

目录
通用选择器
通用选择器可以选择页面上的所有元素,并对它们应用样式,用 * 来表示。
语法:
* { property1: value; property2: value; }
示例:
* { margin:0; padding:0;}
这行代码可以删除每个元素在浏览器中margin和padding的默认值。不同的浏览器对元素的默认margin和padding可能不同,用通用选择器把所有元素的margin和padding都设置为0方便我们精确地控制元素的margin和padding。
此处我们以IE11为例看一下实际效果:
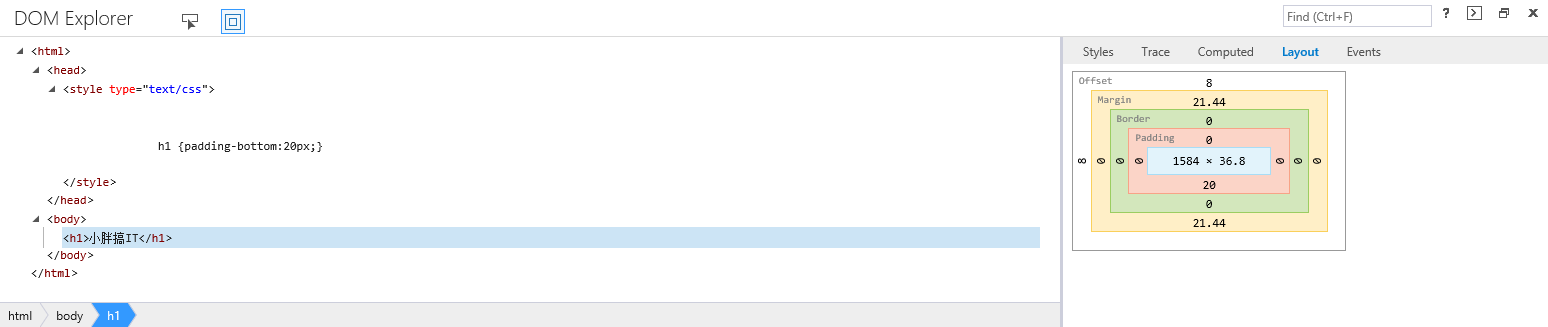
当我们想要h1距离下一个元素的距离为20(此处假设下一个元素的margin-top, padding-top和border-weight都是0),可以通过设置padding-bottom为20px来实现,但观察效果却发现h1距离下一个元素远不止20px,这是由于IE11对h1有一个默认的margin值(可以观察到其实body也是有默认margin的),可以通过通用选择器来修复这个问题:
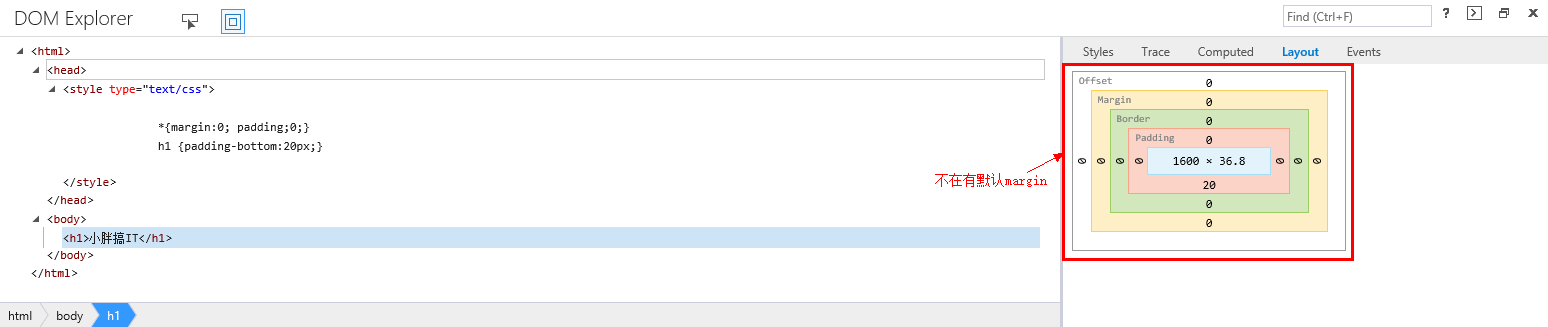
子选择器
后代选择器选择一个元素的所有后代,而子选择器只选择元素的直接后来,即后代的后代不会受影响。
语法:
selector > child { property1: value; property2: value; }
示例:

<html> <head> <style type="text/css"> #test>li{padding-left:30px;} </style> </head> <body> <ul id="test"> <li>A</li> <li>B</li> <li>C <ul> <li>C1</li> <li>C2</li> <li>C3</li> </ul> </li> <li>D</li> </ul> </body> </html>
效果图:
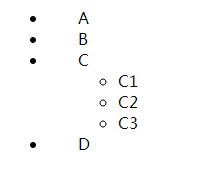
#test>li{padding-left:30px;}
这行代码选择了id为test的子元素li,并将padding-left设置为30px,可以看到 li 标签内部的无序列表项目没有发生变化。若将以上代码改为
#test li{padding-left:30px;}
再来看一下效果图:

li中无序列表项的padding也发生了相应改变。
Note: 只有IE7机器更高版本浏览器才支持子选择器。
相邻兄弟选择器
相邻兄弟选择器可以选择同一个父元素下某个元素之后的元素,并对其应用样式。
示例:
<html> <head> <style type="text/css"> h1+p{color:Red;} </style> </head> <body> <h1>小胖搞IT</h1> <p>一个胖子从楼上掉下来...</p> <p>然后............</p> <p>奇迹发生了!</p> <p>他弹了起来!</p> </body> </html>
效果图:

h1+p{color:Red;}
这行代码选择了h1元素的下一个元素p,并将其设置为红色。
Note: 只有IE7机器更高版本浏览器才支持子选择器。
一个子选择器和相邻兄弟选择器结合使用的例子:
<html> <head> <style type="text/css"> #test > h1 + p {color:Red;} </style> </head> <body> <div id="test"> <h1>小胖搞IT</h1> <p>一个胖子从楼上掉下来...</p> <p>然后............</p> <p>奇迹发生了!</p> <p>他弹了起来!</p> <div> <h1>瘦子搞IT</h1> <p>一个瘦子从楼上掉下来...</p> <p>然后............</p> <p>奇迹没有发生!</p> <p>他摔死了!</p> </div> </div> </body> </html>
效果图:

#test > h1 + p {color:Red;}
这行代码选择了id为test的元素的h1子元素,再找到它的下一个兄弟元素p,并设置为红色, <h1>瘦子搞IT</h1> 不是id为test的div的子元素,故没有变化。
属性选择器
属性选择器可以根据某个属性是否存在或根据属性的值来寻找元素,并对其使用样式。
语法:

示例:
<html> <head> <style type="text/css"> a[title]{font-size:30px;} a[title="Fatty"]{color:Red;} a[title~="Fatty"] {font-weight:bold;} a[title|="FattyDoIT"] {font-style:italic;} a[title^="F"]{text-decoration:line-through; } a[title$="IT"]::before {content:url(star.png);} a[title*="Do"]::after {content:url(heart.png);} </style> </head> <body> <a href="http://www.cnblogs.com/fattydoit/">小胖搞IT</a><br> <a href="http://www.cnblogs.com/fattydoit/" title="FattyDoIT">小胖搞IT</a><br> <a href="http://www.cnblogs.com/fattydoit/" title="Fatty">小胖搞IT</a><br> <a href="http://www.cnblogs.com/fattydoit/" title="Fatty Do IT">小胖搞IT</a> </body> </html>
效果图:

a[title]{font-size:30px;}
这行代码选择了所有具有title属性的a元素,并将字体大小设置为30px;
a[title="Fatty"]{color:Red;}
这行代码选择title值为Fatty的a元素,并将字体颜色设置为红色;
a[title~="Fatty"] {font-weight:bold;}
这行代码选择title所有属性值中包含Fatty的a元素,并将字体加粗;
a[title|="FattyDoIT"] {font-style:italic;}
这行代码选择title值以FattyDoIT开头且是一个单词的a元素,并将字体改为斜体;
a[title^="F"]{text-decoration:line-through; }
这行代码选择title属性值以F开头的所有a元素,并设置text-decoration为line-through;
a[title$="IT"]::before {content:url(star.png);}
这行代码选择title属性值以IT结尾的所有a元素,并在之前放置一张图片;
a[title*="Do"]::after {content:url(heart.png);}
这行代码选择title属性值中包含Do的所有a元素,并在之后放置一张图片。
Note: 只有IE7机器更高版本浏览器才支持子选择器。
参考资料:
通用选择器和高级选择器介绍到此结束,下一回来介绍选择器的层叠和特殊性...
-
基于栈空间的优化:
在C语言中函数调用是基于程序堆栈机制,函数调用会进行压栈操作,堆栈被用来保存函数返回地址、寄存器值、入参、局部变量等信息,在函数调用过程中需要在栈上分配空间并对栈空间初始化,一个典型的程序堆栈入下图所示: 函数调用时,首先分配被调用函数的参数空间将其初始化,将其压入调用者的堆栈中,然后将返回地址压入调用者的堆栈。被调函数的堆栈开始依次保存了ebp寄存器、其它一些寄存器的值(用于存放上一个函数的部分局部变量)、对于不能存放在寄存器中的局部变量信息将会保存在栈空间中。了解了函数栈机制,通过对函数进行适当的调整就可以显著的优化性能。
函数调用时,首先分配被调用函数的参数空间将其初始化,将其压入调用者的堆栈中,然后将返回地址压入调用者的堆栈。被调函数的堆栈开始依次保存了ebp寄存器、其它一些寄存器的值(用于存放上一个函数的部分局部变量)、对于不能存放在寄存器中的局部变量信息将会保存在栈空间中。了解了函数栈机制,通过对函数进行适当的调整就可以显著的优化性能。
1:通过修改入参的传递方式的优化,一个典型的例子是作为结构体的入参,如下所示:
void Fun1(struct St st);
void Fun2(struct St *pSt);
Fun1需要在被调函数的栈上分配对应大小的空间并将结构体整体拷贝过去。入下图:

Fun2只需要分配一个地址空间并且保存结构体的地址信息,入下图:

2:通过使用非本地跳转来提升异常返回效率。
对于正常的函数调用返回需要一层层的解开函数调用栈,在异常情况下可以通过非本地跳转直接返回到调用点处理,避免解开多层的调用栈。
3:通过使用全局变量来替换函数的局部变量可以避免每次函数调用局部变量空间分配和初始化。
4:通过宏来替换函数调用可以避免栈的开销。
-
基于计算策略的优化:
1:推迟计算
在程序中可能存在批量的资源申请,如果批量申请十分耗时并且存在部分资源不会马上被使用或者可能不会用到,可以把资源分配的过程推迟到真正需要的时候。一个典型的例子是Linux的写时拷贝技术,其核心思想就是父子进程共享相同的物理空间,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。下面是一个通过引用记数模拟写时拷贝的例子:
 View Code
View Code2:预先计算
对于某些要求操作的可以预测性、低延迟的系统,要提高运行的性能,我们通过可以提前获取资源,在系统启动过程中就获取所有资源并且高效的存放起来,后期直接使用。比如运行过程中动态内存的申请,其开销很大并且时间不固定,通过预测系统内存使用量,在启动期间申请所有动态内存并通过自定义的高效内存池来进行管理。
3:避免计算
通常一些好的编程习惯,可能会导致性能的恶化,比如数据块的初始化,在代码中经常可以看到malloc后马上memset,然后再对数据块赋值,如果操作的内存块很大,对性能影响很明显。变量初始化是一个好的编程习惯,但如果跟性能冲突尽可能避免这样的操作或者只对关键的数据进行初始化,避免大块数据的操作。
-
基于内存对齐的优化:
为了能使 CPU 对变量进行高效快速的访问,变量的起始地址应该具有某些特性,即所谓的 “ 对齐 ” 。例如对于 4 字节的 int 类型变量,其起始地址应位于 4 字节边界上,即起始地址能够被 4 整除。变量的对齐规则如下( 32 位系统):
|
Type |
Alignment( 默认的自然对齐 ) |
|
char |
在字节边界上对齐 |
|
short(16-bit) |
在双字节边界上对齐 |
|
int long (32-bit) |
在 4 字节边界上对齐 |
|
float |
在 4 字节边界上对齐 |
|
double |
在 8 字节边界上对齐 |
|
structures |
单独考虑结构体的每个成员,它们在不同的字节边界上对齐。 其中最大的字节边界数就是该结构的字节边界数 |
如果访问未对齐的地址需要两个总线周期来访问两次内存,而对齐的地址只需要一个总线周期来访问一次内存。编译器中提供了#pragma pack(n)来设定变量以n字节对齐方式。n字节对齐就是说变量存放的起始地址的偏移量有两种情况:第一、如果n大于等于该变量所占用的字节数,那么偏移量必须满足默认的对齐方式,第二、如果n小于该变量的类型所占用的字节数,那么偏移量为n的倍数,不用满足默认的对齐方式。结构的总大小也有个约束条件,分下面两种情况:如果n大于所有成员变量类型所占用的字节数,那么结构的总大小必须为占用空间最大的变量占用的空间数的倍数;否则必须为n的倍数。
入下例所示当指定4字节对齐时:
#pragma pack(4)
struct A
{
short a;
int b;
short ;
};
#pragma pack()
假设a的初始化地址为0,则b的地址为4,c的地址为8,总共占用12个字节空间,为了对齐浪费了4个字节空间。
入下例所示当指定1字节对齐时:
#pragma pack(1)
struct A
{
short a;
int b;
short c;
};
#pragma pack()
假设a的初始化地址为0,则b的地址为2,c的地址为4,数据紧凑存放节省了存储空间,但由于b并没有对齐导致对b的操作需要两次访问内存。
以上两种声明方式分别针对时间和空间性能的优化,但如果我们合理的设计结构体中的成员位置,则可以兼顾时间和空间的性能。入下例所示:
#pragma pack(1)
struct A
{
short a;
short c;
int b;
};
#pragma pack()
假设a的初始化地址为0,则c的地址为2,b的地址为4,数据紧凑存放而且各个变量都是对齐的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号