Linux高并发服务器开发
Linux高并发服务器开发
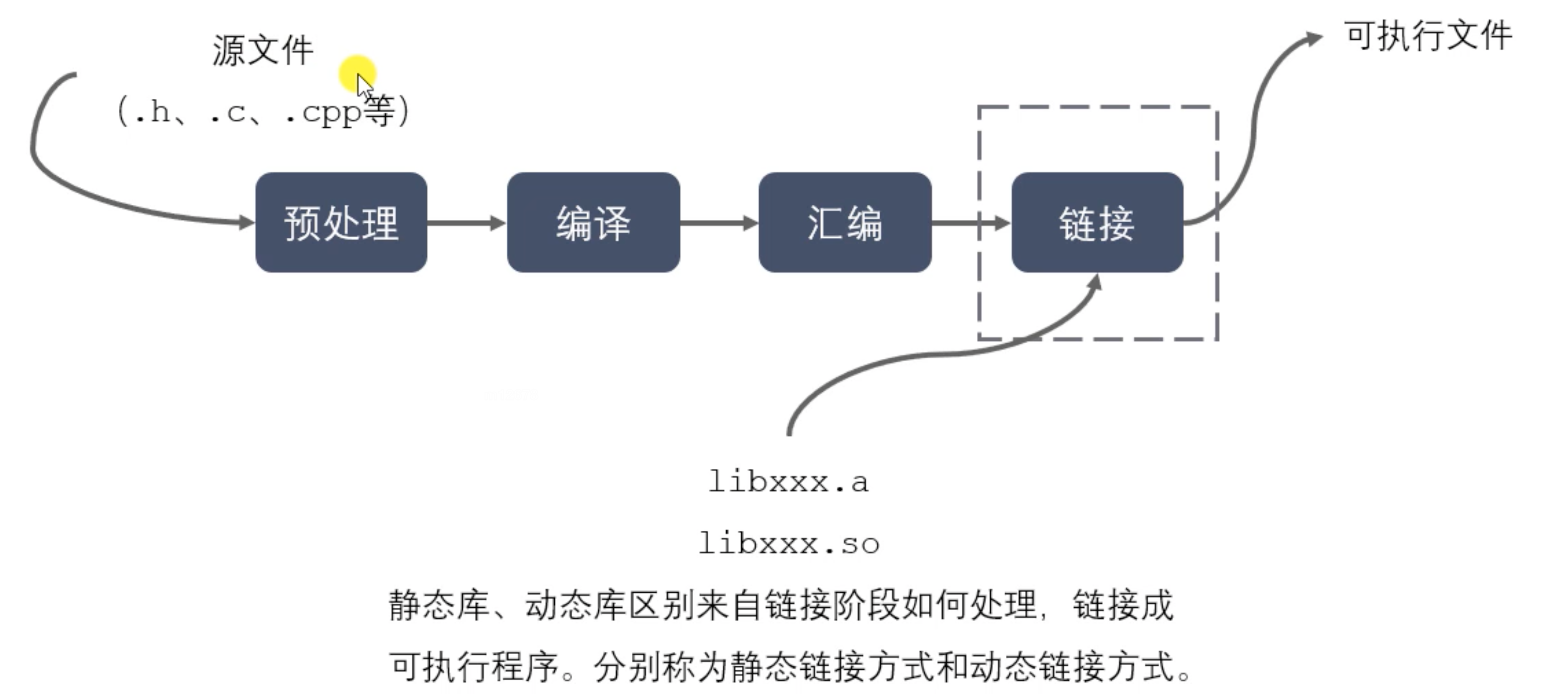
GCC
gcc: GNU C语言编译器
gcc -E:预处理指定的源代码, 不进行编译(预编译)gcc -S:编译指定的源文件,但不进行汇编gcc -c:编译、汇编指定的源文件,但不进行链接gcc -o [file1] [file2] / [file2] -o [file1]:将file2编译成可执行文件file1gcc -I directory:指定include包含文件的搜索目录gcc -g:在编译的时候,生成调试信息,该程序可以被调试器调试gcc -D:在程序编译时,指定一个宏gcc -w:不生成任何警告信息gcc -Wall:生成所有警告信息gcc -On:n的取值范围:0~3。编译器的优化选项的四个级别: -O0表示没有优化, -O1为缺省值,-O3表示优化级别最高gcc -l:在程序编译的时候指定使用的库gcc -L:指定编译的时候搜索的库的路径gcc -fPIC/fpic:生成与位置无关的代码gcc -shared:生成共享目标文件,通常用在建立共享库时gcc -std:指定编译的版本


静态链接库的制作 & 使用
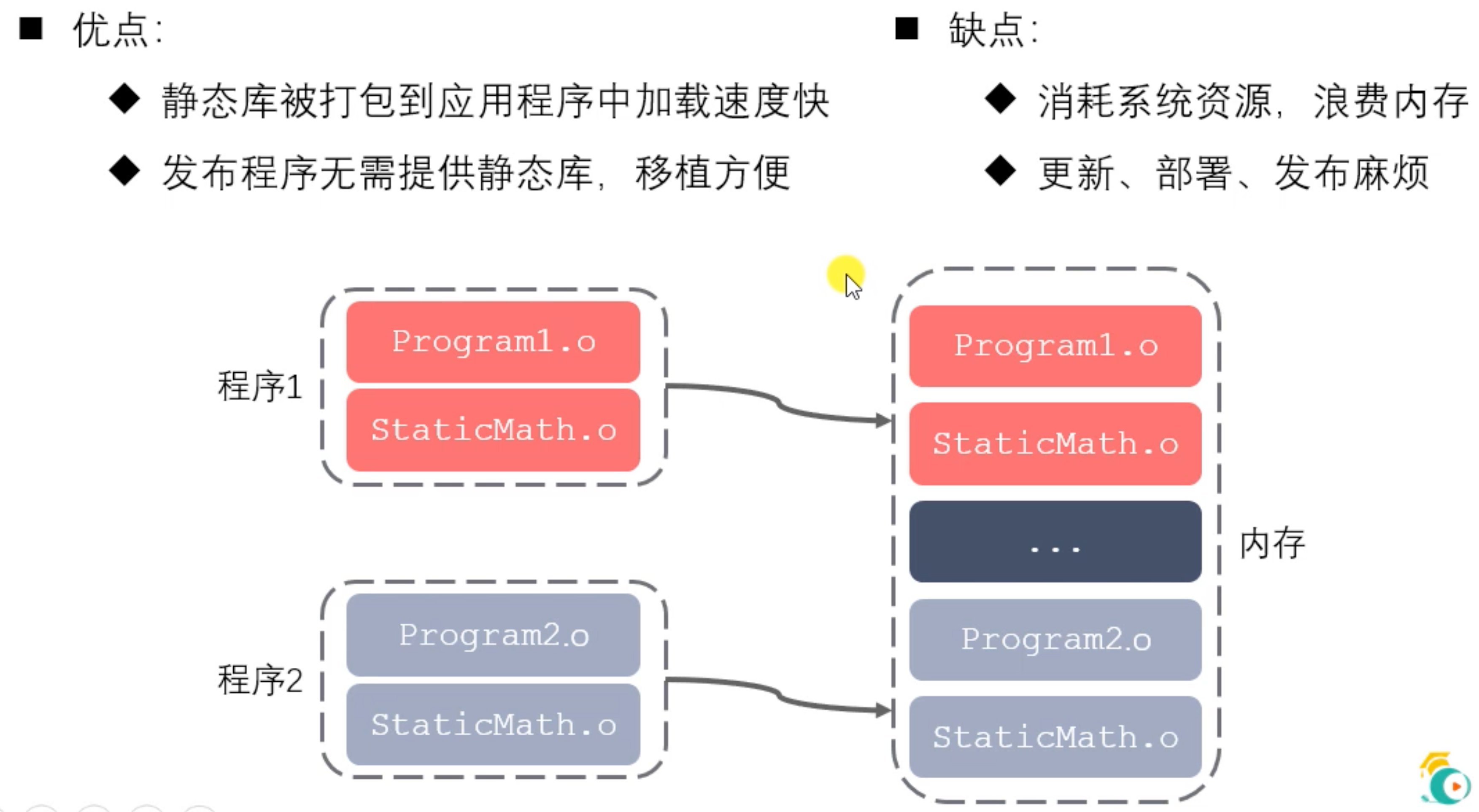
静态链接库在程序链接阶段被复制到了程序中;
动态链接库在链接阶段没有被复制到程序中,而是程序在运行时由系统动态加载到内存中供程序调用。
静态链接库制作
- gcc - c filename.c -> filename.o
- ar rcs libname.a filename1.o filename2.o

静态链接库使用
一个标准的C projects的格式:
- include : 包含需要使用的头文件
- lib:需要使用的动静态链接库
- src:lib中库的源码
- main.c: 主程序
gcc main.c -o main -I ./include/ -L ./lib/ -l calc
动态链接库的制作与使用
gcc -c -fpic a.c b.cgcc -shared a.o b.o -o libcalc.sogcc main.c -o main -I ./include/ -L ./lib/ -l calc- 执行完上述操作后依然会报错,我们可以使用
ldd去查看上述编译好的可执行文件的动态链接库依赖关系 - (临时环境变量配置)设置
LD_LIBRARY_PATH,export $LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/libxxx.soPath - (用户环境变量配置)将临时环境变量配置放到
~/.bashrc即可 - (系统环境变量配置)
sudo vim /etc/profile加上即可 vim /etc/ld.so.config加上绝对路径即可



动静态链接库对比
Makefile
Define
Makefile文件定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新定义,``Makefile也可以执行Shell`脚本的命令。
make是一个命令工具,是用来解释Makefile文件中指令的命令工具。
Makefile文件命名 & 规则
-
文件命名
- makefile or Makefile
-
Makefile规则
-
目标 ...: 依赖 ... 命令 (Shell命令) ... - 目标: 最终生成的文件
- 依赖:生成目标所需要的文件
- 通过执行命令对依赖操作生成目标
-
Makefile 工作原理
- 命令执行之前,需要先检查规则中的依赖是否存在
- 存在,执行命令
- 不存在,向下检查其他规则,检查是否有规则用来生成第一条规则的依赖,如果找到没执行改规则
- 检测更新,执行规则命令中,会比较目标和依赖文件的时间
- Makefile中的其他规则一般都是会为第一条规则服务的
Makefile常用语法
-
自定义变量:src:sub.c...div.c target:main
-
预定义变量
- AR:归档维护程序的名称,默认值为ar
- CC:C编译器的名称,默认值为cc
- CXX: C++ 编译器的名称,默认值为g++
- $@: 目标的完整名称
- $<: 第一个依赖文件的名称
- $^: 所有依赖文件
-
获取变量值$(变量名)
-
模式匹配
- %: 通配符,匹配一个字符串
- %%匹配的事同一个字符串
- %.o:%.c <=> gcc -c $< -o $@
-
函数
-
$ (wildcard PATTERN...)
- 获取指定目录下指定类型的文件列表
- 参数:PATTERN指的是某个或多个目录下的对应的某种类型的文件,如果有多个目录,要使用空格隔开
-
$(wildcard *.c ./sub/*.c) return: a.c b.c ....
-
$(patsubst
, , ) - 查找text中的单词,单词以空格、Tab、回车、换行作分割,是否符合模式pattern,匹配的话以replacement替换
-
# main:sub.o add.o mult.o div.o main.o
# gcc sub.o add.o mult.o div.o main.o -o main
src=$(wildcard ./*.c)
objs=$(patsubst %.c, %.o, $(src))
target=main
$(target):$(objs)
$(CC) $(objs) -o $(target)
%.o:%.c
$(CC) -c $< -o $@
.PHONY:clean
clean:
rm $(objs) -f
GDB调试
通常,在为调试而编译时,我们会()关掉编译器的优化选项(-O), 并打开调试选项(-g)。另外,-Wall在尽量不影响程序行为的情况下选项打开所有warning,也可以发现许多问题,避免一些不必要的 BUG。
编译指令:gcc -g -Wall program.c -o program
-g 选项的作用是在可执行文件中加入源代码的信息,比如可执行文件中第几条机器指令对应源代码的第几行,但并不是把整个源文件嵌入到可执行文件中,所以在调试时必须保证 gdb 能找到源文件。
- 启动: gdb 可执行程序
- 退出:quit
- 给程序设定参数:set args args[1] args[2]
- 获取设置参数:show args
- 查看当前文件代码 list/l or list/l 行号 or list/l 函数名
- 设置显示的行数: show list, set list 行数
- 设置断点: b/break 行号, b/break 函数名, b/break 文件名:行号 b/break 文件名:函数
- 查看断点 i b
- 删除断点:del 断点编号
- 设置断点无效:dis/disable 断点编号
- ena/enable 断点编号
- 设置条件断点(一般在循环位置使用):b/break 10 if i ==5
- 运行gdb程序:start(从第一行开始), run(遇到断点才停)
- 继续运行,到下一个断点停:c
- 向下执行一行代码(不会进入函数体):n
- 变量操作:p变量名 (打印变量值), ptype 变量名(打印变量类型)
- 向下单步调试(遇到函数进行函数体)s, finish(跳出函数体)
- 自动变量操作:display 变量名(自动打印指定变量的值)
文件IO
LInux文件IO 与 C标准库文件IO


虚拟地址空间
虚拟地址通过页表映射到屋里内存,页表由操作系统维护并被处理器引用。
分为用户段(0~3G)和内核段(3G ~ 4G), 如下图所示。

文件描述符
def: Linux 系统中,把一切都看做是文件,当进程打开现有文件或创建新文件时,内核向进程返回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索引,用来指向被打开的文件,所有执行I/O操作的系统调用都会通过文件描述符。
- 每个文件描述符会与一个打开的文件相对应
- 不同的文件描述符也可能指向同一个文件
- 相同的文件可以被不同的进程打开,也可以在同一个进程被多次打开

open & create & read & write
open
/*
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// 打开一个已经存在的文件
int open(const char *pathname, int flags);
参数:
- pathname:要打开的文件路径
- flags:对文件的操作权限设置还有其他的设置
O_RDONLY, O_WRONLY, O_RDWR 这三个设置是互斥的
返回值:返回一个新的文件描述符,如果调用失败,返回-1
errno:属于Linux系统函数库,库里面的一个全局变量,记录的是最近的错误号。
#include <stdio.h>
void perror(const char *s);作用:打印errno对应的错误描述
s参数:用户描述,比如hello,最终输出的内容是 hello:xxx(实际的错误描述)
// 创建一个新的文件
int open(const char *pathname, int flags, mode_t mode);
*/
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main() {
// 打开一个文件
int fd = open("a.txt", O_RDONLY);
if(fd == -1) {
perror("open");
}
// 读写操作
// 关闭
close(fd);
return 0;
}
create
/*
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags, mode_t mode);
参数:
- pathname:要创建的文件的路径
- flags:对文件的操作权限和其他的设置
- 必选项:O_RDONLY, O_WRONLY, O_RDWR 这三个之间是互斥的
- 可选项:O_CREAT 文件不存在,创建新文件
- mode:八进制的数,表示创建出的新的文件的操作权限,比如:0775
r w x: 读 写 可执行
最终的权限是:mode & ~umask
0777 -> 111111111
& 0775 -> 111111101
----------------------------
111111101
按位与:0和任何数都为0
umask的作用就是抹去某些权限。
flags参数是一个int类型的数据,占4个字节,32位。
flags 32个位,每一位就是一个标志位。
*/
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
int main() {
// 创建一个新的文件
int fd = open("create.txt", O_RDWR | O_CREAT, 0777);
if(fd == -1) {
perror("open");
}
// 关闭
close(fd);
return 0;
}
read & write <=> copy
/*
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
参数:
- fd:文件描述符,open得到的,通过这个文件描述符操作某个文件
- buf:需要读取数据存放的地方,数组的地址(传出参数)
- count:指定的数组的大小
返回值:
- 成功:
>0: 返回实际的读取到的字节数
=0:文件已经读取完了
- 失败:-1 ,并且设置errno
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
参数:
- fd:文件描述符,open得到的,通过这个文件描述符操作某个文件
- buf:要往磁盘写入的数据,数据
- count:要写的数据的实际的大小
返回值:
成功:实际写入的字节数
失败:返回-1,并设置errno
*/
#include <unistd.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main() {
// 1.通过open打开english.txt文件
int srcfd = open("english.txt", O_RDONLY);
if(srcfd == -1) {
perror("open");
return -1;
}
// 2.创建一个新的文件(拷贝文件)
int destfd = open("cpy.txt", O_WRONLY | O_CREAT, 0664);
if(destfd == -1) {
perror("open");
return -1;
}
// 3.频繁的读写操作
char buf[1024] = {0};
int len = 0;
while((len = read(srcfd, buf, sizeof(buf))) > 0) {
write(destfd, buf, len);
}
// 4.关闭文件
close(destfd);
close(srcfd);
return 0;
}
lseek 扩展文件
- 移动文件指针到文件头:
lseek(fd, 0, SEEK_SET) - 获取当前文件指针的位置:
lseek(fd, 0, SEEK_CUR) - 获取文件长度:
lseek(fd, 0, SEEK_END) - 拓展文件的长度, 当前文件长度为10b, 110b, 增加了100个字节:
lseek(fd, 100, SEEK_END)
/*
标准C库的函数
#include <stdio.h>
int fseek(FILE *stream, long offset, int whence);
Linux系统函数
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
参数:
- fd:文件描述符,通过open得到的,通过这个fd操作某个文件
- offset:偏移量
- whence:
SEEK_SET
设置文件指针的偏移量
SEEK_CUR
设置偏移量:当前位置 + 第二个参数offset的值
SEEK_END
设置偏移量:文件大小 + 第二个参数offset的值
返回值:返回文件指针的位置
作用:
1.移动文件指针到文件头
lseek(fd, 0, SEEK_SET);
2.获取当前文件指针的位置
lseek(fd, 0, SEEK_CUR);
3.获取文件长度
lseek(fd, 0, SEEK_END);
4.拓展文件的长度,当前文件10b, 110b, 增加了100个字节
lseek(fd, 100, SEEK_END)
注意:需要写一次数据
*/
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
int main() {
int fd = open("hello.txt", O_RDWR);
if(fd == -1) {
perror("open");
return -1;
}
// 扩展文件的长度
int ret = lseek(fd, 100, SEEK_END);
if(ret == -1) {
perror("lseek");
return -1;
}
// 写入一个空数据
write(fd, " ", 1);
// 关闭文件
close(fd);
return 0;
}
拓展完之后如果不写入为什么字节数不增加呢,既然可以直接写入空数据,那为何还要扩展呢?就是说我扩展位111个字节,在写入空数据,不应该是从第12个字节写入吗?为何写到了第112个字节位置呢?write自带扩展功能吗?
lseek()不是扩展数据的功能哈,只是可以利用lseek()去扩展文件,lseek()只是单纯的移动文件指针偏移。
拓展时,lseek只是逻辑上移动文件指针的位置,并没有为文件分配存储空间,为了让这些空间实际得到分配,可以使用write在最后补充一个字符,这样拓展的存储空间应该就分配了。
stat & lstat查看文件属性参数
def:stat:是用来获取文件属性的参数的命令,lstat:用来获取软链接文件属性的参数的命令
/*
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *pathname, struct stat *statbuf);
作用:获取一个文件相关的一些信息
参数:
- pathname:操作的文件的路径
- statbuf:结构体变量,传出参数,用于保存获取到的文件的信息
返回值:
成功:返回0
失败:返回-1 设置errno
int lstat(const char *pathname, struct stat *statbuf);
参数:
- pathname:操作的文件的路径
- statbuf:结构体变量,传出参数,用于保存获取到的文件的信息
返回值:
成功:返回0
失败:返回-1 设置errno
*/
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
int main() {
struct stat statbuf;
int ret = stat("a.txt", &statbuf);
if(ret == -1) {
perror("stat");
return -1;
}
printf("size: %ld\n", statbuf.st_size);
return 0;
}
struct stat {
dev_t st_dev; // 文件的设备编号
ino_t st_ino; // 节点
mode_t st_mode; // 文件的类型和存取的权限
nlink_t st_nlink; // 连到该文件的硬连接数目
uid_t st_uid; // 用户ID
gid_t st_gid; // 组ID
dev_t st_rdev; // 设备文件的设备编号
off_t st_size; // 文件字节数(文件大小)
blksize_t st_blksize; // 块大小
blkcnt_t st_blocks; // 块数
time_t st_atime; // 最后一次访问时间
time_t st_mtime; // 最后一次修改时间
time_t st_ctime; // 最后一次改变时间(指属性)
};
模拟实现ls
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <pwd.h>
#include <grp.h>
#include <time.h>
#include <string.h>
// 模拟实现 ls -l 指令
// -rw-rw-r-- 1 nowcoder nowcoder 12 12月 3 15:48 a.txt
int main(int argc, char * argv[]) {
// 判断输入的参数是否正确
if(argc < 2) {
printf("%s filename\n", argv[0]);
return -1;
}
// 通过stat函数获取用户传入的文件的信息
struct stat st;
int ret = stat(argv[1], &st);
if(ret == -1) {
perror("stat");
return -1;
}
// 获取文件类型和文件权限
char perms[11] = {0}; // 用于保存文件类型和文件权限的字符串
switch(st.st_mode & __S_IFMT)
{
case __S_IFLNK:
perms[0] = 'l';
break;
case __S_IFDIR:
perms[0] = 'd';
break;
case __S_IFREG:
perms[0] = '-';
break;
case __S_IFBLK:
perms[0] = 'b';
break;
case __S_IFCHR:
perms[0] = 'c';
break;
case __S_IFSOCK:
perms[0] = 's';
break;
case __S_IFIFO:
perms[0] = 'p';
break;
default:
perms[0] = '?';
break;
}
// 判断文件的访问权限
// 文件所有者
perms[1] = (st.st_mode & S_IRUSR) ? 'r' : '-';
perms[2] = (st.st_mode & S_IWUSR) ? 'w' : '-';
perms[3] = (st.st_mode & S_IXUSR) ? 'x' : '-';
// 文件所在组
perms[4] = (st.st_mode & S_IRGRP) ? 'r' : '-';
perms[5] = (st.st_mode & S_IWGRP) ? 'w' : '-';
perms[6] = (st.st_mode & S_IXGRP) ? 'x' : '-';
// 其他人
perms[7] = (st.st_mode & S_IROTH) ? 'r' : '-';
perms[8] = (st.st_mode & S_IWOTH) ? 'w' : '-';
perms[9] = (st.st_mode & S_IXOTH) ? 'x' : '-';
// 硬连接数
int linkNum = st.st_nlink;
// 文件所有者
char * fileUser = getpwuid(st.st_uid)->pw_name;
// 文件所在组
char * fileGrp = getgrgid(st.st_gid)->gr_name;
// 文件大小
long int fileSize = st.st_size;
// 获取修改的时间
char * time = ctime(&st.st_mtime);
char mtime[512] = {0};
strncpy(mtime, time, strlen(time) - 1);
char buf[1024];
sprintf(buf, "%s %d %s %s %ld %s %s", perms, linkNum, fileUser, fileGrp, fileSize, mtime, argv[1]);
printf("%s\n", buf);
return 0;
}
access & chmod & chown & truncate 文件属性操作函数
access:判断某个文件是否有某个权限,或者判断文件是否存在
chomod:修改文件的权限
chown:修改当前文件所属用户组
truncate:缩减或者扩展文件的尺寸至指定的大小
mkdir & rmdir & rename & chdir & getcwd目录操作函数
mkdir:创建一个目录
rmdir: 删除一个目录
rename:更改目录名称
chdir: 更换目录
getcwd:当前位置
/*
#include <unistd.h>
int chdir(const char *path);
作用:修改进程的工作目录
比如在/home/nowcoder 启动了一个可执行程序a.out, 进程的工作目录 /home/nowcoder
参数:
path : 需要修改的工作目录
#include <unistd.h>
char *getcwd(char *buf, size_t size);
作用:获取当前工作目录
参数:
- buf : 存储的路径,指向的是一个数组(传出参数)
- size: 数组的大小
返回值:
返回的指向的一块内存,这个数据就是第一个参数
*/
#include <unistd.h>
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main() {
// 获取当前的工作目录
char buf[128];
getcwd(buf, sizeof(buf));
printf("当前的工作目录是:%s\n", buf);
// 修改工作目录
int ret = chdir("/home/nowcoder/Linux/lesson13");
if(ret == -1) {
perror("chdir");
return -1;
}
// 创建一个新的文件
int fd = open("chdir.txt", O_CREAT | O_RDWR, 0664);
if(fd == -1) {
perror("open");
return -1;
}
close(fd);
// 获取当前的工作目录
char buf1[128];
getcwd(buf1, sizeof(buf1));
printf("当前的工作目录是:%s\n", buf1);
return 0;
}
目录遍历函数
opendir: 打开目录
struct dirent *readdir(DIR *dirp);读取目录
closedir:关闭目录
递归的遍历统计目录文件个数
/*
// 打开一个目录
#include <sys/types.h>
#include <dirent.h>
DIR *opendir(const char *name);
参数:
- name: 需要打开的目录的名称
返回值:
DIR * 类型,理解为目录流
错误返回NULL
// 读取目录中的数据
#include <dirent.h>
struct dirent *readdir(DIR *dirp);
- 参数:dirp是opendir返回的结果
- 返回值:
struct dirent,代表读取到的文件的信息
读取到了末尾或者失败了,返回NULL
// 关闭目录
#include <sys/types.h>
#include <dirent.h>
int closedir(DIR *dirp);
*/
#include <sys/types.h>
#include <dirent.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int getFileNum(const char * path);
// 读取某个目录下所有的普通文件的个数
int main(int argc, char * argv[]) {
if(argc < 2) {
printf("%s path\n", argv[0]);
return -1;
}
int num = getFileNum(argv[1]);
printf("普通文件的个数为:%d\n", num);
return 0;
}
// 用于获取目录下所有普通文件的个数
int getFileNum(const char * path) {
// 1.打开目录
DIR * dir = opendir(path);
if(dir == NULL) {
perror("opendir");
exit(0);
}
struct dirent *ptr;
// 记录普通文件的个数
int total = 0;
while((ptr = readdir(dir)) != NULL) {
// 获取名称
char * dname = ptr->d_name;
// 忽略掉. 和..
if(strcmp(dname, ".") == 0 || strcmp(dname, "..") == 0) {
continue;
}
// 判断是否是普通文件还是目录
if(ptr->d_type == DT_DIR) {
// 目录,需要继续读取这个目录
char newpath[256];
sprintf(newpath, "%s/%s", path, dname);
total += getFileNum(newpath);
}
if(ptr->d_type == DT_REG) {
// 普通文件
total++;
}
}
// 关闭目录
closedir(dir);
return total;
}
dup & dup2复制、重定向文件描述符
dup:复制当前文件描述符
/*
#include <unistd.h>
int dup(int oldfd);
作用:复制一个新的文件描述符
fd=3, int fd1 = dup(fd),
fd指向的是a.txt, fd1也是指向a.txt
从空闲的文件描述符表中找一个最小的,作为新的拷贝的文件描述符
*/
#include <unistd.h>
#include <stdio.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
int main() {
int fd = open("a.txt", O_RDWR | O_CREAT, 0664);
int fd1 = dup(fd);
if(fd1 == -1) {
perror("dup");
return -1;
}
printf("fd : %d , fd1 : %d\n", fd, fd1);
close(fd);
char * str = "hello,world";
int ret = write(fd1, str, strlen(str));
if(ret == -1) {
perror("write");
return -1;
}
close(fd1);
return 0;
}
dup2:重定向文件描述符
/*
#include <unistd.h>
int dup2(int oldfd, int newfd);
作用:重定向文件描述符
oldfd 指向 a.txt, newfd 指向 b.txt
调用函数成功后:newfd 和 b.txt 做close, newfd 指向了 a.txt
oldfd 必须是一个有效的文件描述符
oldfd和newfd值相同,相当于什么都没有做
*/
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main() {
int fd = open("1.txt", O_RDWR | O_CREAT, 0664);
if(fd == -1) {
perror("open");
return -1;
}
int fd1 = open("2.txt", O_RDWR | O_CREAT, 0664);
if(fd1 == -1) {
perror("open");
return -1;
}
printf("fd : %d, fd1 : %d\n", fd, fd1);
int fd2 = dup2(fd, fd1);
if(fd2 == -1) {
perror("dup2");
return -1;
}
// 通过fd1去写数据,实际操作的是1.txt,而不是2.txt
char * str = "hello, dup2";
int len = write(fd1, str, strlen(str));
if(len == -1) {
perror("write");
return -1;
}
printf("fd : %d, fd1 : %d, fd2 : %d\n", fd, fd1, fd2);
close(fd);
close(fd1);
return 0;
}
fcntl 复制文件描述符 & 设置文件描述状态
/*
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ...);
参数:
fd : 表示需要操作的文件描述符
cmd: 表示对文件描述符进行如何操作
- F_DUPFD : 复制文件描述符,复制的是第一个参数fd,得到一个新的文件描述符(返回值)
int ret = fcntl(fd, F_DUPFD);
- F_GETFL : 获取指定的文件描述符文件状态flag
获取的flag和我们通过open函数传递的flag是一个东西。
- F_SETFL : 设置文件描述符文件状态flag
必选项:O_RDONLY, O_WRONLY, O_RDWR 不可以被修改
可选性:O_APPEND, O)NONBLOCK
O_APPEND 表示追加数据
NONBLOK 设置成非阻塞
阻塞和非阻塞:描述的是函数调用的行为。
*/
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
int main() {
// 1.复制文件描述符
// int fd = open("1.txt", O_RDONLY);
// int ret = fcntl(fd, F_DUPFD);
// 2.修改或者获取文件状态flag
int fd = open("1.txt", O_RDWR);
if(fd == -1) {
perror("open");
return -1;
}
// 获取文件描述符状态flag
int flag = fcntl(fd, F_GETFL);
if(flag == -1) {
perror("fcntl");
return -1;
}
flag |= O_APPEND; // flag = flag | O_APPEND
// 修改文件描述符状态的flag,给flag加入O_APPEND这个标记
int ret = fcntl(fd, F_SETFL, flag);
if(ret == -1) {
perror("fcntl");
return -1;
}
char * str = "nihao";
write(fd, str, strlen(str));
close(fd);
return 0;
}
Linux多进程
进程概述
程序和进程
程序是包含一系列信息的文件,这些信息描述了如何在运行时创建一个进程
- 二进制格式标识:每个程序文件都包含用于描述可执行文件格式的元信息。内核利用此信息来解释文件中的其他信息。(ELF可执行连接格式)
- 机器语言指令:对程序算法进行编码。
- 程序入口地址:标识程序开始执行时的起始指令位置。
- 数据:程序文件包含的变量初始值和程序使用的字面量值(比如字符串)。
- 符号表及重定位表:描述程序中函数和变量的位置及名称。这些表格有多重用途,其中包括调试和运行时的符号解析(动态链接)。
- 共享库和动态链接信息:程序文件所包含的一些字段,列出了程序运行时需要使用的共享库,以及加载共享库的动态连接器的路径名。
- 其他信息:程序文件还包含许多其他信息,用以描述如何创建进程。
- 进程是正在运行的程序的实例。是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是
基本的分配单元,也是基本的执行单元。 - 可以用一个程序来创建多个进程,进程是由内核定义的抽象实体,并为该实体分配用以执行程序的各项系统资源。从内核的角度看,进程由用户内存空间和一系列内核数
据结构组成,其中用户内存空间包含了程序代码及代码所使用的变量,而内核数据结构则用于维护进程状态信息。记录在内核数据结构中的信息包括许多与进程相关的标
识号(IDs)、虚拟内存表、打开文件的描述符表、信号传递及处理的有关信息、进程资源使用及限制、当前工作目录和大量的其他信息。
单道、多道程序
- 单道程序, 即在计算机内存中只允许一个程序运行。
- 多道程序,
- 在计算机内存中同时存放几道相互独立的程序,使它们在管理程序控制下,相互穿插运行,两个或两个以上程序在计算机系统中同处于开始到结束之
间的状态, 这些程序共享计算机系统资源。引入多道程序设计技术的根本目的是为了提高 CPU 的利用率。 - 对于一个单 CPU 系统来说,程序同时处于运行状态只是一种宏观上的概念,他们虽然都已经开始运行,但就微观而言,任意时刻,CPU 上运行的程序只有一个。
- 在多道程序设计模型中,多个进程轮流使用 CPU。而当下常见 CPU 为纳秒级,1秒可以执行大约 10 亿条指令。由于人眼的反应速度是毫秒级,所以看似同时在运行。
时间片
- 时间片(timeslice)又称为“量子(quantum)”或“处理器片(processor slice)”是操作系统分配给每个正在运行的进程微观上的一段 CPU 时间。事实上,虽然一台计
算机通常可能有多个 CPU,但是同一个 CPU 永远不可能真正地同时运行多个任务。在只考虑一个 CPU 的情况下,这些进程“看起来像”同时运行的,实则是轮番穿插地运行,
由于时间片通常很短(在 Linux 上为 5ms-800ms),用户不会感觉到。 - 时间片由操作系统内核的调度程序分配给每个进程。首先,内核会给每个进程分配相等的初始时间片,然后每个进程轮番地执行相应的时间,当所有进程都处于时间片耗尽的
状态时,内核会重新为每个进程计算并分配时间片,如此往复。
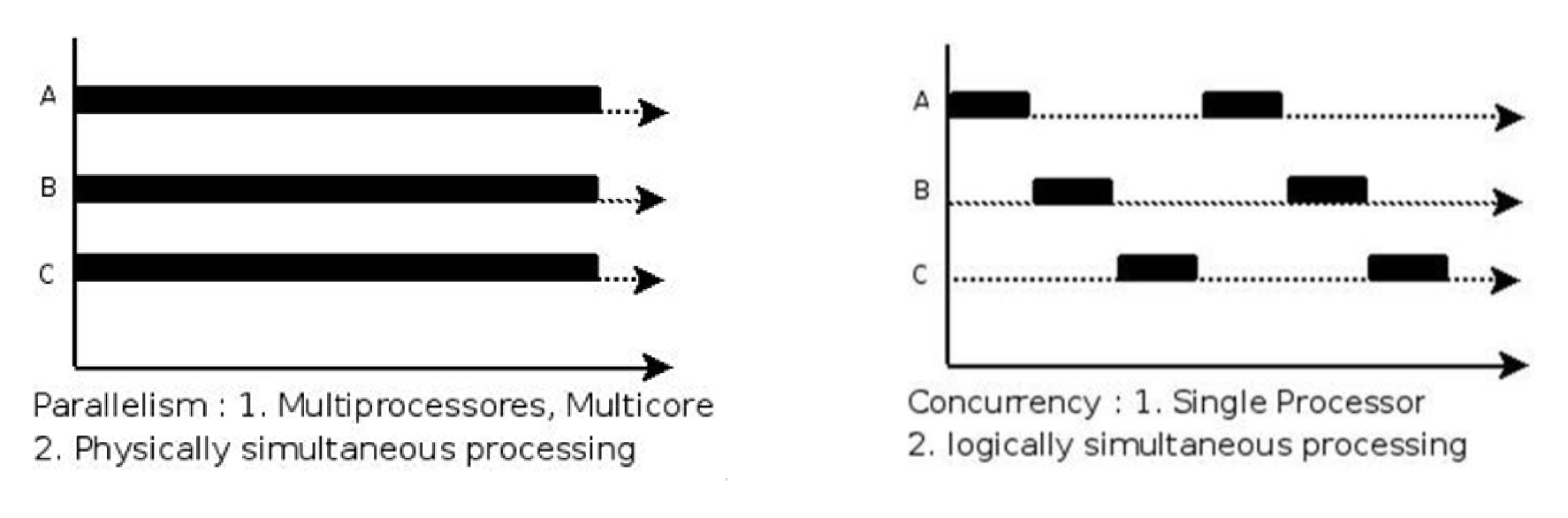
并行和并发
- 并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。并行是两个队列同时使用两个咖啡机。
- 并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,
只是把时间分成若干段,使多个进程快速交替的执行。并发是两个队列交替使用一台咖啡机。
进程控制块PCB
为了管理进程,内核必须对每个进程所做的事情进行清楚的描述。内核为每个进程分配一个 PCB(Processing Control Block)进程控制块,维护进程相关的信息,Linux 内核的进程控制块是 task_struct 结构体。
- 在 /usr/src/linux-headers-xxx/include/linux/sched.h 文件中可以查看 struct task_struct 结构体定义。其内部成员有很多,我们只需要掌握以下
部分即可:- 进程id:系统中每个进程有唯一的 id,用 pid_t 类型表示,其实就是一个非负整数
- 进程的状态:有就绪、运行、挂起、停止等状态
- 进程切换时需要保存和恢复的一些CPU寄存器
- 描述虚拟地址空间的信息
- 描述控制终端的信息
- 当前工作目录(Current Working Directory)
- umask 掩码
- 文件描述符表,包含很多指向 file 结构体的指针
- 和信号相关的信息
- 用户 id 和组 id
- 会话(Session)和进程组
- 进程可以使用的资源上限(Resource Limit)
进程状态转换
进程三态状态
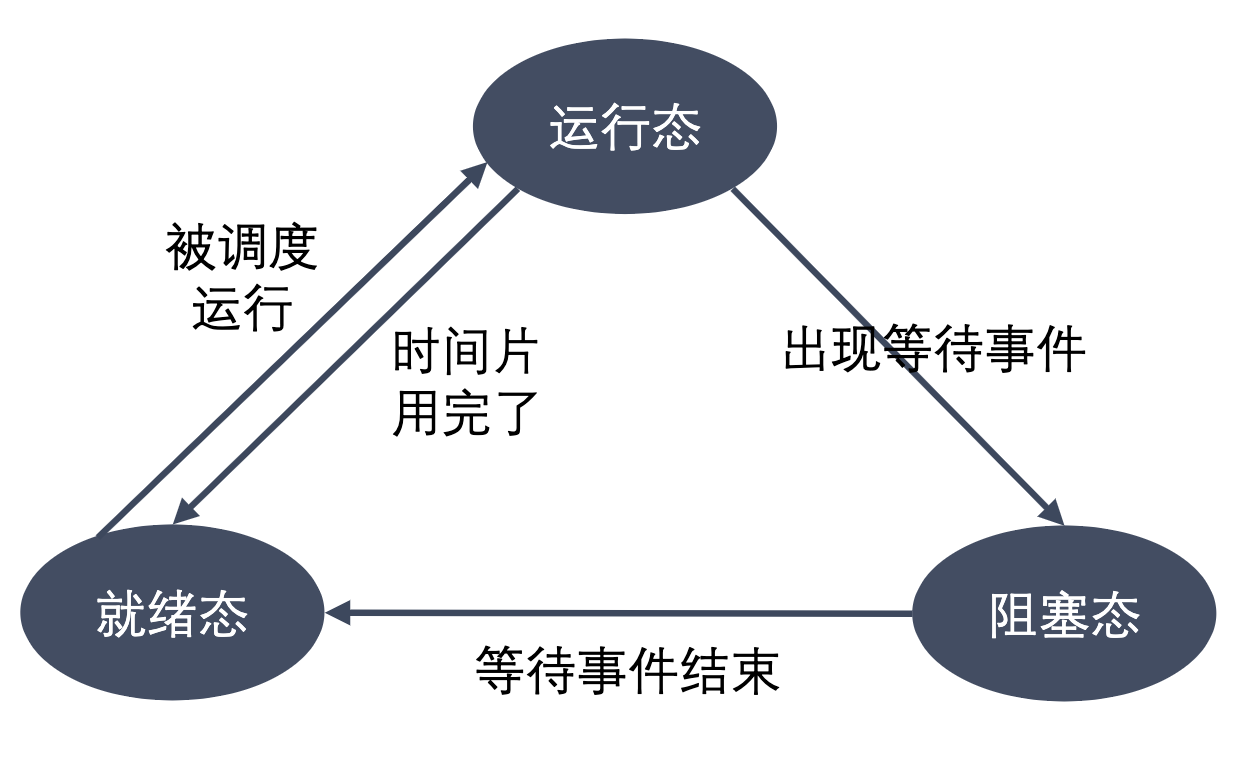
- 运行态:进程占有处理器正在运行。
- 就绪态:进程具备运行条件,等待系统分配处理器以便运行。当进程已分配到除CPU以外的所有必要资源后,只要再获得CPU,便可立即执行。在一个系统中处于就绪状态的进
程可能有多个,通常将它们排成一个队列,称为就绪队列。 - 阻塞态:又称为等待(wait)态或睡眠(sleep)态,指进程不具备运行条件,正在等待某个事件的完成。
进程五态状态
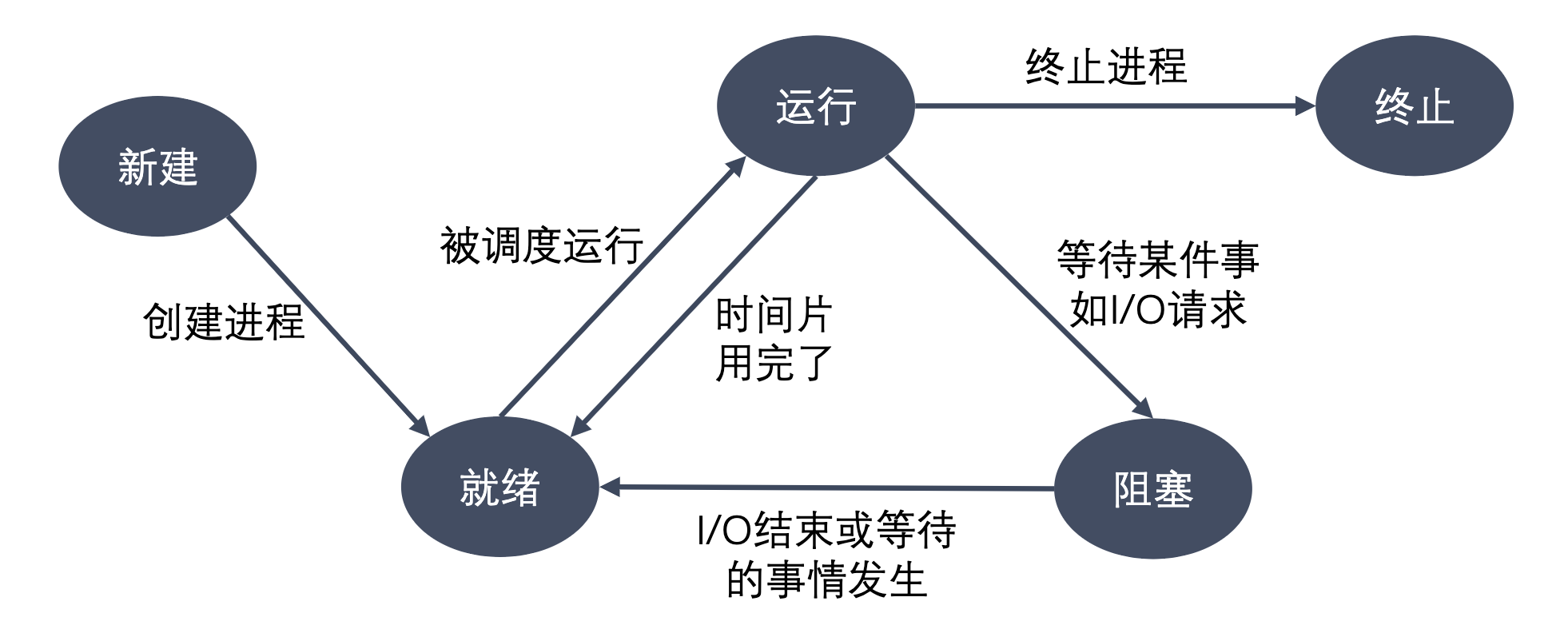
- 新建态:进程刚被创建时,尚未进入就绪队列。
- 终止态:进程完成任务到达正常结束点,或出现无法克服的错误而异常终止,或被操作系统及有终止权的进程所终止时所处的状态。进入终止态的进程以后不再执行,但依然保留在操作系
统中等待善后。一旦其他进程完成了对终止态进程的信息抽取之后,操作系统将删除该进程。
进程创建
系统允许一个进程创建新进程,新进程即为子进程,子进程还可以创建新的子进程,形成
进程树结构模型。
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
返回值:
⚫ 成功:子进程中返回 0,父进程中返回子进程 ID
⚫ 失败:返回 -1
失败的两个主要原因:
- 当前系统的进程数已经达到了系统规定的上限,这时 errno 的值被设置为 EAGAIN
- 系统内存不足,这时 errno 的值被设置为 ENOMEM
/*
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
函数的作用:用于创建子进程。
返回值:
fork()的返回值会返回两次。一次是在父进程中,一次是在子进程中。
在父进程中返回创建的子进程的ID,
在子进程中返回0
如何区分父进程和子进程:通过fork的返回值。
在父进程中返回-1,表示创建子进程失败,并且设置errno
父子进程之间的关系:
区别:
1.fork()函数的返回值不同
父进程中: >0 返回的子进程的ID
子进程中: =0
2.pcb中的一些数据
当前的进程的id pid
当前的进程的父进程的id ppid
信号集
共同点:
某些状态下:子进程刚被创建出来,还没有执行任何的写数据的操作
- 用户区的数据
- 文件描述符表
父子进程对变量是不是共享的?
- 刚开始的时候,是一样的,共享的。如果修改了数据,不共享了。
- 读时共享(子进程被创建,两个进程没有做任何的写的操作),写时拷贝。
*/
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main() {
int num = 10;
// 创建子进程
pid_t pid = fork();
// 判断是父进程还是子进程
if(pid > 0) {
// printf("pid : %d\n", pid);
// 如果大于0,返回的是创建的子进程的进程号,当前是父进程
printf("i am parent process, pid : %d, ppid : %d\n", getpid(), getppid());
printf("parent num : %d\n", num);
num += 10;
printf("parent num += 10 : %d\n", num);
} else if(pid == 0) {
// 当前是子进程
printf("i am child process, pid : %d, ppid : %d\n", getpid(),getppid());
printf("child num : %d\n", num);
num += 100;
printf("child num += 100 : %d\n", num);
}
// for循环
for(int i = 0; i < 3; i++) {
printf("i : %d , pid : %d\n", i , getpid());
sleep(1);
}
return 0;
}
/*
实际上,更准确来说,Linux 的 fork() 使用是通过写时拷贝 (copy- on-write) 实现。
写时拷贝是一种可以推迟甚至避免拷贝数据的技术。
内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。
只用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间。
也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。
注意:fork之后父子进程共享文件,
fork产生的子进程与父进程相同的文件文件描述符指向相同的文件表,引用计数增加,共享文件偏移指针。
*/
GDB多进程调试
使用 GDB 调试的时候,GDB 默认只能跟踪一个进程,可以在 fork 函数调用之前,通过指令设置 GDB 调试工具跟踪父进程或者是跟踪子进程,默认跟踪父进程。
设置调试父进程或者子进程:set follow-fork-mode [parent(默认)| child]
设置调试模式:set detach-on-fork [on | off]
默认为 on,表示调试当前进程的时候,其它的进程继续运行,如果为 off,调试当前进程的时候,其它进程被 GDB 挂起。
查看调试的进程:info inferiors
切换当前调试的进程:inferior id
使进程脱离 GDB 调试:detach inferiors id
exec函数族
函数族: 根据指定的文件名找到可执行文件,并用它来取代调用进程的内容(即:在调用进程内部执行一个可执行文件)。
exec 函数族的函数执行成功后不会返回,因为调用进程的实体,包括代码段,数据段和堆栈等都已经被新的内容取代,只留下进程 ID 等一些表面上的信息仍保持原样,颇有些神似“三十六计”中的“金蝉脱壳”。看上去还是旧的躯壳,却已经注入了新的灵魂。只有调用失败了,它们才会返回 -1,从原程序的调用点接着往下执行。
int execl(const char *path, const char *arg, .../* (char *) NULL */);
int execlp(const char *file, const char *arg, ... /* (char *) NULL */);
int execle(const char *path, const char *arg, .../*, (char *) NULL, char * const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);
int execve(const char *filename, char *const argv[], char *const envp[]);
/*
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
- 参数:
- path:需要指定的执行的文件的路径或者名称
a.out /home/nowcoder/a.out 推荐使用绝对路径
./a.out hello world
- arg:是执行可执行文件所需要的参数列表
第一个参数一般没有什么作用,为了方便,一般写的是执行的程序的名称
从第二个参数开始往后,就是程序执行所需要的的参数列表。
参数最后需要以NULL结束(哨兵)
- 返回值:
只有当调用失败,才会有返回值,返回-1,并且设置errno
如果调用成功,没有返回值。
*/
#include <unistd.h>
#include <stdio.h>
int main() {
// 创建一个子进程,在子进程中执行exec函数族中的函数
pid_t pid = fork();
if(pid > 0) {
// 父进程
printf("i am parent process, pid : %d\n",getpid());
sleep(1);
}else if(pid == 0) {
// 子进程
// execl("hello","hello",NULL);
execl("/bin/ps", "ps", "aux", NULL);
perror("execl");
printf("i am child process, pid : %d\n", getpid());
}
for(int i = 0; i < 3; i++) {
printf("i = %d, pid = %d\n", i, getpid());
}
return 0;
}
l(list) 参数地址列表,以空指针结尾
v(vector) 存有各参数地址的指针数组的地址
p(path) 按 PATH 环境变量指定的目录搜索可执行文件
e(environment) 存有环境变量字符串地址的指针数组的地址
/*
#include <unistd.h>
int execlp(const char *file, const char *arg, ... );
- 会到环境变量中查找指定的可执行文件,如果找到了就执行,找不到就执行不成功。
- 参数:
- file:需要执行的可执行文件的文件名
a.out
ps
- arg:是执行可执行文件所需要的参数列表
第一个参数一般没有什么作用,为了方便,一般写的是执行的程序的名称
从第二个参数开始往后,就是程序执行所需要的的参数列表。
参数最后需要以NULL结束(哨兵)
- 返回值:
只有当调用失败,才会有返回值,返回-1,并且设置errno
如果调用成功,没有返回值。
int execv(const char *path, char *const argv[]);
argv是需要的参数的一个字符串数组
char * argv[] = {"ps", "aux", NULL};
execv("/bin/ps", argv);
int execve(const char *filename, char *const argv[], char *const envp[]);
char * envp[] = {"/home/nowcoder", "/home/bbb", "/home/aaa"};
*/
#include <unistd.h>
#include <stdio.h>
int main() {
// 创建一个子进程,在子进程中执行exec函数族中的函数
pid_t pid = fork();
if(pid > 0) {
// 父进程
printf("i am parent process, pid : %d\n",getpid());
sleep(1);
}else if(pid == 0) {
// 子进程
execlp("ps", "ps", "aux", NULL);
printf("i am child process, pid : %d\n", getpid());
}
for(int i = 0; i < 3; i++) {
printf("i = %d, pid = %d\n", i, getpid());
}
return 0;
}
进程退出
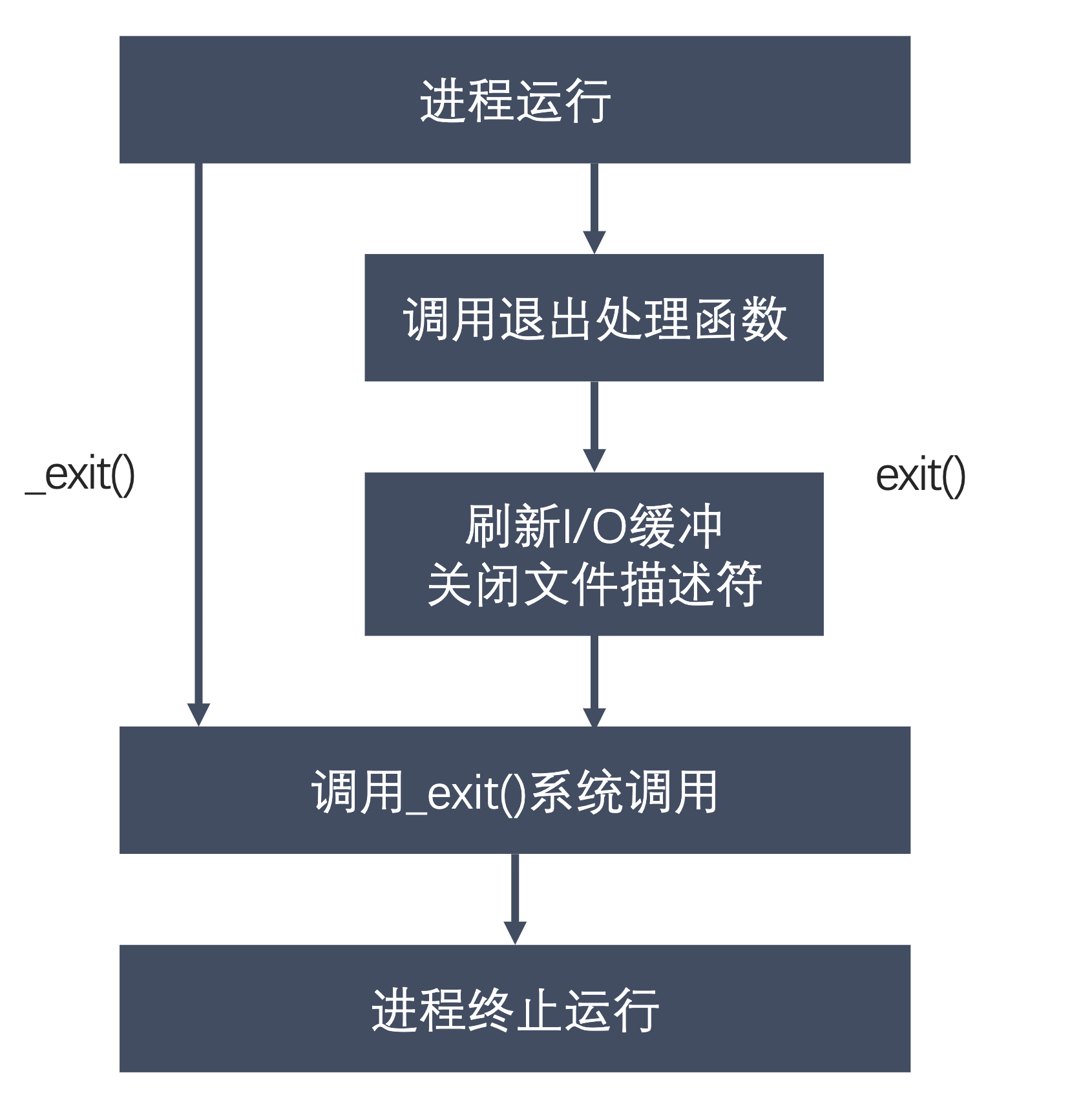
exit与_exit区别在于_exit不会刷新缓存
/*
#include <stdlib.h>
void exit(int status);
#include <unistd.h>
void _exit(int status);
status参数:是进程退出时的一个状态信息。父进程回收子进程资源的时候可以获取到。
*/
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
printf("hello\n");
printf("world");
// exit(0);
_exit(0);
return 0;
}
孤儿进程
- 父进程运行结束,但子进程还在运行(未运行结束),这样的子进程就称为孤儿进程(Orphan Process)。
- 每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为 init ,而 init进程会循环地 wait() 它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束
了其生命周期的时候,init 进程就会代表党和政府出面处理它的一切善后工作。 - 因此孤儿进程并不会有什么危害。
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main() {
// 创建子进程
pid_t pid = fork();
// 判断是父进程还是子进程
if(pid > 0) {
printf("i am parent process, pid : %d, ppid : %d\n", getpid(), getppid());
} else if(pid == 0) {
sleep(1); // 睡眠一秒导致父进程运行结束,但子进程还在运行
// 当前是子进程
printf("i am child process, pid : %d, ppid : %d\n", getpid(),getppid());
}
// for循环
for(int i = 0; i < 3; i++) {
printf("i : %d , pid : %d\n", i , getpid());
}
return 0;
}
僵尸进程
- 每个进程结束之后, 都会释放自己地址空间中的用户区数据,内核区的 PCB 没有办法自己释放掉,需要父进程去释放。
- 进程终止时,父进程尚未回收,子进程残留资源(PCB)存放于内核中,变成僵尸(Zombie)进程。
- 僵尸进程不能被 kill -9 杀死,这样就会导致一个问题,如果父进程不调用 wait()或 waitpid() 的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程,此即为僵尸进程的危害,应当避免。
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main() {
// 创建子进程
pid_t pid = fork();
// 判断是父进程还是子进程
if(pid > 0) {
while(1) {
printf("i am parent process, pid : %d, ppid : %d\n", getpid(), getppid());
sleep(1);
}
} else if(pid == 0) {
// 当前是子进程
printf("i am child process, pid : %d, ppid : %d\n", getpid(),getppid());
}
// for循环
for(int i = 0; i < 3; i++) {
printf("i : %d , pid : %d\n", i , getpid());
}
return 0;
}
wait & waitpid
- 在每个进程退出的时候,内核释放该进程所有的资源、包括打开的文件、占用的内存等。但是仍然为其保留一定的信息,这些信息主要主要指进程控制块PCB的信息(包括进程号、退出状态、运行时间等)。
- 父进程可以通过调用wait或waitpid得到它的退出状态同时彻底清除掉这个进程。
- wait() 和 waitpid() 函数的功能一样,区别在于,wait() 函数会阻塞,waitpid() 可以设置不阻塞,waitpid() 还可以指定等待哪个子进程结束。
- 注意:一次wait或waitpid调用只能清理一个子进程,清理多个子进程应使用循环。
/*
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *wstatus);
功能:等待任意一个子进程结束,如果任意一个子进程结束了,次函数会回收子进程的资源。
参数:int *wstatus
进程退出时的状态信息,传入的是一个int类型的地址,传出参数。
返回值:
- 成功:返回被回收的子进程的id
- 失败:-1 (所有的子进程都结束,调用函数失败)
调用wait函数的进程会被挂起(阻塞),直到它的一个子进程退出或者收到一个不能被忽略的信号时才被唤醒(相当于继续往下执行)
如果没有子进程了,函数立刻返回,返回-1;如果子进程都已经结束了,也会立即返回,返回-1.
*/
/*
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *wstatus, int options);
功能:回收指定进程号的子进程,可以设置是否阻塞。
参数:
- pid:
pid > 0 : 某个子进程的pid
pid = 0 : 回收当前进程组的所有子进程
pid = -1 : 回收所有的子进程,相当于 wait() (最常用)
pid < -1 : 某个进程组的组id的绝对值,回收指定进程组中的子进程
- options:设置阻塞或者非阻塞
0 : 阻塞
WNOHANG : 非阻塞
- 返回值:
> 0 : 返回子进程的id
= 0 : options=WNOHANG, 表示还有子进程或者
= -1 :错误,或者没有子进程了
*/
进程间通信
概念
- 进程是一个独立的资源分配单元,不同进程(用户进程)之间的资源是独立的,没有关联,不能在一个进程中直接访问另一个进程的资源,但是,进程不是孤立的,不同的进程需要进行信息的交互和状态的传递,进程间通信(IPC:Inter Processes Communication)。
- 进程通信的作用:
- 数据传输
- 通知:一个进程需要向另一个或一组进程发送消息,通知它们发生了某种事件
- 资源共享:多个进程之间共享同样的资源。为了做到这一点,需要内核提供互斥和同步机制
- 进程控制:有些进程希望完全控制另一个进程的执行(Debug),控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。

匿名管道
- UNIX系统IPC的一种古老形式,所有的UNIX系统都支持这种通信机制
- 例如:ls | wc -l, shell会创建两个进程来分别执行ls和wc
- 管道其实是一个在内核内存中维护的缓存器,这个缓存器的存储能力有限,不同操作系统大小不一定相同
- 管道可以进行读、写操作,匿名管道没有文件实体,有名管道有文件实体,但不存数据。可以按照操作文件的方式对管道进行操作。
- 一个管道是一个字节流,从管道读取数据的进程可以读取任意大小的数据块,而不管写入进程写入管道的数据块的大小是多少
- 通过管道传递的数据是有序的
- 管道数据传递方向是单向的,一端用于写入,一端用于读取,管道是半双工的。
- 管道读数据是一次性操作,数据一旦被读走,就会释放空间
- 匿名管道只能在具有公共祖先的进程(父进程与子进程,两个兄弟进程)之间使用。
- 管道的底层实现是一个循环队列

/*
#include <unistd.h>
int pipe(int pipefd[2]);
功能:创建一个匿名管道,用来进程间通信。
参数:int pipefd[2] 这个数组是一个传出参数。
pipefd[0] 对应的是管道的读端
pipefd[1] 对应的是管道的写端
返回值:
成功 0
失败 -1
管道默认是阻塞的:如果管道中没有数据,read阻塞,如果管道满了,write阻塞
注意:匿名管道只能用于具有关系的进程之间的通信(父子进程,兄弟进程)
*/
// 子进程发送数据给父进程,父进程读取到数据输出
#include <unistd.h>
#include <sys/types.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
// 在fork之前创建管道
int pipefd[2];
int ret = pipe(pipefd);
if(ret == -1) {
perror("pipe");
exit(0);
}
// 创建子进程
pid_t pid = fork();
if(pid > 0) {
// 父进程
printf("i am parent process, pid : %d\n", getpid());
// 关闭写端
close(pipefd[1]);
// 从管道的读取端读取数据
char buf[1024] = {0};
while(1) {
int len = read(pipefd[0], buf, sizeof(buf));
printf("parent recv : %s, pid : %d\n", buf, getpid());
// 向管道中写入数据
//char * str = "hello,i am parent";
//write(pipefd[1], str, strlen(str));
//sleep(1);
}
} else if(pid == 0){
// 子进程
printf("i am child process, pid : %d\n", getpid());
// 关闭读端
close(pipefd[0]);
char buf[1024] = {0};
while(1) {
// 向管道中写入数据
char * str = "hello,i am child";
write(pipefd[1], str, strlen(str));
//sleep(1);
// int len = read(pipefd[0], buf, sizeof(buf));
// printf("child recv : %s, pid : %d\n", buf, getpid());
// bzero(buf, 1024);
}
}
return 0;
}
/*
实现 ps aux | grep xxx 父子进程间通信
子进程: ps aux, 子进程结束后,将数据发送给父进程
父进程:获取到数据,过滤
pipe()
execlp()
子进程将标准输出 stdout_fileno 重定向到管道的写端。 dup2
*/
#include <unistd.h>
#include <sys/types.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <wait.h>
int main() {
// 创建一个管道
int fd[2];
int ret = pipe(fd);
if(ret == -1) {
perror("pipe");
exit(0);
}
// 创建子进程
pid_t pid = fork();
if(pid > 0) {
// 父进程
// 关闭写端
close(fd[1]);
// 从管道中读取
char buf[1024] = {0};
int len = -1;
while((len = read(fd[0], buf, sizeof(buf) - 1)) > 0) {
// 过滤数据输出
printf("%s", buf);
memset(buf, 0, 1024);
}
wait(NULL);
} else if(pid == 0) {
// 子进程
// 关闭读端
close(fd[0]);
// 文件描述符的重定向 stdout_fileno -> fd[1]
dup2(fd[1], STDOUT_FILENO);
// 执行 ps aux
execlp("ps", "ps", "aux", NULL);
perror("execlp");
exit(0);
} else {
perror("fork");
exit(0);
}
return 0;
}
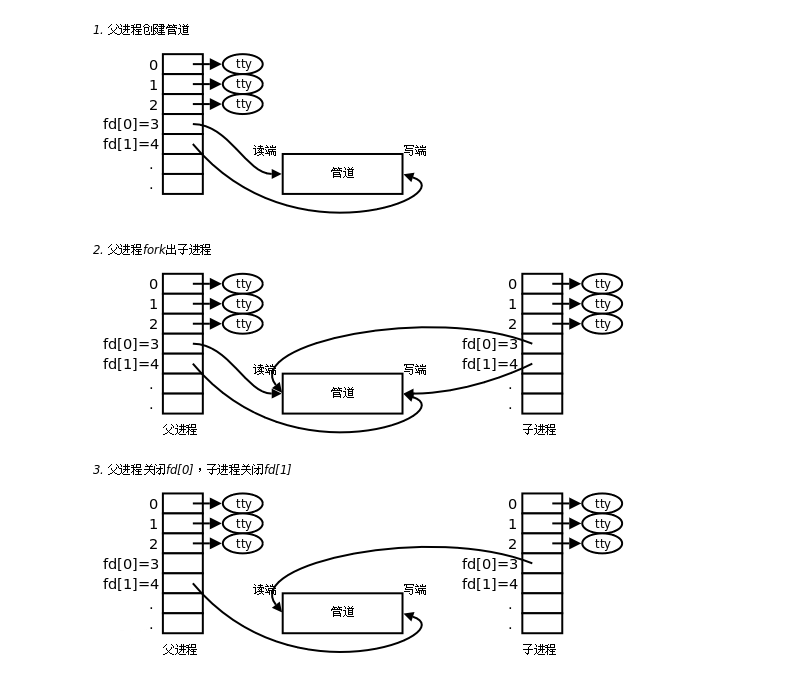
管道读写特点
管道的读写特点:
使用管道时,需要注意以下几种特殊的情况(假设都是阻塞I/O操作)
- 所有的指向管道写端的文件描述符都关闭了(管道写端引用计数为0),有进程从管道的读端读数据,那么管道中剩余的数据被读取以后,再次read会返回0,就像读到文件末尾一样。
- 如果有指向管道写端的文件描述符没有关闭(管道的写端引用计数大于0),而持有管道写端的进程也没有往管道中写数据,这个时候有进程从管道中读取数据,那么管道中剩余的数据被读取后,
再次read会阻塞,直到管道中有数据可以读了才读取数据并返回。 - 如果所有指向管道读端的文件描述符都关闭了(管道的读端引用计数为0),这个时候有进程向管道中写数据,那么该进程会收到一个信号SIGPIPE, 通常会导致进程异常终止。
- 如果有指向管道读端的文件描述符没有关闭(管道的读端引用计数大于0),而持有管道读端的进程也没有从管道中读数据,这时有进程向管道中写数据,那么在管道被写满的时候再次write会阻塞,直到管道中有空位置才能再次写入数据并返回。
总结:
读管道:
管道中有数据,read返回实际读到的字节数。
管道中无数据:
写端被全部关闭,read返回0(相当于读到文件的末尾)
写端没有完全关闭,read阻塞等待
写管道:
管道读端全部被关闭,进程异常终止(进程收到SIGPIPE信号)
管道读端没有全部关闭:
管道已满,write阻塞
管道没有满,write将数据写入,并返回实际写入的字节数
#include <unistd.h>
#include <sys/types.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
/*
设置管道非阻塞
int flags = fcntl(fd[0], F_GETFL); // 获取原来的flag
flags |= O_NONBLOCK; // 修改flag的值
fcntl(fd[0], F_SETFL, flags); // 设置新的flag
*/
int main() {
// 在fork之前创建管道
int pipefd[2];
int ret = pipe(pipefd);
if(ret == -1) {
perror("pipe");
exit(0);
}
// 创建子进程
pid_t pid = fork();
if(pid > 0) {
// 父进程
printf("i am parent process, pid : %d\n", getpid());
// 关闭写端
close(pipefd[1]);
// 从管道的读取端读取数据
char buf[1024] = {0};
int flags = fcntl(pipefd[0], F_GETFL); // 获取原来的flag
flags |= O_NONBLOCK; // 修改flag的值
fcntl(pipefd[0], F_SETFL, flags); // 设置新的flag
while(1) {
int len = read(pipefd[0], buf, sizeof(buf));
printf("len : %d\n", len);
printf("parent recv : %s, pid : %d\n", buf, getpid());
memset(buf, 0, 1024);
sleep(1);
}
} else if(pid == 0){
// 子进程
printf("i am child process, pid : %d\n", getpid());
// 关闭读端
close(pipefd[0]);
char buf[1024] = {0};
while(1) {
// 向管道中写入数据
char * str = "hello,i am child";
write(pipefd[1], str, strlen(str));
sleep(5);
}
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号