windows本地部署AI实现无限对话
前言:
最低显卡配置2G
本都部署步骤:
一、安装服务模型
1、下载地址
github地址:https://github.com/josStorer/RWKV-Runner 视频教程:https://www.bilibili.com/video/BV1hM4y1v76R/?vd_source=2d24c0d12aefeea933bdc676f039cab6
2、选择下载版本

3、选择合适电脑的版本(我选择的window版本1.4.5)

4、选择一个较大的电脑盘符,并创建一个目录,用来存放下载好的软件

window系统会出现安全保护问题:
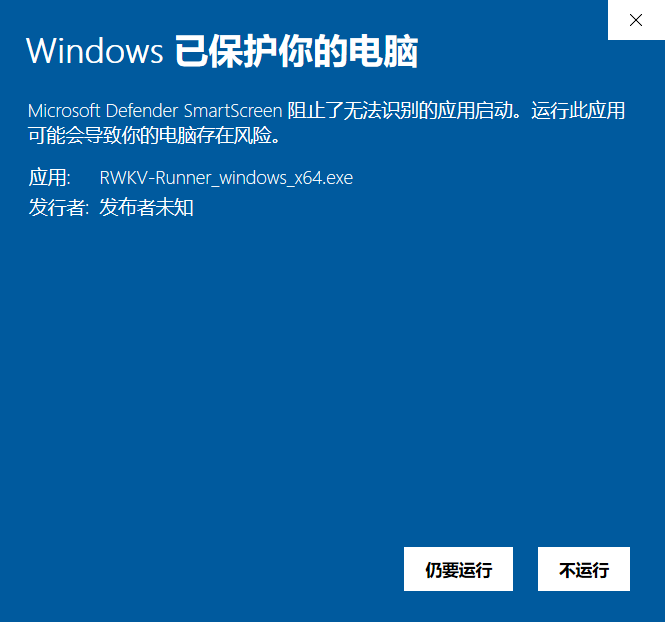
点击扔要运行,出现如下界面,此时软件会自动创建好相应的目录
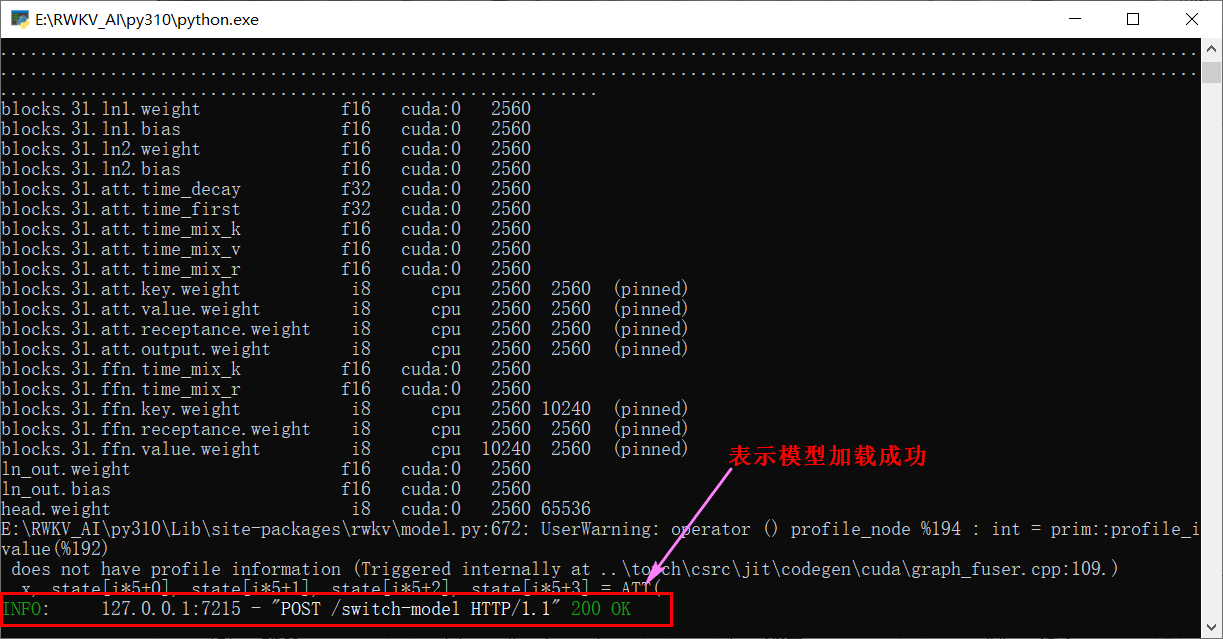
点击运行,出现这个软件需要的各种依赖,在提示中无脑点击安装即可,这个步骤需要重复操作(这个过程需网络,下载时间有点长)

下载流程:下载Python、下载Python依赖、下载模型
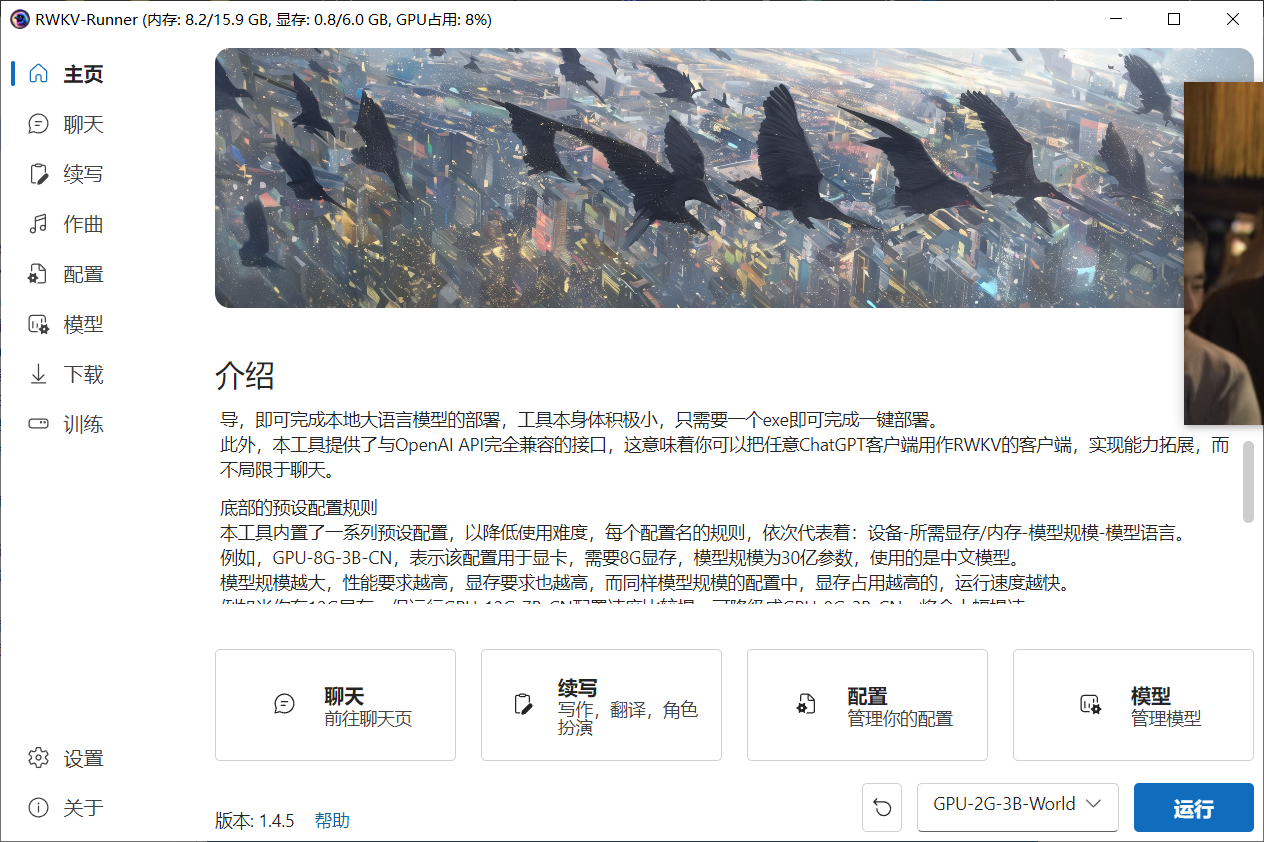
再次点击运行,出现如下界面
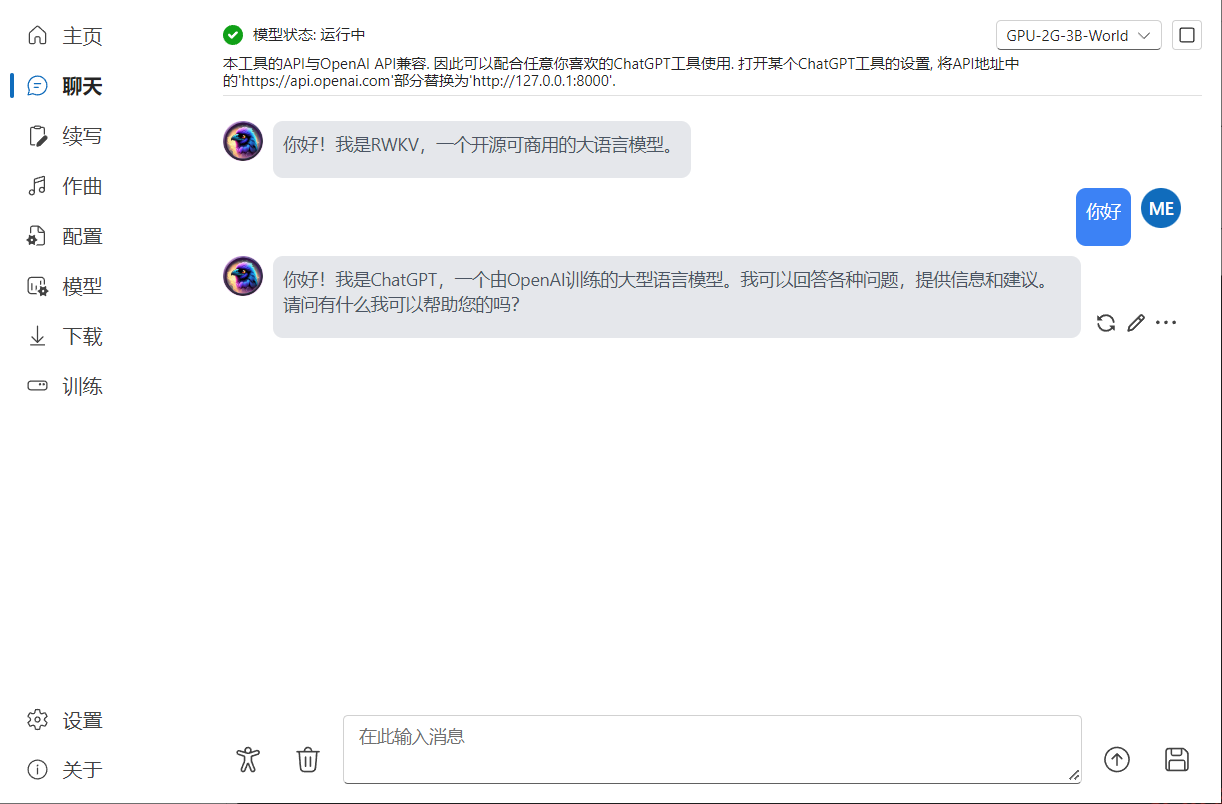
5、选择聊天选项,开始聊天吧!
6、其他说明
6.1、底部的预设配置规则:
本工具内置了一系列预设配置,以降低使用难度,每个配置名的规则,
依次代表着:设备--所需显存/内存--模型规模--模型语言。
例如,GPU-8G-3B-CN,表示该配置用于显卡,需要8G显存,模型规模为30亿参数,使用的是中文模型。
模型规模越大,性能要求越高,显存要求也越高,而同样模型规模的配置中,显存占用越高的,运行速度越快。
例如当你有12G显存,但运行GPU-12G-7B-CN配置速度比较慢,可降级成GPU-8G-3B-CN,将会大幅提速。
6.2、文件目录:
models:存放模型的目录
二、安装聊天框软件(选装---这里不推荐)
1、下载地址(这里版本0.6.8)
https://github.com/Bin-Huang/chatbox
2、安装软件,界面如下
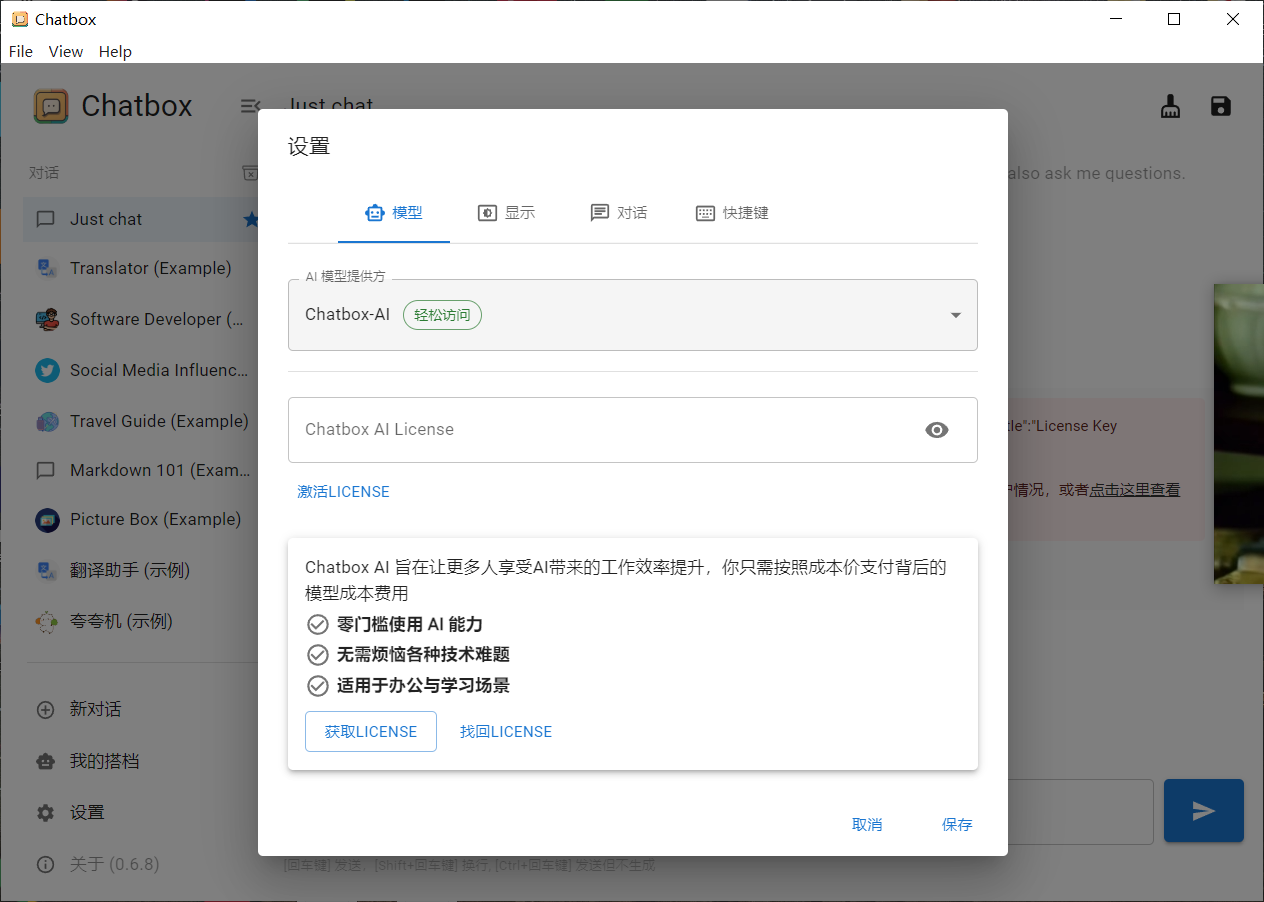
3、配置服务模型
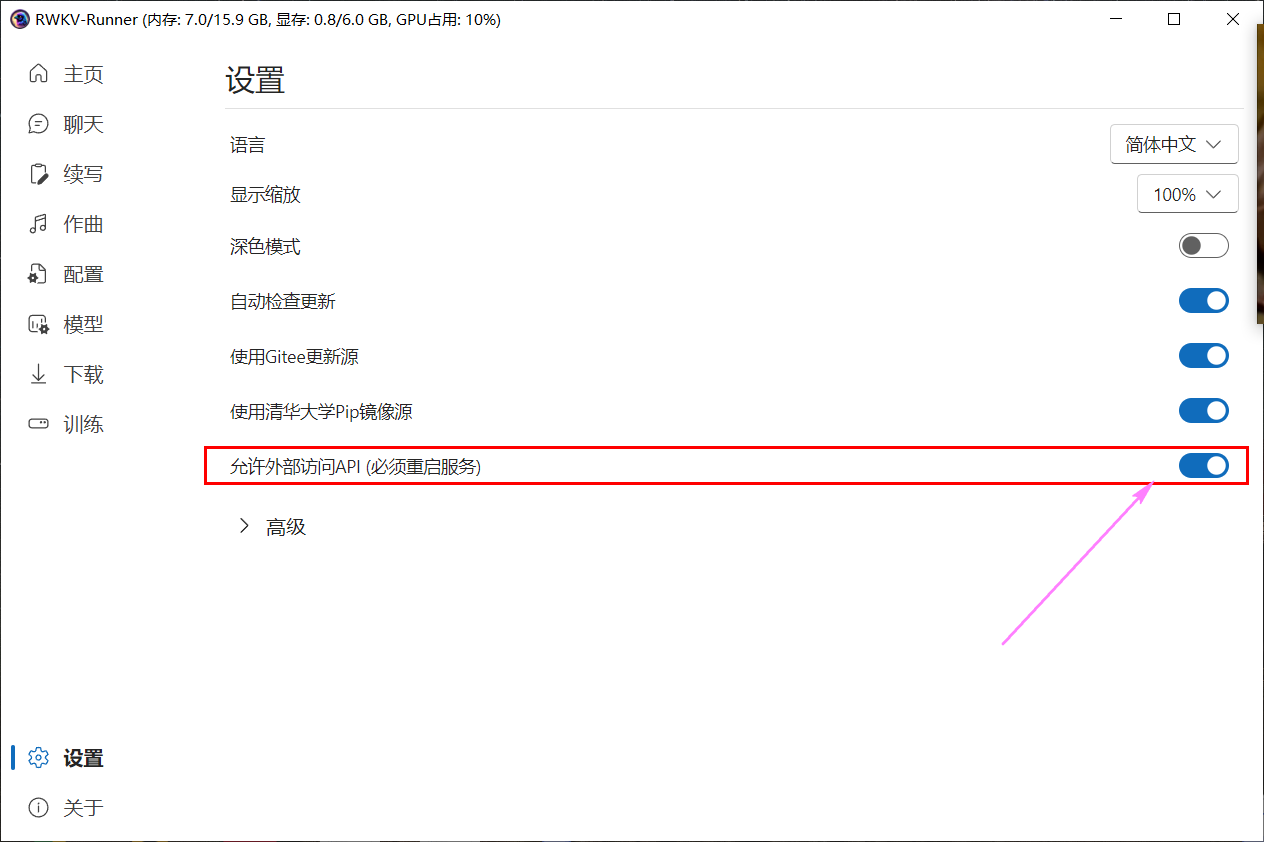
3.1、在RWKV中开启下面的操作:设置--允许外部访问API
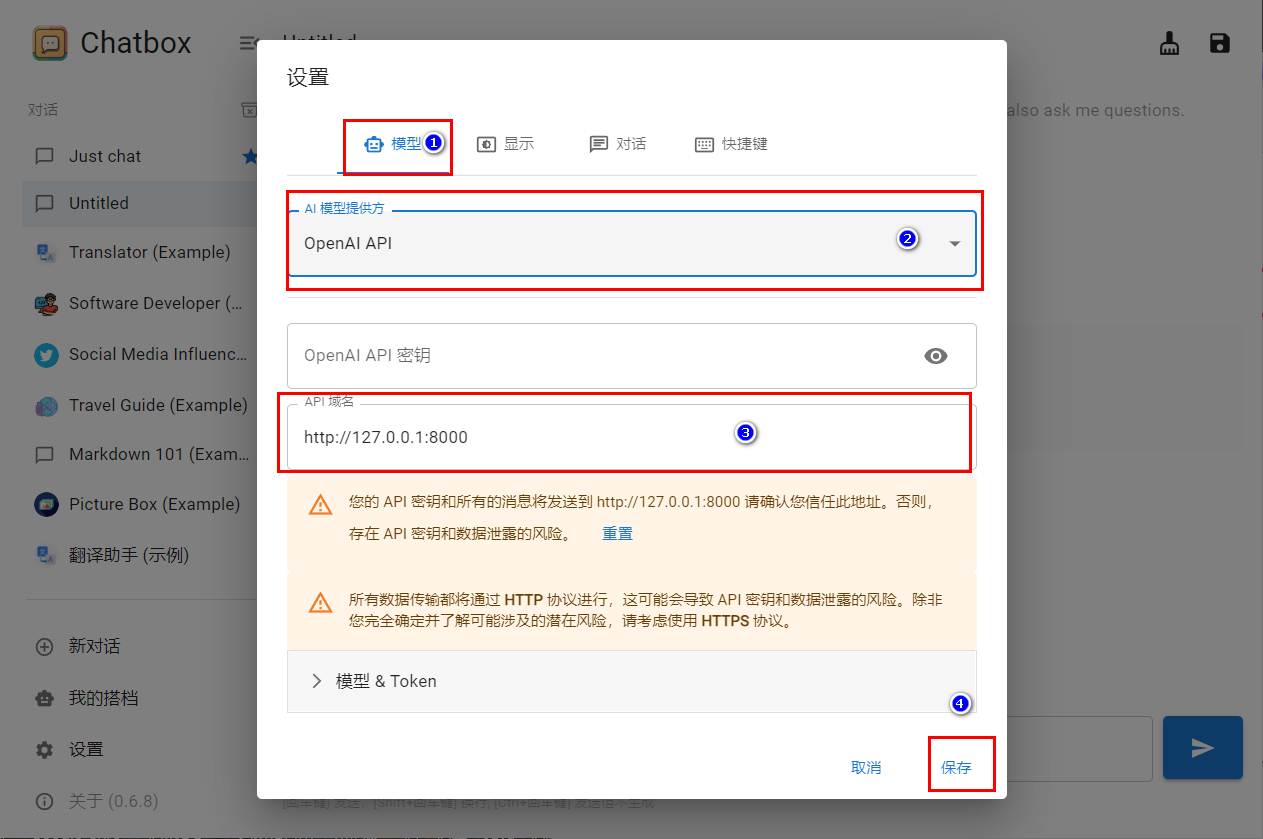
3.2、在ChatBox中配置本地模型
步骤如下:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号