网络爬虫小实操
网络爬虫小案例
网络爬虫模块之requests模块
requests模块能够模拟浏览器发送网络请求:
import requests
# 朝指定网址发送请求获取页面数据
res = requests.get('http://www.redbull.com.cn/about/branch') # 红牛官网源码
这里要介绍以下浏览器的原理,浏览器就是将一段HTML文件实时渲染为浏览界面的工具,网页向我们展示的页面其本质就是一个文本文件。而HTML文件本身含有网页的样式、文本、图片、链接等等信息。
所以我们通过requests的get功能拿到的是网址的HTML文件数据,我们可以对HTML文件用正则表达式进行匹配,快速的整理我们需要的信息。
这个就叫网络爬虫,说到网络爬虫,千万不要利用爬虫来做一些如获取私人信息等违法的事情
我们将上述代码获取的对象打印出来发现:
print(res) # <Response [200]>
# 只得到了这个结果,而这是requests里面的一个对象,我们把它的content属性打印出来就可以得到文件了
print(res.content) # 得到了html文件,但是发现的中文是bytes类型的
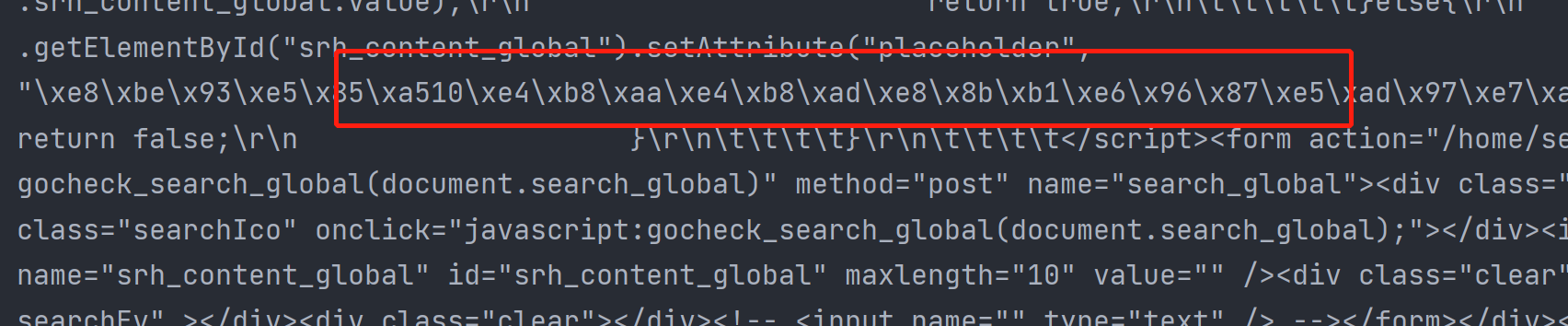
我们使用content模式得到的其实二进制类型的数据,不过pycharm中的字母、数字都会优化出来,而中文会显示为十六进制的模式。
如果想得到HTML的文本格式就要用:
print(res.text) # 默认以utf8编码去解码文件,得到文本
至此,如何获取网页上的所有文本数据,就算实现了。
网络爬虫实战之爬取链家二手房数据
尝试从链家展示的100页房屋出租信息网页整理出一份表格,包含房屋的标题、位置、价格等信息。
获取每个小标题
我们在链家官网按F12查看官网源码,一层层展开标签,发现左侧页面中每个页签的小标题对应的源码格式红框框起来的这部分。
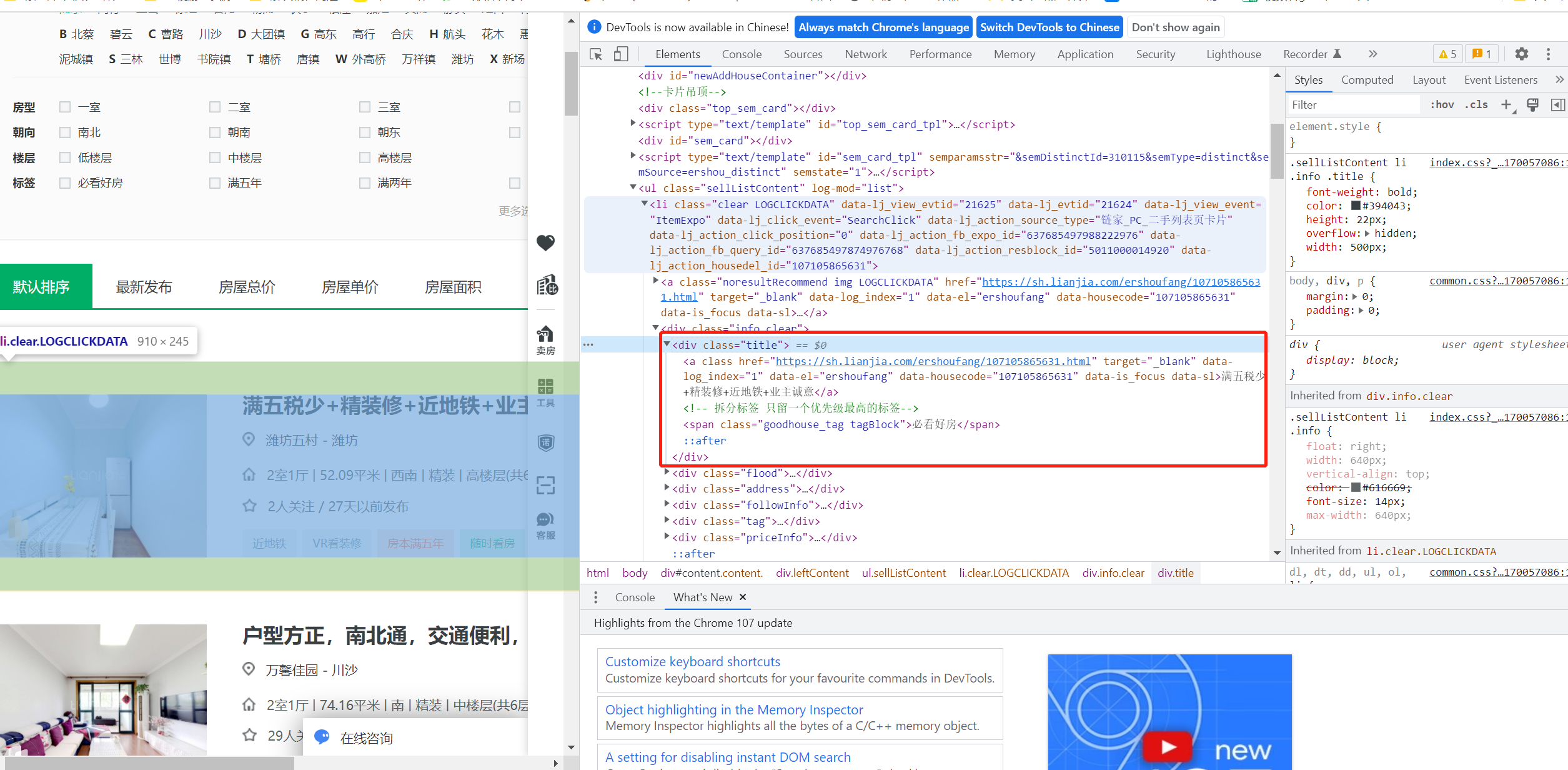
了解html标签的可以得知,每个小标题对应的源码都是这种格式的,会有个<div class="title"></div>将内容a标签和span标签框起来,而我们需要的小标题就在a标签中。
每个标题内部的a标签都是<a ...>小标题</a>这种格式的,而。。。的部分每个标题都不同,我们应该接收任意字符,使用经典的.*?的正则表达式将其接收。仅匹配上述两个共性的地方,于是我们可以用以下程序得到链家第一页所有的小标题组成的列表。
import requests
import re
res = requests.get('https://sh.lianjia.com/ershoufang/pudong/')
ret = re.findall('<div class="title"><a.*?>(?P<content>.*?)</a>.*?</div>', res.text)
print(ret)

获取每个词条的所有有效内容
import requests
import re
# 获取链家首页的网页内容
res = requests.get('https://sh.lianjia.com/ershoufang/pudong/').text
# 对每类数据分组爬取
title = re.findall('<div class="title"><a.*?>(?P<content>.*?)</a>.*?</div>', res)
position = re.findall('<a href=".*?" target="_blank" data-log_index=".*?" data-el="region">(.*?)</a>', res)
pos = re.findall(
'<div class="positionInfo"><span class="positionIcon"></span><a href=".*?" target="_blank" '
'data-log_index=".*?" data-el="region">.*?</a> - <a href=".*?" target="_blank">(.*?)</a> </div>',
res)
house_info = re.findall('<span class="houseIcon"></span>(.*?)</div>', res)
time = re.findall('<span class="starIcon"></span>(.*?)</div>', res)
total_price = re.findall('<div class="totalPrice totalPrice2"><i> </i><span class="">(.*?)</span>', res)
unit_price = re.findall('<span>(.*?元/平)</span>', res)
# 用zip将每个词条的内容拼到一起
house_information = zip(title, position, pos, house_info, time, total_price, unit_price)
for i in house_information:
print(i)
获取每一页的信息
我们刚才获取的是链家首页的信息,我们还可以对每页的网址分别发请求,拿到所有的内容。
import requests
import re
# 循环拿到每一页的网址
for web_site in (f'https://sh.lianjia.com/ershoufang/pudong/pg{i}/' for i in range(1, 101)):
将web_site变量替换掉上述程序中的爬取网址即可逐个爬取每页。
自动化办公领域之openpyxl模块
操作excel表格的第三方模块
-
xlwt往表格中写入数据、wlrd从表格中读取数据
兼容所有版本的excel文件
-
openpyxl最近几年比较火热的操作excel表格的模块
03版本之前的兼容性较差
-
ps:还有很多操作excel表格的模块,甚至涵盖了上述的模块>>>:pandas
openpyxl模块操作
from openpyxl import Workbook
# 创建一个excel文件
wb = Workbook()
# 在一个excel文件内创建多个工作簿
wb1 = wb.create_sheet('学生名单')
wb2 = wb.create_sheet('舔狗名单')
wb3 = wb.create_sheet('海王名单')
# 还可以修改默认的工作簿位置
wb4 = wb.create_sheet('富婆名单', 0)
# 还可以二次修改工作簿名称
wb4.title = '高富帅名单'
wb4.sheet_properties.tabColor = "1072BA"
# 填写数据的方式1
wb4['F4'] = 666
# 填写数据的方式2
wb4.cell(row=3, column=1, value='jason')
# 填写数据的方式3
wb4.append(['编号', '姓名', '年龄', '爱好']) # 表头字段
wb4.append([1, 'jason', 18, 'read'])
wb4.append([2, 'kevin', 28, 'music'])
wb4.append([3, 'tony', 58, 'play'])
wb4.append([4, 'oscar', 38, 'ball'])
wb4.append([5, 'jerry', 'ball'])
wb4.append([6, 'tom', 88, 'ball', '哈哈哈'])
# 填写数学公式
wb4.cell(row=1, column=1, value=12321)
wb4.cell(row=2, column=1, value=3424)
wb4.cell(row=3, column=1, value=23423432)
wb4.cell(row=4, column=1, value=2332)
wb4['A5'] = '=sum(A1:A4)'
wb4.cell(row=8, column=3, value='=sum(A1:A4)')
# 保存该excel文件
wb.save(r'111.xlsx')
将网页爬取内容存成表格
在学会了如何使用第三方模块创建和存储表格后,那我们就可以将从网页上拿到的信息很容易的保存下来了。
import requests
import re
from openpyxl import Workbook
excel_map = Workbook()
lianjia_sheet = excel_map.create_sheet('lianjia')
lianjia_sheet.append(['小标题', '小区', '街道', '标签', '关注度', '总价', '平方价格'])
for web_site in (f'https://sh.lianjia.com/ershoufang/pudong/pg{i}/' for i in range(1, 101)):
# 获取链家首页的网页内容
res = requests.get(web_site).text
# 对每类数据分组爬取
title = re.findall('<div class="title"><a.*?>(?P<content>.*?)</a>.*?</div>', res)
position = re.findall('<a href=".*?" target="_blank" data-log_index=".*?" data-el="region">(.*?)</a>', res)
pos = re.findall(
'<div class="positionInfo"><span class="positionIcon"></span><a href=".*?" target="_blank" '
'data-log_index=".*?" data-el="region">.*?</a> - <a href=".*?" target="_blank">(.*?)</a> </div>',
res)
house_info = re.findall('<span class="houseIcon"></span>(.*?)</div>', res)
time = re.findall('<span class="starIcon"></span>(.*?)</div>', res)
total_price = re.findall('<div class="totalPrice totalPrice2"><i> </i><span class="">(.*?)</span>', res)
unit_price = re.findall('<span>(.*?元/平)</span>', res)
house_information = zip(title, position, pos, house_info, time, total_price, unit_price)
for row in house_information:
# print(i)
lianjia_sheet.append(row)
excel_map.save(r'链家房源信息一览表.xlsx')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号