


slice(一)——初识底层结构
如果你承认自己不是一个聪明的人,那么就请花别人不愿花的精力,冒别人不愿冒的风险,不敢说能够望其项背,至少不要让差距再度扩大。
Slices wrap arrays to give a more general, powerful, and convenient interface to sequences of data. Except for items with explicit dimension such as transformation matrices, most array programming in Go is done with slices rather than simple arrays.
上述文字是Go官方文档对slice这个内置类型的一个笼统性介绍,最后一句话指出了在Go语言编程中,相较于array,slice更为常用,为什么?很简单,它更灵活,不像数组,在定义实例时,必须预先分配好内存,而且之后不可改变。slice如同C++的vector容器一样,可以根据需要动态的伸缩其大小。
但是世上没有绝对的好坏之分,slice的灵活性是依靠底层更为复杂的机制来支持,这也就给类似于我这种不懂得其底层实现的程序员编写出来的程序带来了不小的安全隐患,有时可能是灾难性的。
1. 问题重现
在较为深入的了解slice底层实现之前,我从一些书上了解到,slice是引用类型,而我们都知道,引用类型和值类型的主要区别在于赋值,如下:
b = a
b.Modify()
如果b的修改不会影响a的值,那么此类型就属于值类型,否则,此类型就是引用类型。
Okay,我们来写一段简单的代码来验证下:
func test1() { var a []int = make([]int, 1) a[0] = 5 fmt.Printf("before modifying: %v\n", a) b := a b[0] = 6 fmt.Printf("after modifying: %v\n", a) }
结果如下:

嗯,结果是我们预料的那样,b的修改确实影响了a的值。
有了上面的验证,我们不禁又会想到,如果我们往b里面添加一个元素,相应的,a的元素个数也会变成两个才对。让我们对上面的代码进行一下修改,来验证我们这个猜想。改动后的代码如下:
func test1() { var a []int = make([]int, 1) a[0] = 5 fmt.Printf("Before appending a element, a is: %v\n", a) b := a b = append(b, 6) fmt.Printf("After appending a element, a is: %v\n", a) fmt.Printf("After appending a element, b is: %v\n", b) }
快来看看运行结果:

嗯?看到这样的结果,我的感受可以用下图诠释:

看到这里,应该有些看官心里已经在偷偷的嘲笑小弟了:小伙子儿,还是太年轻了,这个结果爷早就想到了。
哈哈,没关系,让我们直入腹地,一探究竟。

2. 揭开面纱
要真正的弄清楚上述的问题,唯一的捷径就是直达本质,也就是搞清楚它的底层实现。
从Go语言官方文档了解到,我们在程序中定义的每一个slice变量,标准编译器在底层都为它们定义了一个运行时数据结构的实例,该数据结构大致如下:
type slice struct { array unsafe.Pointer len int cap int }
我们回过头去再看看博客最开始的那段英文描述:
Slices wrap arrays to give a more general, powerful, and convenient interface to sequences of data.
这句话虽看起来笼统,实则是对slice底层实现的高度概括。实际上,slice是一种轻量级结构,每一个slice实例都是对一个array的引用(也可能多个slice对应同一个array)。我们可以用下图来表示slice和其对应的array的关系:
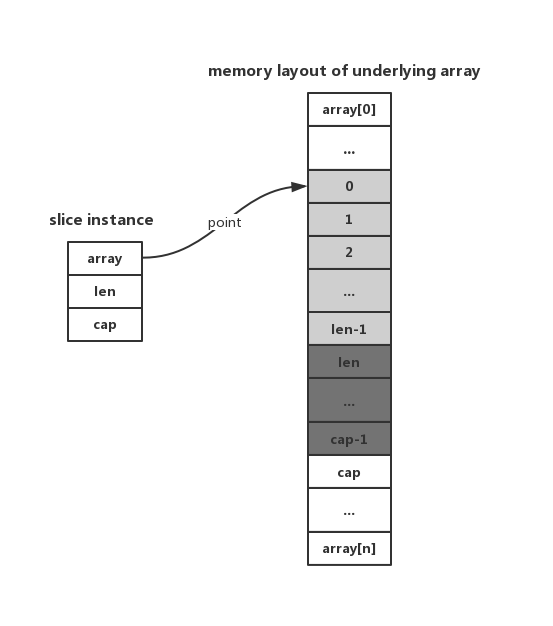
从上图可以看出,尽管slice所包含的元素可能位于一个较大的内存片段上,但是它只能感知其中的一部分,也就是图中非白色的部分,这由first指针、len以及cap三者共同决定。
① array指针
array指针指向底层array的某一个元素,其决定slice所能控制的内存片段的起始位置,这里需要注意的是,array不一定指向底层array的首元素,这与slice的创建有关。
② len
len用来限定slice可直接通过索引(下标)存取元素的范围,对应到上图也就是从0到len-1(浅灰色部分)的内存片段,超过此范围,就会出现我们经常遇到的下标越界问题,在运行时,Go标准编译器会报如下错误:
panic: runtime error: index out of range [x] with length y
③ cap
cap表示slice所引用的array片段的真实大小,对应上图为0到cap-1(浅灰色和深灰色部分的总和)的内存片段。也就是说只有这一部分内存片段是真正属于这个slice的,可以任意"挥霍"。
那我们不禁又会问道,如果我们的对内存的需求超过了cap怎么办?没关系,Go语言已经帮我们想好了解决办法,当我们已使用的内存达到了cap之后,欲继续扩张内存,Go底层会在这个此array之外重新开辟一段内存,其大小为cap的两倍,并将slice中的所有元素拷贝至新的内存片段,以及相应的修改slice对应的数据结构,如何修改?
1)array指针指向新内存片段的首个内存单元的地址;
2)len = len + 1;
3)cap = 2 * cap
3. 回归问题
基于上述对切片底层结构的透析,我们可以在下列代码处打断点,探究底层经历了什么过程:
b = append(b, 6)
开始GDB调试,当程序执行到断点处,我们可以看到此时a和b底层结构的内容是相同的:

由此我们可以得出一个结论,切片之间的赋值实则是对应底层结构的赋值,使它们都维护同一块内存片段。
再执行一步,程序就调用了如下堆栈:
1 // growslice handles slice growth during append. 2 // ... 3 func growslice(et *_type, old slice, cap int) slice
我们从注释中可以了解到此函数的功能是调用append时对切片进行扩容。该函数的三个参数分别表示切片的元素类型、 扩容之前切片的底层结构以及期望的最小的扩容容量(即为原来的容量加上新添加的元素数量)。
我们来看看这个函数中决定新容量大小的核心代码:
1 newcap := old.cap 2 doublecap := newcap + newcap 3 if cap > doublecap { 4 newcap = cap 5 } else { 6 if old.len < 1024 { 7 newcap = doublecap 8 } else { 9 // Check 0 < newcap to detect overflow 10 // and prevent an infinite loop. 11 for 0 < newcap && newcap < cap { 12 newcap += newcap / 4 13 } 14 // Set newcap to the requested cap when 15 // the newcap calculation overflowed. 16 if newcap <= 0 { 17 newcap = cap 18 } 19 } 20 }
通过分析以上代码,一般情况下,只要原切片中的元素个数不超过1024,最后新的容量即为原容量的两倍。其它的情况不为常见,了解即可。
再来看下面这段代码:
var p unsafe.Pointer if et.ptrdata == 0 { p = mallocgc(capmem, nil, false) // The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length). // Only clear the part that will not be overwritten. memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem) } else { // Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory. p = mallocgc(capmem, et, true) if lenmem > 0 && writeBarrier.enabled { // Only shade the pointers in old.array since we know the destination slice p // only contains nil pointers because it has been cleared during alloc. bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem) } } memmove(p, old.array, lenmem) return slice{p, old.len, newcap}
可以看出返回的新的切片的头部指针指向了新分配的内存,并且已经把原切片的数据拷了过去。返回的新切片的容量为原切片容量的两倍。但是此时新切片的长度len等于原来切片的长度,这一点有的看官可能有些疑惑?不必疑惑,因为此函数的功能只是重新分配内存,把原切片的数据拷过去,此时还没有考虑新加入的元素。通过反汇编,找到如下代码:

可以看出,当growslice栈帧返回后,最后会把新的元素,即6,放入rax寄存器存储的地址再加上8个内存单元的位置,此位置实际上就是切片b所占内存片段的下一个内存单元的地址。
此时,就完成了切片b的扩容。
通过前面所有的分析,我们可以总结出,虽然最开始切片b和切片a是指向的是同一块内存单元,但是当切片b扩容之后,其就指向全新的一块内存,与切片a再无瓜葛。
4. 总结
那么,坑就摆在面前,对于不了解这个过程的人,很有可能是个安全隐患。
我个人的建议,当我们使用切片作为函数的参数,并且该函数的功能语义就是往该切片中添加新的元素时,那么,请用指针!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号