

文档开发流程
最近,公司的重大项目快完工了,除了留下一些Bug,还留下了一些收尾工作,比如我今天要讲的文档。在会上,经理说,怕研发人员写文档写不好。不论经理有没有说包含激将之意的言语,写文档都是一项挑战性的工作。
文档开发流程
网上并没有给出一个比较完美的文档模板,如何写这个文档呢?写文档不能简单的看作写一篇文章。它也与软件开发一样,有一个逐步完善的流程。这是我写文档过程中的流程:

图1 文档开发流程
1. 确定条件和背景。
在文档开发的最初阶段需要了解文档写作的内、外部的条件和背景。不同的专业存在不同的专业背景,对于专业软件不是按照一个文档模板,就能把所有的文档写出来。
文档写作的内部条件:
(1)公司的产品是大型机械设备的状态监测的软件,软件中有许多图谱和报表,用于显示状态监测的数据。软件的专业性体现在图谱和报表中,而非软件的操作当中。
(2) 当前软件的可运行的版本并不是稳定的版本,写出来的文档必须符合稳定版本的软件的内容。当然存在一种情况,那就是后面的一个版本(也就是正在做的版本)是一个用户界面比较完善的版本。
开发人员需要对当前软件所处的状态做出一些总结,以便在写文档时,给自己做出指导。
文档写作的外部条件
(1)用户群体的认识。用户主要分为几种:工程人员、销售人员、专业人士。在这些用户当中,我们更关注衣食父母-专业人士。对于专业人士,查看图谱和报表是他们的强项,而他们将面临的是一个新的软件,他们需要的是培养一些新的操作习惯。
(2)文档的最终形式为打印稿。这些专业人士,很多都是经验丰富的老专家,写出的文档需要照顾到老专家们的视觉感受。
这些外部条件是开发人员所容易忽视的,却是经理们所清晰了解的。在开发之初我的经理们就把这些信息在话语中透露给大家。
了解文档开发的内、外部条件,能让我们在文档开发当中,找到一个大的方向。没有找到大方向,很容易剑走偏锋,比如:我花很大的力气来写图谱的内涵,而这是专家所熟知的,到头来说不定,我写的有很多错误、不够详细。
2. 明细要求和准备资源
写文档之前,明细各项要求,才能写出优秀的文档。什么样子才能算优秀的文档呢?这个很难说,但是如果要说你见过哪些狗血的文档,你可以马上大量吐槽:
- ·××,居然还有错别字!
- ·黑压压的一片(文字),看都不想看。
- ·啥文档?找了半天,这个设置功能就是找不到。
- ·我发下这篇文章不适合新手。
细数这些吐槽的片段,作为文档的作者不得不小心翼翼了。文档的明细要求来自于文档的不同的用户。
经理在文档出来前,提出的模糊要求:
(1)文档要符合用户操作。一般我们阅读是从左到右,从上到下。
(2)写出清晰、完整的文档。
(3)能让用户快速入门。
(4)写出的文档可操作性要强,不能出现告诉别人一个功能,而他不知道如何才能达到这些效果。
经理在文档出来后,提出的苛刻要求:
(1)这些文档格式不统一。重写!
(2)段落结构混乱。重写!
(3)归纳的重点偏离。重写!
测试提出质量要求:
(1)完整性。界面上的功能点,都需要写出来。不能却胳膊少腿。
(2)准确性。准确描述功能,给出的步骤能让测试人员实现,并达到预期的效果。
(3)优美性。格式优美,结构清晰,看上去舒服。
自己的要求
(1)快点写完这文档。
(2)写好点,别让我重写,别被吐槽。
用户的要求
(1)快速了解内容
(2)查看感兴趣的部分。
(3)帮助解决问题。
(4)能看懂。
在操刀动笔之前,必须做好准备:
(1)选用一个界面完整的,且不会再做其他修改的软件版本,作为截图的来源。
(2) 软件的数据必须接近真实。
(3)问问工程人员与销售人员有没有前一版本的文档。
3. 提纲。
提纲构筑了整个文章的骨架。按照模板写或者按照前人的模式写,容易让文档缺乏条理。使用提纲,能让文档章节分明,结构清晰,内容详细而充实。下图即本文该章节的提纲的一部分(该图使用的软件是MindManager):

图2 提纲
在提纲中划分了章节和细化了一些要点,有了它之后,一篇完整的文章就填满心中。
4. 编写与审阅。
第一次编写是依据提纲来完成的。如果要添加内容,则先在提纲上做出修改,再修改内容。第一次编写内容,要求做到完美比较难。在写的过程中会遇到各式各样的问题,使用Word的批注来记录面临的问题,写完段落回过头来再修改。
审阅即自己对文档的测试,查找文档是否满足明细的要求,审阅完马上修改。
编写文档过程中重要的一点时,当写完前面的两三个章节时,马上拿给经理(有经验、了解客户的、了解业务的经理,如产品经理)看并让他做出指导。经理手握文档的生杀大权,同时他会告诉你,他需要什么样的文档。如果不这么做,有可能在自己折腾一番之后,重写文档。
5. 测试。
在审阅完之后,提交测试。自己的多次审阅会产生精神疲劳,由于心中非常熟悉文章的思路,我们会快速浏览文章,而忽略很多不足的和错误的地方。我在第一遍之后,测试部测试的结果主要是一些地方写的不全,一些地方出现了错别字。
6. 修改与审阅。
面对测试部提出的Bug,做出修改和完善。当然,这次我做出了更加仔细的检查,以保证无错别字的情况。
7. 测试、完善并提交。
文档工作量的划分
写文档是一项较为繁重的工作。下面有两种写文档的流程:
第一种是传统的办法:
(1)写整个文档。
(2)测试。
(3)修改和完善。
这种方法是脑子中默认的流程。但在实际操作的过程中,会出现一些问题:
(1)工作量难以估计。什么时候才能完成这个文档?经理在问,测试也在问,自己也在问?
(2)其他人无法看到当前的进展。研发、产品、测试经理希望尽早看到成果,哪怕是一部分。每周立会上,整个文档没有写完,研发人员该如何交差?
(3)开发风险大。开发人员不能尽早知道其他人(测试、产品、工程等部门)各项详细的要求;若写完整个文档,被测试部打回来了,全文都得重写;经过多轮迭代,会浪费研发、测试更多时间,可能会延期提交文档。
第二种是划分工作量的流程:
(1)写提纲,并审阅。
(2)根据提纲中的章节划分为多个任务,每个任务走1. 文档编写2.提交测试3. 修改完善的流程。
划分工作量的流程相比传统的流程,有十分明显的优势:
(1)在迭代周期内能输出部分文档。
(2)任务划分明确,能得到清晰的进展。
(3)降低了文档开发的质量和时间上的风险。在文档开发初期,通过经理和测试人员的把关,产出高质量的文档。
(4)切分了章节的耦合度,让文章质量更胜一筹。
不足之处:不能完美地解决工作量的问题。
项目中一个消息推送需求,推送的用户数几百万,用户清单很简单就是一个txt文件,是由hadoop计算出来的。格式大概如下:
uid caller 123456 12345678901 789101 12345678901 ……
现在要做的就是读取文件中的每一个用户然后给他推消息,具体的逻辑可能要复杂点,但今天关心的是如何遍历文件返回用户信息的问题。
之前用C#已经写过类似的代码,大致如下:

/// <summary> /// 读取用户清单列表,返回用户信息。 /// </summary> /// <param name="parameter">用户清单文件路径</param> /// <param name="position">推送断点位置,用户断点推送</param> /// <returns></returns> public IEnumerable<UserInfo> Provide(string parameter, int position) { FileStream fs = new FileStream(parameter, FileMode.Open); StreamReader reader = null; try { reader = new StreamReader(fs); //获取文件结构信息 string[] schema = reader.ReadLine().Trim().Split(' '); for (int i = 0; i < position; i++) { //先空读到断点位置 reader.ReadLine(); } while (!reader.EndOfStream) { UserInfo userInfo = new UserInfo(); userInfo.Fields = new Dictionary<string, string>(); string[] field = reader.ReadLine().Trim().Split(' '); for (int i = 0; i < schema.Length; i++) { userInfo.Fields.Add(schema[i].ToLower(), field[i]); } yield return userInfo; } } finally { reader.Close(); fs.Close(); } }
代码很简单,就是读取清单文件返回用户信息,需要注意的就是标红的地方,那么yield return的作用具体是什么呢。对比下面这个版本的代码:
public IEnumerable<UserInfo> Provide2(string parameter, int position) { List<UserInfo> users = new List<UserInfo>(); FileStream fs = new FileStream(parameter, FileMode.Open); StreamReader reader = null; try { reader = new StreamReader(fs); //获取文件结构信息 string[] schema = reader.ReadLine().Trim().Split(' '); for (int i = 0; i < position; i++) { //先空读到断点位置 reader.ReadLine(); } while (!reader.EndOfStream) { UserInfo userInfo = new UserInfo(); userInfo.Fields = new Dictionary<string, string>(); string[] field = reader.ReadLine().Trim().Split(' '); for (int i = 0; i < schema.Length; i++) { userInfo.Fields.Add(schema[i].ToLower(), field[i]); } users.Add(userInfo); } return users; } finally { reader.Close(); fs.Close(); } }
本质区别是第二个版本一次性返回所有用户的信息,而第一个版本实现了惰性求值(Lazy Evaluation),针对上面的代码简单调试下,你会发现同样是通过foreach进行迭代,第一个版本每次代码运行到yield return userInfo的时候会将控制权交给“迭代”它的地方,而后面的代码会在下次迭代的时候继续运行。
static void Main(string[] args) { string filePath = @"D:\users.txt"; foreach (var user in new FileProvider().Provide(filePath,0)) { Console.WriteLine(user); } }
而第二个版本则需要等所有用户信息全部获取到才能返回。相比之下好处是显而易见的,比如前者占用更小的内存,cpu的使用更稳定:


当然做到这点是需要付出代价(维护状态),真正的好处也并不在此。之前我在博客中对C#的yield retrun有一个简单的总结,但是并没有深入的研究:
- IEnumerable是对IEnumerator的封装,以支持foreach语法糖。
- IEnumerable<T>和IEnumerator<T>分别继承自IEnumerable和IEnumerator以提供强类型支持(即状态机中的“现态”是强类型)。
- yield return是编译器对IEnumerator和IEnumerable实现的语法糖。
- yield return 表现是实现IEnumerator的MoveNext方法,本质是实现一个状态机。
- yield return能暂时将控制权交给外部,我比作“程序上奇点”,让你实现穿越。能达到目的:延迟计算、异步流。
先看第1条,迭代器模式是大部分语言都支持一个设计模式,它是一种行为模式:
行为模式是一种简化对象之间通信的设计模式。
在C#中是IEnumerator接口,Java是Iterator,且目前都有泛型版本提供,语法层面上两个接口基本是一致的。
//C# public interface IEnumerator { object Current { get; } bool MoveNext(); void Reset(); } //Java public interface Iterator<E> { boolean hasNext(); E next(); void remove(); }
在C#2(注意需要区别.net,c#,CLR之间的区别)之前创建一个迭代器,C#和Java的代码量是差不多的。两个语言中除了迭代器接口之外还分别提供了一个IEnumerable和Iterable接口:
//C# public interface IEnumerable<out T> : IEnumerable { IEnumerator<T> GetEnumerator(); } //Java public interface Iterable<T> { Iterator<T> iterator(); }
那么它们的关系是什么呢?语法上看IEnumerable是对IEnumerator的封装,以支持foreach语法糖,但这么封装的目的是什么呢,我们的类直接实现IEnumerator接口不就行了。回答这个问题我们需要理解迭代的本质是什么。我们使用的迭代器的目的是在不知道集合内部状态的情况下去遍历它,调用者每次只想获取一个元素,所以在返回上一个值的时候需要跟踪当前的工作状态:
- 必须具有某个初始状态。
- 每次调用MoveNext的时候,需要维护当前的状态。
- 使用Current属性的时候,返回生成的上一个值。
- 迭代器需要知道何时完成生成值的操作
所以实现迭代器的本质是自己维护一个状态机,我们需要自己维护所有的内部状态,看下面一个简单的实现IEnumerator接口的例子:
public class MyEnumerator : IEnumerator { private object[] values; int position; public MyEnumerator(object[] values) { this.values = values; position = -1; } public object Current { get { if (position == -1 || position == values.Length) { throw new InvalidOperationException(); } return values[position]; } } public bool MoveNext() { if (position != values.Length) { position++; } return position < values.Length; } public void Reset() { position = -1; } }
static void Main(string[] args) { object[] values = new object[] { 1, 2, 3 }; MyEnumerator it = new MyEnumerator(values); while (it.MoveNext()) { Console.WriteLine(it.Current); } }
这个例子很简单,也很容易实现,现在假设同时有两个线程去迭代这个集合,那么使用一个MyEnumerator对象明显是不安全的,这正是IEnumerable存在的原因,它允许多个调用者并行的迭代集合,而各自的状态独立互不影响,同时实现了foreach语法糖。这也是为什么C#中在迭代Dictionary的时候只是只读原因:

增加一个IEnumerable并没有使问题变的很复杂:
public class MyEnumerable : IEnumerable { private object[] values; public MyEnumerable(object[] values) { this.values = values; } public IEnumerator GetEnumerator() { return new MyEnumerator(values); } } static void Main(string[] args) { object[] values = new object[] { 1, 2, 3 }; MyEnumerable ir = new MyEnumerable(values); foreach (var item in ir) { Console.WriteLine(item); } }
言归正传,回到之前的yield return之上,看着很像我们通常写的return,但是yield return后面跟的是一个UserInfo对象,而方法的返回对象其实是一个IEnumerable<UserInfo>对象,其实这里也可以返回一个IEnumerator<UserInfo>,这又是为什么呢?正如我前面说的“yield return是编译器对IEnumerator和IEnumerable实现的语法糖”,其实所有这些又是编译器在幕后做了很多不为人知的“勾当”,不过这一次它做的更多。
看下用yield return实现上面的例子需要几行代码:
static IEnumerable<int> GetInts() { yield return 1; yield return 2; yield return 3; }
多么简洁优雅!!!yield return大大简化了我们创建迭代器的难度。通过IL DASM反汇编看下编译器都干了些什么:
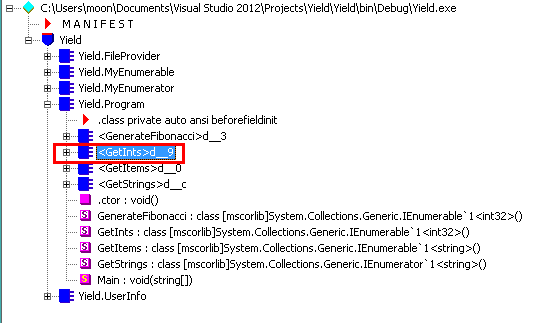
可以看到编译器本质上还是生成一个类的,主要看下MoveNext方法:
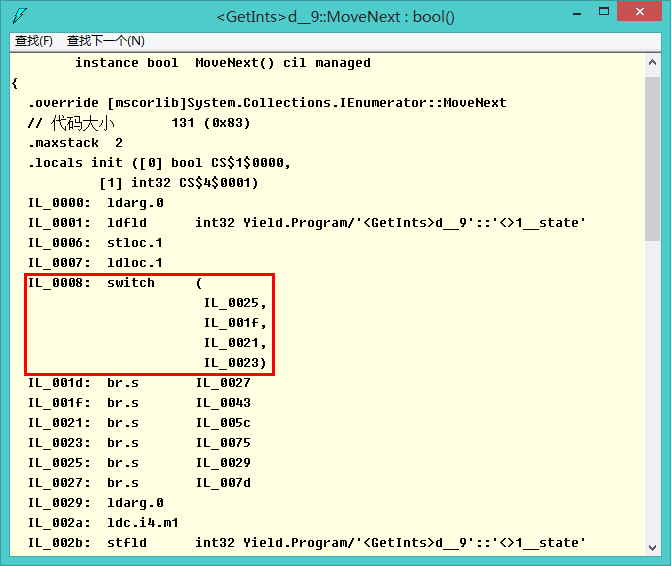
说实话,IL我基本一无所知,但大致可以看出来使用了switch(实现跳转表)和类似C语言中的goto语句(br.s),还好还有强大的reflect,逆向工程一下便可以还原“真相”:
private bool MoveNext() { switch (this.<>1__state) { case 0: this.<>1__state = -1; this.<>2__current = 1; this.<>1__state = 1; return true; case 1: this.<>1__state = -1; this.<>2__current = 2; this.<>1__state = 2; return true; case 2: this.<>1__state = -1; this.<>2__current = 3; this.<>1__state = 3; return true; case 3: this.<>1__state = -1; break; } return false; }
这便是编译器所做的操作,其实就是实现了一个状态机,要看完整的代码朋友们可以自己试下。这是一个再简单不过的例子貌似编译器做的并不多,那么看下文章一开始我写的那个读取文件的例子:
[CompilerGenerated] private sealed class <Provide>d__0 : IEnumerable<UserInfo>, IEnumerable, IEnumerator<UserInfo>, IEnumerator, IDisposable { // Fields private int <>1__state; private UserInfo <>2__current; public string <>3__parameter; public int <>3__position; public FileProvider <>4__this; private int <>l__initialThreadId; public string[] <field>5__5; public FileStream <fs>5__1; public StreamReader <reader>5__2; public string[] <schema>5__3; public UserInfo <userInfo>5__4; public string parameter; public int position; // Methods [DebuggerHidden] public <Provide>d__0(int <>1__state); private void <>m__Finally6(); private bool MoveNext(); [DebuggerHidden] IEnumerator<UserInfo> IEnumerable<UserInfo>.GetEnumerator(); [DebuggerHidden] IEnumerator IEnumerable.GetEnumerator(); [DebuggerHidden] void IEnumerator.Reset(); void IDisposable.Dispose(); // Properties UserInfo IEnumerator<UserInfo>.Current { [DebuggerHidden] get; } object IEnumerator.Current { [DebuggerHidden] get; } } Expand Methods
private bool MoveNext() { bool CS$1$0000; try { int i; switch (this.<>1__state) { case 0: this.<>1__state = -1; this.<fs>5__1 = new FileStream(this.parameter, FileMode.Open); this.<reader>5__2 = null; this.<>1__state = 1; this.<reader>5__2 = new StreamReader(this.<fs>5__1); this.<schema>5__3 = this.<reader>5__2.ReadLine().Trim().Split(new char[] { ' ' }); i = 0; goto Label_0095; case 2: goto Label_0138; default: goto Label_0155; } Label_0085: this.<reader>5__2.ReadLine(); i++; Label_0095: if (i < this.position) { goto Label_0085; } while (!this.<reader>5__2.EndOfStream) { this.<userInfo>5__4 = new UserInfo(); this.<userInfo>5__4.Fields = new Dictionary<string, string>(); this.<field>5__5 = this.<reader>5__2.ReadLine().Trim().Split(new char[] { ' ' }); for (int i = 0; i < this.<schema>5__3.Length; i++) { this.<userInfo>5__4.Fields.Add(this.<schema>5__3[i].ToLower(), this.<field>5__5[i]); } this.<>2__current = this.<userInfo>5__4; this.<>1__state = 2; return true; Label_0138: this.<>1__state = 1; } this.<>m__Finally6(); Label_0155: CS$1$0000 = false; } fault { this.System.IDisposable.Dispose(); } return CS$1$0000; }
编译器以嵌套类型的形式创建了一个状态机,用来正确的记录我们在代码块中所处的位置和局部变量(包括参数)在该处的值,从上面的代码中我们看到了goto这样的语句,确实这在C#中是合法的但是平时我们基本不会用到,而且这也是不被推荐的。
一句yield return看似简单,但其实编译做了很多,而且尽善尽美,第一个例子中标红的还有一处:
…… finally { reader.Close(); fs.Close(); } ……
使用yield return这点倒和return类似,就是finally块在迭代结束后一定会执行,即使迭代是中途退出或发生异常,或者使用了yield break(这跟我们平常使用的return很像):
static IEnumerable<int> GetInts() { try { yield return 1; yield return 2; yield return 3; } finally { Console.WriteLine("do something in finally!"); } } //main foreach (var item in GetInts()) { Console.WriteLine(item); if (item==2) { return; } }
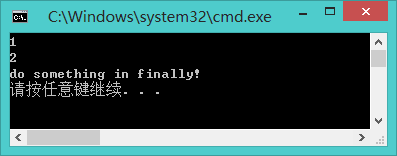
这是因为foreach保证在它包含的代码块运行结束后会执行里面所有finally块的代码。但如果我们像下面这样迭代集合话就不能保证finally块一定能执行了:
IEnumerator it = GetInts().GetEnumerator();
it.MoveNext();
Console.WriteLine(it.Current);
it.MoveNext();
Console.WriteLine(it.Current);
it.MoveNext();
Console.WriteLine(it.Current);
这也提醒我们在迭代集合的时候一定要用foreach,确保资源能够得到释放。 还有一点需要注意的就是yield return不能用于try...catch...块中。原因可能是编译在处理catch和yield return之间存在“冲突”,有知道的朋友可以告诉我一下,感激不尽。
好了,到目前为止yield return貌似只是一个普通的语法糖而已,但其实简化迭代器只是它一个表面的作用而已,它真正的妙处正如我前面总结的:
- yield return能暂时将控制权交给外部,我比作“程序上奇点”,让你实现穿越。能达到目的:延迟计算、异步流。
其实本文第一个代码片段已经能说明这点了,但是体现的作用只是延迟计算,yield return还有一个作用就是它能让我们写出非常优雅的异步编程代码,以前在C#中写异步流,全篇充斥这各种BeginXXX,EndXXX,虽然能达到目的但是整个流程支离破碎。这里举《C# In Depth》中的一个例子,讲的是微软并发和协调运行库CCR。
假如我们正在编写一个需要处理很多请求的服务器。作为处理这些请求的一部分,我们首先调用一个Web服务来获取身份验证令牌,接着使用这个令牌从两个独立的数据源获取数据(可以认为一个是数据库,另外一个是Web服务)。然后我们要处理这些数据,并返回结果。每一个提取数据的阶段要话费一点时间,比如1秒左右。我们可选择两种常见选项仅有同步处理和异步处理。
这个例子很具代表性,不禁让我想到了之前工作中的一个场景。我们先来看下同步版本的伪代码:
HoldingsValue ComputeTotalStockValue(string user, string password) { Token token = AuthService.Check(user, password); Holdings stocks = DbService.GetStockHoldings(token); StockRates rates = StockService.GetRates(token); return ProcessStocks(stocks, rates); }
同步很容易理解,但问题也很明确,如果每个请求要话费1秒钟,整个操作将话费3秒钟,并在运行时占用整个线程。在来看异步版本的:
void StartComputingTotalStockValue(string user, string password) { AuthService.BeginCheck(user, password, AfterAuthCheck, null); } void AfterAuthCheck(IAsyncResult result) { Token token = AuthService.EndCheck(result); IAsyncResult holdingsAsync = DbService.BeginGetStockHoldings (token, null, null); StockService.BeginGetRates (token, AfterGetRates, holdingsAsync); } void AfterGetRates(IAsyncResult result) { IAsyncResult holdingsAsync = (IAsyncResult)result.AsyncState; StockRates rates = StockService.EndGetRates(result); Holdings holdings = DbService.EndGetStockHoldings (holdingsAsync); OnRequestComplete(ProcessStocks(stocks, rates)); }
我想不需要做太多解释,但是它确实比较难理解,最起码对于初学者来说是这样的,而且更重要的一点是它是基于多线程的。最后来看下使用CCR的yield return版本:
IEnumerator<ITask> ComputeTotalStockValue(string user, string pass) { Token token = null; yield return Ccr.ReceiveTask( AuthService.CcrCheck(user, pass) delegate(Token t){ token = t; } ); Holdings stocks = null; StockRates rates = null; yield return Ccr.MultipleReceiveTask( DbService.CcrGetStockHoldings(token), StockService.CcrGetRates(token), delegate(Stocks s, StockRates sr) { stocks = s; rates = sr; } ); OnRequestComplete(ProcessStocks(stocks, rates)); }
在了解CCR之间,这个版本可能更难理解,但是这是伪代码我们只需要理解它的思路就可以了。这个版本可以说是综合了同步和异步版本的优点,让程序员可以按照以往的思维顺序的写代码同时实现了异步流。
这里还有一个重点是,CCR在等待的时候并没有使用专用线程。其实一开始了解yield return的时候,我以为它是通过多线程实现,其实它使用的是一种更小粒度的调度单位:协程。
协程和线程的区别是:协程避免了无意义的调度,由此可以提高性能,但也因此,程序员必须自己承担调度的责任,同时,协程也失去了标准线程使用多CPU的能力。
关于协程网上有很多资料,各种语言也有支持,可以说C#对协程的支持是通过yield return来体现的,而且非常优雅。其他语言中貌似也有类似的关键字,好像javascript中也有。
好吧说了这么多回到文章的标题上来,因为某些原因,现在要用Java实现文章一开头那个需求。刚刚接触Java,菜鸟一枚,本想应该也会有类似C#中yield return的语法,但是却碰壁了。找来找去就发现有一个Thread.yield(),看了api貌似并不是我想要的。好不容易在stackoverflow上找到一篇帖子:Yield Return In Java。里面提到了一个第三方库实现了类似C#中的yield return语法,下载地址。
激动万分啊,可惜使用后发现貌似有点问题。这个jar包里提供一个Yielder类,按照它Wiki中的示例,只要继承这个类实现一个yieldNextCore方法就可以了,Yielder类内部有一个yieldReturn()和yieldBreak()方法,貌似就是对应C#中的yield return和yield break,于是我写下了下面的代码:
public static void main(String[] args) { Iterable<Integer> itr = new Yielder<Integer>() { @Override protected void yieldNextCore() { yieldReturn(1); yieldReturn(2); yieldReturn(3); } }; Iterator<Integer> it = itr.iterator(); while (it.hasNext()) { Object rdsEntity = it.next(); System.out.println(rdsEntity); } }
但是运行结果确是一直不停的输出3,不知道我实现的有问题(Wiki里说明太少)还是因为这个库以来具体的操作系统平台,我在CentOS和Ubuntu1上都试了,结果一样。不知道有没有哪位朋友知道这个jar包,很想知道原因啊。
在网上搜了很多,如我所料Java对协程肯定是支持的,只不过没有C#中yield return这样简洁的语法糖而已,我一开始的那个问题必然不是问题,只不过可能我是被C#宠坏了,才会发出“可惜Java中没有yield return”这样的感慨,还是好好学习,天天向上吧。
框架篇
最近写了一系列的关于JavaScript文章,时不时就会蹦出个需求,需要写个特定的小函数,或者是为了解决浏览器兼容性问题,或者是简化一些操作,前面写的几篇博客实际上已经写出了一些常用的函数,既然自己希望在两年内变成个技术小牛,提前准备自己的库函数吧。
框架选择
是个库函数都会有自己的框架,我常用的有两种形式,一种可以归结为静态方法型,大概定义一个立即执行函数,对外提供一个对象引用,自己定义的库函数都作为这个对象的静态函数供外部使用访问;类外一种就是一个类jQuery的集成解决方案,相信介绍我就不必多说了。
这两种方式各有利弊吧,经过数次纠结还是决定使用静态方法,好处有几个
1. 代码可读性还稍微高那么一小点儿,因为相对于类jQuery这样的写法还是更好理解一些,方便别人读代码
2. 现在大部分网站包括我们公司自己的网站中大部分页面已经引用了jQuery,在写一个类似的实际意义不大,而写一个静态方法的可以在没有应用jQuery的页面上阻隔简单的拓展
3. 从实用性上考虑,实际上要不是因为有些比较复杂的选择器浏览器兼容性问题,我几乎是不使用jQuery的,而平时自己写一些demo页面,结构很简单,根本用不到复杂的选择器,相反最常用的就是绑定方法等这些小功能,写个静态方法类的平时用起来更方便
选定了框架后看看标题,有些难为情,因为下面这两句就是框架的代码,这么简单都不好意思称之为框架
(function (window) { //内部函数 //JavaScript原生对象拓展 var ssLib={ /*库函数*/ //1.Event //2.DOM 拓展、CSS //3.Ajax //4.动画 //5.简单插件 }; window.ssLib = ssLib; //对外提供接口 })(window);
组织结构及内容
在读jQuery源码的时候我发现很难读,里面各种方法穿插,经常读到某句的时候,发现其调用了一个内部函数,然后再去找这个内部函数在哪里,好麻烦,所以在自己写的库函数里面干脆把公用的内部函数写到最前面,方便查找。
看过一些书讲过jQuery的一个好处就是不会与未来的API冲突,如果对JavaScript原生对象进行拓展很大可能会与未来API冲突,除非把名字起的非常奇怪,这里就尽量做一下判断原生的有没有,并且随时关注人家未来API是什么样子,尽量把作用及返回结果保持一致,使IE低版本用起来也不会感觉很奇怪。
我平时除了选择器用的最频繁的大概就是Event处理了(最近在做插件),所以把它放到最前面,DOM拓展、CSS部分希望写一些对class的处理、对DOM元素移动、添加、删除等处理,Ajax及动画就是那么回事儿了,简单插件部分希望添加像Dialog、Tab、Tree这样的插件吧
最后
这只是今天早上拍拍脑袋的初步计划与设想,有很多缺陷,希望各位多给意见,如果不吝分享自己的就更感激不尽了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号