
容器
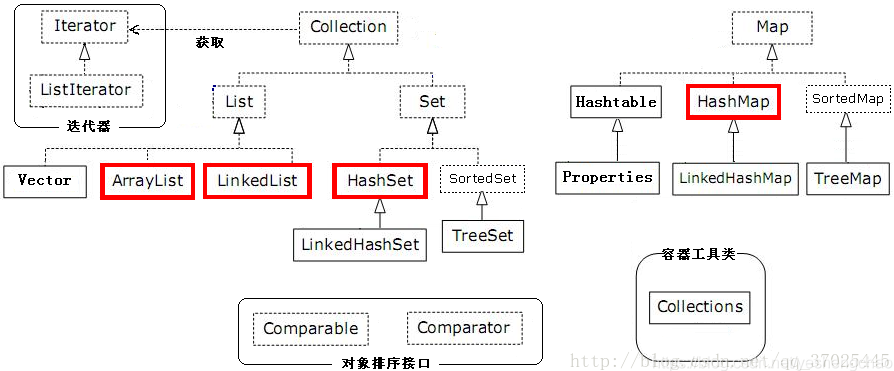
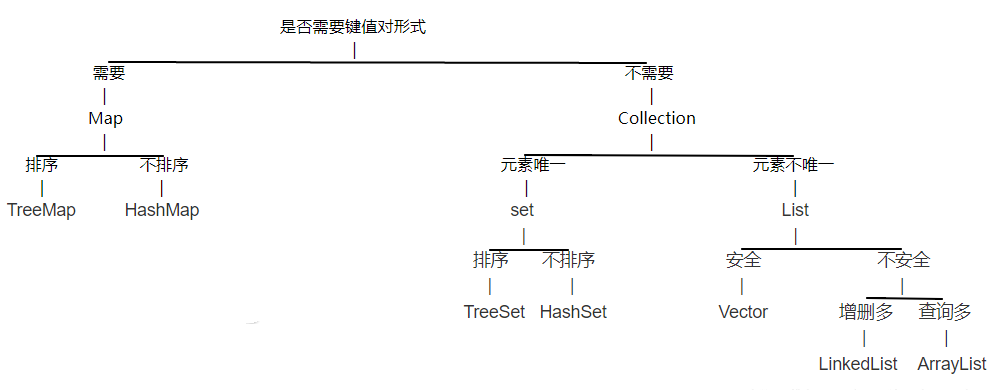
1.connection
1.1 List

(1)ArrayList
- ArrayList是采用数组实现的列表,因此它支持随机访问,
不适合频繁删除和插入操作。对于需要经常进行查询的数据建议采用此结构。 - ArrayList与java数组的一个大的区别是ArrayList能够自动扩容
- ArrayList不支持同步
(2)LinkedList
- LinkedList采用双向链表实现的列表,因此可以被用作队列、堆栈、双端队列;顺序访问高效,随机访问性能较差、适用于需要经常添加和删除的数据。
- LinkedList不支持同步
1.2 Set

1.2.1 HashSet
HashSet简单的理解就是HashSet对象中不能存储相同的数据,存储数据时是无序的。但是HashSet存储元素的顺序并不是按照存入时的顺序(和List显然不同) 是按照哈希值来存的所以取数据也是按照哈希值取得。
底层数据结构是哈希表。线程安全,效率低
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
1 package SetTest; 2 3 import java.util.HashSet; 4 import java.util.Set; 5 6 public class HashSetTest { 7 8 /* 9 * 特点: 10 * 1.无序:没有顺序,存的顺序和读取的顺序不一定相同。 11 * 2.不可重复:若添加多个相同的数据,则只保留1个
3.放到HashSet集合中的元素实际上是放到HashMap集合的key部分 12 */ 13 14 15 public static void main(String[] args){ 16 Set<String> s=new HashSet<String>(); 17 18 s.add("a"); 19 s.add("b"); 20 s.add("1"); 21 s.add("2"); 22 s.add("a"); 23 24 for(String str:s){ 25 System.out.println(str); 26 } 27 28 } 29 30 }
运行结果:

1.2.2 TreeSet
底层数据结构是红黑树。(是一种自平衡的二叉树)
根据比较的返回值是否是0来决定保证元素唯一性
两种排序方式
(1)自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
(2)比较器排序(集合具备比较性)
让集合接收一个Comparator的实现类对象
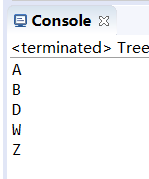
1 package SetTest; 2 3 import java.util.Set; 4 import java.util.TreeSet; 5 6 public class TreeSetTest { 7 8 9 /* 10 * 特点:无序(存的数据和取的数据的顺序不一定相同)不可重复,但是存储的元素可以自动按照大小顺序排序,称为可排序集合。 11 */ 12 13 14 public static void main(String[] args){ 15 Set <String>strs=new TreeSet<String>(); 16 strs.add("A"); 17 strs.add("Z"); 18 strs.add("D"); 19 strs.add("W"); 20 strs.add("B"); 21 strs.add("Z"); 22 for(String s:strs){ 23 System.out.println(s); 24 } 25 26 27 28 29 30 } 31 32 }
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号