OO期末&第四单元总结
OO第四单元博客
提纲
- 总结本单元作业的架构设计
- 总结自己在四个单元中架构设计思维及OO方法理解的演进
- 总结自己在四个单元中测试理解与实践的演进
- 总结自己的课程收获
- 立足于自己的体会给课程提三个具体的改进建议
架构设计
类的设计
主要为一个操作接口类,及数个有关类图、状态图、顺序图的类,后者根据UmlElement的层次结构进行适当拆分。
-
Main
-
MyImplemetation 操作接口
- FindClassResult 对操作接口中需要寻找类的返回内容进行封装
-
MyClass 类图
- MyOperation 类图中的操作
-
MyStateMachine 状态图
-
MyInteration 顺序图
- MyLifeLine
内容的存储
关于类中内容的存储,主要有两个问题:
第一大问题是要实现ID, Name, Element三者之间的寻找,有时还要检测Name的重复性;其中ID和Element两两无重复,Name会有重复。本次作业主要通过两个HashMap实现,第一个HashMap关联的Key为ID,Value为Element;第二个HashMap的Key为Name,Value为ID。Name重复性检测在存储数据时完成,若当时第二个HashMap已有相应name的Key,则name重复。
第二个人问题是存储多种类型UmlElement时容器的设计问题。如果将所有类都单独设计两个HashMap则会过于繁琐,也无法实现需要查找跨不同类UmlElement的操作。对这个问题,我主要关注具体的需求,有需求的则单独构建两个HashMap,同时设立一个存储一切UmlElement的“顶层”HashMap。
四个单元架构设计的思维
第一单元
对表达式的解析、展开和化简,突出层次性。实现数据层次的抽象。
从Pre到第一单元,主要实现了从“别人设计类”到“自己设计类”的转变,对类的理解也从简单的”不同物体“深化到了程序设计时的抽象层次上。
但由于表达式中“递归下降”本身有一些面向过程的色彩,刚开始理解时出现了一些疑惑,写出了面向过程的代码。
第二单元
这个单元的架构设计上主要考虑三个方面:一是对电梯本身和电梯控制的区分,二是对需求的接收-处理时用到的生产者-消费者模式思想,三是对request进行适当封装。
难点在多线程的理解、及线程保护的处理上。认识多线程。我发现我在Sychronized-notify的设计上虽然实现了线程安全,但设计得比较杂碎,不利于别人在读代码时的理解。
第三单元
加入了Exception的处理和接口的实现。在类的设计上,实现已有的要求兼具适当封装。学习JML。
第四单元
理解UML。在实现已有的要求的基础上结合对内容层次结构的考虑。内容层次结构需要自己通过理解UML的存储存储结构去理解。与此同时,也学习了UML的数据存储结构。
阅读大量别人写的代码(官方包),接触package的应用。
测试理解与实践的演进
第一阶段-朴素认知:主要依靠课程网站上的评测机,及自己构造的简单样例,以之前的惯性思维“完成测试”,对测试并无深入理解;
第二阶段-依靠评测机的随机样例生成:发现以上方法不能保证完备性,经常会出现没有检测到的问题
第三阶段-评测机与主动构造样例相结合:理解老师讲的“在写程序之前提前想好测试样例”——主要针对边界条件等;同时使用评测机;接触单元测试。
课程收获
- 面向对象、架构设计的理解
- Java语法:得益于教材的精心设计,学习非常快,效率很高
- 提升编程能力:既是大代码量的训练,也涉及了之前学过的数据结构的知识
- git的使用:从0到熟悉
- 对测试的理解
- 时间安排上:课程的难点不仅在作业本身,更在时间安排上,如果错过了时间,即使有能力完成,也会失去分数
三个改进建议
- 第一单元的引导:表达式中“递归下降”本身有一些面向过程的色彩,刚开始理解时出现了一些疑惑,看到其他同学的博客也提到了这个问题,不知道课程组是否可以给予一些引导,减少同学学习过程中的弯路
- 增加应用讲解:学习UML、JML、Junit时并不非常清楚的了解以上技术在现今的工业界具体有哪些应用,有时网上的资料也非常少,建议可以增加这部分的讲解
- 统计作业完成用时:现在大家对OO用时的理解主要在一个字“长”上,但似乎并无准确认识。建议在收集作业时一并收集作业完成用时,并对同学展示,一方面有利于同学对自己能力的定位,另一方面也可以增强课程组对学生的了解、以及对每次作业情况的了解
OO第一单元博客(补交):初识面向对象
1 程序分析
-
主要特点:
- 按照题目
形式化表述中的主要思路进行类和因子的构建:分为多项式、项、因子三大类,因子作为父类,被不同细分子类因子继承; - 针对自定义函数,采用“字符串替换”的思路处理;
- 未使用HashCode、HashMap等;
- 按照题目
-
重构历程:
- 在第二次作业进行重构,主要是进行不同类因子的拆分 和 针对重复使用字符串处理方法的封装(方便复用);
-
最终架构:(清晰及方便考虑,已省略set、get等方法)
![]()
-
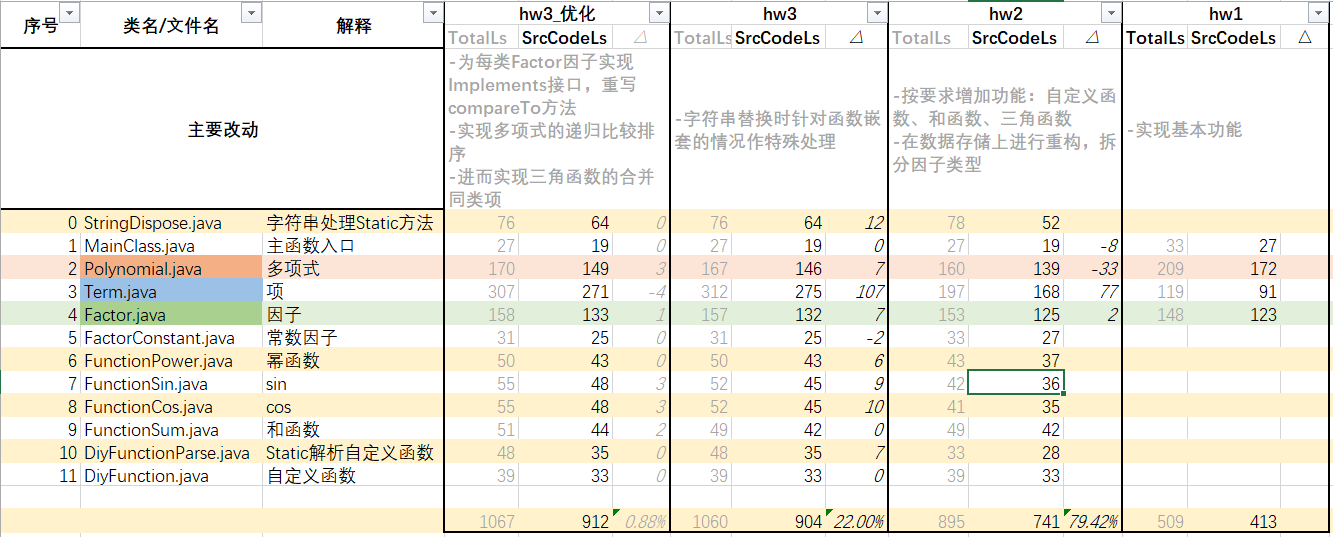
分Class行数分析及每版的主要改动:
![]()
-
横向比较得出的不足:
- 架构设计的差距
- 方法实现的美观性
- 重复造轮子(主要是对已有的轮子不熟)
- 代码风格,主要是注释的清晰程度

2-3 Bug分析
2.1 公测和互测出现的Bug
第二次作业:公测得分67.9868分,3个点错误(以下三个问题)。
- 使用
Long解析BigInteger的创建,实际无法处理BigInteger;- 优化时将
sin(0)直接输出为0,没有考虑sin(0)**0=1;- 幂函数替换未外加括号;
第三次作业:公测得分61.1536分,4个点错误(3个点因问题1,1个点因问题2)。
- sum函数无法处理
BigInteger的情况;- 使用字符串替换函数时的逻辑小问题;
- 编写
cos代码时直接复制粘贴了sin的代码(toString)函数,导致cos(0)输出0(疏于检查,因此问题扣分多于其他Bug之和)。
本次作业中,互测被发现的Bug是强测的子集(可能与所在B/C房有关)。
2.2 出现Bug代码的特征分析
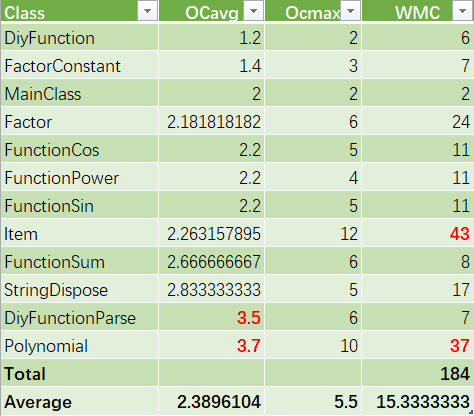
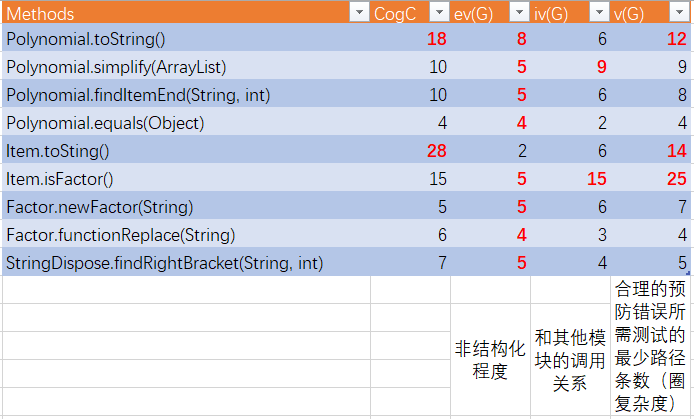
-
使用MatrixReloaded工具进行分析结果(如图)。从统计规律来看,复杂度较高的程序片段更容易出现Bug,减小方法复杂度、优化架构有利于减小Bug的出现可能;
![]()
![]()
-
自己写代码时,思路不够清晰的地方容易出Bug;
-
易出Bug的地方有以下特征(也是我互测中Hack他人的主要数据构造策略):
- 特殊值:特殊性主要在于程序中对其作出了特殊处理(尤其是优化时作出的处理,像
sin(x-x)这种),一旦特殊处理就容易出Bug; - 设计要求的“边界”:核心部分相对不容易有问题,一旦有问题也很容易发现;往往不容易被发现的是使用较少的边界部分。可以进一步地分为两类:
- 数据边界:如sum函数处理超出
long必须使用BigInteger的情况; - 操作边界:触发次数的特点是比较少在编写程序时容易对其理解模糊,需要特别关注才能搞清楚。如
i**+2等。
- 数据边界:如sum函数处理超出
- 特殊值:特殊性主要在于程序中对其作出了特殊处理(尤其是优化时作出的处理,像
3.1 发现Bug策略及启示
-
Hack他人:没有做评测机,构造数据的策略见2.2第3点。
![]()
-
启示:测试和Debug是程序设计中比较重要、又比较有难度的一个步骤。经过debug、hack他人的训(折)练(磨),老师在上课时讲解的比较科学的测试策略对我的吸引力显著增加。在总结出现Bug程序片段特征的基础上,争取在写程序时就想好对应的测试数据,多进行主动测试而非被动的改Bug。

4 架构设计体验
完成第一次作业时只是粗浅地只到对象、方法的概念,还不太理解面向的特征,在设计时思考好几种架构,也想到过一个非常简洁美观但完全面向过程的结构。最后还是根据指导书照葫芦画瓢的把程序简单分为多项式、项、因子三类,可以说让自己的程序大体具备了面向对象的特征,但在具体方法的设计、程序的细节上缺乏考虑,很多都不美观。
完成第二次作业时吸取第一次作业的经验和教训,对程序进行了完全的重写/重构。这是最费时费力的一周,虽然我的程序仍然称不上优雅,也使用了老师“并不推荐”的字符串替换方法,但仍然提供了我在第三周作业时不用进行重构的基础。
第三次作业在第二次作业的基础上添加了功能,但因为很快就通过了全部中测点,我没有进行认真地测试,最终出现了一些比较滑稽的低级错误。
总的来讲,这三次作业让我体会到了架构设计的重要性。一方面,分析自己的设计思路,在设计时只是大体的构建到了类的层面,具体方法的实现则是走一步看一步,我想这或许是出现一些错误的原因,也是之后还可以注意改进的点。另一方面,参考优秀的架构、阅读别人的程序确实受益很大,因此也要注意不能闭门造车。
5 心得体会
无论是作业还是理论课,总体感受都是挺充实的。不过希望自己能在时间节点的把控上更明智一些。
OO第三单元博客(补交)
提纲
- 分析在本单元自测过程中如何利用JML规格来准备测试数据
- 梳理本单元的架构设计,分析自己的图模型构建和维护策略
- 按照作业分析代码实现出现的性能问题和修复情况
- 请针对下页ppt内容对Network进行扩展,并给出相应的JML规格
- 本单元学习体会
自测时自测数据的准备
-
写评测机,构造随机性普遍数据
# 数据生成部分 import random import _thread import string # 0 指令及指令数 ops = ['ap', 'ar', 'qv', 'qps', 'qci', 'qbs', 'ag', 'atg', 'dfg','qgps', 'qgvs', 'qgav', 'am', 'sm', 'qsv', 'qrm', 'qlc', 'arem', 'anm', 'cn', 'aem', 'sei', 'qp', 'dce', 'qm', 'sim'] #ops = ['ap', 'ar'] numOfInput = 30000 # 指令条数 # 1 评测模式 useOpNumLimit = False # 是否使用指令数限制(针对互测) # 2 指令参数限制 # 2.1 person minId = -250 maxId = 250 # (maxPersonId) maxAge = 200 maxValue = 1000 # 2.2 Group maxGroupId = 20 # 2.3 Message maxMessageId = 300 minSocialValue = -1000 #题目限制 [-1000,+1000] maxSocialValue = 1000 maxMoney = 200 # 题目限制:[0,200] maxEmojiId = 100 # 题目限制:[0,10000] maxNoticeLen = 98 # 题目限制:[1,100] deleteColdEmojiLimit = 3 # 2.4 姓名 strSize = 10 chars = string.ascii_letters # + string.punctuation myChars = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'] def random_string_generator(strSize, allowed_chars): return ''.join(random.choice(allowed_chars) for x in range(strSize)) # 一般性数据 def create_normal(fileName): input = [] for i in range(numOfInput): op = random.choice(ops) str = op if op == 'qbs' or op == 'qps': pass elif op == 'ap': # add person id = random.randint(minId, maxId) name = random_string_generator(1, myChars) age = random.randint(0, maxAge) str += (" %d BUAA?BUA%s. %d" % (id, name, age)) elif op == 'ar': # add relation id1 = random.randint(minId, maxId) id2 = random.randint(minId, maxId) value = random.randint(0, maxValue) str += (" %d %d %d" % (id1, id2, value)) elif op == 'qv' or op == 'qci': # queryValue, queryCirlcle id1 = random.randint(minId, maxId) id2 = random.randint(minId, maxId) str += (" %d %d" % (id1, id2)) elif op == 'atg' or op == 'dfg': # AddToGroup, deleteFromGroup id1 = random.randint(minId, maxId) id2 = random.randint(0, maxGroupId) str += (" %d %d" % (id1, id2)) elif op == 'ag' or op == 'qgps' or op == 'qgvs' or op == 'qgav': # add_goup query_group_people_sum query_group_value_sum query_group_age_var id = random.randint(0, maxGroupId) str += (" %d" % (id)) elif op == 'am': # query_group_people_sum id = random.randint(0, maxMessageId) socialValue = random.randint(minSocialValue, maxSocialValue) type = random.randint(0, 1) # randint包含左右极限 pid1 = random.randint(minId, maxId) pid2 = random.randint(minId, maxId) gid = random.randint(0, maxGroupId) str += (" %d %d %d %d" % (id, socialValue, type, pid1)) if type == 0: str += (" %d" % (pid2)) else: str += (" %d" % (gid)) elif op == 'sm' or op == 'sim': # sendMessage sendIndirectMessage id = random.randint(0, maxMessageId) str += (" %d" % (id)) elif op == 'qsv' or op == 'qrm' or op == 'qlc' or op == 'qm' or op == 'cn': # query_social_Value query_received_messages query_least_connection queryMoney id = random.randint(minId, maxId) str += (" %d" % (id)) elif op == 'arem' or op == 'anm' or op == 'aem': # add red envelop message mid = random.randint(0, maxMessageId) str += " %d" % mid if op == 'arem': str += " %d" % random.randint(0, maxMoney) elif op == 'anm': str += " %s" % random_string_generator(random.randint(10, maxNoticeLen), chars) elif op == 'aem': str += " %d" % random.randint(0, maxEmojiId) else: pass type = random.randint(0, 1) str += " %d %d" % (type, random.randint(0, maxId)) if type == 0: str += " %d" % random.randint(minId, maxId) else: str += " %d" % random.randint(0, maxGroupId) elif op == 'dce' or op == 'qp' or op == 'sei': limit = random.randint(0, deleteColdEmojiLimit) str += " %d" % limit else: print("DataCreateError") input.append(str) if useOpNumLimit == True: outputList = delete_op_outof_limit(input) else: outputList = input f = open("%s.txt" % (fileName), "w+", encoding='utf-8') for i in range(len(outputList)): print(outputList[i], file=f) f.close()# 自动评测(有些繁琐) # -*- coding:utf-8 -*- import os import DataCreate import subprocess import datetime import time #设置参数:评测次数, 是否碰到错误就停止 timesOfJudge = 3 stopWhenErr = False jarNames = ["lpf.jar", "lsh.jar", "gbl.jar"] judgeMachineDir = "D:\\OO\\code\\oo-homework\\unit3\\MachineJudge" # 评测文件夹 #firstJudgeInput = ["test1", "1", "1new", "20220514-164734input004"] #firstJudgeInput = ["20220515-170425input009"] firstJudgeInput = [] inputFileName = "" jarName = "" outputFileName = "" removeFileName = "" cmd0 = "chcp 65001" cmd1 = "cd " + judgeMachineDir # 进入评测文件夹 cmd2 = "java -jar " + jarName + " < " + inputFileName + " > " + outputFileName cmd3 = "rm " + removeFileName cmdSep = " && " def calcmd(jarName): global cmd1, cmd2, cmd3, cmdSep cmd1 = "cd " + judgeMachineDir # 进入评测文件夹 cmd2 = "java -jar " + jarName + " < " + inputFileName + " > " + outputFileName cmd3 = "rm " + removeFileName def removeFile(fileName): global removeFileName removeFileName = fileName calcmd("") #os.system(cmd1 + cmdSep + cmd3) def working(inputName, jarName): global inputFileName, outputFileName inputFileName = inputName + ".txt" outputFileName = inputName + "-" + jarName + ".txt" calcmd(jarName) # print(cmd1 + cmdSep + cmd2) nowTime = time.time() os.system(cmd1 + cmdSep + cmd2) useTime = time.time() - nowTime # p = subprocess.Popen(cmd1 + cmdSep + cmd2) # time.sleep(120 * 1000) # p.kill() print("%s运行完成, 用时 %3.3f s" % (jarName, useTime)) return outputFileName def fileCmp(fileName1, fileName2, inputName): global diary f1 = open(fileName1, 'r', encoding = 'gbk', errors = 'ignore') f2 = open(fileName2, 'r', encoding = 'gbk', errors = 'ignore') f0 = open(inputName + ".txt", 'r', encoding = 'gbk', errors = 'ignore') errInfo = "" isEqual = True j = 0 # 行数 while True: str0 = f0.readline() str1 = f1.readline() str2 = f2.readline() j += 1 if str1 == "" and str2 == "": break elif str1 == "" or str2 == "": errInfo += "评测至第%d行发现行数不同(首行为第1行)" % (j) isEqual = False break elif str1 != str2: errInfo += "第%d行不同 (首行为第1行),指令为 %s, 前者输出 %s , 后者输出 %s" % (j, str0, str1, str2) isEqual = False break else: continue f1.close() f2.close() f0.close() if (errInfo == ""): errInfo = "完全相同" print("%s与%s: " % (fileName1, fileName2) + errInfo) print("%s与%s: " % (fileName1, fileName2) + errInfo, file = diary) return isEqual def judgeAll(inputName, cnt): global diary result = [[] * 0] * 0 errorInfo = "" findError = False for i in range(len(jarNames)): print("第%d个程序 %s开始运行" % (i+1, jarNames[i])) flag = False outputFileName = working(inputName, jarNames[i]) # 运行 for j in range(len(result)): isEqual = fileCmp(outputFileName, result[j][0], inputName) if isEqual == True: result[j].append(outputFileName) flag = True break if flag == False: result.append([outputFileName]) print("第%d次评测完成,共得到%d份结果" % (cnt, len(result))) print("第%d次评测共得到%d份结果" % (cnt, len(result)), file = diary) if len(result) != 1 : str = "" for i in range(len(result)): str = "第%d份: " % (i + 1) for j in range(len(result[i])): str += "%s " % (result[i][j]) print(str, file=diary) if len(result) != 1: findError = True if (findError == False): for i in range(len(result[0])): removeFile(result[0][i]) return findError now = datetime.datetime.now() timeStr = now.strftime("%Y%m%d-%H%M%S") cnt = 0 # 评测次数计数 flag = False diary = open(timeStr + "diary.txt", "w+") print("评测开始时间%s" % (timeStr)) if len(jarNames) <= 1: print("需要提供多个jar对比评测,评测未成功开始") firstJudgeInputCnt = 0 errorCnt = 0 while cnt < timesOfJudge and len(jarNames) > 1: flag = False cnt += 1 if firstJudgeInputCnt < len(firstJudgeInput): inputName = firstJudgeInput[firstJudgeInputCnt] firstJudgeInputCnt += 1 print("=================第%03d次评测开始,使用给定数据 %s=================" % (cnt, inputName)) print("=================第%03d次评测开始,使用给定数据 %s=================" % (cnt, inputName), file = diary) else: inputName = timeStr + "input%03d" % (cnt) DataCreate.create_normal(inputName) print("=================第%03d次评测开始,使用随机数据 %s=================" % (cnt, inputName)) print("=================第%03d次评测开始,使用随机数据 %s=================" % (cnt, inputName), file = diary) flag = judgeAll(inputName, cnt) print("++++++++++++++++++++++第%03d次评测完成+++++++++++++++++++++++++++" % (cnt)) print("++++++++++++++++++++++第%03d次评测完成+++++++++++++++++++++++++++" % (cnt), file = diary) if flag == True and stopWhenErr == True: break if flag == True: errorCnt += 1 print("所有评测完成!错误%d/%d次" % (errorCnt, timesOfJudge)) print("所有评测完成!错误%d/%d次" % (errorCnt, timesOfJudge), file = diary) diary.close() -
对于重点操作,构造强数据,检验正确性
举例:针对qlc的数据
ap 1 1 1 ap 2 2 2 ..... ap 3000 300 3000 ar [] [] [] ...... ar [] [] [] qlc 1336 -
对于重点操作,考虑卡时间限制的数据,并判断会不会超时
架构设计
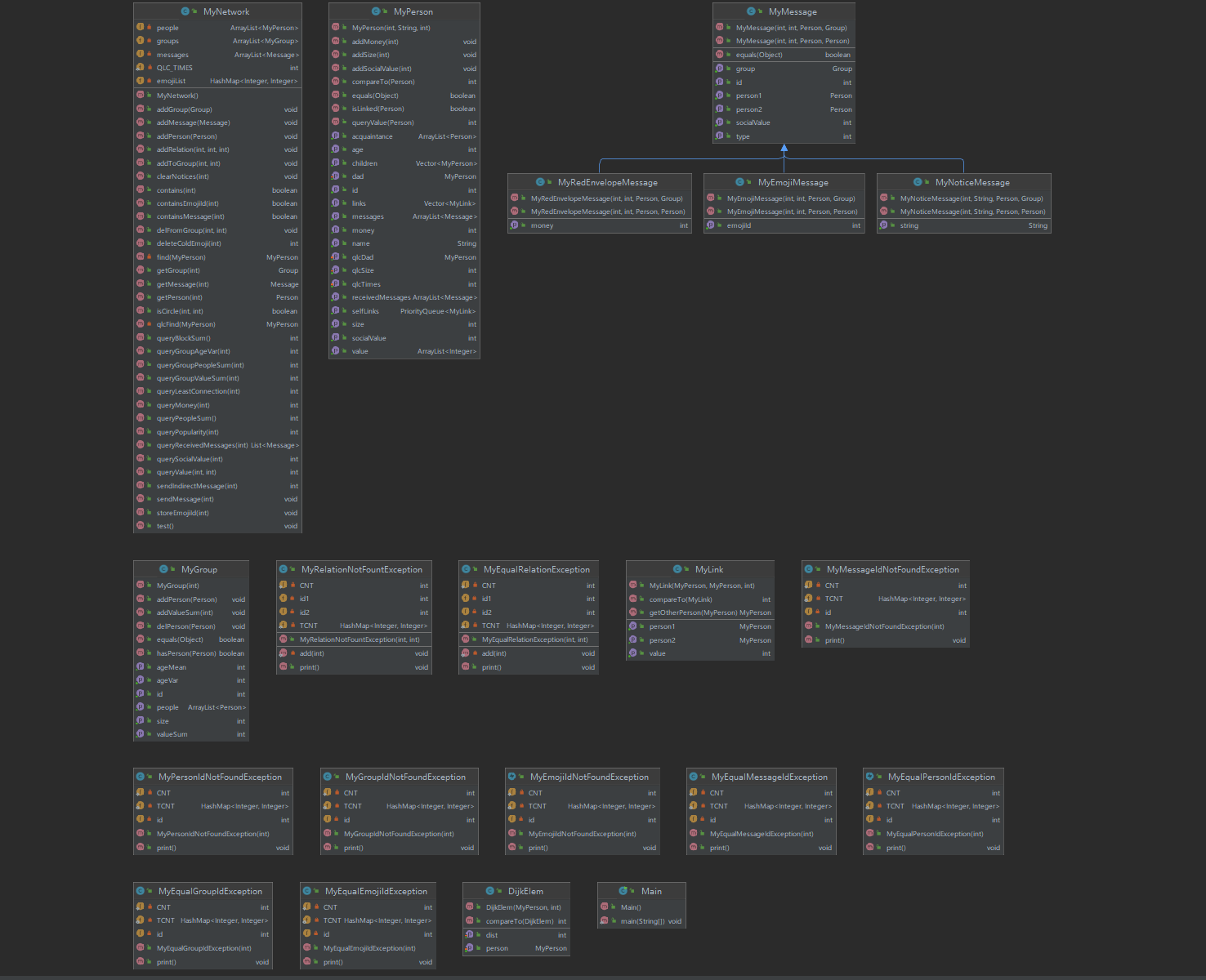
-
类图
![]()
-
构建和维护策略
- 初始构建
- 针对qci与qbs,使用并查集优化
- 针对qlc与sim,使用图中最小生成树(Kruskal)和最短路径的算法(dijkstra)
- 动态维护,针对关键数据予以缓存,提升运行效率
性能问题和修复情况
-
第二次作业,面对互测中的超强数据出现了qgvs超时的情况
解决策略:单独维护socialValueSum变量
扩展
假设出现了几种不同的Person
- Advertiser:持续向外发送产品广告
- Producer:产品生产商,通过Advertiser来销售产品
- Customer:消费者,会关注广告并选择和自己偏好匹配的产品来购买 -- 所谓购买,就是直接通过Advertiser给相应Producer发一个购买消息
- Person:吃瓜群众,不发广告,不买东西,不卖东西
如此Network可以支持市场营销,并能查询某种商品的销售额和销售路径等 请讨论如何对Network扩展,给出相关接口方法,并选择3个核心业务功能的接口方法撰写JML规格(借鉴所总结的JML规格模式)
几种类型的Person都可通过实现Person接口实现。在此基础上,Advertiser需要新增属性表示发送广告的ID, Producer需要新增属性表示生产产品的Id,Customer新增属性表示自身产品偏好的id。
-
查询销售额
/*@ public normal_behavior @ requires (\exist int i; 0 <= i && i < sales.size(); sales[i].getId() == objectId) @ ensures \result == sales[id]; @ also @ public exceptional_behavior @ signals (ObjectIdNotFoundException e) ((\forall int i; 0 <= i && i < sales.size(); sales[i].getId() != objectId) */ int /*@ pure @*/ getSales(int objectId)throws ObjectIdNotFoundException; -
发送广告
/*@ public normal_behavior @ requires (\exists int i; 0 <= i && i < customers.length; @ customers[i].getId() == id1) && (\exists int i; 0 <= i && i < getAdvertiser(id1).advertisements.length; @ getAdvertiser(id1).advertisements[i].getId() == id2); @ assignable getAdvertiser(id1).advertisements @ ensures (\forall Advertisement i; \old(getAdvertiser(id1).hasAdvertisement(i)); @ getAdvertiser(id1).hasAdvertisement); @ ensures \old(getPerson(id1).advertisements.length) == getPerson(id1).advertisements.length - 1; @ ensures getAdvertiser(id1).hasAdvertisement(getAdvertisement(id2)); @ also @ public exceptional_behavior @ signals (AdvertiserIdNotFoundException e) !(\exists int i; 0 <= i && i < advertisers.length; @ advertisers[i].getId() == id1); @ signals (AdvertisementIdException e) (\exists int i; 0 <= i && i < customers.length; @ customers[i].getId() == id1) && !(\exists int i; 0 <= i && i < getAdvertiser(id1).advertisements.length; @ getAdvertiser(id1).advertisements[i].getId() == id2); @*/ public void sendAdvertisement(int id1, int id2) throws AdvertiserIdNotFoundException,AdvertisementIdException; -
添加Producer
/*@ public normal_behavior @ require (\forall int i; 0 <= i && i < producers.size(); !producers[i].equals(advertiser)) @ assignable persons; @ assignable producers; @ ensures producers.size() == \old(producers.size()) + 1; @ ensures (\exists int i; 0 <= i && i < producers.size(); producers[i].equals(producer)); @ ensures (\exists int i; 0 <= i && i < persons.size(); persons[i].equals(producer)); @ ensures (\forall int i; 0 <= i && i < \old(producers.size()); @ (\exists int j;0 <= j && j < producers.size();producers[j].equal(\old(producer[i])))) @ ensures (\forall int i; 0 <= i && i < \old(persons.size()); @ (\exists int j;0 <= j && j < persons.size();persons[j].equal(\old(persons[i])))) @ also @ public exceptional_behavior @ signals (EqualPersonIdException) (\exists int i; 0 <= i && i < producers.size(); producers[i].equals(producer)) @*/ void addProducer(Producer producer);
学习体会
- 学习了JML契约式编程,体会到了其严谨性和低效率的两方面特点。
- 听工业界人士报告,感受到程序严谨性在某些领域的重要地位。
- 代码量进一步上升,涉及的细节进一步增多,出错的概率也随之增大。一方面要从完成代码时提高正确性入手,另一方面要从加强测试入手,并总结出可持续实现的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号