paperInfo);
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
DBUtil1.close(resultSet,preparedStatement,connection);
}
return list;
}
删除数据的方法“delete”
public void delete(String title) {
String sql = "DELETE FROM paper WHERE name =\""+title+"\""; //连同表中数据一起删除
try {
connection = DBUtil1.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.execute();
} catch (SQLException e) {
e.printStackTrace();
}finally {
DBUtil1.close(resultSet,preparedStatement,connection);
}
}
}
KeynumDao类(实现了与keywords表的连接,用来实现与该表的各种操作)
以下方法操作与上类似,代码展示略
public List<Keynum> selectkey(); //查找前十个最火的关键词
public List<Keynum> selectyear(String year, String meeting) //通过年份和会议名查找最火的十个关键词
Servlet类
-
UserServlet(通过setAttribute设置键值对的方式,将数据传到首页)
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { dao = new PaperInfoDAOImpl(); keynumDao = new KeynumDaoImpl(); List<PaperInfo> paperInfos = dao.selectPaperInfos(); if(req.getParameter("search")!=null) //查询 { paperInfos = dao.getinfo(req.getParameter("search")); req.setAttribute("paperInfos",paperInfos); req.getRequestDispatcher("/front/index.jsp").forward(req,resp); } else if(req.getParameter("delete")!=null) //删除 { dao.delete(req.getParameter("delete")); List<PaperInfo> paperInfos1 = dao.selectPaperInfos(); req.setAttribute("paperInfos",paperInfos1); req.getRequestDispatcher("/front/index.jsp").forward(req,resp); } else if(req.getParameter("p")!=null) //关键词查询 { paperInfos = dao.getkey(req.getParameter("p")); req.setAttribute("paperInfos",paperInfos); req.getRequestDispatcher("/front/index.jsp").forward(req,resp); } else if(req.getParameter("view")!=null) //论文信息展示 { req.setAttribute("paperInfo",dao.selectPaperInfo(req.getParameter("view"))); req.getRequestDispatcher("/front/user.jsp").forward(req,resp); } else //展示线性表和所有数据 { List<Keynum> list = new ArrayList<Keynum>(); list = keynumDao.selectyear("2020" , "cvpr"); for(Keynum keynum : list) { System.out.println(keynum.getKeyword()); } req.setAttribute("cvpr",keynumDao.selectyear("2020" , "cvpr")); req.setAttribute("paperInfos",paperInfos); req.getRequestDispatcher("/front/index.jsp").forward(req,resp); } }- MyServlet(和论文展示页对应)
- ChildServlet(和关键词展示页对应)
Filter(过滤器,将页面解码为UTF-8)
public class EncodingFilter {
public void init(FilterConfig filterConfig) throws ServletException {
}
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
request.setCharacterEncoding("UTF-8");
filterChain.doFilter(request,response);
}
public void destroy() {
}
}
前端
展示表格(通过JSP来展示表格,并实现分页)<% List<PaperInfo> list= (List<PaperInfo>) request.getAttribute("paperInfos"); %>
<% int i=0;%>
<% for(PaperInfo user : list){ %>
<tr>
<td><div class="absrtr"><%=user.getTitle()%></div></td>
<td><%=user.getYear()%></td>
<td><%=user.getMeeting()%></td>
<td><div class="abstract"><%=user.getAbstr()%></div></td>
<td><%=user.getUrl()%></td>
<td><%=user.getKeyword()%></td>
<td>
<form action="homepage" method="get">
<input type="hidden" name="view" value=
"<%=user.getTitle()%>"
>
<input type="submit" value="查看" />
</form>
</td>
<td>
<form action="homepage" method="get">
<input type="hidden" name="delete" value=
"<%=user.getTitle()%>"
>
<input type="submit" value="删除" />
</form>
</td>
</tr>
<% } %>
通过表单实现搜索
<form class="navbar-form navbar-left" role="search">
<div class="form-group">
<input type="text" class="form-control" name="search"/>
</div> <button type="submit" class="btn btn-default">搜索</button>
</form>
删除和查找同上,通过表单实现
通过bootstrap,jquery,echart,highchart来实现标签云,条形图和走势图,数据部分同样使用了jsp来进行前后端交互
<script src="<%= basePath+"javascript/jquery-1.8.3.js" %>"></script>
<script src="<%= basePath+"javascript/highchart.js" %>"></script>
<script src="<%= basePath+"javascript/exporting.js" %>"></script>
<script src="<%= basePath+"javascript/Jcloud.js" %>"></script>
<script src="<%= basePath+"javascript/bootstrap.js" %>"></script>
<link rel="stylesheet" href="<%= basePath+"css/cloud.css" %>" type="text/css">
<link rel="stylesheet" href="<%= basePath+"css/style1.css" %>" type="text/css">
<script src="<%= basePath+"javascript/chart.js" %>" style="width: 50%"></script>
<script style="width: 50%">
var data = [
<% List<Keynum> list= (List<Keynum>) request.getAttribute("keynumList"); %>
<% for(Keynum keynum : list){ %>
{xAxis:'<%=keynum.getKeyword()%>',value:<%=keynum.getAppeartimes()%>},
<% } %>
]
</script>
附加功能
#### 爬虫爬虫的实现(只能爬取由html构成的网站,对助教给的那三个网站爬去不了,但是学了很久,又不想放弃,就写在这里了。。。)
Spider.create(new MyProcesser())
//.addUrl("https://dblp.uni-trier.de/db/conf/eccv/eccv2020-1.html")
.addUrl("https://cnblogs.com/") //爬取csdn
.addPipeline(new ConsolePipeline()) //爬取试着
.addPipeline(new JsonFilePipeline("e:/WebLib")) //保存为jaso文件
.addPipeline(new FilePipeline("e:/File")) //保存为html文件
.addPipeline(new MyPipeline()) //过滤
.run(); //运行
选择爬取网站的格式,定位
public void process(Page page) {
//System.out.println(page.getHtml().toString()); //获得网站的H5
//page.addTargetRequests((page.getHtml().links().all())); //爬取全部内容
page.addTargetRequests(page.getHtml().links().regex("https://www.cnblogs.com/[\\w\\-]+/p/[0-9]+.html").all()); //博客园
page.putField("title",page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/span")); //通过xpath来定位要查找的数据
//page.addTargetRequests(page.getHtml().links().regex("https://link.springer.com/chapter/[0-9\\-\\%\\.]+.html").all());
}
public Site getSite() {
return Site.me().setSleepTime(100).setRetrySleepTime(3);
}
连接池(DBCP连接池)
这也是一个半成品的代码,明明没有报错,在别的程序上也能实现,可是在这里就不行了,最后本来想改改看,可是因为本人实力不足,外加同伴没有经验,虽然去专门学习了可是也只能到最后的半成品。
static String driver = "com.mysql.jdbc.Driver";
static String ip="rm-2zeo875ys8j8pq6epuo.mysql.rds.aliyuncs.com"; //IP名字
static int port=3306; //端口
static String database = "sfjteam"; //数据库名字
static String encoding = "UTF-8";
static String loginName = "wzn";
static String password = "Ww123456";
static int firSize = 10; //初始化线程池大小
static int maxId = 20; //最大空闲数量
static int minId = 5; //最小空闲数量
static int maxAct = 50; //最大活跃数
static int maxWait = 1000; //最长等待时间
public static void init(BasicDataSource basicDataSource) //初始化basicDataSource
{
String url = String.format("jdbc:mysql://%s:%d/%s?characterEncoding=%s&serverTimezone=GMT", ip, port, database, encoding);
basicDataSource.setDriverClassName(driver);
basicDataSource.setUrl(url);
basicDataSource.setUsername(loginName);
basicDataSource.setPassword(password);
basicDataSource.setInitialSize(firSize);
basicDataSource.setMaxIdle(maxId);
basicDataSource.setMinIdle(minId);
basicDataSource.setMaxTotal(maxAct);
basicDataSource.setMaxWaitMillis(maxWait);
}
public Connection getConn(BasicDataSource basicDataSource)
{
Connection conn = null;
init(basicDataSource);
try{
conn = basicDataSource.getConnection();
} catch (SQLException e){
e.printStackTrace();
}
return conn;
}
/*public static void main(String[] args) throws SQLException {
BasicDataSource basicDataSource= new BasicDataSource();
DBUtil dbUtil = new DBUtil();
Connection connection = dbUtil.getConn(basicDataSource);
String sql = "select * from books";
PreparedStatement preparedStatement = null;
try{
preparedStatement = connection.prepareStatement(sql);
ResultSet resultSet = preparedStatement.executeQuery();
while(resultSet.next()){
//String title = resultSet.getString(2);
//double price = resultSet.getDouble(3);
}
if(connection !=null){
connection.close();
}
} catch (SQLException e){
e.printStackTrace();
}
}*/
结对讨论过程
-
刚得知结对课题时,我们就进行了分工,采用交叉合作的方式,这样的好处在于,当自己陷入bug而头脑发昏的时候,另一个清醒的头脑会发挥极大效益。
-
因为是结对完成课题,交流讨论是必然的,但是大伙儿又都认识,所以比如在QQ、微信上扣文字、发语音,哪里有在宿舍、自习室、空教室里交流来得自来?因此,线上的交流就没有线下来的好,于是我们就放了平时交流时被“偷拍”的照片。
-
小宋和小毛一起讨论
-
-
小毛和小宋一起Debug

心路历程和收获、队友评价
心路历程:最开始时候一直担心写不完,因为上学期的JavaWeb很水(大家都这么觉得),我们对web独立开发也算是第一次:但是在对JSP,servlet进行深入学习后,我们发现JavaWeb是可以实现的,但是可能很难;在结束前一周左右时,写了一个小的Javaweb项目,发现已经有了思路;但是这时候因为太过夸大,也导致了爬虫技术和数据池的半成(虽然学习这东西花了我3天的时间,可能咱俩太笨了。。);但是当作业的完成,我们心中只有满满的成就感,兴奋之情溢于言表。
- 小宋的收获:这一次掌握了JavaWeb的编程技术,可以让我以后在学习各种Web框架的时候更加轻松,当然,对项目的时间管理上又获得了经验。
- 小毛的收获:这一次终于明白了前端对界面的强迫症,那是改了又改呐,留下了一大盆泪水,不过终于搞好了!同时,学会了许多非常超级实用的知识,总而言之就是,我很期待下一次的表现!
小宋:在和毛sir交流后,他表现出来了平时没有的执行力,虽然他的编程能力不强,但是他对界面的设计和对新知识的学习能力还是值得信赖的,我感觉下次实践我可以和他做出更棒的项目。
小毛:宋sir真乃奇才也!俺们发现只要我们付出努力、拼搏,就不知不觉解决了好多问题啊!我们的合作将会越来越强大!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号