python 类的继承、多继承与派生
python 类的继承、多继承与派生
继承的概念与本质
继承是指类与类之间名称空间的传递关系,如果一个类A可以全数访问另一个类B的所有名称,或者说类A拿到了类B所有属性的访问权限,那么就称类A继承了类B。
- 被继承的类被称之为父类、基类、超类
- 继承的类被称为子类、派生类
继承的方式如下:
class B:
name = 'from B'
money = 666666
@staticmethod
def show_off():
print('我很有钱')
class A(B): # 定义类时跟随括号,括号中放入想要继承的类
pass # A类是空的,什么都没有
print(A.money) # 666666
A.show_off() # 我很有钱
上述代码中,子类A的类体中没有任何的数据和功能(我们可以通过A.__dict__方式查看验证,忽略类本身一些隐藏的属性,则确实是没有任何属性)。但是我们仍然可以通过句点的方式访问到一些属性,而且这些属性是父类B中的。

所以,我们可以通过子类访问到它继承的父类的所有属性。
我们可以让A继承B,也可以让C继承B,即一个类可以被多个类继承,操作也很简单,只要在一个类定义时后面跟父类就行了。
class B:
name = 'from B'
class A(B): pass
class C(B): pass
继承的本质
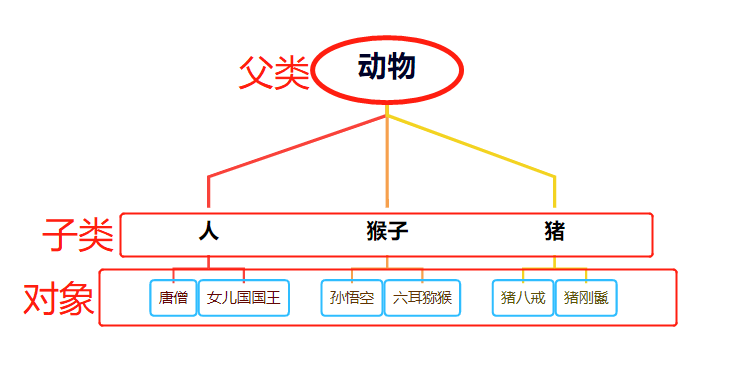
多个类继承一个类,实际上是给类分类的一个过程:
-
抽象:我们通过将对象的共同点提炼出来,构造出了类,对象可以访问类的共有属性
同样的,通过将子类的共同点提炼出来,构造出了父类,子类可以访问父类的共有属性
-
继承:共同的属性存放于类中,子类不必再反复添加重复的属性,只需要继承父类的就好了
所以继承的本质就是抽象多个相似的类的属性,减少代码的重复。
多继承
而且在python中,支持多继承,即一个儿子可以有多个爹(bushi
即一个子类可以继承多个父类。
class Ma:
money = 666666
@staticmethod
def show_money():
print('我很有钱')
class Wang:
house = 888888
@staticmethod
def show_house():
print('我很有房')
class Be:
car = 999999
@staticmethod
def show_car():
print('我很有车')
class A(Ma, Wang, Be): # 继承多个类
pass # A类是空的,什么都没有
a_obj = A() # A产生的对象
print(a_obj.money, a_obj.house, a_obj.car)
我们通过上述代码,可以通过A类甚至于A类产生的对象拿到三个父类的所有属性。
至此,可以总结:
- 子类可以通过继承访问到父类的所有属性
- 多个子类可以继承同一个父类
- 子类和子类产生的对象都可以通过句点的方式拿到父类
- python中支持多继承
名字的查找顺序
类体和对象是有名称空间的,我们通过类和对象的名称空间可以拿到其中的所有属性。
而对象也可以访问创造它的类的名称空间,那么在类与对象查找属性时,会以什么顺序查找名字呢。
不继承时的查找顺序
class C1:
name = 'leethon'
def func(self):
print('from func')
obj = C1()
# print(C1.name) # 类肯定找的自己的
obj.name = '旅行者' # 由于对象原本没有name属性 该语法会在对象名称空间中创建一个新的'键值对'
print(obj.__dict__)
print(obj.name) # 旅行者
print(C1.name) # leethon
-
先从自己的名称空间中查找
-
自己没有再去产生该对象的类中查找
-
如果类中也没有,那么直接报错

单继承时的查找顺序
class F1:
name = 'jason'
class S1(F1):
name = 'kevin'
obj = S1()
obj.name = 'oscar'
print(obj.name)
'''
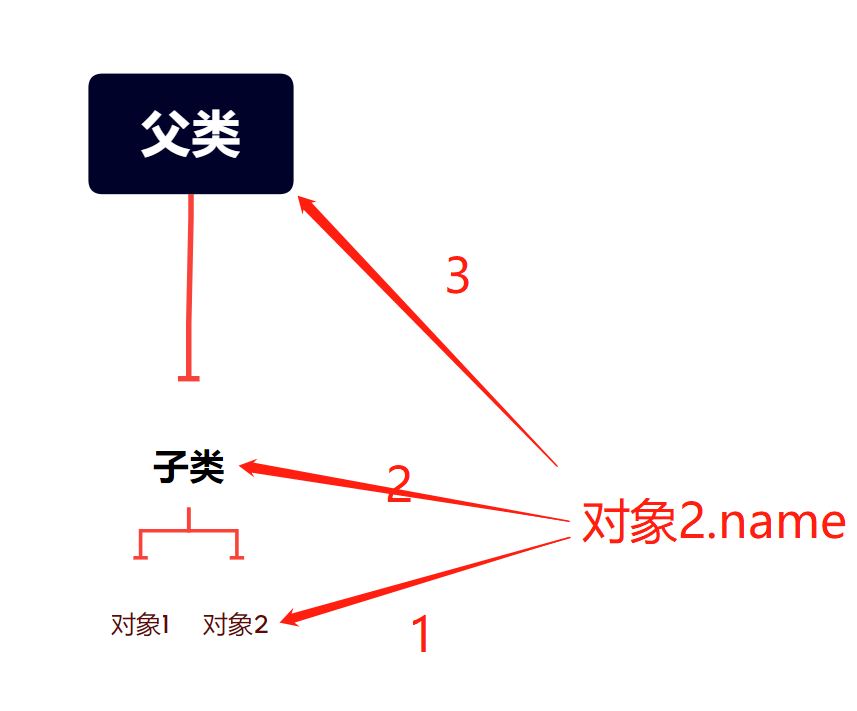
对象自身 >>> 产生对象的类 >>> 父类
'''
功能查找顺序需要注意的点
class A:
def func1(self):
print('from A func1')
def func2(self):
print('from A func2')
self.func1()
class B(A):
def func1(self):
print('from B func1')
obj = B()
obj.func2()
"""
强调:对象点名字 永远从对象自身开始一步步查找
以后在看到self.名字的时候 一定要搞清楚self指代的是哪个对象
"""
上述代码中,A的func2中会执行self.func1(),这个self是obj向上查找传入了A类的,而obj本身的查找顺序还是要从obj开始。
多继承时的查找顺序
-
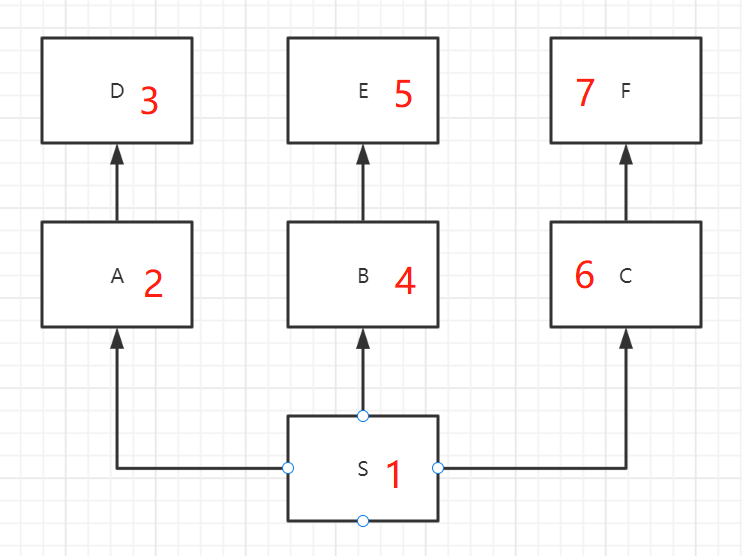
非菱形继承
没有最终继承到同一交点,遵循深度遍历,先对某一条分支搜索。
-
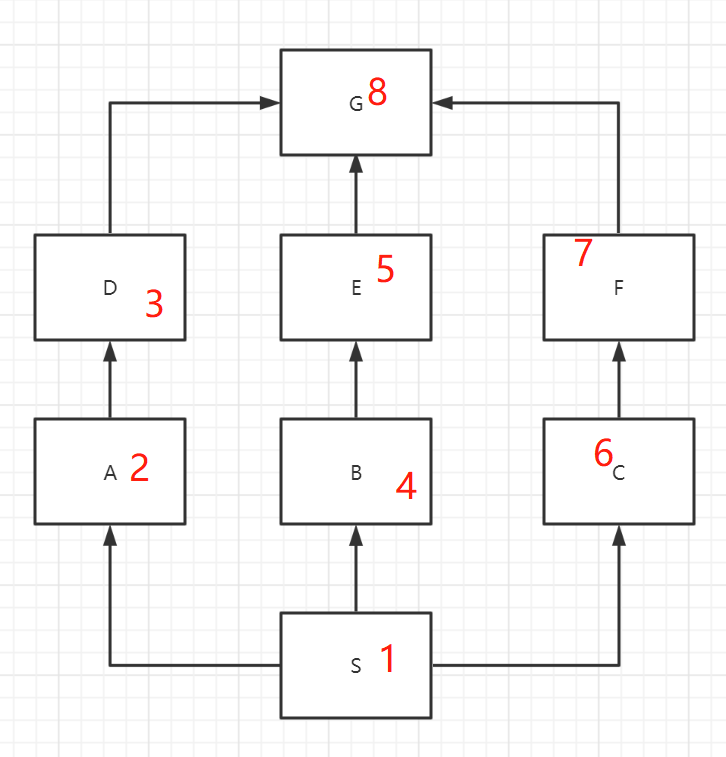
菱形继承
最终会继承到同一交点,广度优先,会依次的先遍历每条分支,最后再遍历交点
'''
对象自身 >>> 产生对象的类 >>> 父类(从左往右)
'''
# 读者可自行更改下面程序中的name注释来实验
class G:
name = 'from G'
pass
class A(G):
name = 'from A'
pass
class B(G):
name = 'from B'
pass
class C(G):
# name = 'from C'
pass
class D(A):
# name = 'from D'
pass
class E(B):
# name = 'from E'
pass
class F(C):
# name = 'from F'
pass
class S1(D,E,F):
pass
obj = S1()
print(obj.name)
这个名字查找顺序其实可以用类的内置函数来查看:
print(S1.mro())
[<class '__main__.S1'>, <class '__main__.D'>, <class '__main__.A'>, <class '__main__.E'>, <class '__main__.B'>, <class '__main__.F'>, <class '__main__.C'>, <class '__main__.G'>, <class 'object'>]
可以看见,列表中类的排列顺序就是我们所推导的顺序。
并且在列表尾部还有一个object类,这就要涉及一个知识点:
新式类和经典类
-
经典类:不继承object或者其子类的类
-
新式类:继承object或者其子类的类
在python2中有经典类和新式类
在python3中只有新式类(所有类默认都继承object)
class Student(object):pass # python2中必须这么写才能创建新式类
# 所以我们在python3中也可能这么写,为了兼容python2
派生方法
super关键字
我们可以在子类中对父类的同名函数做引用:
在上述继承中,我们提到子类会优先拿自己的名字,但是如果我们就想拿父类的名字来做操作,就要借助关键字super().属性来代表从当前子类的父类中找点后面的属性
class Person:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(Person):
def __init__(self, name, age, gender, sid):
super().__init__(name, age, gender) # 子类调用父类的方法
self.sid = sid
class Teacher(Person):
def __init__(self, name, age, gender, level):
super().__init__(name, age, gender)
self.level = level
stu1 = Student('jason', 18, 'male', 666)
print(stu1.__dict__)
tea1 = Teacher('tony', 28, 'female', 99)
print(tea1.__dict__)
派生用法
派生就是在父类的功能基础上做修改优化
# 使列表的尾部添加功能做了一个整型筛选
class MyList(list):
def append(self, values):
if isinstance(values, int):
raise ValueError('只能在尾部添加数字')
super().append(values)
obj = MyList()
print(obj, type(obj))
obj.append(111)
obj.append(222)
obj.append(333)
obj.append('leethon')
print(obj)
派生方法实战
json模块中,我们可以将编程中的一些数据类型序列化成字符串并存储起来,但是json模块能够序列化的数据类型是有限的。
如我们想将datetime序列化存入json就会报错,因为datetime并不是一段字符串,而是一种结构化时间的数据类型。
import datetime
import json
print(datetime.datetime.now()) # 2022-11-07 14:45:21.877414
print(json.dumps(datetime.datetime.now())) # TypeError: Object of type datetime is not JSON serializable
我们去进入json的源码进行查看它的源码和注释,会显示:默认使用jsonencoder这个类来做操作。
而jsonencoder的注释说,默认支持的对象只有以下的表格中的。
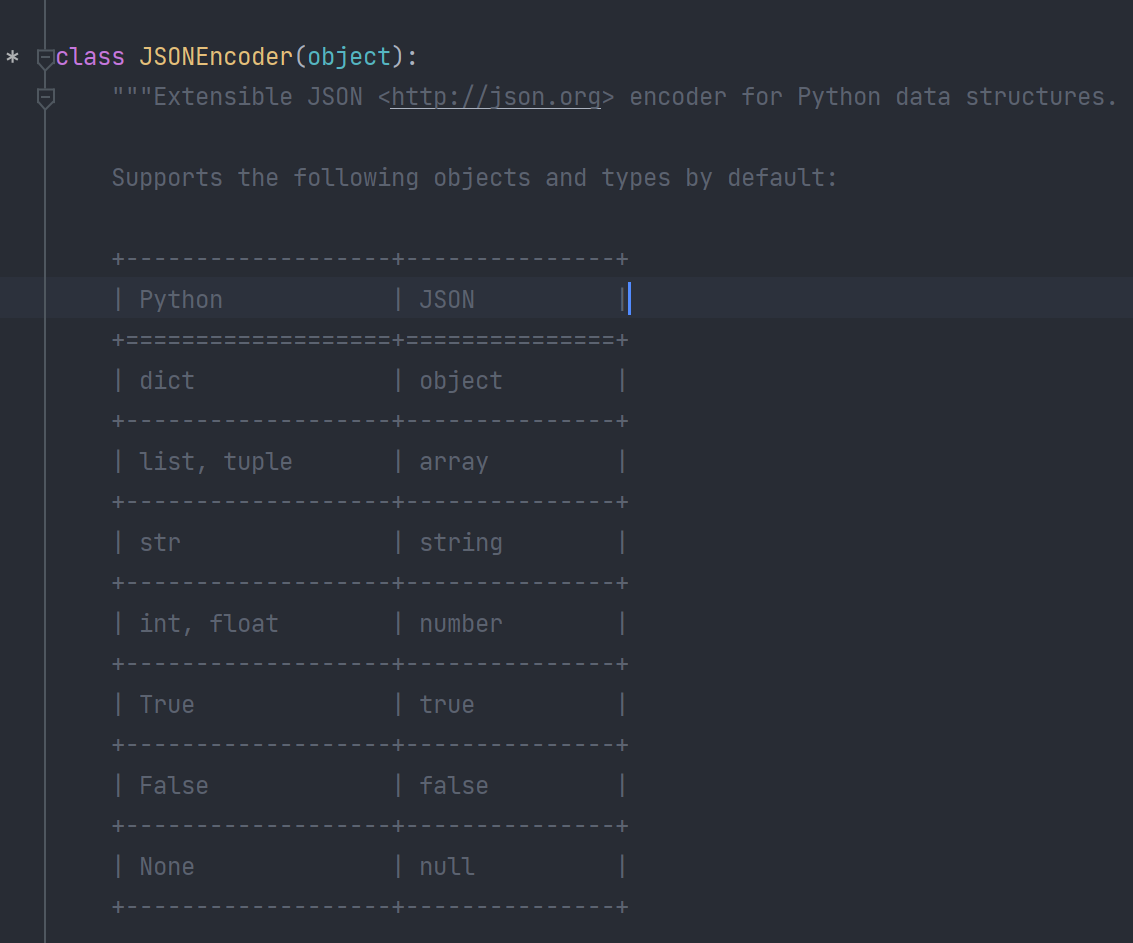
里面有我们熟悉的字典转对象,列表和元组转数组等等。
并没有我们本次想要转的datetime对象。
那我们可以想,如果datetime通过strftime得到字符串格式时间str类型,不就可以通过dumps转换成json中的string格式了吗。
简单的先对datetime进行判断处理不必多说:
但是怎么将以下的数据格式序列化呢:
d = {
't1': datetime.date.today(),
't2': datetime.datetime.today(),
't3': 'leethon'
}
难道还要自己写一遍将里面所有的datetime处理成字符串吗,这显然是个麻烦的程序。
这时候我们就可以通过查看json的源码,对它里面的功能进行理解,找到default函数:
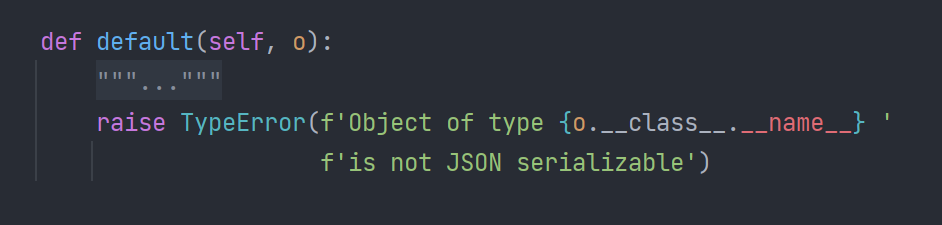
会发现这个报错的功能正是之前我们运行时的报错TypeError: Object of type datetime is not JSON serializable,说明在遇到不是json默认可转的数据格式时,就会运行这个函数。
那我们可以尝试用派生的方法对这个函数进行改造。
class MyJSONEncoder(json.JSONEncoder): # 继承json编辑器的类
def default(self, o):
if isinstance(o, datetime.datetime):
return o.strftime('%Y-%m-%d %X') # 当是datetime类型就处理成字符串返回
if isinstance(o, datetime.date):
return o.strftime('%Y-%m-%d')
return super(MyJSONEncoder, self).default(o)
d = {
't1': datetime.date.today(),
't2': datetime.datetime.today(),
't3': 'leethon'
}
print(json.dumps(d, cls=MyJSONEncoder)) # 更改dumps的编辑器为我们自己改造过的编辑器
当然了,这个方法实际上也是json本身就为我们提前预留的拓展空间,打开JSONEncoder中的函数default的注释,实际上是有相应说明的:
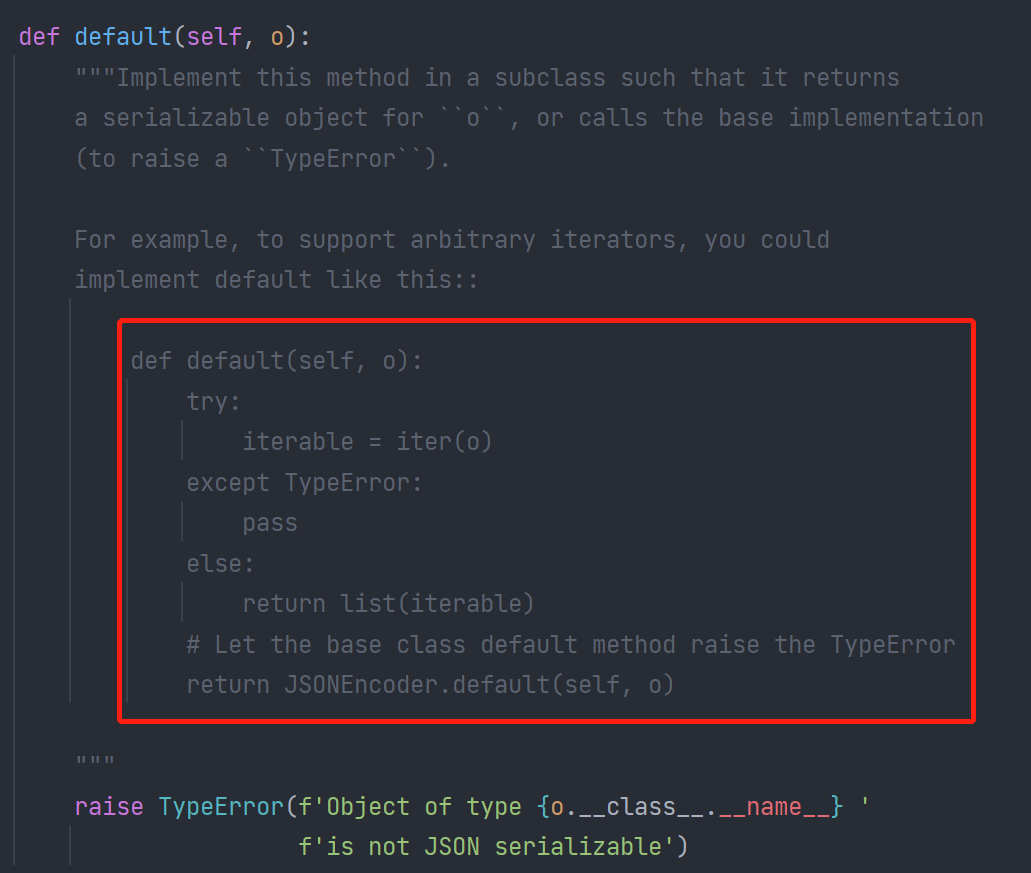
即,如果在default这一步避免raise关键字触发后,后续它们会接收default的返回值进行序列化操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号