20212313 吴剑标 实验四 Python综合实践实验报告
课程: 《Python程序设计》
班级: 2123
姓名: 吴剑标
学号: 20212313
实验教师: 王志强
实验日期: 2022年5月25日
必修/选修: 公选课
一、实验内容:基于tkinter爬取小说网站
1、实验灵感与设计
最初的想法,因为我这个酷爱阅读小说,然后最近又学习的python的爬虫技术,所以灵光凸显,想着做一个爬取小说网站的实验吧。但因为我认为单单只有爬取网站的实验重复性太高了,基于我上学期学习了tkinter的图形用户界面,就想着可以直接做一个页面来爬取小说排行榜以及小说的章节还有小说的内容。
2、实验过程与结果
前期的准备:
(1)确定的大致的实验方向后,我就开始了技术准备,先复习了一下上学期的tkinter,还有加强学习这学期的request以及beautifulsoup还有lxml模块。
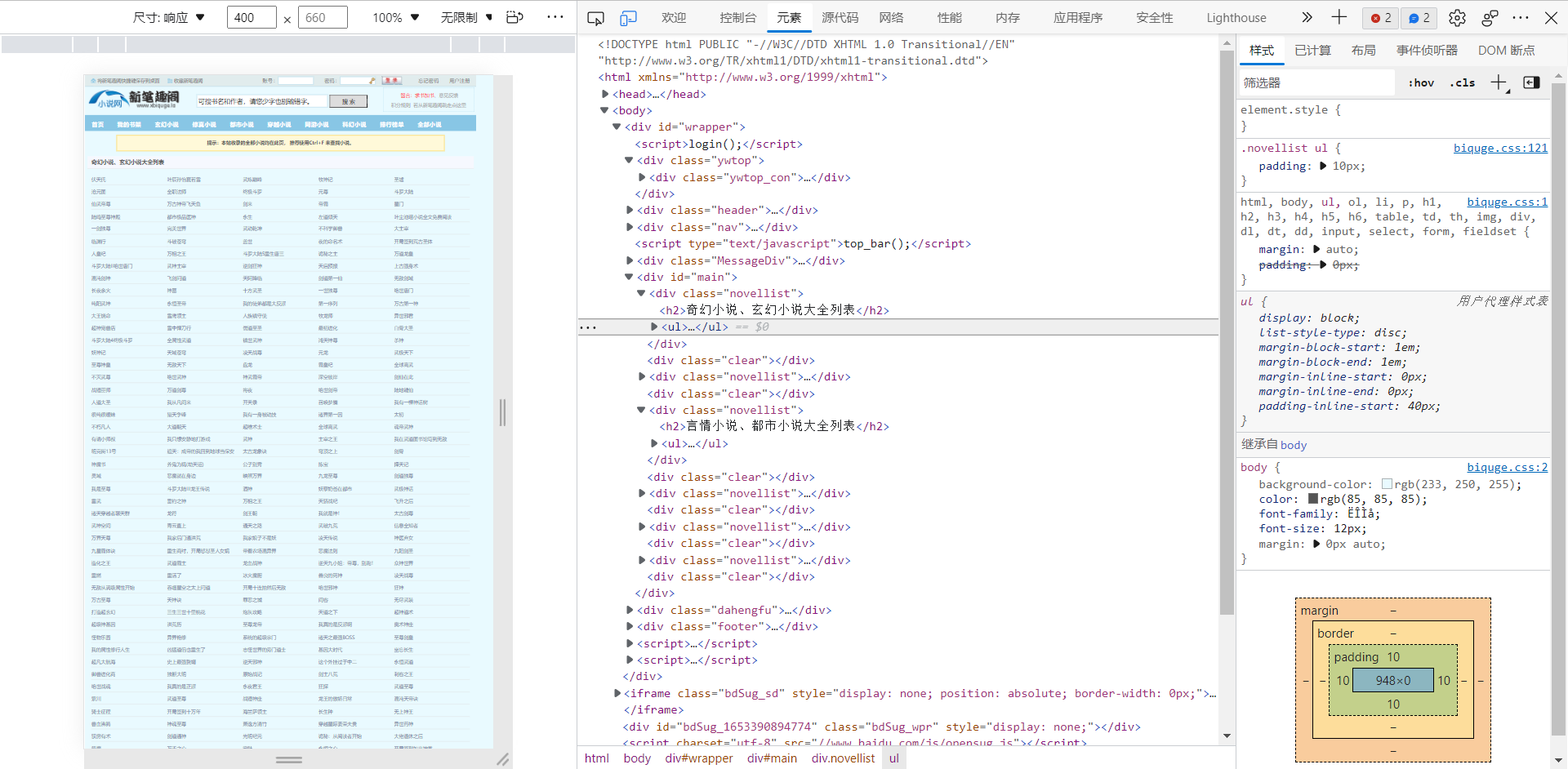
(2)并且选择了爬取的小说网站:https://wap.xbiquge.la/,了解其头文件信息和html的内容情况。

编写python
1、开头先爬取小说页面的小说名并且将其保存再文件中。
import requests
import re
import distutils.sysconfig
from lxml import etree
from bs4 import BeautifulSoup
import string
url = "https://www.xbiquge.la/xiaoshuodaquan/"
response = requests.get(url)
response.encoding="utf-8"
html = response.text
ele = etree.HTML(html)
book_names = ele.xpath("//div[@id='main']/div[@class='novellist']/ul/li/a/text()")
book_urls = ele.xpath("//div[@id='main']/div[@class='novellist']/ul/li/a/@href")
s = ''
for book_name in range(len(book_names)):
s += book_names[book_name] + '\n' + book_urls[book_name] + '\n'
with open('title.txt','w+') as file:
file.writelines(s)
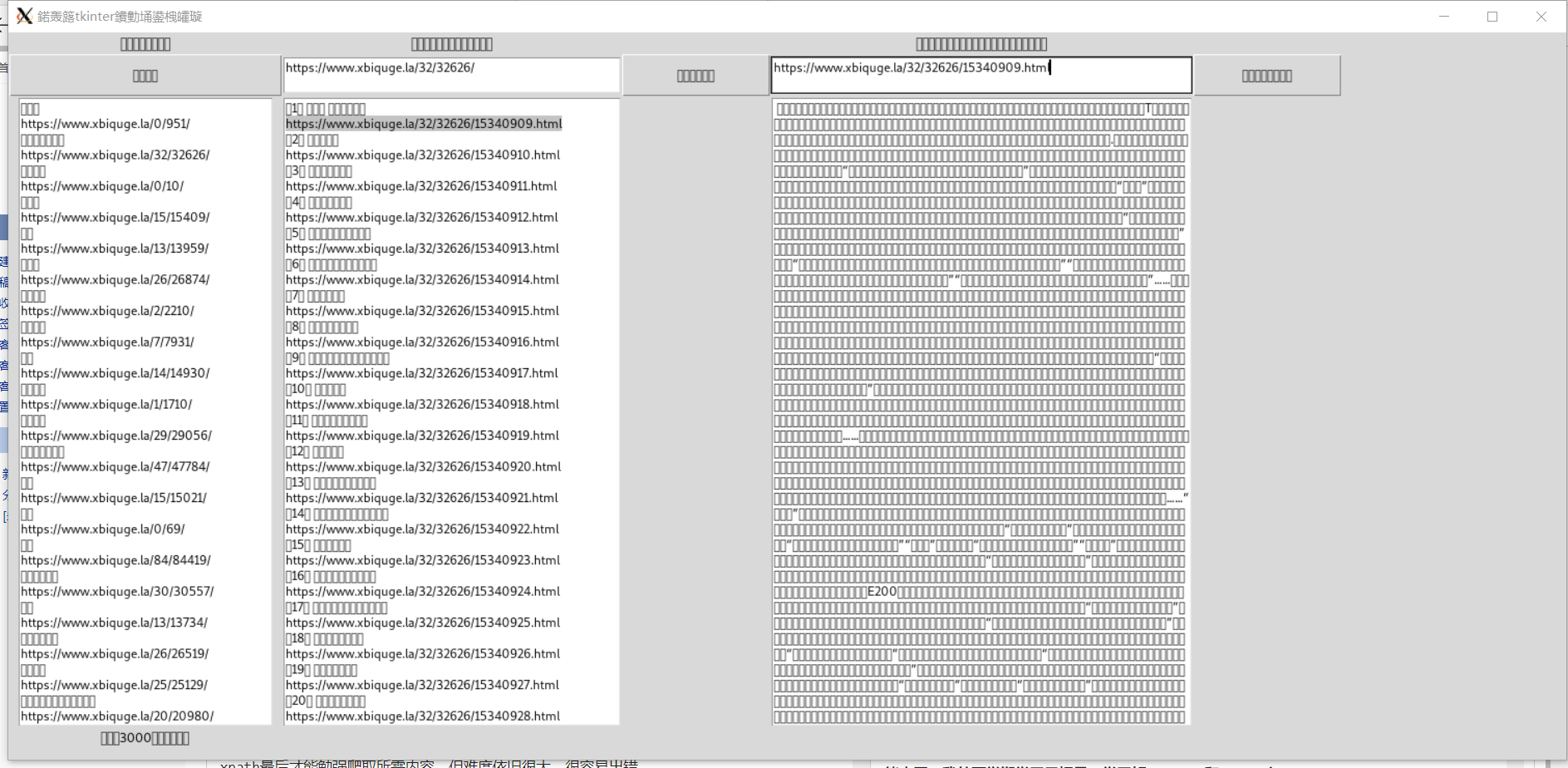
2、创建tkinter的图形用户界面
import tkinter
root=tkinter.Tk()
root.title("爬取小说")
root.geometry('1250x700')
root.resizable
lable1=tkinter.Label(root,text='开始爬取小说吧!',width='30',height='1',font=22).grid(row=1,column=1)
text1=tkinter.Text(root,width=30,height=40)
text1.grid(row=3,column=1)
def button1():
text1.insert("end",s)
button1=tkinter.Button(root,text="爬取目录",command=button1,width=30,height=2).grid(row=2,column=1)
lable=tkinter.Label(root,text="一共有3000本书供您阅读",width=30,height=1,font=22).grid(row=4,column=1)
lable2=tkinter.Label(root,text='输入你想要阅读的小说的链接',width='40',height='1',font=22).grid(row=1,column=2)
text2=tkinter.Text(root,width=40,height=2)
text2.grid(row=2,column=2)
bookname=text2.get("1.0","end")
text3=tkinter.Text(root,width=40,height=40)
text3.grid(row=3,column=2)
button2=tkinter.Button(root,text="爬取书的章节" ,command=button2,width=15,height=2).grid(row=2,column=3)
lable3=tkinter.Label(root,text='请在下面的文本框输入你想要阅读的小说的链接',width='50',height='1',font=22).grid(row=1,column=4)
text4=tkinter.Text(root,width=50,height=2)
text4.grid(row=2,column=4)
text5=tkinter.Text(root,width=50,height=40)
text5.grid(row=3,column=4)
root.mainloop()
3、编写爬取小说章节和小说内容的函数来运用到tkinter的button中去
def papuzhangjie(c):
response1 = requests.get(url=c)
response1.encoding = "utf-8"
html1 = response1.text
ele1 = etree.HTML(html1)
book_chapters = ele1.xpath("//div[@class='box_con']/div[@id='list']/dl/dd/a/text()")
book_c_urls = ele1.xpath("//div[@class='box_con']/div[@id='list']/dl/dd/a/@href")
print(len(book_chapters))
s1 = ""
for book_chapter in range(len(book_chapters)):
s1 += book_chapters[book_chapter] + "\n" + 'https://www.xbiquge.la'+book_c_urls[book_chapter] + "\n"
with open('chapter.txt', 'w+') as file1:
file1.writelines(s1)
print("输入成功")
return s1```
```def xiaoshuoneirong(d):
def remove_upprintable_chars(s):
"""移除所有不可见字符"""
return ''.join(x for x in s if x.isprintable())
# new_url = o_url + chapter_urls[0]
response = requests.get(d)
response.encoding = "utf-8"
html = response.text
# print(html)
ele = etree.HTML(html)
book_bodys = ele.xpath("//div[@id='content']/text()")
# print(book_bodys[0])
#s = "\n" + chapter_titles[i] + "\n"
s2=" "
for book_body in book_bodys:
c = "".join(book_body.split())
#c = remove_upprintable_chars(c)
s2 += c
with open('neirong.txt','w+') as file3:
file3.writelines(s2)
return s2
def button1():
text1.insert("end",s)
def button2():
c=str(text2.get("1.0","end"))
zhangjie=papuzhangjie(c)
#print(zhangjie)
text3.insert("end",zhangjie)
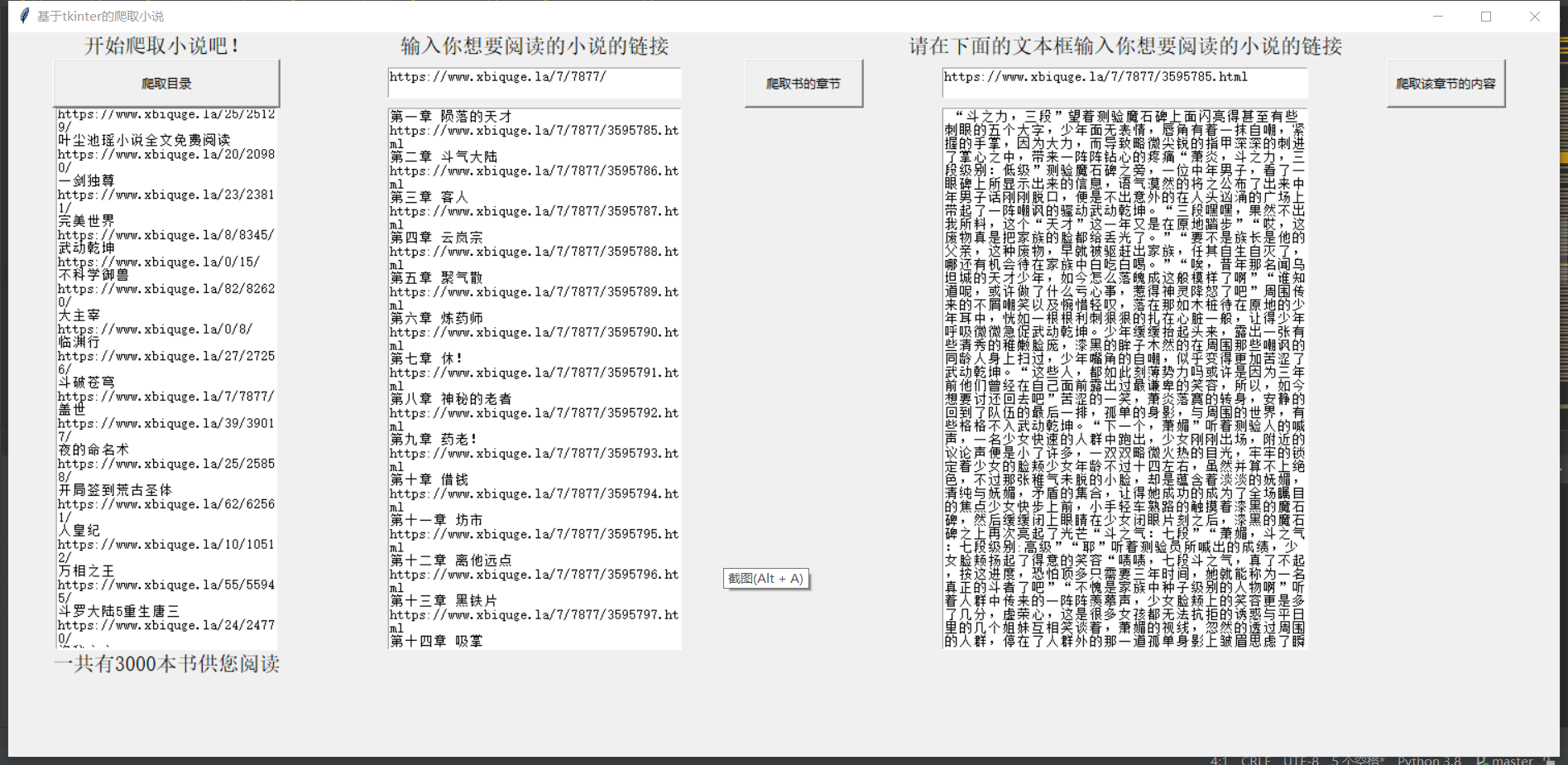
4、最终整合起来,形成了最终的实验结果
5、上传ECS,并使用
>先创建华为云ecs的控制台,然后下载putty和winscp。最后就是上传实验文件然后更新pip3,和python3。最好就是下载各种模块,如xming、tkinter、lxml然后运行。
>但是不知道tkinter页面中的中文是乱码,目前我不知道改怎么改变,也算是这次实验的一个遗憾吧,但pycharm上运行是可以的。还是自己的水平不够。还是得继续努力!

6、实验反思与感想
本次实验是历时最长,难度最大的一次了。前前后后花了好多时间学习。
遇到的困难:
(1).上学期学习的tkinter已经大部分忘记,复习起来很有难度。
(2).再html中很难的爬取准确且需要的内容。我刚开始是一头雾水,最终通过学习lxml中的xpath最后才能勉强爬取所需内容,但难度依旧很大,很容易出错。
(3).tkinter 的text和lable和button的排版比较复杂,所以最终的实验结果也没有将其页面做的好看,结果页面太过简单。
(4).讲爬取小说内容和小说章节的函数与button的command结合起来,是我第二头疼的地方。
二、课程总结
1、课程笔记(都是以pycharm的形式记录的)
我们本学期主要学习的是:
变量赋值
运算符及其优先级
基本数据类型
循环语句
列表、元组、字典、集合
字符串与正则表达式
函数
面向对象程序设计
文件操作及异常处理
Python操作数据库
Python爬虫
import base64
def make_skirt(chima,yinzi):
print(f'您要定制的skirt尺码是{chima},印字是{yinzi}')
make_skirt('xl',yinzi='hahah勒布朗')
def city(cityname,county='中国'):
print(f'{cityname}is in {county}')
city('shanghai')
city('beijing')
city('lundong','england')
name1=["wjb","jzj","gy","hhl"]
def dictionary(name):
a=name1.append(name)
return a
dictionary('llc')
dictionary('cpy')
print(name1)
a={'name':'wjb','singer':'llc','number':'10'}
print(a)
def make_album(name3,singer,number=None) :
if number:
a={'name':{name3},'singer':{singer},'number':{number}}
else :
a = {'name': {name3}, 'singer': {singer}}
return a
b=make_album('jzj','sb',10)
c=make_album('lbj','fw',10)
d=make_album('czy','zz')
print(a)
print(c)
string1="zzzzz20212313"
number=string1[5:14] #分割
print(number)
#spilt ("#",3) 这个是以#分割三次的意思
#string1.find("#") 是查找有多少个警号
#strip 是去掉字符
#正则表达式: ^是开始的意思,$是结束的意思333333
#\w是匹配字母数字或下划线或汉字,不能匹配\
#^\d{8,11}$ 表达是匹配八-11位的数字
#go*gle 匹配gglr到gooole *是匹配前面的字符0次以上 ?是匹配0次或一次
#go+gle 匹配gogle到goooooole +是匹配前面的字符1次以上
# | 是或的意思
import re #引入正则运算
pattern= '^(13[4-9]\d{8})$'
mobile ='11560665795'
pipei=re.match(pattern,mobile)
print(pipei)
if pipei==None:
print("no")
else:
print("yes")
"""
a=int(input("输入人数:"))
sum=0
for i in range (0,a):
b = int(input("输入站数:"))
if b>=1 and b<=4 :
price=3
elif b>=5 and b<=9:
price=4
elif b>=10:
price=5
print(f'''应付款{price}''')
sum=sum+price
print(f'''应付款总额为{sum}''')
"""
class User():
def __init__(self,name,login_attempts):
self.login_attempts=login_attempts
self.name=name
def increment_login_attempts(self):
login_attempts =self.login_attempts +1
print(login_attempts)
def reset_login_attempts(self):
login_attempts=0
print(login_attempts)
wjb=User('llc','4')
class Student:
def __init__(self, name, number):
self.name = name
self.number = number
def student_info(self):
print('name: {}, number: {}'.format(self.name, self.number))
student = Student('zhang', 34)
student.student_info()
print(student.__dict__)
import random
import string
a=random.sample(string.digits,4)
print(a)
print(a[::-1])
print(".".join(a))
# class里面是属性(形参)加方法(def)
#具体的name如wjb,这个是实例,引用实例是用.
class people :
pi=3.1415926 #__是封装,只能在类中被使用
__llc=wjb
def __init__(self,name,number):
self.name=name
self.number=number
def put_npy(self):
print("lalalalal")
s=people("llc","20211111")
print(s.name,s.number)
print(s.put_npy())
print(people.pi)
#类中最重要的是封装继承多态
# __双下划线是封装。只能在类中被使用。
#多态就是一个类中可以有多个子类,且不同子类可以有同种实例方法,如都有def hobby()
'''import json
filename='username.json'
username=input("输入用户名")
with open(filename,'r+') as f:
json.dump(username,f) #文件拓展名一定要是json
print("存入用户名成功")
with open(filename, 'r+') as f:
name=json.load(f)
print(f'欢迎回来,{name}')
'''
'''
socket是用于连接两个端口的。网络进程都是通过socket通信
s.bind(address) 绑定ip地址
s.listen
'''
import socket
a=socket.gethostname() #获取主机名
b=socket.gethostbyname(a)#通过解析主机名得出ip地址
print(b)
print(socket.getservbyname('http')) #搜索端口的
#sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #创建tcp的socket ,第一个是用于服务器与服务器之间的网络通信,第二个是基于TCP的流式socket通信。
#s.bind(b,5050)
#s.listen
'''while True:
conn,addr=s.accept()
print(addr)
while True:
data=conn.recv()
print(data)
conn.send("server received you message.")'''
s=lambda a,b:a+b
print(s([2],[3,4]))
print(s(3,5))
a="llala798 wjb很聪明"
b=a.encode('utf-8')
print(a)
print(b)
print(b.decode()) #把中文编码
print(bytes(a,'utf-8'))
c=base64.b32encode(bytes(a,'utf-8'))
print(c)
print(base64.b32decode(c).decode())
#bytes(a,'utf-8')=a.encode(utf-8)=
with open('llc.txt','r+',encoding='utf-8') as f:
print(bytes(f.read(),'utf-8'))
import os
'''
文件读写:
r是只读,文件必需存在
r+是可以读也可以全覆盖
w是只写,可以创建新文件
w+是打开后清空文件内容然后可读可写
a是在文件末尾追加
a+是在文件末尾写,或者是创建新文件
os 模块
getcwd() 是显示当前目录
mkdir 是创建目录
rmdir 删除目录
'''
path=r"C:\Users\26233\Desktop"
if os.path.exists(path):
print("路径存在")
else:
os.mkdir(path)
with open(path+"\\学习成绩.txt","a+") as file1:
#name=input("输入你的名字")
#number=input("输入你的学号")
#score=input("输入你的成绩")
#file1.write(f'''姓名:{name}\n学号:{number}\n你的成绩:{score}\n''')
file1.seek(0) #如果没有seek,写入后指针指向末尾[EOF],因此读出空
student1=file1.read()
print(student1)
#随机生成姓名和性别和学号
import requests
from bs4 import BeautifulSoup
import lxml
url=r"https://www.baidu.com/s" #要爬虫的地址
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0'} #头文件
response=requests.get(url='https://www.besti.edu.cn/')
soup1=BeautifulSoup(response.content,'lxml')
print(soup1.title)
print(soup1.name)
#print(soup1)
e = requests.get('https://www.bilibili.com/v/popular/rank/game') #当前网站链接
soup2 = BeautifulSoup(e.content,'lxml') #解析html
print(soup2.title)
div_people_list = soup2.find('ul', attrs={'class': 'rank-list'}) #爬取ul类class为rank-list下的数据
print(div_people_list)
ca_s = div_people_list.find_all('a', attrs={'class': 'title'}) #爬取a类class为title下的数据
print(ca_s)
2、结课感想以及体会建议
> 选课之前,我对python课程设计是抱着继续进步的心态的。这学期的课程,我认为让我在python的基础内容是有了更夯实的基础,并且也让我扩宽了知识面,如正则表达式还有python中的爬虫,还有socket等等。都让我受益匪浅。我想继续努力。提高自己的python技能水平。我的下学期学习目标是,学习好pygame和 wxpython。
>至于对老师的建议,我觉得老师就是有的时候简单的内容讲的又比较慢,有些比较难的,比如说socket以及爬虫等内容讲的又比较快。其他就没有了,其他的地方,老师讲的很好而且很耐心。
> 最后希望有时间还可以继续请教老师,大家都一起努力进步

 浙公网安备 33010602011771号
浙公网安备 33010602011771号