大数据概述
题目:
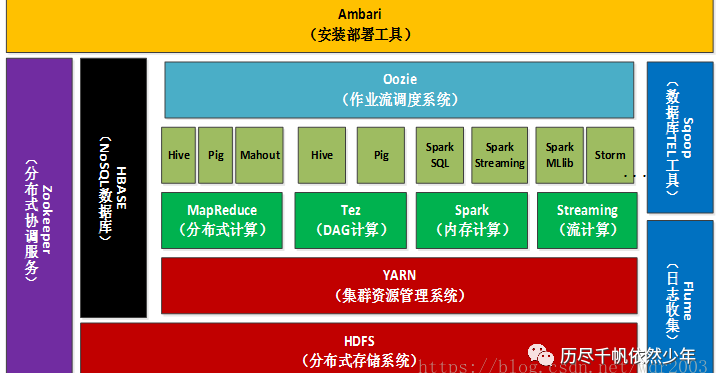
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
2.对比Hadoop与Spark的优缺点。
3.如何实现Hadoop与Spark的统一部署?
回答:
1)Hadoop是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。 Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YARN。
1,HDFS(hadoop分布式文件系统)
1,HDFS(hadoop分布式文件系统)
是hadoop体系中数据存储管理的基础。
2,mapreduce(分布式计算框架)
mapreduce是一种计算模型,用于处理大数据量的计算。
3, hive(基于hadoop的数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
4,hbase(分布式列存数据库)
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。
5,zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
6,sqoop(数据同步工具)
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。
7,pig(基于hadoop的数据流系统)
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。
8,Oozie
Oozie是可扩展可伸缩的工作流协调管理器。Oozie协调的作业属于一次性的非循环作业,例如MapReduce, Streaming, Pipes, Pig, Hive, Sqoop等等都是。Oozie将要调度的作业作为一个单一的作业来管理。Oozie的
调度基于时间跟数据可用性。具有数据感知功能,可以协调作业之间的依赖关系.
8,Oozie
Oozie是可扩展可伸缩的工作流协调管理器。Oozie协调的作业属于一次性的非循环作业,例如MapReduce, Streaming, Pipes, Pig, Hive, Sqoop等等都是。Oozie将要调度的作业作为一个单一的作业来管理。Oozie的
调度基于时间跟数据可用性。具有数据感知功能,可以协调作业之间的依赖关系.
9,Flume
Flume是一个类似facebook的scribe的分布式,高可靠,高可用,高效的数据收集器,一般用于聚合众多服务器上面的大量日志到某一个数据中心。
Flume是一个类似facebook的scribe的分布式,高可靠,高可用,高效的数据收集器,一般用于聚合众多服务器上面的大量日志到某一个数据中心。
10,Hue
Hue是cdh专门的一套web管理器,它包括3个部分hue ui,hue server,hue db。hue提供所有的cdh组件的shell界面的接口。你可以在hue编写mr,查看修改hdfs的文件,管理hive的元数据,运行Sqoop,编写Oozie工作流等大量工作。
Hue是cdh专门的一套web管理器,它包括3个部分hue ui,hue server,hue db。hue提供所有的cdh组件的shell界面的接口。你可以在hue编写mr,查看修改hdfs的文件,管理hive的元数据,运行Sqoop,编写Oozie工作流等大量工作。
11,HCatalog
HCatalog提供表格数据类型到pig,hive,mr的输入数据的转换,HCatalog依赖Hive的元数据存储系统。通过HCatalog的接口pig,hive,mr自到识别这些输入数据的架构。
HCatalog提供表格数据类型到pig,hive,mr的输入数据的转换,HCatalog依赖Hive的元数据存储系统。通过HCatalog的接口pig,hive,mr自到识别这些输入数据的架构。
12,Avro
Avro是一个数据序列化系统。能保存持久化的数据到hdfs,能传输并且反序列化为高级数据结构。类似facebook的thrift,它也是提供多语言客户端支持的。
Avro是一个数据序列化系统。能保存持久化的数据到hdfs,能传输并且反序列化为高级数据结构。类似facebook的thrift,它也是提供多语言客户端支持的。
13,HttpFS
HttpFS提供REST HTTP API来读写hdfs。
HttpFS提供REST HTTP API来读写hdfs。
14,Mahout
Mahout是一个编写基于大数据的机器学习软件,人工智能程序的协助工具。
Mahout是一个编写基于大数据的机器学习软件,人工智能程序的协助工具。
15,Snappy
Snappy是压缩跟解压缩工具,它的应用包括将mr的最终输出结果压缩起来,Sqoop导入数据的时候也可以使用这个压缩引擎.
Snappy是压缩跟解压缩工具,它的应用包括将mr的最终输出结果压缩起来,Sqoop导入数据的时候也可以使用这个压缩引擎.
16,Whirr
Whirr是将hadoop生态系统云化的一个组件。只需要在Whirr的配置文件里指明你需要的hadoop组件,它能够用一个命令将一个hadoop生态系统完整的部署到像Amazon EC2这样的云服务器中,也能够一个命令回收这个hadoop生态系统及其使用的资源。intel的hadoop发行版也可以实现类似快捷部署的功能。
Whirr是将hadoop生态系统云化的一个组件。只需要在Whirr的配置文件里指明你需要的hadoop组件,它能够用一个命令将一个hadoop生态系统完整的部署到像Amazon EC2这样的云服务器中,也能够一个命令回收这个hadoop生态系统及其使用的资源。intel的hadoop发行版也可以实现类似快捷部署的功能。
2)与Hadoop相比,Spark真正的优势在于速度。Spark的大部分操作都是在内存中,而Hadoop的MapReduce系统会在每次操作之后将所有数据写回到物理存储介质上。这是为了确保在出现问题时能够完全恢复,但Spark的弹性分布式数据存储也能实现这一点
3)Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,资源管理和调度依赖YARN,分布式存储则依赖HDFS。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号