

上一篇为求振聋发聩的效果,有些口号主义,现在开始实战,归于实用主义。
使用情景
开始之前,我们先设定这样一个情景:
1.一百万注册用户的页游或者手游,这是不温不火的一个状态,刚好是数据量不上不下的一个情况。也刚好是传统MySql数据库性能开始吃紧的时候。
2.数据库就用一台很普通的服务器,只有一台。读写分离、水平扩展、内存缓存都不谈。一百万注册用户如果贡献度和活跃度都不高,恐怕公司的日子还不是那么宽裕,能够在数据库上的投资也有限。
以此情景为例,设每个用户都拥有100个道具,用户随时会获得或失去道具。
我们就来看看这一亿的道具怎么搞。
道具一般要使用原型、实例的设计方法,这个不属于数据库的范畴。
道具类型001 是屠龙刀,屠龙刀价格1500,基础攻击150,这些,我们把它们称为道具原型,保存在原型数据文件中。
这个原型数据文件,无论是存在何种数据库或者本地文件中,对服务器来说都不是问题,也不干扰数据库设计,所以我们不去讨论他。
关系数据库设计方法
典型的关系数据库设计方法:
用户表:字段 xxx userid xxx ,记录数量100万
xxx是其他字段,userid标示用户
用户道具表:字段 xxx userid itemtype xxx ,记录数量一亿
xxx是其他字段,userid 标示
一个亿的记录数是不是看起来有点头疼,mysql这个时候就要想各种办法了。
MongoDB设计方法
但我们用mongoDB来实现这个需求,直接就没有问题
首先第一个集合:users集合,用UserName 作为_id ,记录数100万
然后道具的组织,我们有两种选择
1.在users集合的值中建立Items对象,用Bson数组保存道具(Mongo官方称为Bson,和Json一模一样的存储方法)
方法一,没有额外的记录数
2.新建userItems集合,同样用UserName作为_id 每个UserItems集合的值中建立一个Item对象,使用一个Bson数组来保存道具
方法二,多了一个集合和100万记录数
我们的道具数据看起来像下面这样:
{_id:xxx,Items:[
{Itemtype:xxx,ItemPower:xxx},
...
...
...
]}
测试方法
测试方法如下:测试客户端随机检查一个用户的道具数量,小于100加一个道具,大于100 删除一个道具。
连续100万次,采用10个线程并发。
如果用关系数据库设计方法+mysql来实现,这是一个很压力很大的数据处理需求。
可是用文档数据库设计方法+MongoDB来实现,这个测试根本算不上有压力。
注意事项
即使我们用了一个如此胜之不武的设计方式,你依然有可能还是能把他写的很慢。
因为MongoDB在接口设计上并没有很好的引导和约束,如果你不注意,你还是能把他用的非常慢。
第一个问题:Key-Value数据库可以有好多的Key,没错,但对MongoDB来说,大错特错
MongoDB的索引代价很大,大到什么程度:
1.巨大的内存占用,100万条索引约占50M内存,如果这个设计中,你一个道具一条记录,5G内存将用于索引。
我们的屌丝情景不可能给你这样的服务器,
2.巨大的性能损失,作为一个数据库,所有的东西终将被写入硬盘,没有关系数据库那样的表结构,MongoDB的索引写入性能看起来很差,如果记录数据较小的时候,你可以观测到这样震撼的景象,加一个索引,性能变成了1/2,加两个索引,性能变成了1/3。
只有当第二个索引的查询不可避免,才值得增加额外索引。因为没索引的数据,查询性能是加几个零的慢,比加索引更惨。
我们既然选择了Key-Value数据库,应尽量避免需要多个索引的情况。
所有的索引只能存在于内存中,而读取记录时,也需要将Bson在内存中处理,内存还承担着更重要的作用:读取缓存。
本来就不充裕的内存,应该严格控制我们的记录条数,能够用Bson存储的,尽量用之。
那么我们之前在MongoDB的设计中怎么还考虑第二种设计方法呢?独立一个userItems 集合,不是又多出100万条记录了吗?
这基于另两个考虑:a.Bson的处理是要反复硬盘和内存交换的,如果每条记录更小,则IO压力更小。内存和硬盘对服务器来说都是稀缺资源,至于多大的数据拆分到另一个集合中更划算,这需要根据业务情况,服务器内存、硬盘情况来测试出一个合适大小,我们暂时使用1024这个数值,单用户的道具表肯定是会突破1024字节的,所以我们要考虑将他独立到一个集合中
b.可以不部署分片集群,将另一个集合挪到另一个服务器上去。只要服务器可以轻松承载100万用户,200万还会远么?在有钱部署分片集群以前,考虑第二组服务器更现实一些。
第二个问题:FindOne({_id:xxx})就快么?
毋庸置疑,FindOne({_id:xxx})就是最直接的用Key取Value。
也的确,用Key取Value 就是我们能用的唯一访问Value的方式,其他就不叫Key-Value数据库了。
但是,由于我们要控制Key的数量,单个Value就会比较大。
不要被FindOne({_id:xxx}).Items[3].ItemType这优雅的代码欺骗,这是非常慢的,他几乎谋杀你所有的流量。
无论后面是什么 FindOne({_id:xxx})总是返回给你完整的Value,我们的100条道具,少说也有6~8K.
这样的查询流量已经很大了,如果你采用MongoDB方案一设计,你的单个Value是包含一个用户的所有数据的,他会更大。
如果查询客户端和数据库服务器不在同一个机房,流量将成为一个很大的瓶颈。
我们应该使用的查询函数是FindOne({_id:xxx},filter),filter里面就是设置返回的过滤条件,这会在发送给你以前就过滤掉
比如FindOne({_id:xxx},{Items:{"$slice":[3,1]}}),这和上面那条优雅的代码是完成同样功能,但是他消耗很少的流量
第三个问题:精细的使用Update
这和问题二相对的,不要暴力的FindOne,也尽量不要暴力的Update一整个节点。虽然MangoDB的性能挺暴力的,IO性能极限约等于MongoDB性能,暴力的Update就会在占用流量的同时迎接IO的性能极限。
除了创建节点时的Insert或者Save之外,所有的Update都应该使用修改器精细修改.
比如Update({_id:xxx},{$set:{"Items.3.Item.Health":38}});//修改第三把武器的健康值
至于一次修改和批量修改,MongoDB默认100ms flush一次(2.x),只要两次修改比较贴近,被一起保存的可能性很高。
但是合并了肯定比不合并强,合并的修改肯定是一起保存,这个也要依赖于是用的开发方式,如果使用php做数据客户端,缓存起来多次操作合并了一起提交,实现起来就比较复杂。
注意以上三点,一百万注册用户并不算很多,4G内存,200G硬盘空间的MongoDB服务器即可轻松应对。性能瓶颈是硬盘IO,可以很容易的使用Raid和固态硬盘提升几倍的吞吐量。不使用大量的Js计算,CPU不会成为问题,不要让索引膨胀,内存不会成为问题。你根本用不着志强的一堆核心和海量的内存,更多的内存可以让缓存的效果更好一些,可是比读写分离还是差远了。如果是高并发时查询性能不足,就要采用读写分离的部署方式。当IO再次成为瓶颈时,就只能采用集群部署MongoDB启用分片功能,或者自行进行分集合与key散列的工作。
mySagasoft.MisCore 需求分析说明书
作者:sagahu@163.com,2013-05-07,太原
1. 文档概要
本文分析、总结企业管理类软件在权限管理方面的一些共性需求,包括功能操作权限、部门权限、字段权限三种。
本文归纳的需求模型是针对数据共享式管理软件的,即传统MIS型软件;不涉及工作流/步骤类软件。
本文面向研讨审议,所以仅简略、概要,但是明确地定义与说明需求模型,详细文字忽略。
2. 术语定义
2.1. 权限管理三个环节
权限管理包括三个环节:(1)登录时的身份认证;(2)使用软件时的界面控制;(3)提交操作请求时的许可验证。
2.1.1. 登录时身份认证
最常见的身份认证就是,操作员输入用户帐号与口令数据,进行登录,系统后台验证帐号/口令对,从而确认操作员身份。其实这是权限管理工作的开始。
传统桌面应用程序,一般会在登录成功后把用户帐号对象缓存在进程空间里;而Web应用程序常常会把用户帐号对象缓存在个人会话里。
最简单的身份缓存的数据内容就是帐号名/口令,常常再增加帐号ID,也有人再增加一些权限与菜单控制数据。高级的有缓存登录身份认证返回的密钥或者passport。
2.1.2. 使用软件时的界面控制
就是在软件使用时,根据当前操作员的许可权限来控制菜单、页面按钮,甚至控制数据行、字段,等等。
2.1.3. 提交操作请求时的许可验证
有了前面的软件界面控制,还不是完善的权限管理。
例如,你向第三方子系统开发者提供中间件功能接口,对方对你的调用是不走你的界面的,人家只是调用你的服务接口。当对方提交操作请求(带着数据)时,你会认为他在半个小时前通过了身份认证,就不需要再验证其操作请求被许可吗?
还有一种情况,就是软件界面控制在某些情况下会被用户的某些特殊数据绕过。虽然这种情况会存在,但是属于少数情况。所以在自己开发自己的应用界面层时,可以偷懒不作提交请求时的验证。
总之,完善的权限管理,需要包含这三个环节,而第三个环节却是容易被初学者忽视。
2.2. RBAC相关
2.2.1. 角色(Role)
Role是RBAC模型中的概念,用来解耦权限许可与用户帐号的直接联系。
角色是权限许可的集合。RBAC模型通过给角色分配权限许可,再把角色赋予用户帐号,从而使得用户帐号间接得到权限许可。这样的解耦使得用户帐号可以灵活地跨职能部门来调动,只需重新赋予角色即可。尽管不少实际应用中允许给帐号直接分配权限许可,但是决不是推荐标准。
在RBAC2中,需要考虑不同的业务资源需要相应的功能权限许可,结合实际的资源范围/职能部门划分,常常需要把角色设计到相应职能部门下面。本方案就为角色设计了隶属部门。
这样,“角色”作为软件系统权限管理范畴的一个概念,一方面负责分类组织相关权限许可;另一方面又负责分门别类相关用户帐号。
2.2.2. 角色(Role)与职务(Job)的关系
岗位、职务、职位、职务级别、职称等级这些概念都是实际业务中来的,都会在企业组织中对应一定的特权与职责,就可能与软件系统的权限管理发生某种对应关系,因而会归入软件需求。
虽然它们并不好区分,但是可以分为两大类:“职”与“级”。例如说“处长”,首先会让人明白是初级干部,应该享受处级干部的待遇,从而在软件系统中对应了处级干部的一些功能许可;然后人们会问是哪个处室部门的处长,当归位到财务处的时候,在软件系统中又需要对应他一些功能许可与业务范围。这里把岗位、职务、职位统称为职务(Job),把职务级别称为等级(Joblevel)。总结二者的区别如下:职务(Job)必然有自己的隶属部门,脱离开隶属部门则只剩下等级(Joblevel)了,有等级不一定有职务。例如“处长”表示处级干部的级别,而“财务处长”表示隶属财务处的职务;并且任命一个人为财务处长并不一定就必须同时把他的职称等级提升为“处长”级别。所以软件系统把它们设计为2个不同的对象。
职务(Job)是实际业务中既包含权限又具有其它业务意义的概念,角色(Role)是软件权限模型中管理权限许可的概念。所以,如果软件系统仅仅需要实现职务(Job)的权限许可,那么用角色(Role)映射前者就可以了,实践中不少系统确实就是这么玩的。否则,再单独实现职务(Job)特有的业务意义就可以了。
2.2.3. 用户帐号(User)
用户帐号(User)代表企业雇员(Employee),前者并不是后者,也不能完全代替后者,但是在实现很多软件功能时代表后者,具有很大的方便性。
例如人力资源管理业务中,登录系统时仅仅需要用户帐号包含的数据,不需要雇员包含的其它很多信息的。这就表明二者不能互相代替。就算有些实践中帐号用雇员姓名,其实也是把雇员默认成帐号了。
不少应用中不需要雇员的太多个人信息,仅仅必须登录数据及联系方式等少量个人信息,就可以省略雇员而只使用用户帐号了。本方案也仅限于用户帐号,以后需要雇员的时候可以再扩展。
2.2.4. 用户组(User group)
用户组的基本功能是要分门别类的管理用户帐号。
尽管可以设计每个用户帐号都有自己唯一隶属的组织结构/部门,但是当需要查看同一类功能相似的用户帐号时,按隶属部门来操作会感到不方便,这就需要使用“用户组”这个概念了。例如,在省、市、县三级的相应保化部门都有承担保化干事这类角色的用户帐号,就可以使用“保化干事组”把相关帐号组织到一起,而得到便利。
所以用户组基本功能设计为分类组织用户帐号,这一点在99%的同类项目中都是没有疑义的。但是肯定有人会发现,角色也是分类组织用户帐号的。如果二者功能完全相同,仅仅概念名称不同,那么就可以合并为一。所以一些简单的系统设计中只有角色,没有用户组。
这里参考一些应用实践,为用户组定义一些其它的功能:
(1)用户组不隶属于某个部门,仅仅组织管理某一类别的用户帐号;这点与角色不同。
(2)可以向用户组分配菜单权限,从而使用户间接得到个性化菜单,这点与角色类似,但是却可以解放向不同部门下类似角色分配菜单权限的麻烦。
(3)可以向用户组分配权限,包括功能权限,甚至字段权限,以及将来可能扩展的其它权限;这一点还是与角色相同。
(4)可以向用户组分配角色,从而使用户间接得到权限。又与角色不同。
(5)最后,当把用户帐号加进用户组时,就间接得到了用户组的菜单及其拥有角色的所有权限并集。
无疑,引进用户组增加了实现的复杂度,使用者也不好同时理解角色与用户组,但是确有其方便性。
2.2.5. 操作权限与资源权限
资源泛指软件系统中一切对象,包括业务实体、菜单/按钮/界面、报表、票据、流程/步骤,甚至数据表、视图、字段等等。
在最初的RBAC中,不考虑对软件系统中各种对象细分范围,只考虑允许/禁止何种操作,就是所谓的“操作权限”。但是当实际业务中需求特定业务对象才能进行某种操作时,就引出了“资源权限”的概念。
资源权限,就是特定资源才许可/禁止的某项操作。例如:批准报销单:(1)首先是保险单;(2)选定目标保险单;(3)可以批准它(它们)。就是说:资源权限包含2个要素:①资源种类、范围或个体、②特有的操作。二者总是绑定在一起的,所以分配时需要一起操作。这样一来,前面的“操作权限”,就可以看作隐式的(不需要特别指出种类、范围或个体)资源权限。
系统中的资源多种多样,因而资源权限也有多种。如菜单权限实现对匹配当前用户帐号的菜单控制。也有某些应用,特别强调从业务数据的角度来分配操作许可,可称为数据权限。
2.2.6. 菜单权限
当用户登录软件系统后,系统应该根据用户具有的操作权限与资源权限,自动为其生成相应的菜单与界面控制,可称为菜单权限或者界面权限。
常见界面权限实现有2种形式:(1)可见/不可见;(2)可用/不可用。
2.2.7. 部门权限
在企业管理软件实践中,最常见的情况可能就是:各项业务对象/数据隶属于各自业务部门,角色/操作员因部门不同而许可操作的数据范围不同。也就是说,企业组织结构,特别是部门,现实地划分了数据范围。这种权限需求可以看成数据权限范畴的横向切割。
所以,这种权限需求的本质是:首先以部门划分数据范围,然后追求将数据范围及操作许可灵活分配,可以称为“部门权限”。
2.2.8. 字段权限
在一些实际的应用中,对某些表格、单据,对不同的角色或者部门,要求可见性/可修改许可各异,可称为“字段权限”。这可以看成数据权限范畴的纵向切割。
2.3. 组织结构
2.3.1. 组织结构树
当前很多行业企业的组织结构是省、市、县几个大级别的多层次、上下级部门关系,或者层次更多一些。有很多的业务应用是全部,或者部分依赖于这棵“树”,其在应用系统中具有关键性的作用。
部门是组织结构树中的基本节点;部门有物理的,也可以为细分业务的虚拟部门。而职务/岗位可以看成一种组织结构节点,而员工是另一种组织结构节点。在软件系统权限管理方面,后二种业务概念常常通过角色与用户帐号来对应。
2.3.2. 对口业务上下级
结合多个行业应用分析,会发现还有这样一种情况。例如:省局保化处在保化业务上直接指导下属各市保化科工作,间接指导各市下辖各县保化办工作。像这种组织结构与上下级关系,仅仅是客户企业组织机构中的一部分,或者看成一个“子树”,却会跨越省、市、县三个大的层次而不局限于 “整个树”基本上下级关系,就可以称为对口业务。
对口有着自己独特的一系列部门及上下级关系,这就是所谓的对口业务上下级关系。开发应用系统,常常需要上级能找到对口下级,下级能找到对口上级。
3. 用例分析
3.1. 产品整体结构需求

3.2. 需求分解

4. 领域模型
4.1. 权限管理核心对象总图

5. 动态流程分析
5.1. 登录系统,自动生成菜单
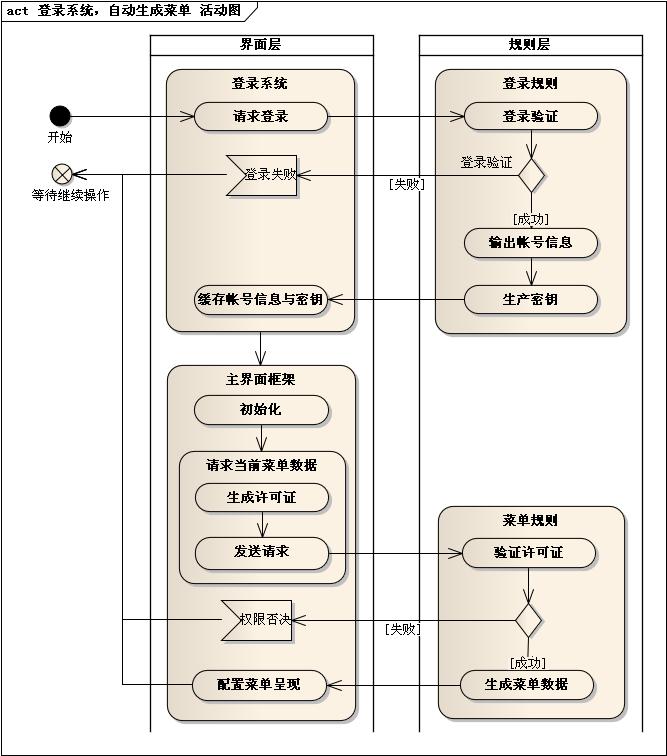
5.2. 登录过程与身份认证
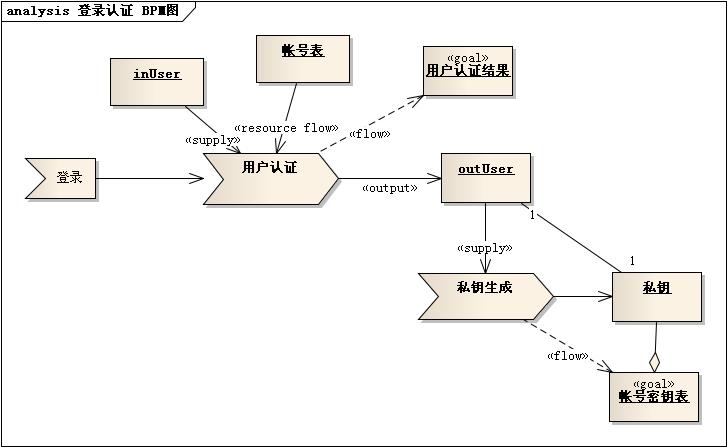
5.3. 请求操作与许可验证


 浙公网安备 33010602011771号
浙公网安备 33010602011771号