
数据结构与算法(10)--查找
Ch10 查找
0x01 基本概念
查找:查询关键字是否在(数据元素集合)表中的过程。也称作检索。
主关键字:能够惟一区分各个不同数据元素的关键字。
次关键字:通常不能惟一区分各个不同数据元素的关键字。
查找成功:在数据元素集合中找到了要查找的数据元素。
查找不成功:在数据元素集合中没有找到要查找的数据元素。
静态查找:只查找,不改变数据元素集合内的数据元素。
动态查找:既查找,又改变(增减)集合内的数据元素。
静态查找表:静态查找时构造的存储结构。
动态查找表:动态查找时构造的存储结构。
平均查找长度:查找过程所需进行的关键字比较次数的平均值,是衡量查找算法效率的最主要标准。
0x02 静态查找表
静态查找表主要有三种结构。
顺序表,有序顺序表,索引顺序表。
顺序表
在顺序表上查找的基本思想是:从顺序表的一端开始,用给定数据元素的关键字逐个和顺序表中各数据元素的关键字比较,若在顺序表中查找到要查找的数据元素,则查找成功,函数返回该数据元素在顺序表中的位置;否则查找失败,函数返回-1。
int SeqSearch(DataType a[], int n, KeyType key)
//在a[0]--a[n-1]中顺序查找关键码为key的数据元素
//查找成功时返回该元素的下标序号;失败时返回-1
{
int i = 0;
while(i < n && a[i].key != key) i++;
if(a[i].key == key) return i;
else return -1;
}
算法效率分析:

有序顺序表
一种方法是和顺序表查找方法类似。
另一种方法是二分查找。
算法的基本思想:先给数据排序(例如按升序排好),形成有序表,然后再将key与正中元素相比,若key小,则缩小至前半部内查找;再取其中值比较,每次缩小1/2的范围,直到查找成功或失败为止。反之,如果key大,则缩小至后半部内查找。
int BiSearch(DataType a[], int n, KeyType key)
//在有序表a[0]--a[n-1]中二分查找关键码为key的数据元素
//查找成功时返回该元素的下标序号;失败时返回-1
{
int low = 0, high = n - 1; //确定初始查找区间上下界
int mid;
while(low <= high)
{
mid = (low + high)/2; //确定查找区间中心下标
if(a[mid].key == key) return mid; //查找成功
else if(a[mid].key < key) low = mid + 1;
else high = mid - 1;
}
return -1; //查找失败
}
算法效率分析:
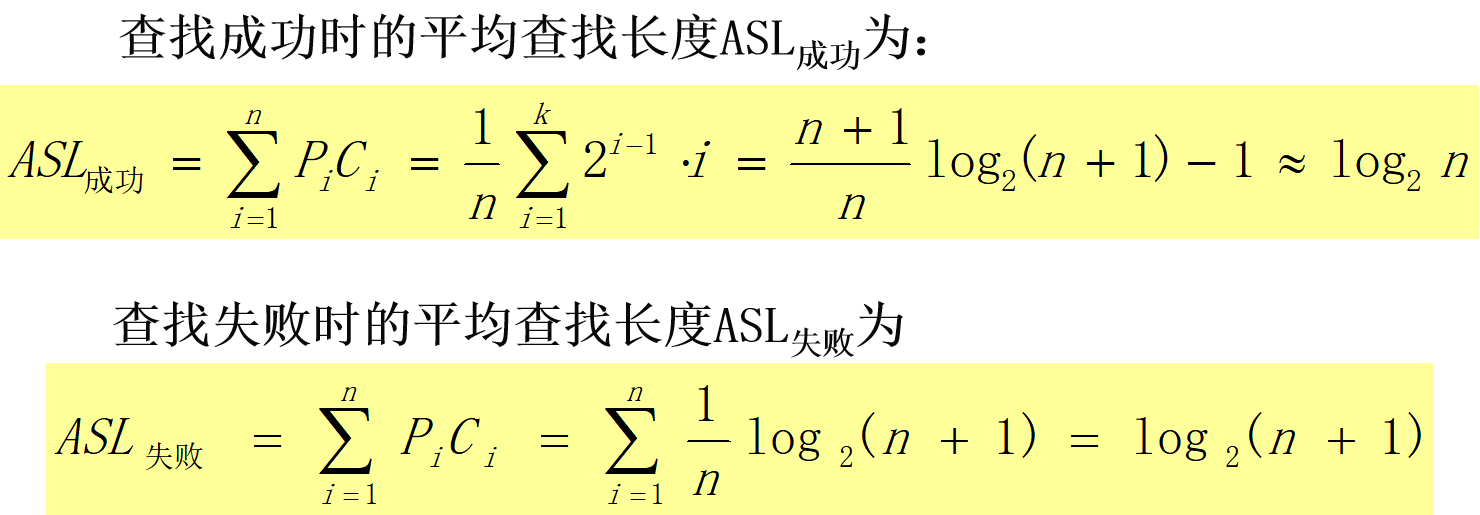
索引顺序表
当顺序表中的数据元素个数非常大时,采用在顺序表上建立索引表的办法提高查找速度。把要在其上建立索引表的顺序表称作主表。主表中存放着数据元素的全部信息,索引表中只存放主表中要查找数据元素的主关键字和索引信息。
完全索引表:和主表项完全相同,但只包含索引关键字和该数据元素在主表中位置信息的索引表
二级索引表:当主表中的数据元素个数非常庞大时,按照建立索引表的同样方法对索引表再建立的索引表。二级以上的索引结构称作多级索引结构
等长索引表:索引表中的每个索引项对应主表中的数据元素个数相等;反之称为不等长索引表。不等长索引表中的索引长度可随着动态插入和动态删除过程改变,因此不仅适用于静态查找问题,而且也适用于动态查找问题。

假设索引表的长度为m,主表中每个子表的长度为s,并假设在索引表上和在主表上均采用顺序查找算法,则索引顺序表上查找算法的平均查找长度为:
0x03 动态查找表
主要有二叉树结构和树结构两种类型。
二叉树结构:二叉排序树、平衡二叉树等
树结构:B-树,B+树等
二叉排序树
或是一棵空树;或者是具有如下性质的非空二叉树:
(1)左子树的所有结点均小于根的值;
(2)右子树的所有结点均大于根的值;
(3)它的左右子树也分别为二叉排序树。
构造过程略。
查找过程,遍历二叉排序树,并在遍历过程中寻找要查找的数据元素是否存在。
template <class T>
BiTreeNode<T>* BiSearchTree<T>::Find(const T &item)
{
if(root != NULL)
{
BiTreeNode<T> *temp = root;
while(temp != NULL)
{
if(temp->data == item) return temp; //查找成功
if(temp->data < item)
temp = temp->Right(); //在右子树继续
else
temp = temp->Left(); //在左子树继续
}
}
return NULL; //查找失败
}
插入过程
插入操作中首先查找数据元素是否在二叉排序树中存在,若存在则返回;若不存在,插入到查找失败时结点的左指针或右指针上。
template <class T>
void BiSearchTree<T>::Insert(BiTreeNode<T>* &ptr, const T &item)
{
if(ptr == NULL)
ptr = new BiTreeNode<T>(item); //生成并插入结点
else if(item < ptr->data)
Insert(ptr->Left(), item); //在左子树递归
else if(item > ptr->data)
Insert(ptr->Right(), item); //在右子树递归
}
删除算法
删除操作要求首先查找数据元素是否在二叉排序树中存在,若不存在则结束;存在的情况及相应的删除方法有如下四种:
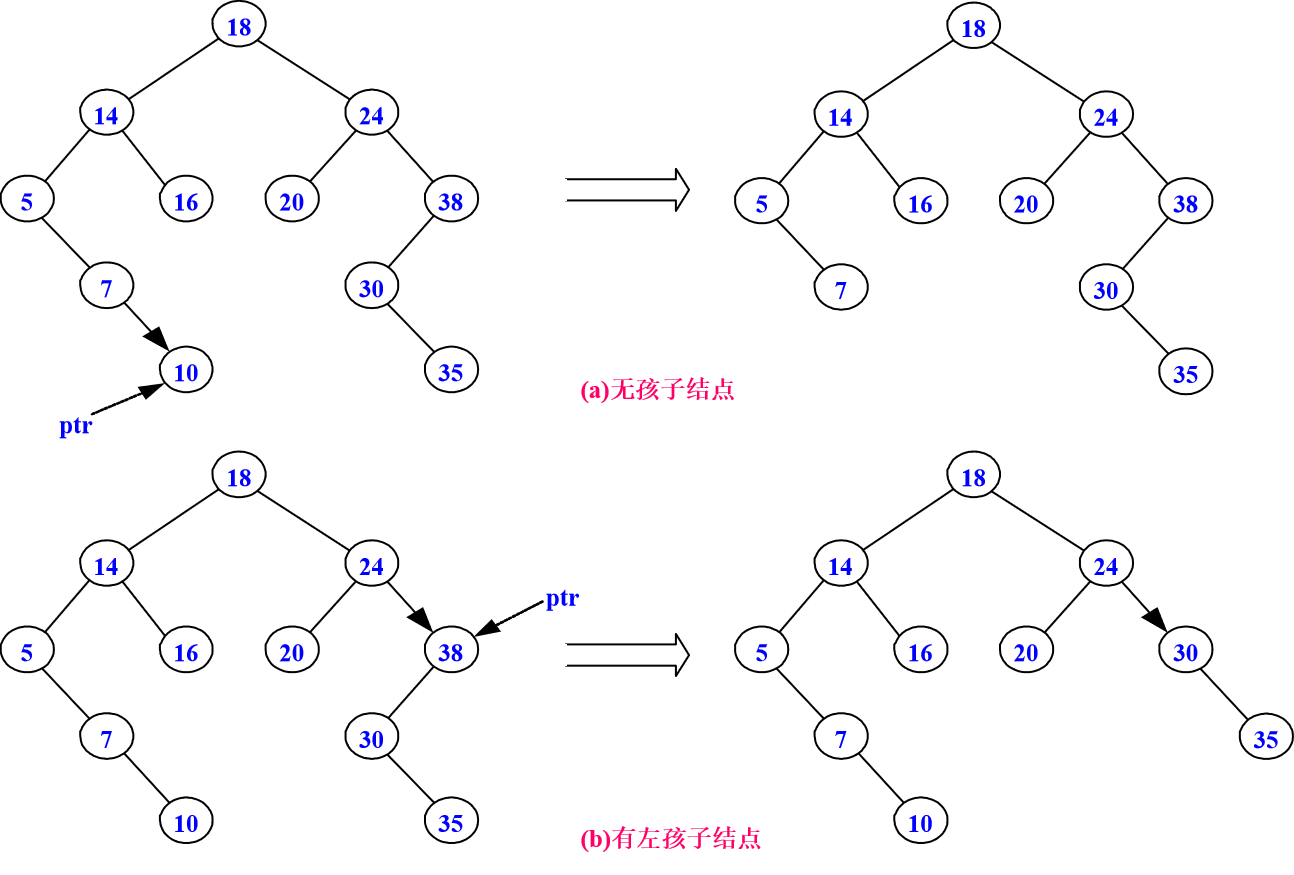
(1)要删除结点无孩子结点,直接删除该结点。
(2)要删除结点只有左孩子结点,删除该结点且使被删除结点的双亲结点指向被删除结点的左孩子结点。
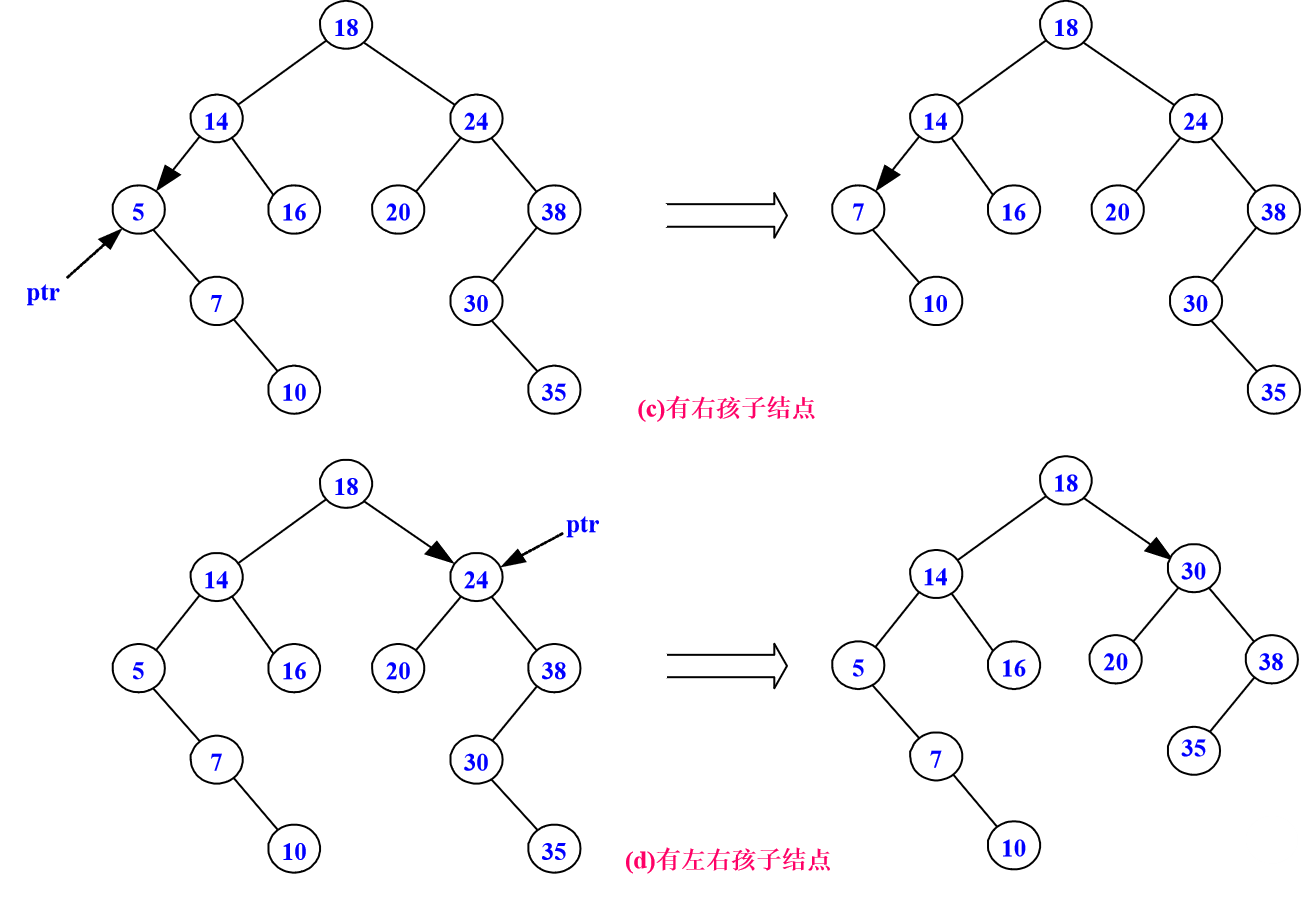
(3)要删除结点只有右孩子结点,删除该结点且使被删除结点的双亲结点指向被删除结点的右孩子结点。
(4)要删除结点有左右孩子结点,分如下三步完成:首先寻找数据元素的关键字值大于要删除结点数据元素关键字的最小值,即寻找要删除结点右子树的最左结点;然后把右子树的最左结点的数据元素值拷贝到要删除的结点上;最后删除右子树的最左结点。
性能分析:
若每个数据元素的查找概率相等,则二叉排序树查找成功的平均查找长度为ASL成功=log(n+1)
当二叉排序树是一棵单分支退化树时,查找成功的平均查找长度和有序顺序表的平均查找长度相同。即ASL成功=(n+1)/2
最坏情况下,平均查找长度O(n),一般情况下平均查找长度为O(logn)
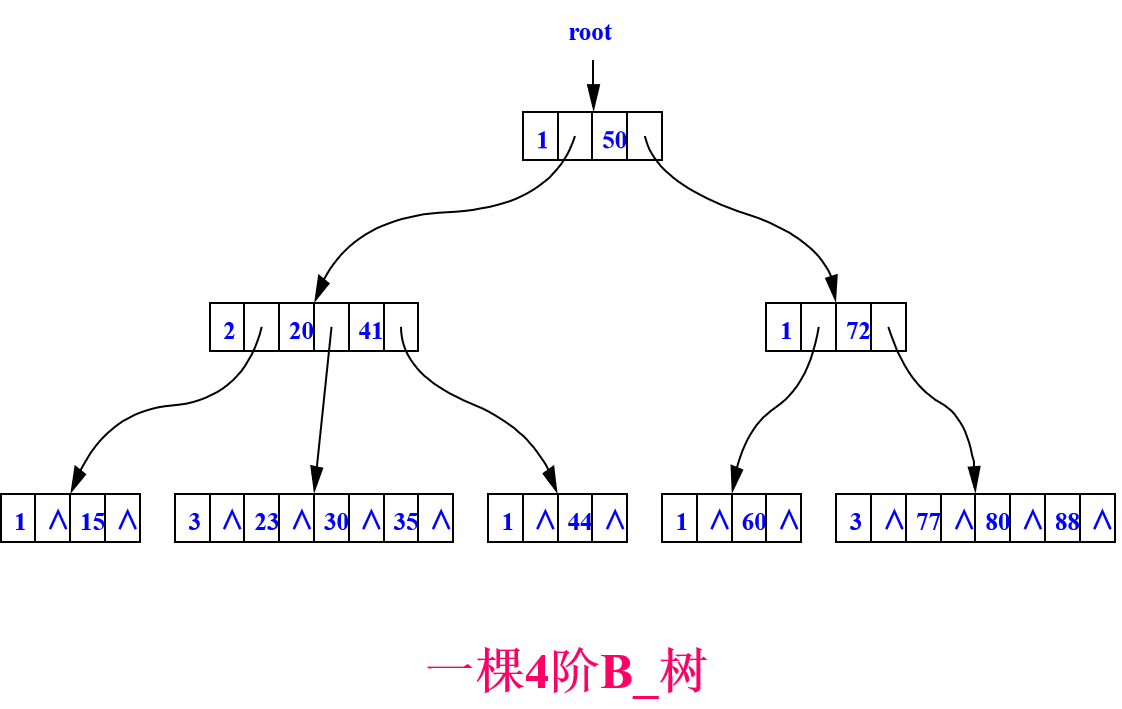
B-树
B_树是一种平衡多叉排序树。平衡是指所有叶结点都在同一层上,从而可避免出现像二叉排序树那样的分支退化现象。因此B_树的动态查找效率更高。
B_树中所有结点的孩子结点的最大值称为B_树的阶,一棵m阶的B_树或者是一棵空树,或者是满足下列要求的m叉树:
(1)树中每个结点至多有m个孩子结点。
(2)除根结点外,其他结点至少有m/2(向上取整)个孩子结点。
(3)若根结点不是叶结点,则根结点至少有两个孩子结点;
(4)所有叶结点都在同一层上。
(5)每个结点的结构为:

查找算法
在B_树上查找数据元素x的方法为:将 x.key与根结点的Ki逐个进行比较:
(1)若x.key=Ki则查找成功。
(2)若key<K1则沿着指针P0所指的子树继续查找。
(3)若Ki<key<Ki+1则沿着指针Pi所指的子树继续查找。
(4)若key>Kn则沿着指针Pn所指的子树继续查找。
插入算法
分两步:
(1)利用查找算法找出该关键字的插入结点。
(2)判断该结点是否还有空位置,即判断该结点是否满足n<m-1,若该结点满足n<m-1,说明该结点还有空位置,直接把关键字x.key插入到该结点的合适位置上;若该结点有n=m-1,说明该结点已没有空位置,要插入就要分裂该结点。(结点分裂具体方法略)
在3阶B_树上进行插入操作如下图示:
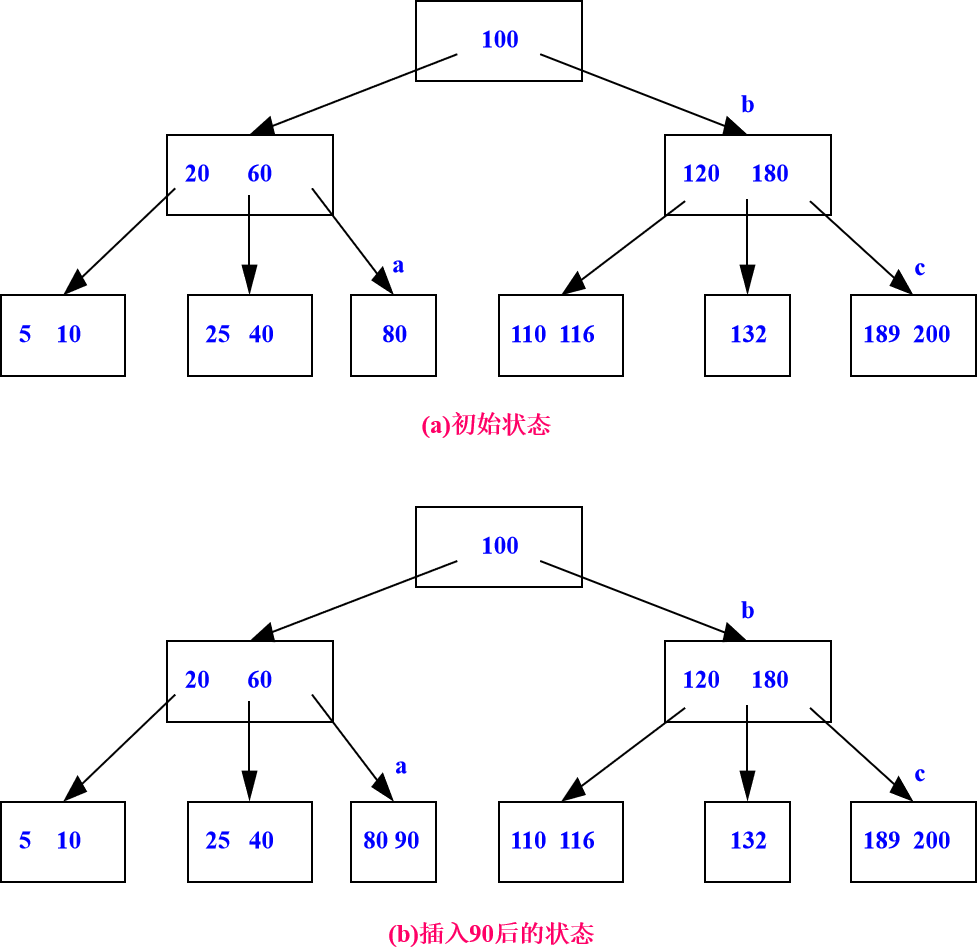
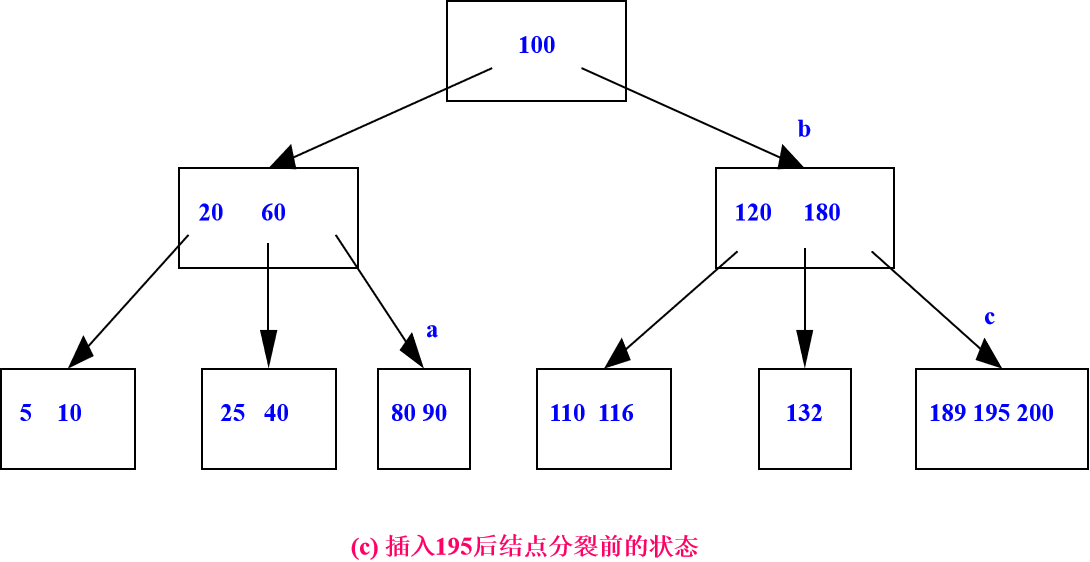
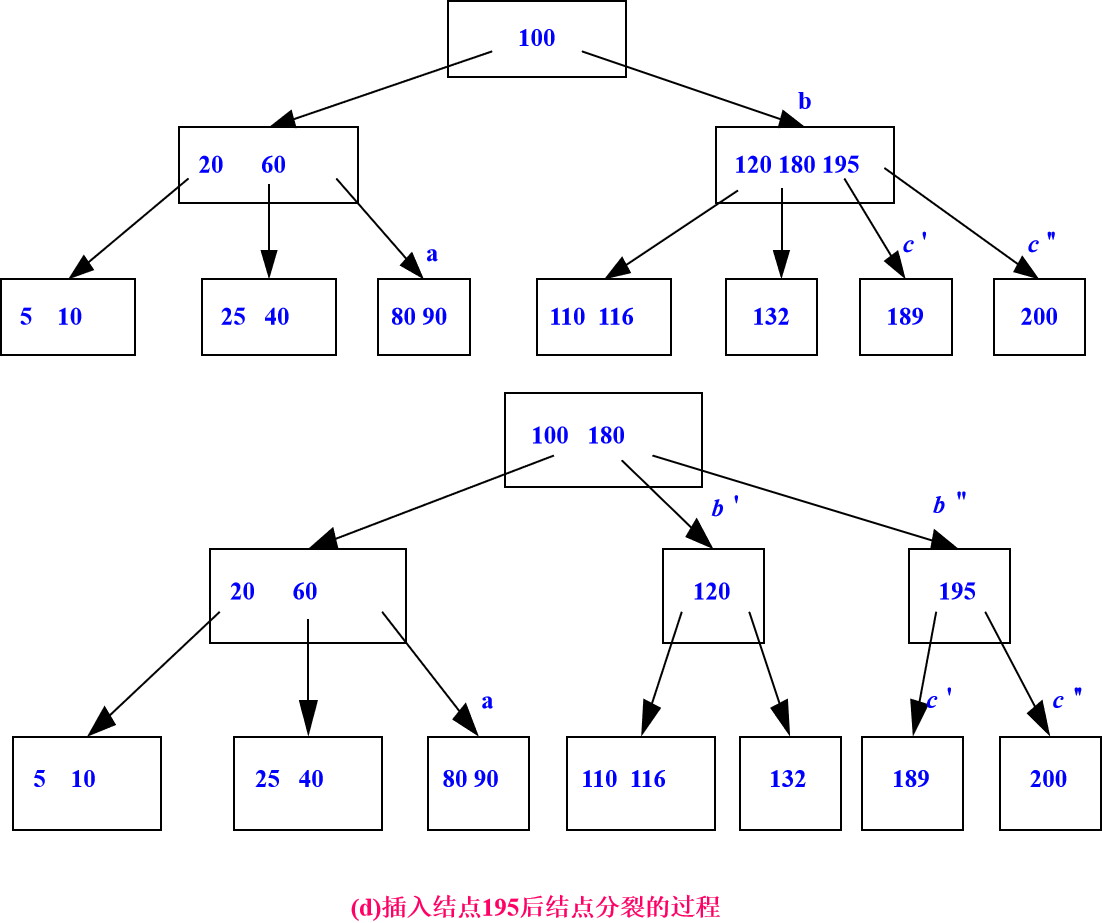
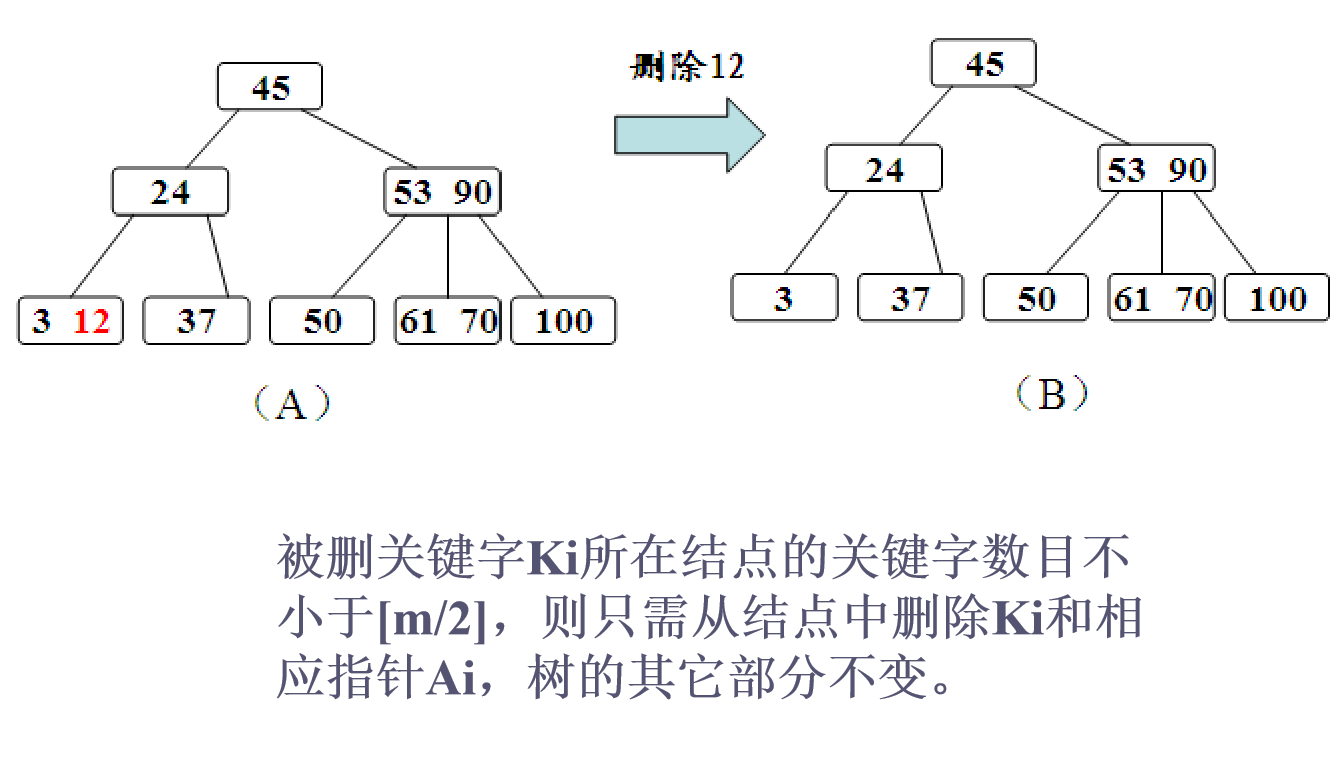
删除算法
分两步
(1)利用查找算法找出该关键字的插入结点。
(2)在结点上删除关键字x.key分两种情况
- 一种是在叶结点上删除(又分为三种情况):
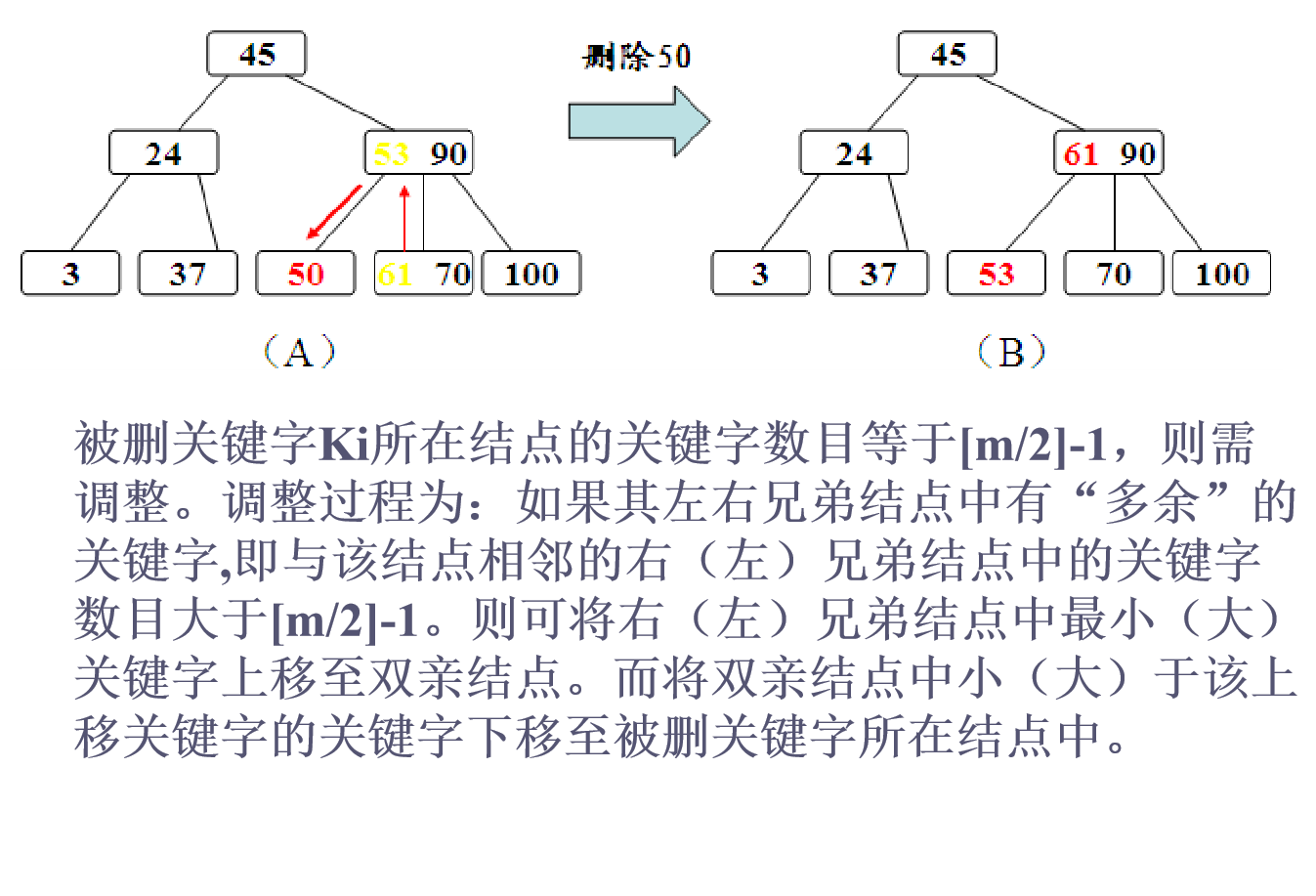
(a)假如要删除关键字结点的关键字个数n大于m/2-1,说明删去该关键字后该结点仍满足B_树的定义,则可直接删去该关键字。
(b)假如要删除关键字结点的关键字个数n等于m/2-1,说明删去该关键字后该结点将不满足B_树的定义,此时若该结点的左(或右)兄弟结点中关键字个数n大于m/2-1,则把该结点的左(或右)兄弟结点中最大(或最小)的关键字上移到双亲结点中,同时把双亲结点中大于(或小于)上移关键字的关键字下移到要删除关键字的结点中,这样删去关键字后该结点以及它的左(或右)兄弟结点都仍旧满足B_树的定义。
(c)假如要删除关键字结点的关键字个数n等于[m/2]-1并且该结点的左和右兄弟结点(如果存在的话)中关键字个数n均等于[m/2]-1,这时需把要删除关键字的结点与其左(或右)兄弟结点以及双亲结点中分割二者的关键字合并成一个结点。
- 另一种是在非叶结点上删除关键字。
在非叶结点上删除关键字时,假设要删除关键字Ki(1≤i≤n),在删去该关键字后,以该结点Pi所指子树中的最小关键字Kmin来代替被删关键字Ki所在的位置(Pi所指子树中的最小关键字Kmin一定是在叶结点上),然后再以指针Pi所指结点为根结点查找并删除Kmin(在非叶结点上删除问题就转化成了叶结点上的删除问题)。

0x04 哈希表
基本概念
哈希函数:数据元素的关键字和该数据元素的存放位置之间的映射函数
哈希表:通过哈希函数来确定数据元素存放位置的一种特殊表结构。
设要存储的数据元素个数为n,设置一个长度为m(m≥n)的连续内存单元,分别以每个数据元素的关键字Ki为(0≤i≤n-1)为自变量,通过哈希函数h(Ki),把Ki映射为内存单元的某个地址h(Ki),并把该数据元素存储在这个内存单元中。哈希函数h(Ki)实际上是关键字Ki到内存单元的映射,因此,h(Ki)也称为哈希地址,哈希表也称作散列表。
哈希冲突:Ki≠Kj(i≠j),但h(Ki)=h(Kj)的现象称作哈希冲突。这种具有不同关键字而具有相同哈希地址的数据元素称作“同义词”,由同义词引起的冲突称作同义词冲突。
构造哈希表时,冲突是难以避免的,有关因素有如下三个:
(1)装填因子。装填因子是指哈希表中已存入的数据元素个数n与哈希地址空间大小m的比值,即α=n/m,α越小,冲突的可能性就越小,但哈希表中空闲单元的比例就越大; α越大(最大可取1)时,冲突的可能性就越大,但哈希表中空闲单元的比例就越小,存储空间的利用率就越高。
(2)与所采用的哈希函数有关。
(3)与解决哈希冲突的哈希冲突函数有关。
解决哈希冲突的基本思想是通过哈希冲突函数(设为hl(K)(l=1,2,…,m-1))产生一个新的哈希地址使hl(Ki)≠hl(Kj)
哈希函数的构造方法
常用方法:
除留余数法、直接定址法、数字分析法。

三、数字分析法:
特点:取数据元素关键字中某些取值较均匀的数字位作为哈希地址,只适合于所有关键字值已知的情况
哈希冲突解决方法
开放定址法、链表法
开放定址法
思路:以发生哈希冲突的哈希地址为自变量、通过某种哈希冲突函数得到一个新的空闲的内存单元地址。
- 线性探查法
![哈希冲突线性探查法.png]()
- 平方探查法
![哈希冲突平方探查法.png]()
- 伪随机数法
![哈希冲突伪随机数法.png]()



链表法
思路:如果没有发生哈希冲突,则直接存放该数据元素;如果发生了哈希冲突,则把发生哈希冲突的数据元素另外存放在单链表中(方法有两种:第一种方法是为发生哈希冲突的不同的同义词建立不同的单链表;第二种方法是为发生哈希冲突的所有同义词建立一个单链表。)。
例题
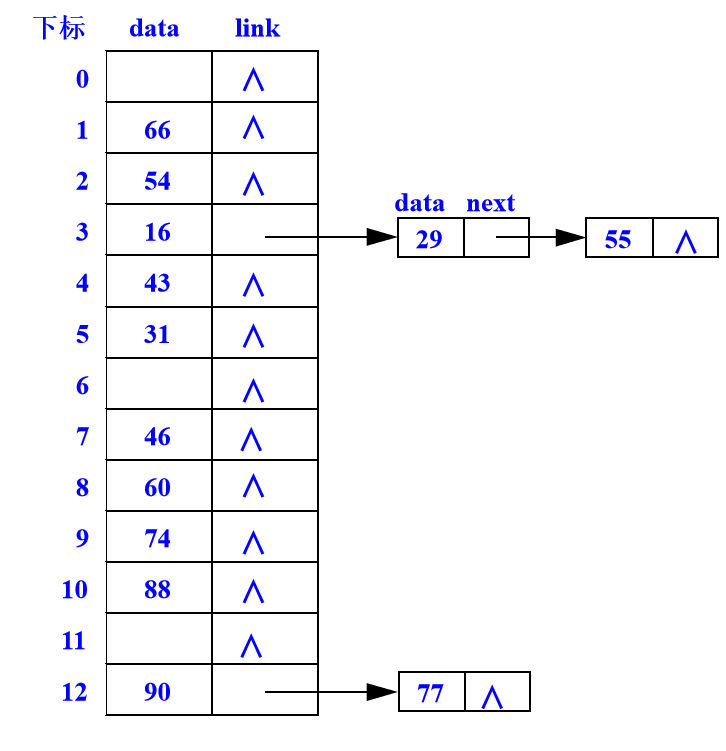
建立数据元素集合a的哈希表。a = {16, 74, 60, 43, 54, 90, 46, 31, 29, 88, 77, 66, 55}。要求哈希函数采用除留余数法,解决冲突方法采用链表法。
分析:
数据元素集合a中共有13个数据元素,取哈希表的内存单元个数m=13。除留余数法的哈希函数为:h(K) = K mod m
则有:
h(16) = 3 h(74) = 9 h(60) = 8
h(43) = 4 h(54) = 2 h(90) = 12
h(46) = 7 h(31) = 5 h(29) = 3
h(88) = 10 h(77) = 12 h(66) = 1
h(55) = 3
采用链表法的第一种方法建立的哈希表存储结构如下图所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号