PyTorch 深度学习实践 第8讲:Dataset and Dataloader
第8讲:Dataset and Dataloader

- Epoch:参与训练的所有进行反向正向传播的数据
- Batch-Size:批量大小:正向,反向,更新所用的训练样本的数量
- Iteration:内层迭代次数
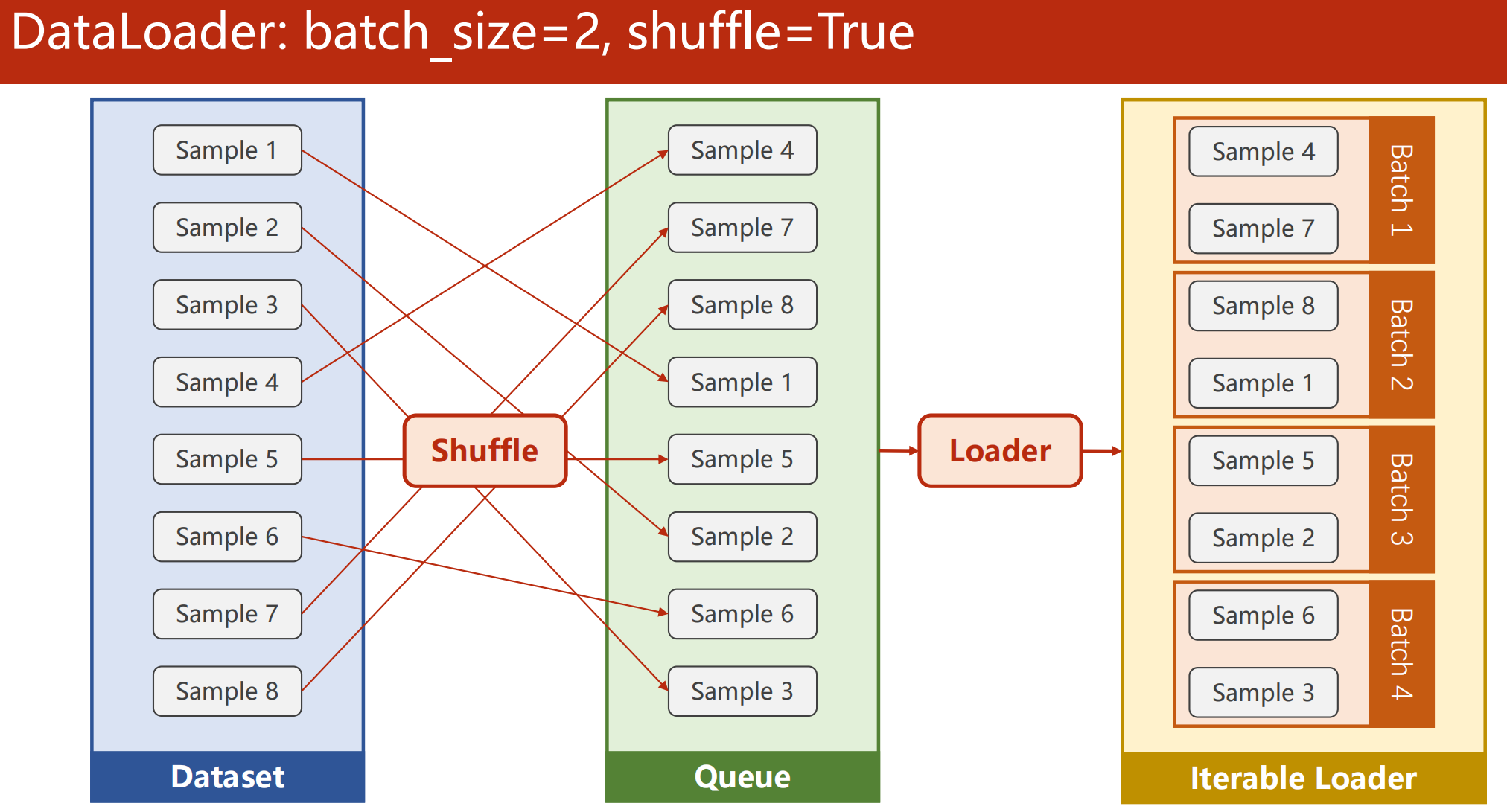
- Dataset支持索引操作,提供数据集的长度
- Shuffle:打乱数据集,是数据具有随机性
- Loader分组:将打乱的数据分组成每个Batch,用来for循环依次拿Batch
代码:
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# Dataset是一个抽象类,不可实例化,需要定义一个类继承自Dataset
#Dtaloader帮助在pytorch中加载数据的一个类
1. Prepare dataset (Dataset and Dataloader)
# DiabetesDataset继承自Dataset,实现一下三个函数:
# __init__()是初始化函数,加载数据集
# __getitem__()魔法函数:检索索引取样本(x,y)
# __len__()魔法函数:获取数据集长度
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # shape(多少行,多少列),shape[0]选择所有的样本数目
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
#自定义DiabetesDataset的对象dataset
#传入dataset,小批量容量,是否打乱,num_workers 多线程:构成Mini-batch需要几个并行的进程来读取数据,提高数据读取效率
2.Design model using Class (inherit from nn.Module)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
3.Construct loss and optimizer (using PyTorch API)
criterion = torch.nn.BCELoss(reduction='mean')#计算loss
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
4.Training cycle(forward, backward, update)
if __name__ == '__main__':#windows下必须封装
for epoch in range(100):
for i, data in enumerate(train_loader, 0):#取一个batch迭代
# train_loader 是先shuffle后mini_batch
inputs, labels = data #输入x,labels是输出y
#forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
#backward
optimizer.zero_grad()
loss.backward()
#update
optimizer.step()
5.错误
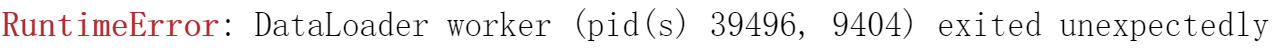
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
#需要修改将Dataloader的线程改为0,即num_workers=0
0 0 0.7828301787376404
0 1 0.8508627414703369
0 2 0.9170447587966919
0 3 0.8455469608306885
0 4 0.9549336433410645
0 5 0.7746846079826355
0 6 0.816917359828949
.......
99 16 0.6436178684234619
99 17 0.7023955583572388
99 18 0.6234514117240906
99 19 0.6436522603034973
99 20 0.6040745973587036
99 21 0.6632190942764282
99 22 0.6829573512077332
99 23 0.6461904644966125
6.补充:
1.shape[0],shape[1]:
import numpy as np
k = np.matrix([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
#注意:列表索引必须是整数或片,而不是元组
#行:样本 0 列:特征 1
print(np.shape(k)) # 输出(3,4)表示矩阵为3行4列
print(k.shape[0]) # shape[0]输出3,为矩阵的行数
print(k.shape[1]) # 同理shape[1]输出列数
(3, 4)
3
4
7.区别总结:
- 数据准备:重新定义三个函数,添加dataloader
- 训练循环:使用嵌套循环对内层batch

 浙公网安备 33010602011771号
浙公网安备 33010602011771号